

在本指南中,你将学习到:
curl_cffi是什么以及它所提供的特性- 它是如何通过最小化基于 TLS 指纹的机器人检测来躲避反爬虫的
- 如何在 Python 中配合它进行网络爬虫
- 高级用法和方法
- 与其他类似 HTTP 客户端的对比
让我们开始吧!
什么是 curl_cffi?
curl_cffi 是一个通过 CFFI 为 curl-impersonate 分支提供 Python 绑定的库。换句话说,它是一个能够模拟浏览器 TLS/JA3/HTTP2 指纹的 HTTP 客户端。因此,对于基于 TLS 指纹检测的反爬虫屏蔽来说,该库是一个非常优秀的解决方案。
⚙️ 特性
- 支持 JA3/TLS 和 HTTP2 指纹伪装,包括最新浏览器及自定义指纹
- 比
requests和httpx更快,速度与aiohttp相当 - 模仿
requests的 API - 支持
asyncio进行异步 HTTP 请求 - 支持在每次请求时进行代理轮换
- 支持 HTTP/2.0
- 支持
WebSocket
工作原理
curl_cffi 基于 cURL Impersonate,它是一个能够生成与真实浏览器匹配的 TLS 指纹的库。
当你发送 HTTPS 请求时,会发生一次 TLS 握手,从而产生一个独特的 TLS 指纹。由于普通 HTTP 客户端与浏览器存在差异,这些指纹可能会暴露自动化行为,进而触发反爬虫防护。
cURL Impersonate 会对 cURL 进行修改,使其匹配真实的浏览器 TLS 指纹:
- TLS 库调整:使用浏览器所用的 TLS 库而不是 cURL 本身的库。
- 配置变更:调整 TLS 扩展和 SSL 选项以模仿浏览器。
- HTTP/2 定制:匹配浏览器的握手方式。
- 自定义 cURL 参数:使用
--ciphers、--curves以及自定义头部信息来实现更精准的模拟。
这样的改动使得请求更接近浏览器的行为,从而帮助绕过反爬虫检测。欲了解更多信息,请参阅我们关于 cURL Impersonate 的指南。
如何使用 curl_cffi 进行网络爬虫:分步指南
假设你要从 Walmart “Keyboard” 页面获取数据:
如果你使用任意 HTTP 客户端访问这个页面,你会收到如下的错误页面:
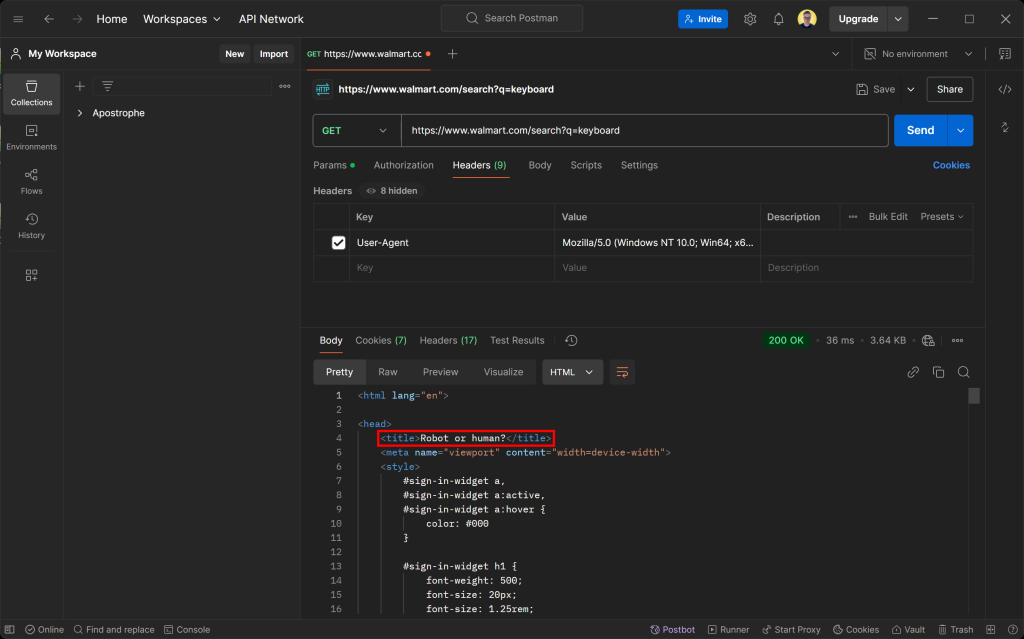
不要被 200 OK 响应状态迷惑。实际上,Walmart 的服务器返回的是一个反机器人检测页面,要求你通过 CAPTCHA 验证来证明自己是人类。
你可能会好奇:即使在请求中设置了 User-Agent 模拟真实浏览器,为何仍会触发?答案就是 TLS 指纹!
