

本指南将介绍以下内容:
- Jupyter Notebook 是什么
- 为什么使用 Jupyter Notebook 抓取网页
- 如何通过分步教程学习使用 Jupyter Notebook
- Jupyter Notebook 在网络数据抓取中的具体应用
现在就来一探究竟吧!
Jupyter Notebook 是什么?
在 Jupyter 语境中,notebook 是“一种可共享的文档,结合了计算机代码、简明语言描述、数据、图表、图形和交互式控件”。
Notebook 提供了交互式环境,用于代码原型设计和讲解、数据探索和可视化,以及想法分享。具体来说,由 Jupyter Notebook 应用创建的 notebook 称为 Jupyter Notebook。
Jupyter Notebook 应用是一款服务器-客户端应用,支持通过网页浏览器编辑和运行 notebook 文档,既可以在本地桌面上执行,也可以安装在远程服务器上。
Jupyter Notebook 可提供所谓的“内核”,即用于执行 Notebook 文档中代码的“计算引擎”。具体来说,ipython 内核负责执行 Python 代码(但也有其他语言的内核):
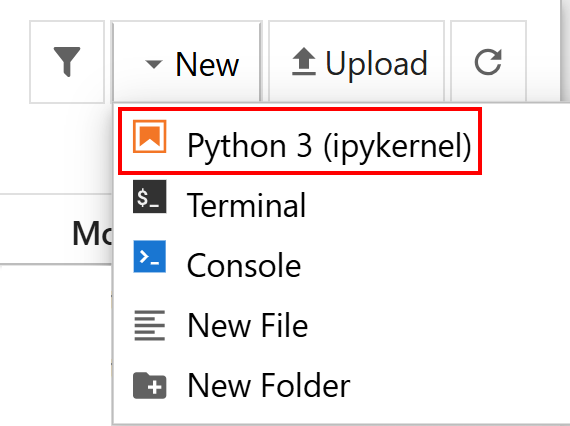
Jupyter Notebook 应用包含一个控制面板,支持显示本地文件、打开现有 notebook 文档、管理文档内核等常见操作:
为什么使用 Jupyter Notebook 抓取网页?
Jupyter Notebook 专为数据分析和研发目的而设计,在网页抓取方面具有以下优势:
- 交互式开发:可以将代码分成易管理的小型代码块(称为“单元格”)来编写和执行。所有单元格相互独立运行。这大大简化了测试和调试的过程。
- 组织性:可以在单元格中使用 markdown 来记录代码、解释逻辑并添加注释或说明。
- 与数据分析工具的集成:由于 Jupyter Notebook 集成了
pandas、matplotlib、seaborn等库,抓取数据后,您可以立即在 Python 中进行数据清洗、处理和分析。 - 可重复性和共享性:Jupyter Notebook 既可以通过
.ipynb文件(标准格式)轻松分享给他人,也可以转换为 ReST、Markdown 等其他格式。
优缺点
使用 Jupyter Notebook 抓取数据的优缺点如下:
👍优点:
- 逐步调试:由于每个单元格都能独立运行,您可以将数据提取代码分解到不同的单元格中分别运行。通过这种方式,您可以分块调试代码,逐个运行单元格并在这一层面捕获错误。
- 文档撰写:在单元格中使用 Markdown 创建文件,记录抓取代码的工作原理,并描述所做选择背后的逻辑。
- 灵活性:在 Jupyter Notebook 中,您可以在同一环境下完成网页抓取、数据清洗和分析等工作。这种设计方便您在不同环境之间灵活切换,既可以在 IDE 中编写抓取脚本,也可以在其他平台分析数据。
👎缺点:
- 不适合大型项目:Jupyter Notebook 容易变成冗长文档,因此在大规模数据抓取项目中并非最佳选择。
- 性能限制:在处理大型数据集或运行长脚本时,Notebook 可能会变得缓慢或无响应。详细了解如何提高网页抓取的效率。
- 不适合自动化:如果您需要定期运行抓取工具或将其部署为大型系统的一部分,Jupyter Notebook 并非最佳选择,这是因为 Jupyter Notebook 主要是为以交互方式手动执行单元格而设计。
如何使用 Jupyter Notebook 抓取网页:分步教程
想必您现已了解为什么使用 Jupyter Notebook 抓取网页。接下来,让我们看看如何在实际抓取场景中运用 Jupyter Notebook!
