

近 25 年来,Tripadvisor 一直是一个在网络上探索各种旅行目的地的好去处。今天,我们将从 Tripadvisor 抓取酒店数据。Tripadvisor 使用了多种技术来阻止网络爬虫,包括:
- JavaScript 挑战
- 浏览器指纹识别
- 动态页面内容
按照下方指南操作,结束后你就能轻松地抓取 Tripadvisor。
前置条件
Tripadvisor 使用了多种阻拦技术。为了简化,我们将它们放在下面的列表中。
- JavaScript 挑战:Tripadvisor 会以 CAPTCHA 的形式向你的浏览器发送简单的 JavaScript 挑战,如果浏览器无法解决,就很可能被判定为爬虫。
- 浏览器指纹识别:它会向你的浏览器发送一个 cookie,然后用这个 cookie 来跟踪你。
- 动态内容:我们最初获得的页面是空白的,随后它会通过一系列 API 调用来获取并渲染数据。
Python Requests 和 BeautifulSoup 并不能胜任此工作。我们需要一个真正的浏览器。通过 Selenium,我们可以使用 webdriver 在 Python 脚本中控制浏览器。Selenium 自带了我们所需的一切。了解更多关于使用 Selenium 进行网页抓取的内容,请点击这里。
让我们安装 Selenium。你还需确保安装了 webdriver。你可以在 这里 找到最新版的 webdriver。你需要确保 Chromedriver 的版本与你的 Chrome 版本相匹配。
你可以使用如下命令来查看 Chrome 的版本号。确保它与你的 Chromedriver 版本相匹配。
google-chrome --version它应该输出类似下面的信息。
Google Chrome 130.0.6723.116然后你可以使用如下命令安装 Selenium。
pip install selenium安装了 Selenium 后,我们不需要额外安装别的东西。Selenium 会处理所有与抓取相关的需求。本教程中的其他包都是 Python 自带的。
需要从 Tripadvisor 抓取什么
让我们来看看我们具体要如何抓取 Tripadvisor 的酒店信息。当我们在 Tripadvisor 上进行一次针对 Miami 的基础搜索时,我们会看到下图中类似的页面。如果你观察,你会发现我们并不仅仅获得了酒店的搜索结果,还有来自所有类别的结果。
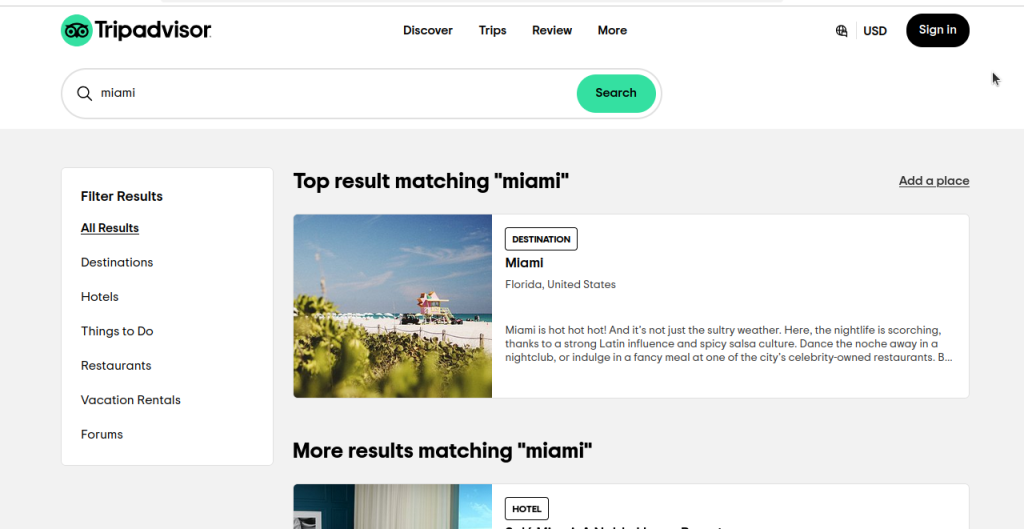
