

请按照本分步教程学习如何构建一个Indeed网站数据抓取的Python脚本,以自动检索有关职位空缺的数据。
本指南将涵盖:
为什么要从网络抓取职位数据?
从网络抓取职位数据有几个好处,包括:
- 市场研究:帮助企业和就业市场分析师收集行业趋势信息。例如,哪些技能需求量大,或哪些地理区域的职位增长。这还可以让你监控竞争对手的招聘活动。
- 优化求职和匹配:帮助求职者从多个来源搜索职位列表,以找到符合其资格和偏好的职位。
- 招聘和人力资源优化:支持招聘过程,帮助理解市场薪资趋势和候选人所需的福利。
因此,职位数据对雇主和求职者都是有用的。
在抓取职位列表时,有一个关键方面需要强调。目标平台需要是公开的。换句话说,它必须允许未登录的用户进行职位搜索。这是因为在登录墙后抓取数据可能会导致法律问题。
这意味着要排除LinkedIn。那么,剩下的哪些职位平台呢?Indeed是领先的在线职位平台之一!
抓取Indeed的库和工具
Python被认为是抓取的最佳语言之一,因其语法、易用性和丰富的库生态系统。因此,让我们开始吧。查看我们的指南使用Python进行网页抓取。
现在,你需要从众多可用的抓取库中选择合适的。为了做出明智的决定,请在浏览器中探索Indeed。你会注意到,站点上的大部分数据是在交互后检索的。这意味着站点大量使用AJAX来动态加载和更新内容而无需页面重新加载。要在这样的网站上进行网页抓取,你需要一个能够运行JavaScript的工具。这个工具就是Selenium!
Selenium使得在Python中抓取动态网站成为可能。它在可控的Web浏览器中渲染站点,按照你的指示执行操作。感谢Selenium,即使目标站点使用JavaScript进行渲染或数据检索,你也可以抓取数据。
了解如何从Indeed等网站抓取职位发布信息!
使用Selenium抓取Indeed上的职位数据
请按照本分步教程,看看如何构建一个抓取Indeed数据的Python脚本。
步骤1:项目设置
在抓取职位之前,请确保你满足以下前提条件:
- 在你的机器上安装Python 3+:下载安装程序,双击并按照安装向导进行操作。
- 选择你喜欢的Python IDE:PyCharm社区版或Visual Studio Code与Python扩展是两个不错的选择。
你现在拥有设置Python项目所需的一切!
打开终端并运行以下命令:
- 创建indeed-scraper文件夹
- 进入该文件夹
- 使用Python虚拟环境进行初始化
mkdir indeed-scraper
cd indeed-scraper
python -m venv env在Linux或macOS上,运行以下命令以激活环境:
./env/bin/activate在Windows上,执行以下命令:
env\Scripts\activate.ps1接下来,在项目文件夹中初始化一个包含以下行的scraper.py文件:
print("Hello, World!")目前,它只打印“Hello, World!”,但很快它将包含Indeed的抓取逻辑。
运行它以验证其是否正常工作:
python scraper.py如果一切顺利,它应在终端中打印此消息:
Hello, World!现在你知道脚本正常工作了,打开你的Python IDE中的项目文件夹。
做得好!准备写一些Python代码吧!
步骤2:安装抓取库
如前所述,Selenium是抓取Indeed职位发布时的一个很好的工具。在激活的Python虚拟环境中运行以下命令,以将其添加到项目的依赖项中:
pip install selenium这可能需要一段时间,请耐心等待。
请注意,本教程涉及Selenium4.11.2,该版本具有自动驱动程序检测功能。如果你的PC上安装了较旧版本的Selenium,请使用以下命令进行更新:
pip install selenium -U现在,清除scraper.py。然后导入包并初始化一个Selenium抓取器:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
# set up a controllable Chrome instance
# in headless mode
service = Service()
options = webdriver.ChromeOptions()
options.add_argument("--headless=new")
driver = webdriver.Chrome(
service=service,
options=options
)
# scraping logic...
# close the browser and free up the resources
driver.quit()此脚本实例化了一个WebDriver实例,以编程方式控制Chrome实例。浏览器将在后台以无头模式打开,这意味着没有图形用户界面。这是生产环境中常见的设置。如果你更喜欢在页面上跟踪抓取脚本运行的操作,请注释掉该选项。这在开发中很有用。
确保你的Python IDE未报告任何错误。忽略可能因为未使用导入而收到的警告。你即将使用这些库从GitHub中提取存储库数据!
