

在本文中,您将了解到:
- 什么是 Indeed 爬虫,以及它的工作原理
- 可以从 Indeed 自动提取哪些数据
- 如何使用 Python 构建一个 Indeed 爬虫脚本
- 何时以及为何可能需要更高级的解决方案
让我们开始吧!
什么是 Indeed 爬虫?
Indeed 爬虫可以自动从 Indeed 网站上提取职位列表和相关数据。它通过模拟人工操作来浏览职位搜索页面,随后识别特定元素,如职位标题、公司、地点和职位描述。最后,爬虫程序会从中提取数据并将数据导出以供分析。
可以在 Indeed 上找到哪些数据
Indeed 是一个与工作相关的数据宝库,对于市场分析、招聘或研究目的而言都极具价值。以下列出了在其中可以爬取的主要数据点:
- 职位标题:招聘广告中的具体职能或岗位。
- 公司名称:雇主的详细信息,包括公司简介。
- 地点:职位所在的城市、州或国家。
- 职位描述:关于角色、职责以及要求的详细信息。
- 薪资范围:招聘广告中列出的薪资范围(若有)。
- 职位类型:全职、兼职、合同、实习等。
- 发布时间:职位发布的时间。
- 标签和属性:例如 “紧急招聘” 或 “远程” 等关键字。
- 评分和评价:对雇主的评分以及员工反馈。
- 申请选项:如 “Easy Apply(轻松申请)” 等标识。
如果您感兴趣的核心是职位信息,请参阅我们的如何爬取招聘信息指南。
如何爬取 Indeed:分步指南
在本教程部分,您将学习如何创建一个 Indeed 爬虫。我们将引导您构建一个 Python 脚本,用于爬取 Indeed 上 “data scientist” (数据科学家)职位的页面:
跟随以下步骤,学习如何爬取 Indeed!
第 1 步:项目设置
在开始之前,请确保您的计算机已安装 Python 3。如果尚未安装,请下载并进行安装。
现在,在终端中执行以下命令,为您的项目创建一个目录:
mkdir indeed_scraperindeed_scraper 将用于存放您的 Python Indeed 爬虫。
在终端中进入该目录,然后在其中初始化虚拟环境:
cd indeed_scraper
python -m venv env接下来,在您喜欢的 Python IDE 中加载该项目文件夹。Visual Studio Code(装有 Python 插件)和PyCharm Community Edition都是不错的选择。
在项目目录中创建一个名为 scraper.py 的文件,此时项目目录结构应如下所示:

scraper.py 很快就会包含爬取逻辑。
现在在 IDE 的终端中激活虚拟环境。对于 Linux 或 macOS,使用以下命令:
./env/bin/activate在 Windows 上,可以使用:
env/Scripts/activate很好!现在您已经为 Indeed 爬虫准备好了 Python 环境。
第 2 步:选择合适的爬取库
接下来要确认 Indeed 页面是动态加载还是静态加载。为此,您可以在浏览器的无痕模式下打开Indeed 目标页面并进行操作。您会发现页面上的大部分数据都是动态加载的:

由此可见,您需要使用类似 Selenium 这样的浏览器自动化工具来有效地爬取 Indeed。想要了解更多细节,请参见我们的 Selenium 爬虫教程。
Selenium 能够编程控制浏览器模拟用户交互,并获取由 JavaScript 渲染的内容。是时候安装并体验它了!
第 3 步:安装并配置 Selenium
在已激活的虚拟环境中执行以下命令来安装 Selenium:
pip install -U selenium在 scraper.py 中导入 Selenium,并设置一个 WebDriver 对象:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
# Set up a controllable Chrome instance
driver = webdriver.Chrome(service=Service())以上代码初始化了一个可控的 Chrome 浏览器实例。
注意:Indeed 部署了反爬机制,阻止无头(headless)浏览器访问页面。因此,如果加上 --headless 参数,脚本通常会失败。想要进一步防范检测,请参考 Playwright Stealth。
在脚本的最后一行,不要忘记关闭浏览器:
driver.quit()准备就绪!您已经可以开始爬取 Indeed 了。
第 4 步:访问目标页面
使用 Selenium 的 get() 方法,让浏览器转到目标页面:
driver.get("https://www.indeed.com/jobs?q=data+scientist&l=New+York%2C+NY&from=searchOnHP%2Cwhatautocomplete&vjk=45d1ba700870fbef")此时,scraper.py 文件的内容应类似如下:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
# Set up a controllable Chrome instance
driver = webdriver.Chrome(service=Service())
# Open the target page in the browser
driver.get("https://www.indeed.com/jobs?q=data+scientist&l=New+York%2C+NY&from=searchOnHP%2Cwhatautocomplete&vjk=45d1ba700870fbef")