仔细看看这个页面的链接:https://www.tripadvisor.com/Search?q=miami&geo=1&ssrc=a&searchNearby=false&searchSessionId=001f4b791e61703a.ssid&offset=0。现在,我们点一下 Hotels(酒店),然后看看链接:https://www.tripadvisor.com/Search?q=miami&geo=1&ssrc=h&searchNearby=false&searchSessionId=001f4b791e61703a.ssid&offset=0。这两个链接依然非常相似。下面我们将简化这些链接,去掉不必要的部分。
- 所有结果:
https://www.tripadvisor.com/Search?q=miami&geo=1&ssrc=a - 酒店:
https://www.tripadvisor.com/Search?q=miami&geo=1&ssrc=h
ssrc 用来选择我们希望看到的搜索结果。ssrc=a 表示 所有结果,而 ssrc=h 则显示 酒店。如果你点击这个链接 https://www.tripadvisor.com/Search?q=miami&geo=1&ssrc=h,你应该会看到类似下图的页面。
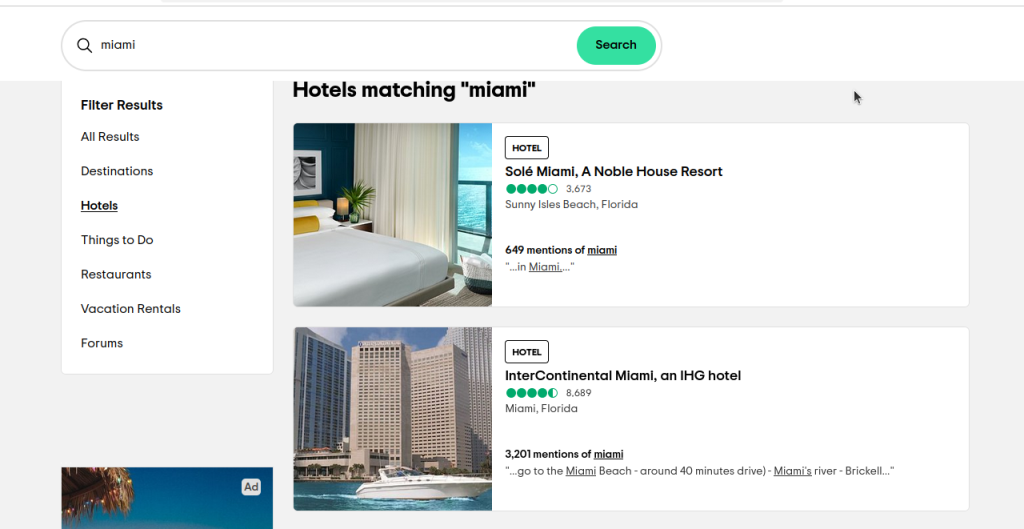
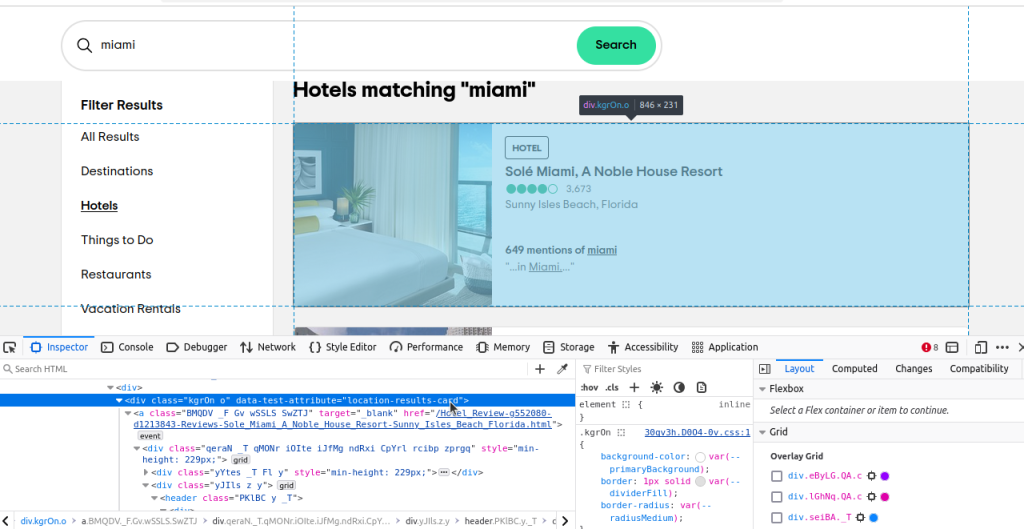
现在,我们只需要弄清楚要定位哪些元素。如果你检查这些元素,会注意到每个结果的 data-test-attribute 都是 "location-results-card"。这很重要,我们可以使用它来构建我们的 CSS 选择器:div[data-test-attribute='location-results-card']。当我们对实际页面进行爬取时,就可以找出页面上所有与此选择器相匹配的元素。
使用原生 Selenium 抓取 Tripadvisor
现在,我们尝试用纯粹的 Selenium 来抓取 Tripadvisor。我们将编写一个整体上相当简单的脚本。我们只需要两个函数:一个用于执行爬取,另一个用于将数据写入 CSV。完成这两个函数后,我们再将其组合成一个完整的脚本。
先看一下 write_to_csv()。它接收两个参数,data 和 page_number。data 可以是 dict,也可以是 dict 对象组成的数组,page_number 用于生成文件名。我们使用 Path(filename).exists() 检查文件是否存在。mode 表示我们打开文件的方式。如果文件已存在,我们将 mode 设为 "a"(追加),如果文件不存在,就保持默认的 "w"(写入)。这两个模式能确保我们总是能得到一个文件,并且不会覆盖已有的文件。
各个函数
def write_to_csv(data, page_number):
if type(data) != list:
data = [data]
print("Writing to CSV...")