先决条件
要跟随本教程操作,请确保您的系统满足以下先决条件:
- Python 3.6 或更高版本:3.6 以上的 Python 版本都可以。具体来说,我们将通过
pip安装依赖项,pip 已预装在所有 3.4 以上版本的 Python 中。
第 1 步:设置环境并安装依赖项
假设您的项目主文件夹名为 scraper/。完成这一步后,文件夹结构如下:
scraper/
├── analysis.ipynb
└── venv/其中:
analysis.ipynb是包含所有代码的 Jupyter Notebook 文档。venv/包含虚拟环境。
您可以按如下方式创建 venv/ 虚拟环境目录:
python -m venv venv如为 Windows 系统,要激活虚拟环境,请运行以下命令:
venv\Scripts\activate相应地,如为 macOS/Linux 系统,请执行以下命令:
source venv/bin/activate在激活的虚拟环境中,安装本教程所需的全部库:
pip install requests beautifulsoup4 pandas jupyter seaborn这些库的用途如下:
requests:执行 HTTP 请求。beautifulsoup4:解析 HTML 和 XML 文档。pandas:功能强大的数据操作和分析库,非常适合处理 CSV 文件或表格等结构化数据。jupyter:基于网页的交互式开发环境,用于运行和共享 Python 代码,非常适合数据分析和可视化。seaborn:基于 Matplotlib 的 Python 数据可视化库。
要创建 analysis.ipynb 文件,首先需要进入 scraper/ 文件夹:
cd scraper然后,使用以下命令创建全新 Jupyter Notebook:
jupyter notebook现在,您可以通过 locahost8888访问 Jupyter Notebook 应用了。
点击“新建 > Python 3”选项创建新文件:
新文件将自动命名为 untitled.ipynb。您可以在控制面板中重命名新文件:
非常好!至此,Jupyter Notebook 已充分设置,可以抓取网页了。
第 2 步:确定目标页面
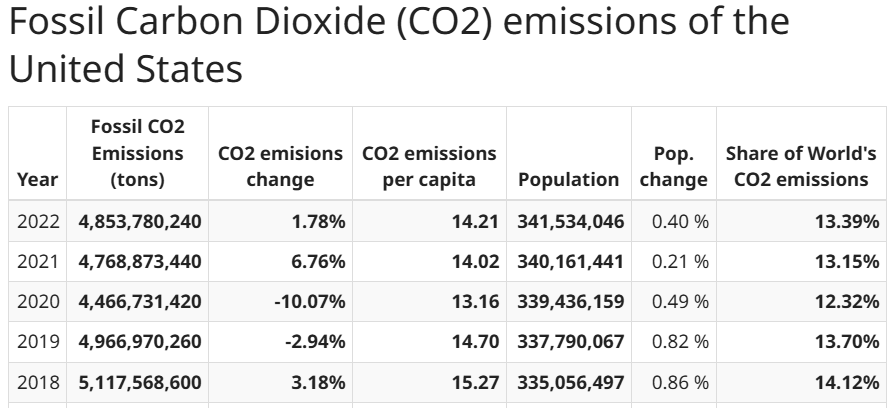
本教程将指导您如何从 worldometer 网站抓取数据。具体来说,目标页面是展示美国每年二氧化碳排放量的表格数据页面:
第 3 步:获取数据
您可以按照以下方式从目标页面获取数据并保存为 CSV 文件:
import requests
from bs4 import BeautifulSoup
import csv
# URL of the website
url = "https://www.worldometers.info/co2-emissions/us-co2-emissions/"
# Send a GET request to the website
response = requests.get(url)
response.raise_for_status()
# Parse the HTML content
soup = BeautifulSoup(response.text, "html.parser")
# Locate the table
table = soup.find("table")
# Extract table headers
headers = [header.text.strip() for header in table.find_all("th")]
# Extract table rows
rows = []
for row in table.find_all("tr")[1:]: # Skip the header row
cells = row.find_all("td")
row_data = [cell.text.strip() for cell in cells]