# Scraping logc...
# Close the web driver
driver.quit()在最后一行添加一个调试断点并运行脚本进行调试,您应看到类似效果:
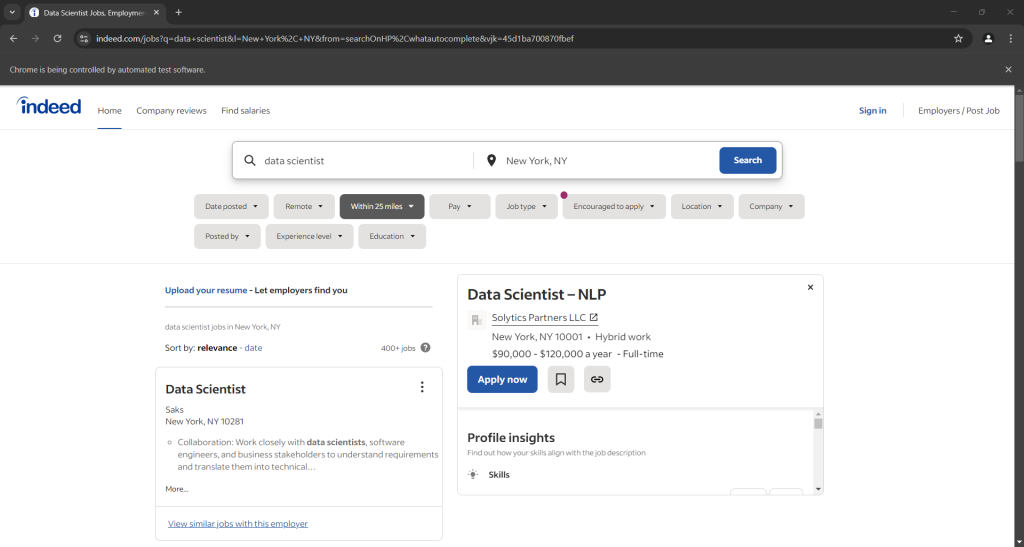
注意:“Chrome 正在受自动测试软件控制” 这条提示说明 Selenium 正在操控浏览器。
干得好!
第 5 步:选择职位元素
Indeed 的搜索页面上会展示多个职位。由于我们的目标是爬取所有职位,因此先初始化一个数组来存储爬取到的数据:
jobs = []接下来,查看页面上职位元素对应的 HTML 结构,以确定如何选择这些元素:
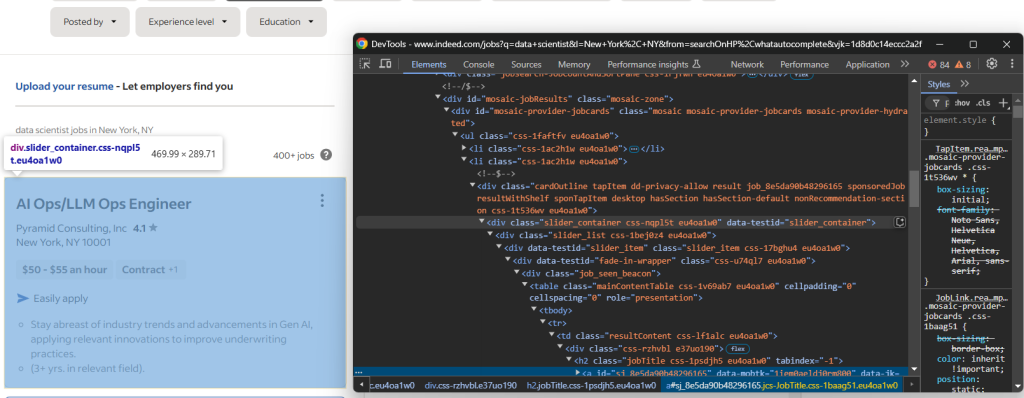
可以看到,每个职位元素都是 #mosaic-provider-jobcards 容器内的一个 slider_item 节点。
通常,您可能会使用 CSS 类选择器来抓取页面元素。但这里的类名疑似是随机生成的(可能在构建时生成),它们变化较大。为了更稳妥,建议使用不易频繁改变的 id 和 data-testid 属性。
使用 Selenium 选择这些职位元素:
jobs_container_element = driver.find_element(By.CSS_SELECTOR, "#mosaic-provider-jobcards")
job_elements = jobs_container_element.find_elements(By.CSS_SELECTOR, "[data-testid=\"slider_item\"]")find_elements() 方法会根据指定的选择策略找出页面上所有匹配的元素。在这里,我们使用的是 CSS 选择器。
别忘了导入 By:
from selenium.webdriver.common.by import By现在,遍历上面获取到的所有职位元素,为后续爬取做准备:
for job_element in job_elements:
# scrape data from each job opening很好!现在您已为 Indeed 爬取逻辑打下了基础。
第 6 步:爬取职位的主要信息
先查看职位卡片上方的主要信息:
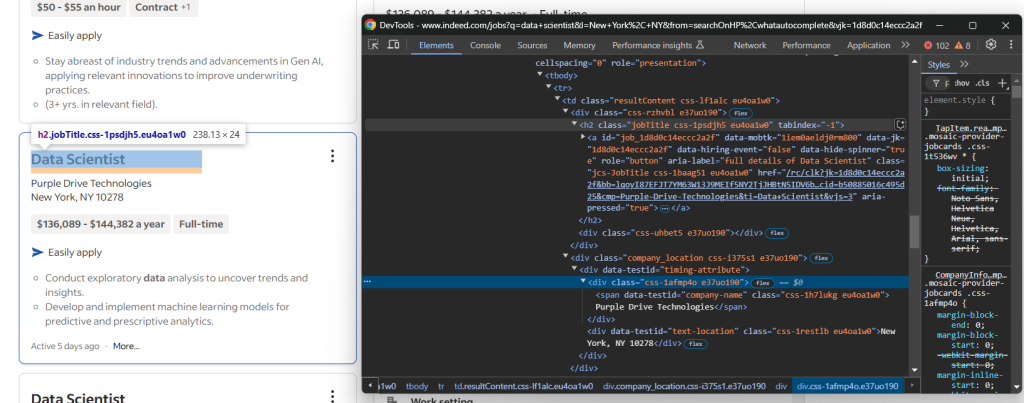
您会看到可以爬取:
<h2>标签中的职位标题<h2>内<a>标签的职位链接 URL[data-testid="company-name"]节点中的公司名称[data-testid="text-location"]节点中的公司地点
将以上信息综合,写出如下的爬取逻辑:
title_element = job_element.find_element(By.CSS_SELECTOR, "h2.jobTitle")
title = title_element.text
url_element = title_element.find_element(By.CSS_SELECTOR, "a")
url = url_element.get_attribute("href")