filename = f"tripadvisor-{page_number}.csv"
mode = "w"
if Path(filename).exists():
mode = "a"
print("Writing data to CSV File...")
with open(filename, mode) as file:
writer = csv.DictWriter(file, fieldnames=data[0].keys())
if mode == "w":
writer.writeheader()
writer.writerows(data)
print(f"Successfully wrote {page} to CSV...")- 在函数开头,我们检查
data是否为list,如果不是就将它转换为list。 f"tripadvisor-{page_number}.csv"用于构建文件名。- 我们的默认
mode是"w",但如果文件已存在,则将其改为"a"。 csv.DictWriter(file, fieldnames=data[0].keys())用于初始化文件写入。- 如果处于写入模式,则使用第一条数据的键来写入头部;如果是追加模式,则不需要写头部。
- 文件初始化后,我们使用
writer.writerows(data)将数据写进 CSV 文件。
现在,让我们看一下爬取函数。它只接收一个参数 page_number。我们先设置一些自定义的 ChromeOptions,添加参数让浏览器使用 headless 模式,并使用一个伪造的 UA(User-Agent),希望可以让 Tripadvisor 认为我们是正常浏览器。然后我们使用 webdriver 启动浏览器,导航到搜索结果页面。我们调用 sleep(5) 等待 5 秒,让内容加载,也让我们的行为更像正常用户。随后,我们使用之前在“需要从 Tripadvisor 抓取什么”小节中提到的 CSS 选择器。如果我们找不到 hotel_cards,就截个图然后提前退出函数;如果找到了,就提取相应数据并添加到 scraped_data 数组。最后,我们将所有数据写入 CSV。
def scrape_page(page_number: int):
options = webdriver.ChromeOptions()
options.add_argument("--headless")
options.add_argument(f"--user-agent={USER_AGENT}")
print("Connecting to Scraping Browser...")
scraped_data = []
print("-------------------------------")
driver = webdriver.Chrome(options=options)
driver.get(f"https://www.tripadvisor.com/Search?q=Miami&geo=1&ssrc=h&offset={page_number*30}")
print("Connected! Scraping page...")
sleep(5)
hotel_cards = driver.find_elements(By.CSS_SELECTOR, "div[data-test-attribute='location-results-card']")
if not hotel_cards:
driver.save_screenshot("error.png")
driver.quit()
return
for index, card in enumerate(hotel_cards):
score = None
divs = card.find_elements(By.CSS_SELECTOR, "div")
for div in divs:
aria_label = div.get_attribute("aria-label")
if aria_label:
if "bubbles" in aria_label:
score = aria_label
break
data_array = card.text.split("\n")
hotel_dict = {
"name": data_array[1],
"reviews": int(data_array[2].replace(",", "")),
"score": float(aria_label[0:3]),
"location": data_array[3],
"location_mentions": data_array[4].split(" ")[0],
"review_summary": data_array[5]
}
scraped_data.append(hotel_dict)
print(f"Successfully scraped card {index}")
print(f"Scraped page {page_number}")
write_to_csv(scraped_data, page_number)抓取 Tripadvisor 数据
将一切合并,我们便得到如下脚本。欢迎将下面的代码复制粘贴到你的 Python 文件中。
from selenium import webdriver
from selenium.webdriver.common.by import By
from time import sleep
import csv
from pathlib import Path
USER_AGENT = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/130.0.0.0 Safari/537.36"
def write_to_csv(data, page_number):
if type(data) != list:
data = [data]
print("Writing to CSV...")