rows.append(row_data)
# Save the data to a CSV file
csv_file = "emissions.csv"
with open(csv_file, mode="w", newline="", encoding="utf-8") as file:
writer = csv.writer(file)
writer.writerow(headers) # Write headers
writer.writerows(rows) # Write rows
print(f"Data has been saved to {csv_file}")这段代码的作用如下:
- 它使用
requests库中的requests.get()方法向目标页面发送 GET 请求,然后通过response.raise_for_status()方法检查请求是否成功。 - 它使用
BeautifulSoup解析 HTML 内容,具体方法为:创建BeautifulSoup类的实例,然后使用soup.find()方法查找表格选择器。此方法尤其适合用来查找存放数据的表格。如果您不熟悉此语法,请阅读我们的 BeautifulSoup 网页抓取指南。 - 它使用列表推导式来提取表格的标题。
- 它使用
for循环来获取表格中的所有数据,同时跳过标题行。 - 最后,它会打开新的 CVS 文件并将获取的所有数据添加进去。
您可以将这段代码粘贴到单元格中,然后按 SHIFT+ENTER 运行。
运行单元格的另一种方法是选中单元格并按下控制面板中的“运行”按钮:
太棒了!看到“数据已保存至 emissions.csv”,即表示数据已成功提取。
第 4 步:确保数据正确无误
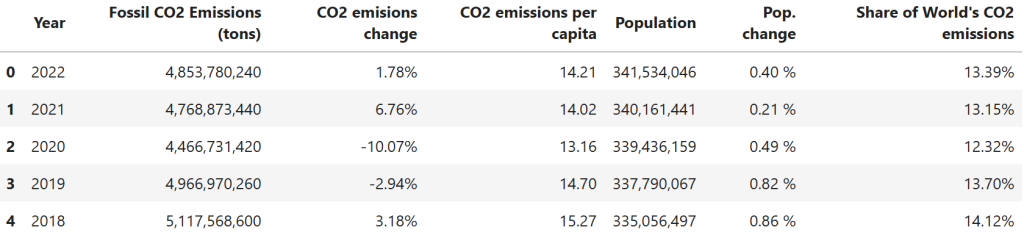
您已将数据保存到 CVS 文件中。打开 CSV 并查看一切是否正常,数据转换过程中有时会出现问题。为此,您可以在新单元格中输入以下代码:
import pandas as pd
# Load the CSV file into a pandas DataFrame
csv_file = "emissions.csv"
df = pd.read_csv(csv_file)
# Print the DataFrame
df.head()这段代码的功能如下:
- 通过
pandas库的pd.read_csv()方法,将 CSV 文件打开为数据框格式。 - 使用
df.head()方法打印数据框的前 5 行。
预期结果如下:
太棒了!接下来只剩下展示所提取的数据了。
第 5 步:直观展示数据
现在,您可以按照自己的需求来分析数据。例如,您可以使用 seaborn 创建折线图来展示二氧化碳排放量随时间的变化趋势。具体操作如下:
import seaborn as sns
import matplotlib.pyplot as plt
# Load the CSV file into a pandas DataFrame
csv_file = "emissions.csv"
df = pd.read_csv(csv_file)
# Clean column names be removing extra spaces
df.columns = df.columns.str.strip().str.replace(' ', ' ')
# Convert 'Fossil CO2 Emissions (tons)' to numeric
df['Fossil CO2 Emissions (tons)'] = df['Fossil CO2 Emissions (tons)'].str.replace(',', '').astype(float)
# Ensure the 'Year' column is numeric
df['Year'] = pd.to_numeric(df['Year'], errors='coerce')