company_element =job_element.find_element(By.CSS_SELECTOR, "[data-testid=\"company-name\"]")
company = company_element.text
location_element = job_element.find_element(By.CSS_SELECTOR, "[data-testid=\"text-location\"]")
location = location_element.textfind_element() 会选中与所给选择器匹配的第一个元素。然后,通过 text 属性获取其文本内容;要获取节点某个属性值,可以使用 get_attribute() 方法。
目前为止,Indeed 爬虫的主要信息获取逻辑已经就绪,但还有更多有用的数据可以爬取。
第 7 步:爬取职位详情
再来关注职位卡片中的详情部分:
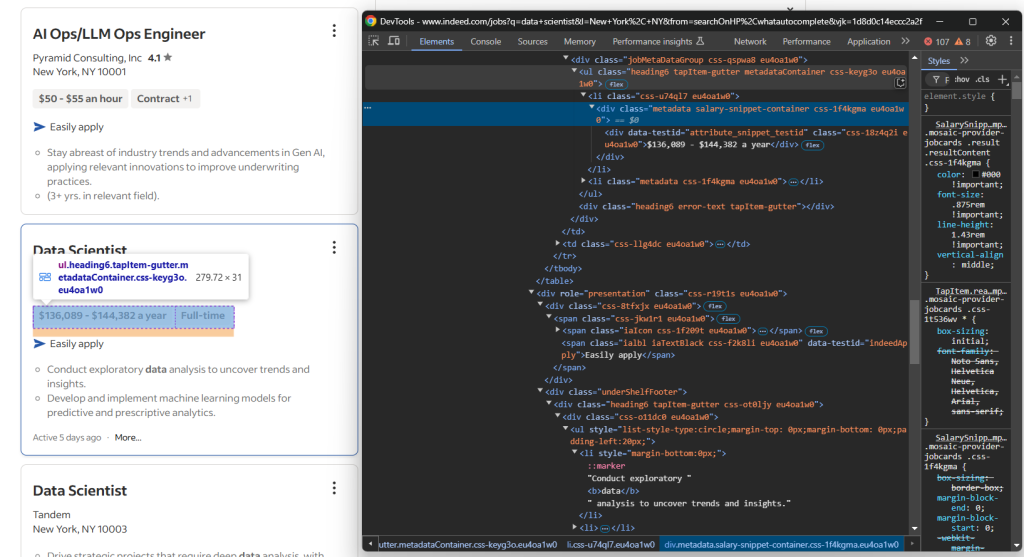
在这里,可以爬取的信息包括:
- 职位标签,它们位于
.jobMetaDataGroup<div>内一个或多个[data-testid="attribute_snippet_testid"]元素中 - 是否支持在 Indeed 上 “Easily apply(轻松申请)”
- 职位描述分点信息,位于
[role="presentation"]<div>的一个或多个ul li中
让我们先来获取这些标签。可以通过以下方式爬取所有标签:
tags = []
tags_container_element = job_element.find_element(By.CSS_SELECTOR, ".jobMetaDataGroup")
tag_elements = tags_container_element.find_elements(By.CSS_SELECTOR, "[data-testid=\"attribute_snippet_testid\"]")
for tag_element in tag_elements:
tag = tag_element.text
tags.append(tag)首先需要为每个职位初始化一个数组来存储标签信息,因为单个职位卡片可能包含多个标签。选中这些标签后,依次提取文本并存入标签数组。
至于 “Easily apply” 选项,相对要更麻烦一点,因为只有部分职位支持此选项,其对应的 HTML 元素并不一定存在。也就是说,只在支持 “Easily apply” 的卡片上才会出现相关节点。
如果尝试选择一个并不存在的元素,Selenium 会抛出一个 NoSuchElementException。因此,可以通过捕获该异常来判断是否支持 “Easily apply”:
try:
job_element.find_element(By.CSS_SELECTOR, "[data-testid=\"indeedApply\"]")
easily_apply = True
except NoSuchElementException:
easily_apply = False如果 [data-testid="indeedApply"] 节点不存在,Selenium 会抛出 NoSuchElementException,一旦被捕获,就将 easily_apply 置为 False。
针对职位描述分点信息,也可与标签爬取类似:
description = []
description_container_element = job_element.find_element(By.CSS_SELECTOR, "[role=\"presentation\"]")
description_elements = description_container_element.find_elements(By.CSS_SELECTOR, "ul li")
for description_element in description_elements:
description_item_text = description_element.text
# Ignore empty description strings
if (description_item_text != ""):
description.append(description_item_text)就这样,Indeed 爬虫即将完成。
第 8 步:收集爬取数据
汇总从各个职位获取的数据,生成一个 job 字典:
job = {
"title": title,
"url": url,
"company": company,
"location": location,
"tags": tags,
"easily_apply": easily_apply,
"description": description
}随后,将其添加到 jobs 数组中:
jobs.append(job)在 for 循环结束后,products(或者这里的 jobs) 中应包含类似这样的结果:
[{'title': 'Data Scientist', 'url': 'https://www.indeed.com/rc/clk?jk=efc7b7f4a8be2882&bb=NM368jsOPyYGAfEtQk2NNae8tSeBHdJ8Y9tImVa1Q9GAipGe0zzddcUozFEL0Na_pYCR4W6ljgljsBxWTUrluVuL8Gom7x7UZlgMzs0spo3NRgisrZ7meuaPfaEcjWoe&xkcb=SoD767M34WNyEaSTwx0FbzkdCdPP&fccid=8678bc4e64c24580&vjs=3', 'company': 'GQR', 'location': 'New York, NY', 'tags': [], 'easily_apply': False, 'description': ['Stay current with industry trends and emerging technologies to ensure competitive edge.', 'Apply statistical and machine learning techniques to improve investment…']},