filename = f"tripadvisor-{page_number}.csv"
mode = "w"
if Path(filename).exists():
mode = "a"
print("Writing data to CSV File...")
with open(filename, mode) as file:
writer = csv.DictWriter(file, fieldnames=data[0].keys())
if mode == "w":
writer.writeheader()
writer.writerows(data)
print(f"Successfully wrote {page} to CSV...")
def scrape_page(page_number: int):
options = webdriver.ChromeOptions()
options.add_argument("--headless")
options.add_argument(f"--user-agent={USER_AGENT}")
print("Connecting to Scraping Browser...")
scraped_data = []
print("-------------------------------")
driver = webdriver.Chrome(options=options)
driver.get(f"https://www.tripadvisor.com/Search?q=Miami&geo=1&ssrc=h&offset={page_number*30}")
print("Connected! Scraping page...")
sleep(5)
hotel_cards = driver.find_elements(By.CSS_SELECTOR, "div[data-test-attribute='location-results-card']")
if not hotel_cards:
driver.save_screenshot("error.png")
driver.quit()
return
for index, card in enumerate(hotel_cards):
score = None
divs = card.find_elements(By.CSS_SELECTOR, "div")
for div in divs:
aria_label = div.get_attribute("aria-label")
if aria_label:
if "bubbles" in aria_label:
score = aria_label
break
data_array = card.text.split("\n")
hotel_dict = {
"name": data_array[1],
"reviews": int(data_array[2].replace(",", "")),
"score": float(aria_label[0:3]),
"location": data_array[3],
"location_mentions": data_array[4].split(" ")[0],
"review_summary": data_array[5]
}
scraped_data.append(hotel_dict)
print(f"Successfully scraped card {index}")
print(f"Scraped page {page_number}")
write_to_csv(scraped_data, page_number)