完美!现在可以构建你的Indeed抓取Python脚本了。
步骤3:连接到目标网页
打开Indeed并搜索你感兴趣的职位。在本指南中,你将看到如何抓取纽约的软件工程师远程职位。请记住,任何其他Indeed职位搜索都可以。抓取逻辑是相同的。
这是截至目前为止,目标页面在浏览器中的样子:
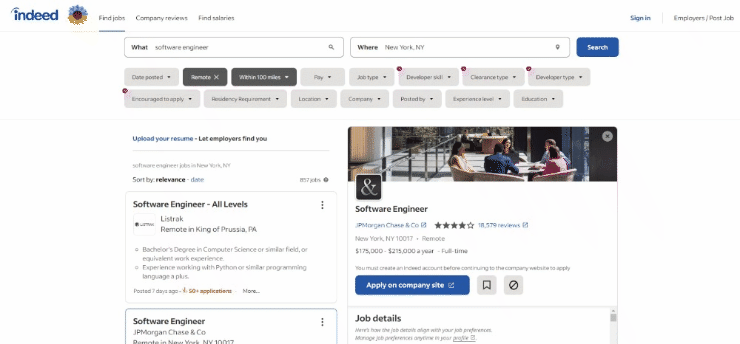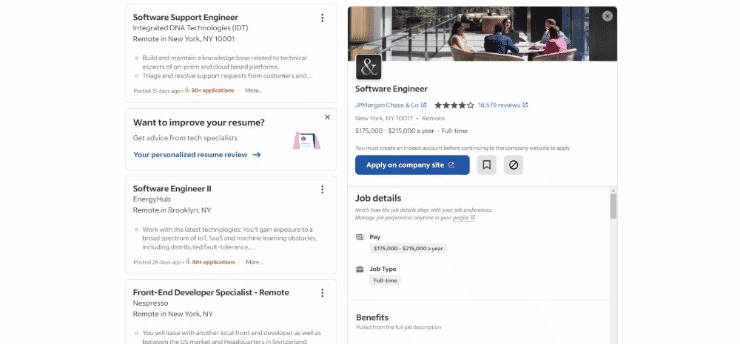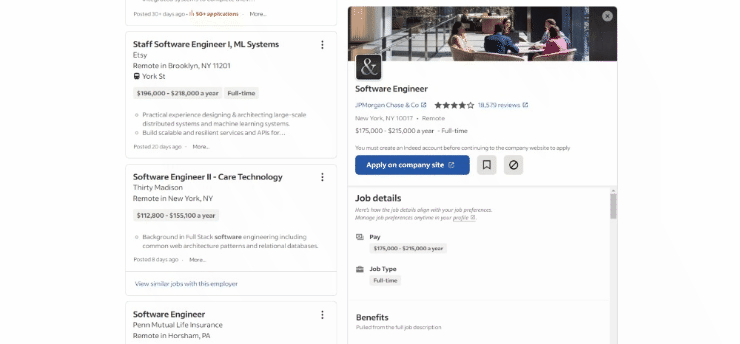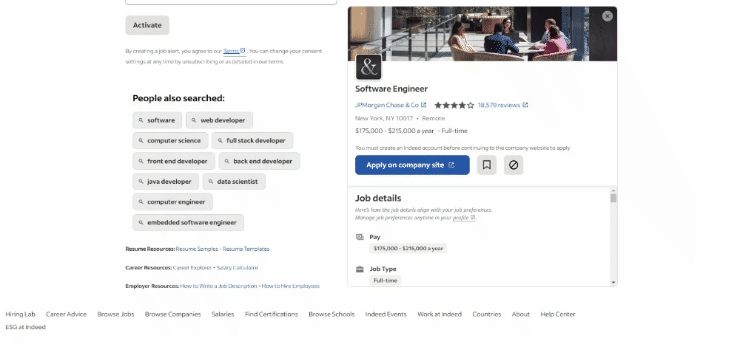
具体来说,目标页面的URL如下所示:
https://www.indeed.com/jobs?q=software+engineer&l=New+York%2C+NY&sc=0kf%3Aattr%28DSQF7%29%3B&radius=100如你所见,它是一个根据一些查询参数而变化的动态URL。
然后,你可以使用Selenium连接到目标页面:
driver.get("https://www.indeed.com/jobs?q=software+engineer&l=New+York%2C+NY&sc=0kf%3Aattr%28DSQF7%29%3B&radius=100")get()函数指示浏览器访问由作为参数传递的URL指定的页面。
打开页面后,应设置窗口大小以确保所有元素都可见:
driver.set_window_size(1920, 1080)到目前为止,你的Indeed抓取脚本如下所示:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
# set up a controllable Chrome instance
# in headless mode
service = Service()
options = webdriver.ChromeOptions()
options.add_argument("--headless=new")
driver = webdriver.Chrome(
service=service,
options=options
)
# set the window size to make sure pages
# will not be rendered in responsive mode
driver.set_window_size(1920, 1080)
# open the target page in the browser
driver.get("https://www.indeed.com/jobs?q=software+engineer&l=New+York%2C+NY&sc=0kf%3Aattr%28DSQF7%29%3B&radius=100")