下面让我们看一看如何使用 curl_cffi 来绕过这些反爬虫检测,以轻松进行爬取。
步骤 #1:项目环境搭建
首先,请确保你的机器上安装了 Python 3 及以上版本。若尚未安装,可从Python 官方网站下载并按照其指示完成安装。
然后,使用以下命令为你的 curl_cffi 爬虫项目创建一个目录:
mkdir curl-cfii-scraper进入该目录,并在其中创建一个虚拟环境:
cd curl-cfii-scraper
python -m venv env在你喜欢的 Python IDE 中打开这个项目文件夹。Visual Studio Code(安装 Python 扩展)或PyCharm 社区版都是不错的选择。
现在,在项目文件夹下创建一个 scraper.py 文件,初始时它是空的,后续你会把爬虫逻辑加入其中。
在 IDE 的终端中激活虚拟环境。对于 Linux 或 macOS:
./env/bin/activate在 Windows 上则执行:
env/Scripts/activate很好!到此为止,你的环境已经就绪。
步骤 #2:安装 curl_cffi
在激活的虚拟环境中,通过 pip 包 curl-cffi 安装该 HTTP 客户端:
pip install curl-cffi在后台,这个库会根据你的操作系统(Windows、macOS 或 Linux)自动下载针对该平台的 curl impersonation 二进制文件。
步骤 #3:连接到目标页面
从 curl_cffi 中导入 requests:
from curl_cffi import requests这个对象提供了一个与Python Requests 库非常相似的高级 API。
你可以像下面这样发送一个 GET 请求到目标页面:
response = requests.get("https://www.walmart.com/search?q=keyboard", impersonate="chrome")这里的 impersonate="chrome" 参数让 curl_cffi 将该请求伪装成最新版本的 Chrome 浏览器请求。这样,Walmart 会将该自动化请求视为普通浏览器请求,而不是反爬虫页面。
你可以通过以下方式获取目标页面的 HTML 内容:
html = response.text如果你打印 html,将会看到:
<!DOCTYPE html>
<html lang="en-US">
<head>
<meta charSet="utf-8"/>
<meta property="fb:app_id" content="105223049547814"/>
<meta name="viewport" content="width=device-width, initial-scale=1.0, minimum-scale=1, interactive-widget=resizes-content"/>
<link rel="dns-prefetch" href="https://tap.walmart.com "/>
<link rel="preload" fetchpriority="high" crossorigin="anonymous" href="https://i5.walmartimages.com/dfw/63fd9f59-a78c/fcfae9b6-2f69-4f89-beed-f0eeb4237946/v1/BogleWeb_subset-Bold.woff2" as="font" type="font/woff2"/>
<link rel="preload" fetchpriority="high" crossorigin="anonymous" href="https://i5.walmartimages.com/dfw/63fd9f59-a78c/fcfae9b6-2f69-4f89-beed-f0eeb4237946/v1/BogleWeb_subset-Regular.woff2" as="font" type="font/woff2"/>
<link rel="preconnect" href="https://beacon.walmart.com"/>
<link rel="preconnect" href="https://b.wal.co"/>
<title>Electronics - Walmart.com</title>
<!-- omitted for brevity ... -->太好了!这是 Walmart “keyboard” 产品页的正常 HTML 内容。
步骤 #4:编写数据爬取逻辑
curl_cffi 仅仅是一个获取页面 HTML 的 HTTP 客户端。若想进行网络爬虫,你还需要一个用于解析 HTML 的库,例如 BeautifulSoup。有关更多详细信息,你可以阅读我们关于 使用 BeautifulSoup 进行网页爬虫的指南。
在激活的虚拟环境中,安装 BeautifulSoup:
pip install beautifulsoup4在 scraper.py 中导入:
from bs4 import BeautifulSoup然后,用它来解析页面的 HTML:
soup = BeautifulSoup(response.text, "html.parser")"html.parser" 是 Python 标准库自带的 HTML 分析器,BeautifulSoup 将使用它来解析 HTML 字符串。现在,soup 可以让你使用各种方法选择并提取页面上的元素。
在本例中,为了演示,我们只采集页面的标题。你可以使用 CSS 选择器 调用 find() 并获取其文本:
title_element = soup.find("title")
title = title_element.text若想编写更高级的爬取逻辑,可参考我们关于 如何爬取 Walmart 的指南。
最后,打印页面标题:
print(title)很棒!你已经实现了一个基本的爬虫逻辑。
步骤 #5:整合所有代码
下面是你完整的 curl_cffi 爬虫脚本:
from curl_cffi import requests
from bs4 import BeautifulSoup
# Send a GET request to the Walmart search page for "keyboard"
response = requests.get("https://www.walmart.com/search?q=keyboard", impersonate="chrome")
# Extract the HTML from the page
html = response.text
# Parse the response content with BeautifulSoup
soup = BeautifulSoup(response.text, "html.parser")
# Find the title tag using a CSS selector and print it
title_element = soup.find("title")