if __name__ == '__main__':
PAGES = 1
for page in range(PAGES):
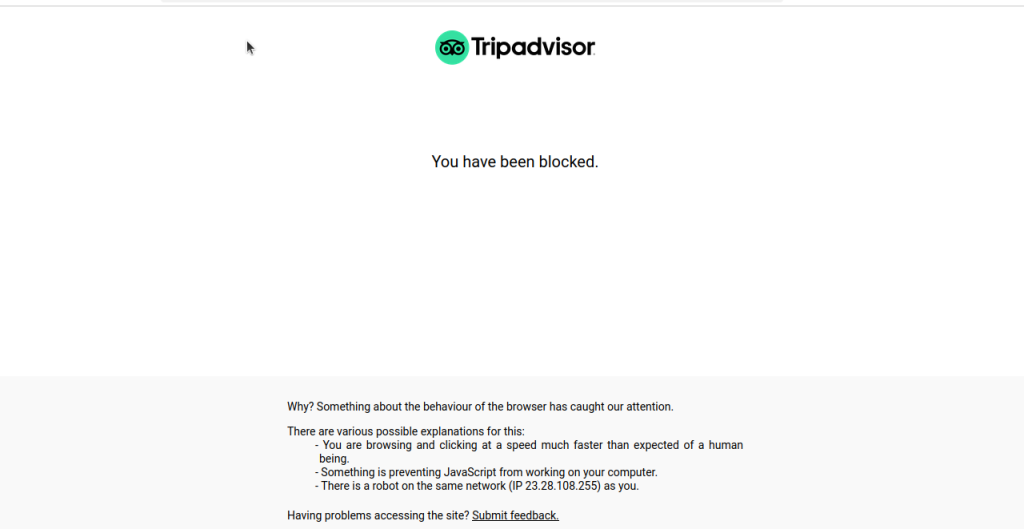
scrape_page(page)当我们运行这段代码时,大多数情况下,我们都会被屏蔽或看到类似下图的 CAPTCHA。
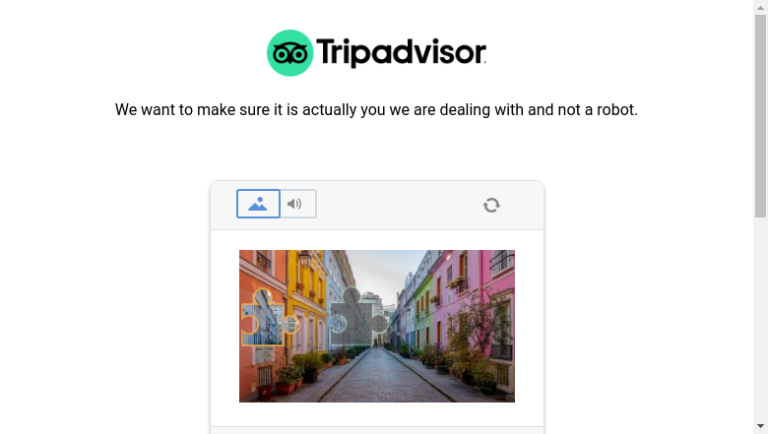
高级技巧
下面是脚本中使用的一些更高级的技巧。主要是在如何处理分页以及如何防止被封锁。
处理分页
看看我们使用的链接:https://www.tripadvisor.com/Search?q=Miami&geo=1&ssrc=h&offset={page_number*30}。分页使用的是 offset 参数。每页给我们 30 个结果。page_number*30 会将页面序号乘以每页结果数(30)。第 0 页会显示第 1-30 条结果,第 2 页则是第 31-60 条结果……依此类推。
再看看我们的 main。PAGES 是我们想抓取的页数。如果你想抓取前 5 页的数据,只需将 PAGES = 1 改为 PAGES = 5。
if __name__ == '__main__':
PAGES = 1
for page in range(PAGES):
scrape_page(page)减轻被封锁风险
在原生 Selenium 中,我们使用了一些技巧来帮助防止被封锁。我们使用了一个伪造的 user agent,并且在多页抓取时使用 sleep(5) 来放慢抓取速度。
以下是我们的 user agent。这告诉 Tripadvisor,我们使用的浏览器支持 Chrome 130.0.0.0 和 Safari 537.36。当 Tripadvisor 读取此信息时,它将返回一个适配这些浏览器的页面。
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/130.0.0.0 Safari/537.36但是,我们依然可能被识别,从而导致脚本被封锁。要想持续突破他们的阻拦,我们需要比原生 Selenium 更强大的东西。
考虑使用 Bright Data
Bright Data 提供各种解决方案帮助我们绕过在使用原生 Selenium 时遇到的封锁问题。Scraping Browser 允许我们在远程环境下运行 Selenium,并使用 Bright Data 的最佳代理。首先,我们将介绍创建账户的过程。随后,我们会在之前的脚本基础上进行微调,以使用 Scraping Browser。
创建账号
首先,进入我们的 Scraping Browser 页面。点击 Start free trial(免费试用)。你可以使用 Google、Github 或电子邮箱注册。
一旦你创建好账号,就会进入控制台。点击 Add。
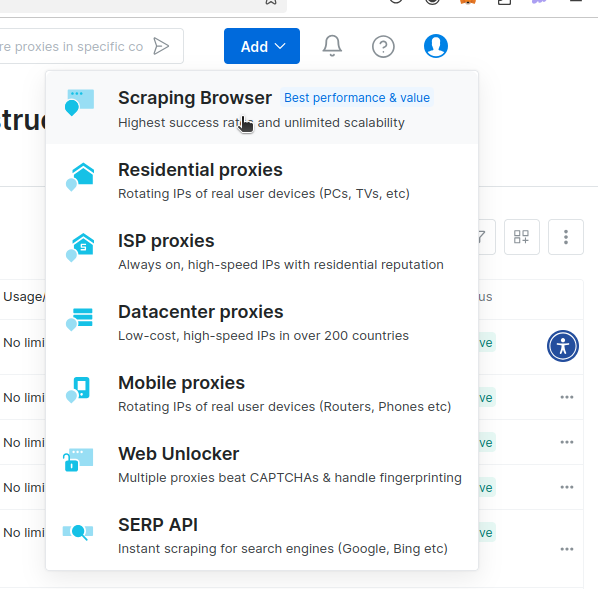
你应该可以看到类似下图的下拉菜单。点击 Scraping Browser。
现在,你就会来到 Scraping Browser 的设置页面。我们使用默认设置即可。默认情况下,Scraping Browser 内置 CAPTCHA 解决方案。
最后,你将被提示创建你的 Scraping Browser 区域(zone)。如果你准备好尝试 scraping browser,就点击 Yes。
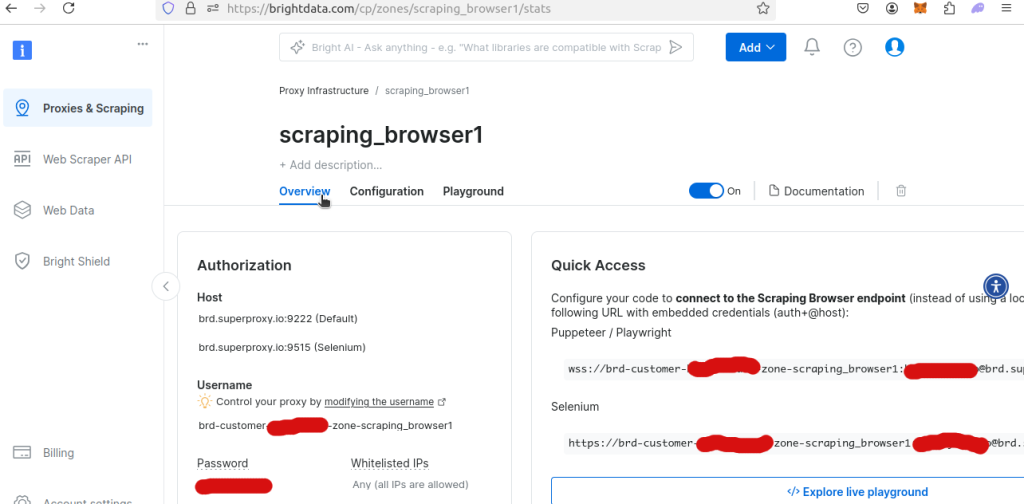
如果你查看新建 Scraping Browser 区域的 Overview,就能查到你的唯一用户名和密码。要在 Python 脚本中使用 Scraping Browser,就需要它们。