# omitted for brevity...
{'title': 'Data Scientist, Financial Crimes - USDS', 'url': 'https://www.indeed.com/rc/clk?jk=aaa16dfd1cc6ef01&bb=NM368jsOPyYGAfEtQk2NNdxizAZQnHpzRrlr6WgbV1RtxmXz4vto1qiiqGiIj9CJFQQCV6cW59nE4hGw1yeNdokPfu8Fgl3EALBx5zdWjPm4COEu78DCFh4KTUMIFWkh&xkcb=SoAT67M34WNyEaSTwx0pbzkdCdPP&fccid=caed318a9335aac0&vjs=3', 'company': 'TikTok', 'location': 'Hybrid work in New York, NY', 'tags': [], 'easily_apply': False, 'description': ['As a Financial Crime Data Scientist, you will play a crucial role in leveraging machine learning, analytics and visualization techniques to enhance our…']}]完成得很好!现在只需要把这些数据转换成一种更优的输出格式即可。
第 9 步:将爬取结果导出为 CSV
为了让爬取得到的数据更加易于查看和分享,建议以可读性强的格式导出。例如,将其写入 CSV 文件。可以使用如下代码:
csv_file = "scraped_jobs.csv"
csv_headers = ["title", "url", "company", "location", "tags", "easily_apply", "description"]
with open(csv_file, mode="w", newline="", encoding="utf-8") as file:
writer = csv.DictWriter(file, fieldnames=csv_headers)
writer.writeheader()
for job in jobs:
writer.writerow({
"title": job["title"],
"url": job["url"],
"company": job["company"],
"location": job["location"],
"tags": ";".join(job["tags"]),
"easily_apply": "Yes" if job["easily_apply"] else "No",
"description": ";".join(job["description"])
})open() 函数用于创建 CSV 输出文件,然后通过 csv.DictWriter 将数据写入。由于 tags 和 description 字段是数组,需要借助 join() 来将它们用 ; 连接成单个字符串。
别忘了从 Python 标准库导入 csv:
import csv这样就大功告成了!Indeed 爬虫已经完成。
第 10 步:查看全部代码
最终,您的 scraper.py 文件应大致如下:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.common import NoSuchElementException
import csv
# Set up a controllable Chrome instance
driver = webdriver.Chrome(service=Service())
# Open the target page in the browser
driver.get("https://www.indeed.com/jobs?q=data+scientist&l=New+York%2C+NY&from=searchOnDesktopSerp")
# A data structure where to store the scraped job openings
jobs = []
# Select the job opening elements on the page
jobs_container_element = driver.find_element(By.CSS_SELECTOR, "#mosaic-provider-jobcards")
job_elements = jobs_container_element.find_elements(By.CSS_SELECTOR, "[data-testid=\"slider_item\"]")
# Scrape each job opening on the page
for job_element in job_elements:
title_element = job_element.find_element(By.CSS_SELECTOR, "h2.jobTitle")
title = title_element.text
url_element = title_element.find_element(By.CSS_SELECTOR, "a")
url = url_element.get_attribute("href")
company_element =job_element.find_element(By.CSS_SELECTOR, "[data-testid=\"company-name\"]")
company = company_element.text
location_element = job_element.find_element(By.CSS_SELECTOR, "[data-testid=\"text-location\"]")
location = location_element.text
tags = []
tags_container_element = job_element.find_element(By.CSS_SELECTOR, ".jobMetaDataGroup")
tag_elements = tags_container_element.find_elements(By.CSS_SELECTOR, "[data-testid=\"attribute_snippet_testid\"]")
for tag_element in tag_elements:
tag = tag_element.text
tags.append(tag)
# Check whether the "Easy Apply" element is on the page
try:
job_element.find_element(By.CSS_SELECTOR, "[data-testid=\"indeedApply\"]")
easily_apply = True
except NoSuchElementException:
easily_apply = False
description = []
description_container_element = job_element.find_element(By.CSS_SELECTOR, "[role=\"presentation\"]")
description_elements = description_container_element.find_elements(By.CSS_SELECTOR, "ul li")
for description_element in description_elements:
description_item_text = description_element.text
# Ignore empty description strings
if (description_item_text != ""):
description.append(description_item_text)
# Store the scraped data
job = {
"title": title,
"url": url,
"company": company,
"location": location,
"tags": tags,
"easily_apply": easily_apply,
"description": description
}
jobs.append(job)
# Export the scraped data to an output CSV file
csv_file = "jobs.csv"
csv_headers = ["title", "url", "company", "location", "tags", "easily_apply", "description"]
with open(csv_file, mode="w", newline="", encoding="utf-8") as file:
writer = csv.DictWriter(file, fieldnames=csv_headers)
writer.writeheader()
for job in jobs:
writer.writerow({
"title": job["title"],
"url": job["url"],
"company": job["company"],
"location": job["location"],
"tags": ";".join(job["tags"]),
"easily_apply": "Yes" if job["easily_apply"] else "No",
"description": ";".join(job["description"])
})
# Close the web driver
driver.quit()不到 100 行代码,您就构建了一个 Indeed 爬虫!