# Extract data from it
title = title_element.text
# More complex scraping logic...
# Print the scraped data
print(title)使用以下命令运行:
python3 scraper.py同样地,在 Windows 上则使用:
python scraper.py运行结果会是:
Electronics - Walmart.com如果你去掉 impersonate="chrome" 参数,那么得到的将会是:
Robot or human?这就说明,当需要避开反爬虫检测时,模拟浏览器指纹是关键所在。
任务完成!
curl_cffi:高级用法
现在你已经掌握了该库的基本原理,可以继续探索一些更高级的场景。
选择不同的浏览器指纹
curl_cffi 支持模拟多种浏览器。每种浏览器都有一个独特的标签(label),你可以通过传递给 impersonate 参数来指定,例如:
response = requests.get("<YOUR_URL>", impersonate="<BROWSER_LABEL>")以下是所支持的浏览器对应的标签:
chrome99、chrome100、chrome101、chrome104、chrome107、chrome110、chrome116、chrome119、chrome120、chrome123、chrome124、chrome131chrome99_android、chrome131_androidedge99、edge101safari15_3、safari15_5、safari17_0、safari17_2_ios、safari18_0、safari18_0_ios
注:
- 如果想始终模拟最新的浏览器版本,可直接使用
chrome、safari或safari_ios。 - 目前不支持 Firefox,仅支持基于 WebKit 的浏览器。
- 只有当浏览器指纹真的发生变化时才会添加新的版本。如果跳过了某个版本(例如
chrome122),可以用上一版本的指纹来模拟。 - 对于非浏览器目标,可以使用
ja3、akamai等来指定自定义的 TLS 指纹。详情可参见 官方文档。
会话管理
就像 requests 库一样,curl-cfii 也支持会话。Session 对象可以在多次请求之间持久化某些参数,比如 cookies、请求头或其他与会话相关的数据。
下面是一个使用 cURL Impersonate 的 Python 绑定来创建会话的示例:
# Create a new session
session = requests.Session()
# This endpoint sets a cookie on the server
session.get("https://httpbin.io/cookies/set/userId/5", impersonate="chrome")
# Print the session's cookies to confirm they are being stored
print(session.cookies)运行以上脚本的输出为:
<Cookies[<Cookie userId=5 for httpbin.org />]>结果表明,会话确实在不同请求之间持久化了状态,例如服务器设置的 Cookie。
代理集成
就像 requests 一样,curl_cffi 也支持使用 proxies 对象进行代理连接:
# Define your proxy URL
proxy = "YOUR_PROXY_URL"
# Create a dictionary of proxies for HTTP and HTTPS
proxies = {"http": proxy, "https": proxy}
# Make a request using a proxy and browser impersonation
response = requests.get("<YOUR_URL>", impersonate="chrome", proxies=proxies)因为它和 requests 的用法非常相似,如果想更深入地了解,可以参考我们关于 在 Requests 中使用代理的教程。
异步 API
curl_cffi 通过基于 asyncio 的 AsyncSession 对象支持异步请求:
from curl_cffi.requests import AsyncSession
import asyncio
# Define an async function to execute the asynchronous code
async def fetch_data():
async with AsyncSession() as session:
# Perform the asynchronous GET request
response = await session.get("https://httpbin.org/anything", impersonate="chrome")