使用 Bright Data Scraping Browser 抓取信息
下面的代码示例已经改动过以使用 Scraping Browser 的远程 Webdriver。记得把 YOUR_USERNAME、YOUR_ZONE_NAME 和 YOUR_PASSWORD 替换成实际的用户名、zone 和密码!
from selenium.webdriver import Remote, ChromeOptions
from selenium.webdriver.chromium.remote_connection import ChromiumRemoteConnection
from selenium.webdriver.common.by import By
from time import sleep
import csv
from pathlib import Path
AUTH = "brd-customer-YOUR_USERNAME-zone-YOUR_ZONE_NAME:YOUR_PASSWORD"
SBR_WEBDRIVER = f"https://{AUTH}@zproxy.lum-superproxy.io:9515"
def write_to_csv(data, page_number):
if type(data) != list:
data = [data]
print("Writing to CSV...")
filename = f"tripadvisor-{page_number}.csv"
mode = "w"
if Path(filename).exists():
mode = "a"
print("Writing data to CSV File...")
with open(filename, mode) as file:
writer = csv.DictWriter(file, fieldnames=data[0].keys())
if mode == "w":
writer.writeheader()
writer.writerows(data)
print(f"Successfully wrote {page} to CSV...")
def scrape_page(page_number: int):
print("Connecting to Scraping Browser...")
sbr_connection = ChromiumRemoteConnection(SBR_WEBDRIVER, "goog", "chrome")
scraped_data = []
print("-------------------------------")
with Remote(sbr_connection, options=ChromeOptions()) as driver:
driver.get(f"https://www.tripadvisor.com/Search?q=Miami&geo=1&ssrc=h&offset={page_number*30}")
print("Connected! Scraping page...")
sleep(5)
hotel_cards = driver.find_elements(By.CSS_SELECTOR, "div[data-test-attribute='location-results-card']")
if not hotel_cards:
print("No hotel cards found! Taking a screenshot and exiting.")