使用以下命令运行该爬虫:
python3 script.py或者在 Windows 下:
python script.py此时,项目文件夹中会生成一个 jobs.csv 文件。打开查看后,可看到:
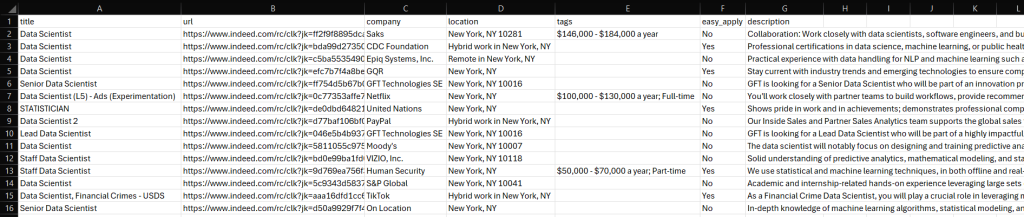
完美呈现!大功告成。
轻松获取 Indeed 数据
Indeed 很清楚其数据价值,并采取了强力措施来保护这些数据。因此,当您使用类似 Selenium 这样的浏览器自动化工具访问其页面时,很可能会遇到 CAPTCHA:
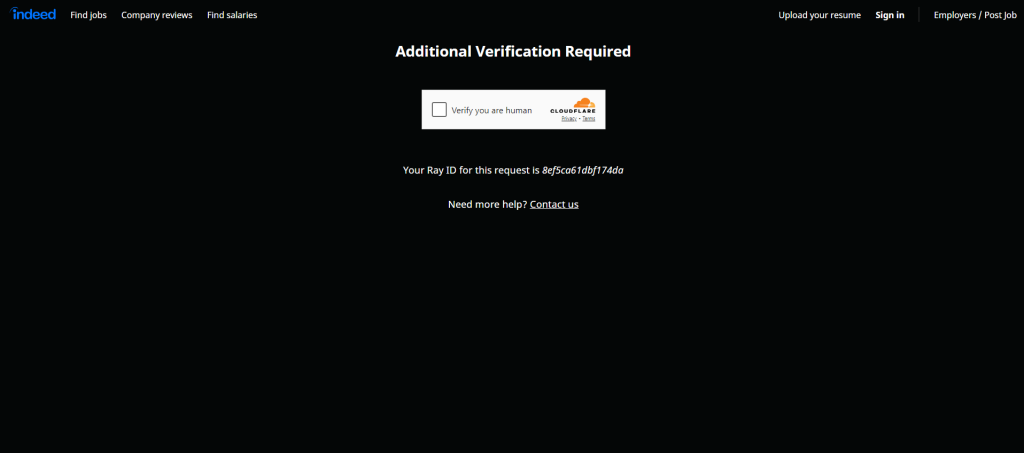
首先,您可以按照我们的Python 绕过 CAPTCHA 教程进行操作。但即使如此,网站仍可能通过其他反爬手段对您的请求进行封锁。想了解更多可参加我们关于反爬技术的线上研讨。
这些障碍说明了没有合适工具时爬取 Indeed 可能非常繁琐且低效。此外,无头(headless)浏览器无法使用也会使您的脚本更慢、更耗资源。
解决方案?Bright Data 的 Indeed Scraper API,让您可通过简单的 API 调用无缝获取 Indeed 上的数据,无需担心 CAPTCHA、阻断或其他麻烦!
结论
通过这篇分步教程,您已经了解到 Indeed 爬虫是什么,可以提取哪些数据,以及如何在 Python 中快速实现一个 Indeed 爬虫。只需大约 100 行代码,就能自动收集 Indeed 上的职位数据。
但是,爬取 Indeed 仍然面临挑战:平台监管严格且会使用 CAPTCHA 等方式来进行反爬检测。这些措施难以绕过,而且会拖慢您的爬取速度,使效率降低。使用我们的 Indeed Scraper API,您可以一键解决所有这些难题。
如果您并不想亲自爬取,但仍然需要职位数据,不妨看看我们现成的 Indeed 数据集!
立即注册一个免费的 Bright Data 账户,试用我们的爬虫 API 或探索我们的数据集吧。