# Print the response text
print(response.text)
# Run the async function
asyncio.run(fetch_data())通过 AsyncSession 可以更方便地并发多个请求,这对提升爬虫的速度至关重要。
WebSocket 连接
curl_cffi 也支持通过 WebSocket 类进行 WebSocket 连接:
from curl_cffi.requests import WebSocket
# Define a callback function to handle incoming messages
def on_message(ws, message):
print(message)
# Initialize the WebSocket connection with the callback
ws = WebSocket(on_message=on_message)
# Connect to a sample WebSocket server and listen for messages
ws.run_forever("wss://api.gemini.com/v1/marketdata/BTCUSD")这对于想要爬取使用 WebSocket 动态更新数据的网站或 API(如金融行情、体育比分或在线聊天室)非常实用。
无需抓取渲染后的页面,即可直接连接 WebSocket 频道,以更高效的方式获取数据。
注:你也可以通过 AsyncWebSocket 类实现异步方式的 WebSocket。
curl_cffi 与 Requests、AIOHTTP、HTTPX 在网络爬虫场景下的对比
下表简要对比了 curl_cffi 与其他常见的 Python HTTP 客户端:
| 特性 | curl_cffi | Requests | AIOHTTP | HTTPX |
|---|---|---|---|---|
| 同步 API | ✔️ | ✔️ | ❌ | ✔️ |
| 异步 API | ✔️ | ❌ | ✔️ | ✔️ |
支持 WebSocket |
✔️ | ❌ | ✔️ | ❌ |
| 连接池 | ✔️ | ✔️ | ✔️ | ✔️ |
| HTTP/2 支持 | ✔️ | ❌ | ❌ | ✔️ |
User-Agent 自定义 |
✔️ | ✔️ | ✔️ | ✔️ |
| TLS 指纹伪装 | ✔️ | ❌ | ❌ | ❌ |
| 速度 | 高 | 中 | 高 | 中 |
| 重试机制 | ❌ | 可通过 HTTPAdapter |
需通过第三方库 | 内置 Transport |
| 支持代理 | ✔️ | ✔️ | ✔️ | ✔️ |
| Cookie 处理 | ✔️ | ✔️ | ✔️ | ✔️ |
curl_cffi 在网络爬虫中可选的替代方案
curl_cffi 属于“手动”爬虫的范畴,需要你亲自编写大部分爬虫代码。对于简单的静态网站,这没什么问题,但面对动态内容或具有强力验证机制的站点会比较麻烦。
Bright Data 为此提供了一系列 curl_cffi 之外的爬虫解决方案:
- 抓取浏览器 API:完全托管的云端浏览器实例,与 Puppeteer、Selenium 和 Playwright 深度集成。这些浏览器自带 CAPTCHA 识别与自动代理轮换功能,能够像真实用户一样与网站交互并绕过反爬虫防护。
- 网页抓取 API:为 100 多个热门站点提供预配置的端点,用于获取新鲜且结构化的数据。此类 API 既合规又高效,可通过 HTTPX 或任何其他 HTTP 客户端进行数据提取。
- 无代码抓取工具:一款直观的、按需使用的数据采集服务,能免去编写代码的繁琐。它在无需处理基础设施、代理和反爬等难题的同时,为用户提供高可控性与可扩展性。
- 数据集:访问众多网站的预构建数据集,或根据实际需求定制数据采集方案。
这些工具为你提供了更健壮、可扩展且合规的数据采集方式,从而显著减少手动开发工作量。
总结
通过本文,你了解了如何使用 curl_cffi 进行网络爬虫,探索了它的用途、主要特性及优势。作为一个快速且可靠的 HTTP 客户端,它可以很好地模拟真实浏览器。
但需要注意的是,自动化 HTTP 请求会暴露你的公共 IP 地址,可能泄露你的身份和地理位置,带来隐私风险。首选的解决方案之一,是使用代理服务器来 隐藏你的 IP。
Bright Data 拥有业内领先的代理服务器网络,为世界 500 强企业和超 2 万家客户提供服务,代理种类包括:
- 数据中心代理 – 超过 770,000 个数据中心 IP
- 住宅代理 – 超过 72M 个住宅 IP,覆盖全球 195 多个国家
- ISP 代理 – 超过 700,000 个 ISP IP
- 移动代理 – 超过 7M 个移动 IP
立即创建一个免费的 Bright Data 帐号,来体验我们的代理和爬虫解决方案吧!