# scraping logic...
# close the browser and free up the resources
driver.quit()注释掉选项以启用无头模式并运行脚本。它将在关闭前的几秒钟内打开以下窗口:
注意“Chrome正由自动化软件控制”免责声明。这确保了Selenium按预期工作。
步骤4:熟悉页面结构
在开始抓取之前,还有一个关键步骤要执行。抓取网站上的数据涉及选择HTML元素并从中提取数据。找到一种从DOM中获取所需节点的方法并不总是容易的。这就是为什么你应该花些时间分析页面结构以了解如何定义有效的选择策略。
打开浏览器并访问Indeed职位搜索页面。右键点击任何元素并选择“检查”选项以打开浏览器的开发工具:
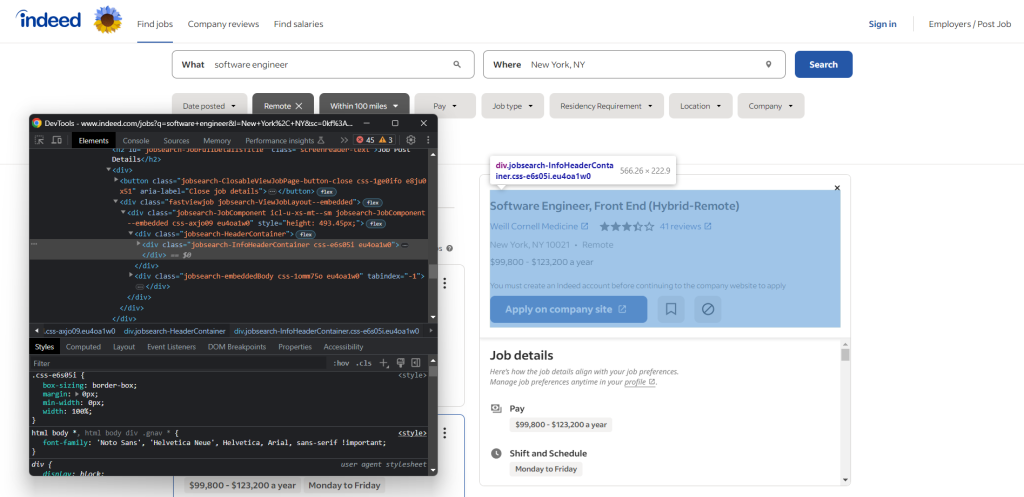
在这里,你会看到大多数包含有趣数据的元素都有以下CSS类:
css-j45z4f、css-1m4cuuf,等等e37uo190、eu4oa1w0,等等job_f27ade40cc1a3686、job_1a53a17f1faeae92,等等
由于这些似乎是编译时随机生成的,因此不应依赖它们进行抓取。相反,你应该基于以下类进行选择逻辑:
jobsearch-JobInfoHeader-titledatecardOutline
或基于如下ID:
companyRatingsapplyButtonLinkContainerjobDetailsSection
还要注意,一些节点具有唯一的HTML属性:
data-company-namedata-testid
这些信息在从Indeed抓取职位数据时很有用。与页面进行交互以研究其反应和显示的数据。你会发现,不同的职位信息具有不同的信息属性。
继续检查目标站点并熟悉其DOM结构,直到你感觉准备好继续为止。
步骤5:开始提取职位数据
单个Indeed搜索页面包含多个职位空缺。因此,你需要一个数组来跟踪从页面抓取的职位:
jobs = []正如你在上一步中注意到的,职位发布显示在.cardOutline卡片中:
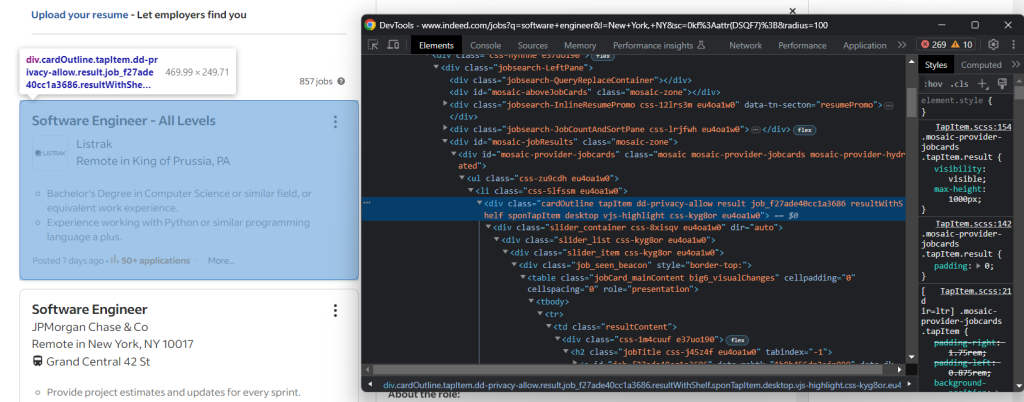
使用以下命令选择它们:
job_cards = driver.find_elements(By.CSS_SELECTOR, ".cardOutline")来自Selenium的find_elements()方法允许你定位网页上的元素。同样,还有find_element()方法可用于获取与选择查询匹配的第一个节点。
By.CSS_SELECTOR指示驱动程序使用CSS选择器策略。Selenium还支持:
By.ID:根据idHTML属性搜索元素By.TAG_NAME:根据HTML标签搜索元素By.XPATH:通过XPath表达式搜索元素
使用以下命令导入By:
from selenium.webdriver.common.by import By遍历职位卡列表,并初始化一个Python字典来存储职位详情:
for job_card in job_cards:
# initialize a dictionary to store the scraped job data
job = {}
# job data extraction logic...职位发布可能有多个属性。由于只有一小部分是必需的,立即初始化一个具有默认值的变量列表:
posted_at = None
applications = None
title = None
company_name = None
company_rating = None
company_reviews = None
location = None
location_type = None
apply_link = None
pay = None
job_type = None
benefits = None
description = None现在你已经熟悉了页面,知道有些详细信息在概述职位卡中。其他信息则在交互时显示的详细信息标签中。
例如,创建日期和申请数量在摘要标签中:
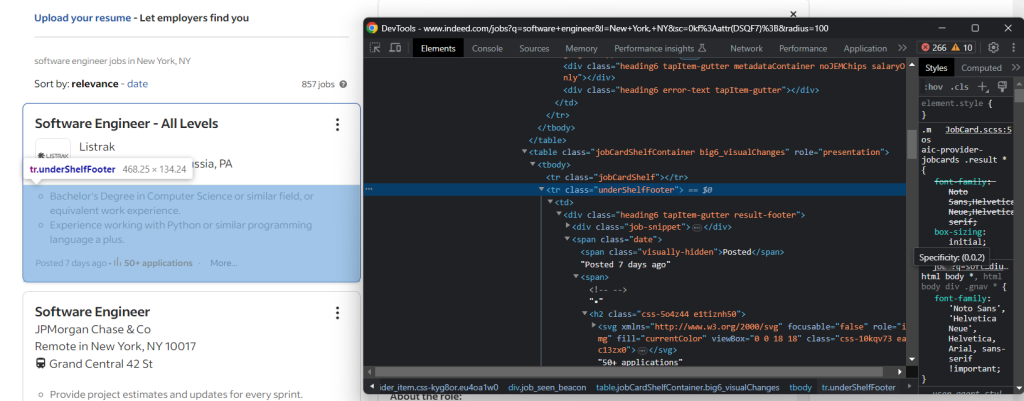
使用以下命令提取它们:
try:
date_element = job_card.find_element(By.CSS_SELECTOR, ".date")
date_element_text = date_element.text
posted_at_text = date_element_text
if "•" in date_element_text:
date_element_text_array = date_element_text.split("•")
posted_at_text = date_element_text_array[0]
applications = date_element_text_array[1] \
.replace("applications", "") \
.replace("in progress", "") \
.strip()
posted_at = posted_at_text \
.replace("Posted", "") \
.replace("Employer", "") \
.replace("Active", "") \
.strip()
except NoSuchElementException:
pass此代码段突出了一些在从Indeed抓取职位数据时关键的模式。由于大多数信息元素是可选的,你必须防止以下错误:
selenium.common.exceptions.NoSuchElementException: Message: no such elementSelenium在尝试选择页面上不存在的HTML元素时会抛出此错误。
使用以下命令导入异常:
from selenium.common import NoSuchElementExceptiontry ... catch指令确保如果目标元素不在DOM中,脚本将继续而不会失败。
此外,一些职位信息包含在如下字符串中:
<info_1> • <info_2>如果缺少<info_2>,则字符串格式为:
<info_1>因此,你需要根据"•"字符的存在来更改数据提取逻辑。
给定一个HTML元素,你可以通过text属性访问其文本内容。使用replace() Python字符串清理收集到的字符串。
步骤6:应对Indeed的反抓取措施
Indeed采用了一些技术来防止机器人访问其数据。例如,当与职位卡片进行交互时,它有时会显示以下模式:
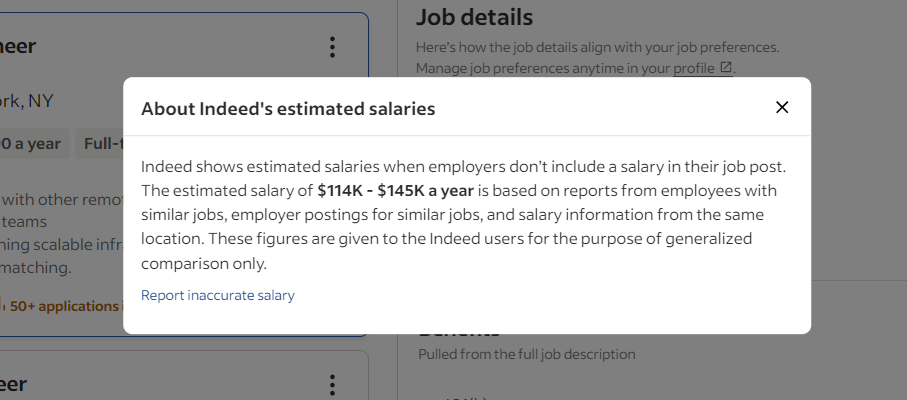
这个弹出窗口阻止了交互。如果未正确处理,它将停止你的Selenium脚本。在开发工具中检查它,并注意关闭按钮:

使用以下命令在Selenium中关闭此模式:
try:
dialog_element = driver.find_element(By.CSS_SELECTOR, "[role=dialog]")
close_button = dialog_element.find_element(By.CSS_SELECTOR, ".icl-CloseButton")
close_button.click()
except NoSuchElementException:
pass来自Selenium的click()方法允许你在受控浏览器中点击所选元素。
太好了!这将关闭弹出窗口并让你继续交互。
另一项数据保护技术需要认真考虑的是Cloudflare。当与页面进行过多的交互并产生过多请求时,Indeed将显示此反机器人屏幕:

在Selenium中解决Cloudflare验证码是一项非常具有挑战性的任务,需要一个高级产品。毕竟,抓取Indeed并不是那么容易。幸运的是,你可以通过在脚本中引入一些随机延迟来避免它们。
确保你的for循环的最后一个操作是:
time.sleep(random.uniform(1, 5))这将使脚本在1到5秒之间随机停止。
使用以下命令导入所需的Python标准库包:
import random
import time太棒了!现在没有任何东西可以阻止你的自动脚本抓取Indeed数据。
步骤7:打开职位详细信息卡
当你点击概述职位卡时,Indeed会执行AJAX调用以即时检索详细信息。在等待此数据时,页面会显示一个动画占位符:

当以下元素出现在页面上时,你可以验证详细信息部分是否已加载:
因此,要在Selenium中访问职位详细信息数据,你需要:
- 执行点击操作
- 等待页面包含感兴趣的数据
通过以下方式实现:
job_card.click()
try:
title_element = WebDriverWait(driver, 5) \
.until(EC.presence_of_element_located((By.CSS_SELECTOR, ".jobsearch-JobInfoHeader-title")))
title = title_element.text.replace("\n- job post", "")
except NoSuchElementException:
continue来自Selenium的WebDriverWait对象允许你等待特定条件发生。在这种情况下,脚本等待最多5秒钟,直到.jobsearch-JobInfoHeader-title出现在页面上。之后,它将抛出一个TimeoutException。
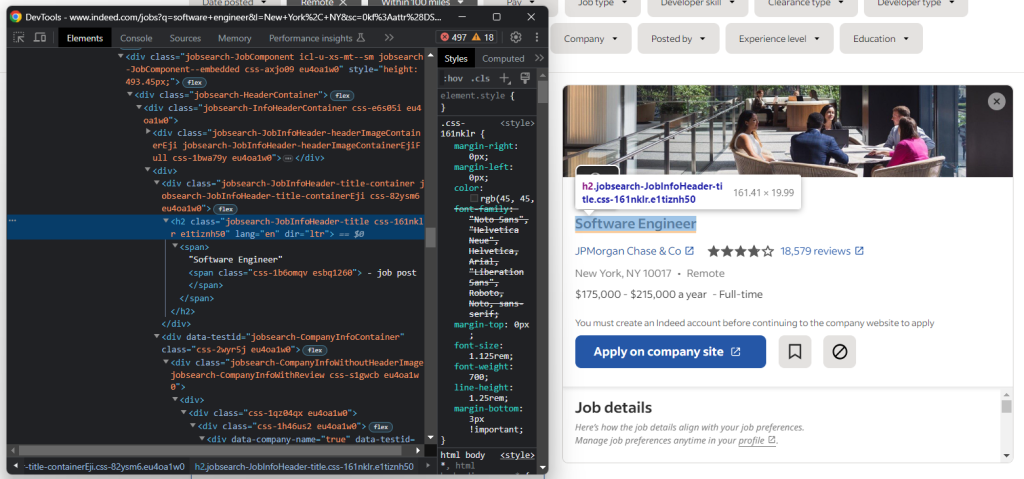
请注意,上述代码段还检索了职位的标题。
使用以下命令导入WebDriverWait和EC:
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC从现在开始,需要关注的元素是此详细信息列:

使用以下命令选择它:
job_details_element = driver.find_element(By.CSS_SELECTOR, ".jobsearch-RightPane")太棒了!你已经准备好抓取一些职位数据了!
步骤8:提取职位详细信息
现在是用一些职位数据填充我们在步骤4中定义的变量的时候了。
获取职位发布背后的公司名称:
try:
company_link_element = job_details_element.find_element(By.CSS_SELECTOR, "div[data-company-name='true'] a")
company_name = company_link_element.text
except NoSuchElementException:
pass然后,提取公司用户评级和评论数量的信息:
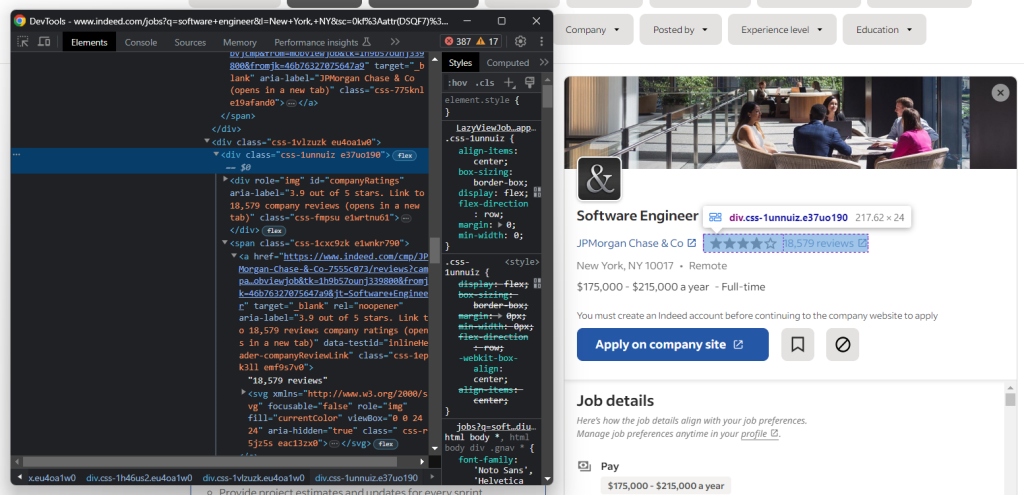