driver.get_screenshot_as_file(f"./error_screenshot_page_{page_number}.png")
return
for index, card in enumerate(hotel_cards):
score = None
divs = card.find_elements(By.CSS_SELECTOR, "div")
for div in divs:
aria_label = div.get_attribute("aria-label")
if aria_label:
if "bubbles" in aria_label:
score = aria_label
break
data_array = card.text.split("\n")
hotel_dict = {
"name": data_array[1],
"reviews": int(data_array[2].replace(",", "")),
"score": float(aria_label[0:3]),
"location": data_array[3],
"location_mentions": data_array[4].split(" ")[0],
"review_summary": data_array[5]
}
scraped_data.append(hotel_dict)
print(f"Successfully scraped card {index}")
print(f"Scraped page {page_number}")
write_to_csv(scraped_data, page_number)
if __name__ == '__main__':
PAGES = 1
for page in range(PAGES):
scrape_page(page)这个示例与我们使用原生 Selenium 的例子非常相似,但有一些小区别,主要是因为我们使用的是远程 webdriver,而不是本地 webdriver。
- 我们通过代理连接来设置远程 webdriver:
SBR_WEBDRIVER = f"https://{AUTH}@zproxy.lum-superproxy.io:9515"。 - 错误处理略有不同:
driver.get_screenshot_as_file(f"./error_screenshot_page_{page_number}.png")。我们现在用driver.get_screenshot_as_file(),而不是driver.save_screenshot()。
除了为远程代理连接做的少数改动之外,我们的 Scraping Browser + Selenium 代码几乎与原生 Selenium 代码相同。最大的区别在于:Scraping Browser 能更轻松地获取数据。
运行此代码时,你可能会遇到下面的错误。这在远程连接中可能会发生。如果遇到,重试脚本即可。有时建立稳定的连接需要多试几次。
urllib3.exceptions.ProtocolError: ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response'))如果脚本成功运行,你应该会看到以下输出。
Connecting to Scraping Browser...
-------------------------------
Connected! Scraping page...
Successfully scraped card 0
Successfully scraped card 1
Successfully scraped card 2
Successfully scraped card 3
Successfully scraped card 4
Successfully scraped card 5
Successfully scraped card 6
Successfully scraped card 7
Successfully scraped card 8
Successfully scraped card 9
Successfully scraped card 10
Successfully scraped card 11
Successfully scraped card 12
Successfully scraped card 13
Successfully scraped card 14
Successfully scraped card 15
Successfully scraped card 16
Successfully scraped card 17
Successfully scraped card 18
Successfully scraped card 19
Successfully scraped card 20
Successfully scraped card 21
Successfully scraped card 22
Successfully scraped card 23
Successfully scraped card 24
Successfully scraped card 25
Successfully scraped card 26
Successfully scraped card 27
Successfully scraped card 28
Successfully scraped card 29
Scraped page 0
Writing to CSV...
Writing data to CSV File...
Successfully wrote 0 to CSV...下面是一张我们使用 ONLYOFFICE 打开 CSV 数据的截图。
Image Not ShowingPossible Reasons
- 图像文件可能已损坏
- 托管图像的服务器不可用
- 图片路径不正确
- 图片格式不受支持
替代方案:使用 Datasets
如果你不想编写爬虫,或者你需要更大规模的数据,可以考虑使用 结构化的 Tripadvisor 数据集。我们的数据集提供了高度组织化、高质量的数据,并能根据需求进行定制,让你轻松分析旅行趋势、监控竞争对手定价并优化客户体验。
通过 Tripadvisor 数据集,你可以访问酒店名称、评论、评分、设施、价格等核心数据——并可通过 JSON、CSV、Parquet 等灵活格式交付,并可按你需要的频率更新数据。最重要的是,这些数据集 100% 合规且可扩展,可在确保准确性的同时节省时间和资源。
主要优势:
- 访问 Tripadvisor 的主要数据点,而无需担心封锁。
- 可用过滤器和自定义输出格式按需调整数据集。
- 自动将数据传送到 Snowflake、S3 或 Azure 等平台。
专注于分析数据,而不是收集数据——将繁琐的部分交给我们。查看我们的 Tripadvisor 数据集吧!
结论
从 JavaScript 挑战到完全动态的内容,Tripadvisor 可能会相当难抓。现在你完成了我们的指南,会发现情况轻松多了。读完这篇,你应该已经明白如何使用 Selenium 同时在本地与远程会话中控制浏览器;借助无头浏览器(如 Selenium),还可以对数据进行截图,这让我们在调试抓取程序时更为方便。你知道了如何提取酒店数据,也懂得了怎样用 Python 里的标准库将数据写入 CSV,无需安装额外的包!
如果你想进行大规模抓取,Bright Data 有很多产品可以助你一臂之力。Scraping Browser 为你的各种抓取需求提供强力支持。你可以利用稳定的代理连接和自己选择的无头浏览器来控制一个真实的浏览器,也无需担心 CAPTCHA!
或者,你也可以用最简单的方式获取数据——直接购买可用的 Tripadvisor 数据集。现在就注册,开始免费试用吧!