df = df.sort_values(by='Year')
# Create the line plot
plt.figure(figsize=(10, 6))
sns.lineplot(data=df, x='Year', y='Fossil CO2 Emissions (tons)', marker='o')
# Add labels and title
plt.title('Trend of Fossil CO2 Emissions Over the Years', fontsize=16)
plt.xlabel('Year', fontsize=12)
plt.ylabel('Fossil CO2 Emissions (tons)', fontsize=12)
plt.grid(True)
plt.show()这段代码的作用如下:
- 它使用
pandas实现以下目的:- 打开 CSV 文件。
- 使用
df.columns.str.strip().str.replace(' ', ' ')方法清理列名,去除多余的空格(如果不使用该方法,本例中的代码可能会出现错误)。 - 访问“化石燃料二氧化碳排放量(吨)”这一列,并使用
df['Fossil CO2 Emissions (tons)'].str.replace(',', '').astype(float)方法将数据转换为数字。 - 访问“年份”这一列,使用
pd.to_numeric()方法将值转换为数字,并使用df.sort_values()方法将值按升序排列。
- 它使用
matplotlib和seaborn库(seaborn 基于matplotlib构建,因此在安装seaborn时也会自动安装 matplotlib)创建实际图表。
预期结果如下:
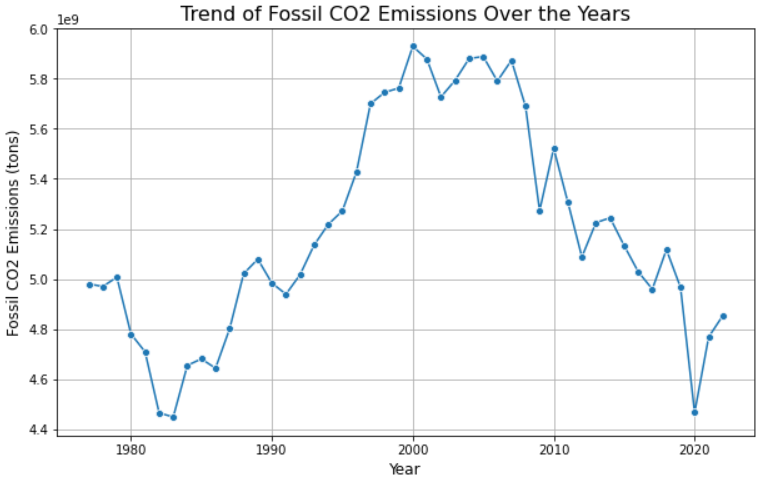
太棒了!这就是 Jupyter Notebook 抓取的强大之处。
第 6 步:整合所有代码
最终的 Jupyter Notebook 网页抓取文档如下所示:
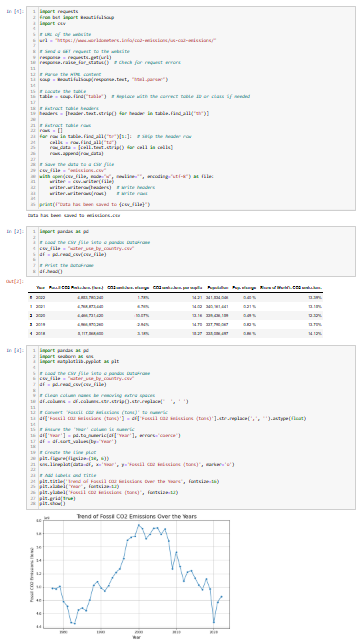
请注意不同的代码块及其各自的输出结果。
Jupyter Notebook 在网页抓取中的具体应用
接下来,我们将讨论 Jupyter Notebook 在网页抓取中的具体应用!
教程
请记住,Jupyter Notebook 中的每个单元格都可以独立执行。再加上对 Markdown 的支持,该库可谓创建分步教程的绝佳工具。
例如,您可以交替使用代码单元格和解释其背后逻辑和推理的单元格。在网页抓取方面,Jupyter Notebook 特别有用。它可以用来为初级开发人员创建教程,指导他们逐步完成整个过程。
科研(研发)
Jupyter Notebook 具有交互性强且便于导出协作的特点,非常适合用于科研和研发工作。这一点在网页抓取方面尤为明显。例如,在抓取需要多次尝试的网站时,您可以在同一个 Notebook 中保存所有测试,并用 Markdown 标注成功的测试。
数据探索
Jupyter 库专为数据探索和分析而设计,因此成为机器学习网页抓取的理想工具。
这种应用场景正好适用于您之前编写的示例。您能够在同一个编程环境中既抓取网站数据,又立即进行分析。
结语
本文介绍了 Jupyter Notebook 在网页抓取方面的强大功能,该工具可为数据提取和分析提供灵活的交互式环境。然而,如果要进行大规模的数据抓取或自动化任务,Jupyter Notebook 可能不是最高效的解决方案。
这正是我们的网页抓取工具的用武之地。无论您是寻求基于 API 的解决方案的开发人员,还是寻找无需编程方案的用户,我们的网页抓取工具都能助您简化数据收集并提升效率。借助 100 多个域名的专用端点、批量请求处理、自动 IP 轮换和验证码破解等功能,您可以轻松实现大规模的结构化数据提取。立即创建免费 Bright Data 账户,体验我们的抓取解决方案并测试我们的代理!