如你所见,没有一种简单的方法来访问存储评论数量的元素。
try:
company_rating_element = job_details_element.find_element(By.ID, "companyRatings")
company_rating = company_rating_element.get_attribute("aria-label").split("out")[0].strip()
company_reviews_element = job_details_element.find_element(By.CSS_SELECTOR, "[data-testid='inlineHeader-companyReviewLink']")
company_reviews = company_reviews_element.text.replace(" reviews", "")
except NoSuchElementException:
pass接下来,关注公司位置:
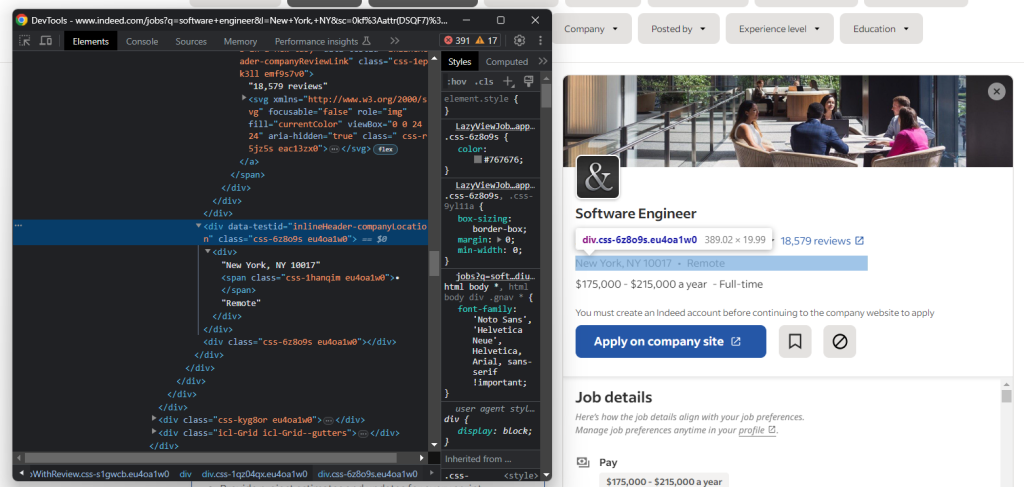
再次,需要应用步骤4中提到的"•"模式:
try:
company_location_element = job_details_element.find_element(By.CSS_SELECTOR,
"[data-testid='inlineHeader-companyLocation']")
company_location_element_text = company_location_element.text
location = company_location_element_text
if "•" in company_location_element_text:
company_location_element_text_array = company_location_element_text.split("•")
location = company_location_element_text_array[0]
location_type = company_location_element_text_array[1]
except NoSuchElementException:
pass由于你可能希望快速申请该职位,请查看Indeed的“在公司网站申请”按钮:
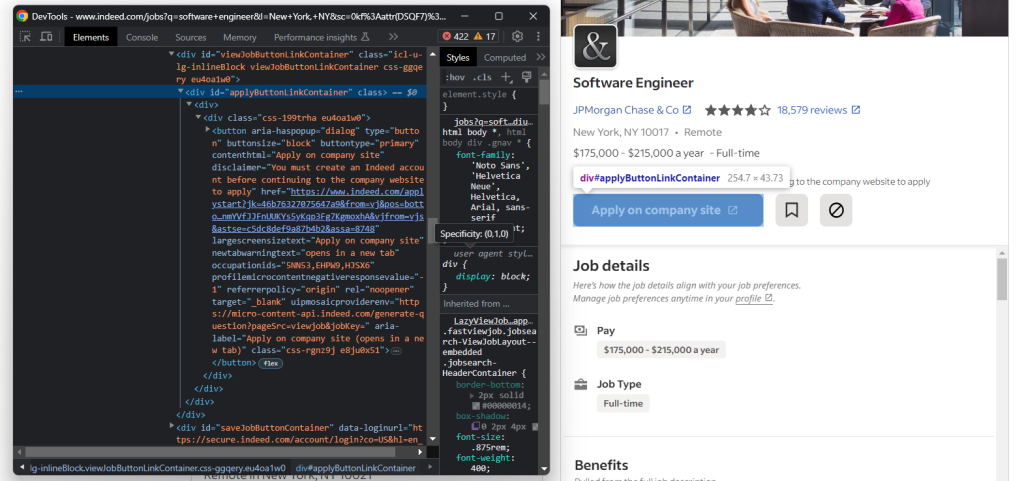
通过以下方式检索按钮的目标URL:
try:
apply_link_element = job_details_element.find_element(By.CSS_SELECTOR, "#applyButtonLinkContainer button")
apply_link = apply_link_element.get_attribute("href")
except NoSuchElementException:
passSelenium的get_attribute()方法返回指定HTML属性的值。
现在,困难的部分开始了。
如果你检查“职位详细信息”部分,你会注意到没有一种简单的方法来选择薪资和职位类型元素:
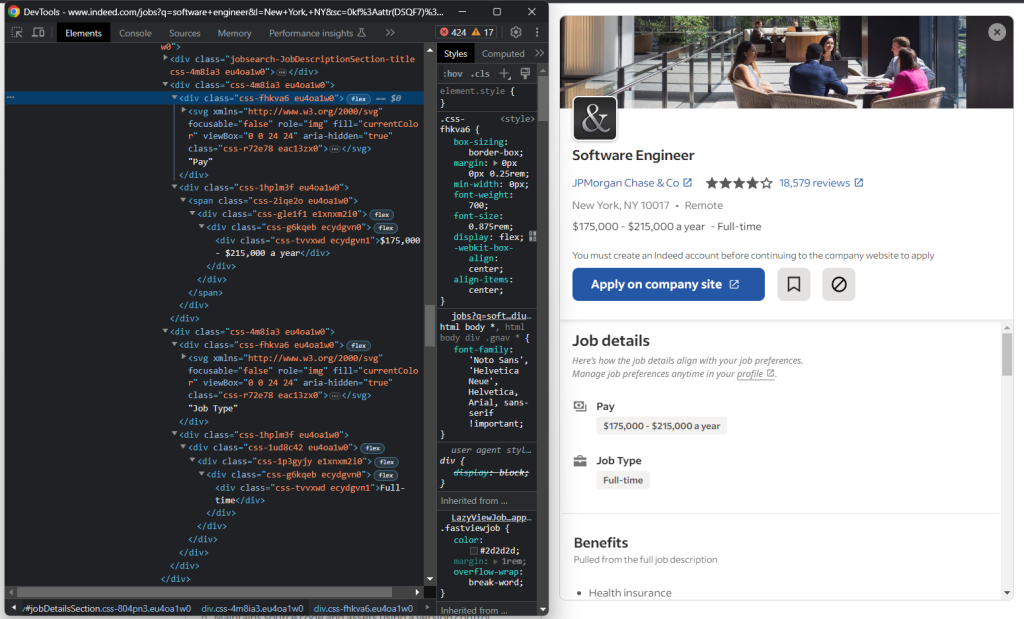
你可以做的是:
- 获取“职位详细信息”
<div>内的所有<div> - 遍历它们
- 如果当前
<div>的文本包含“Pay”或“Job Type”,获取下一个兄弟元素 - 提取感兴趣的数据
换句话说,你需要实现以下逻辑:
for div in job_details_element.find_elements(By.CSS_SELECTOR, "#jobDetailsSection div"):
if div.text == "Pay":
pay_element = div.find_element(By.XPATH, "following-sibling::*")
pay = pay_element.text
elif div.text == "Job Type":
job_type_element = div.find_element(By.XPATH, "following-sibling::*")
job_type = job_type_element.textSelenium不提供用于访问节点兄弟元素的实用方法。你可以使用following-sibling::* XPath表达式。
现在,关注职位的福利。通常情况下,有多个福利:
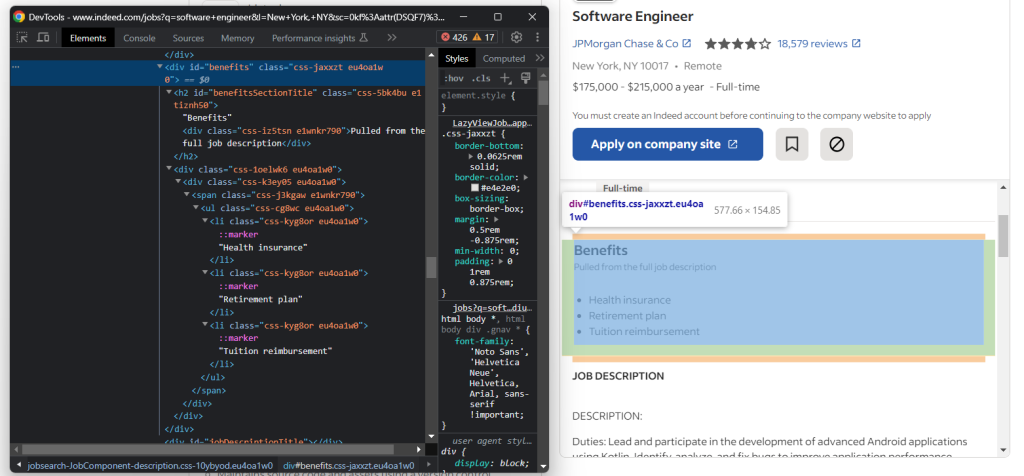
要检索所有福利,你需要初始化一个列表并通过以下方式填充它:
try:
benefits_element = job_details_element.find_element(By.ID, "benefits")
benefits = []
for benefit_element in benefits_element.find_elements(By.TAG_NAME, "li"):
benefit = benefit_element.text
benefits.append(benefit)
except NoSuchElementException:
pass最后,获取职位的原始描述:
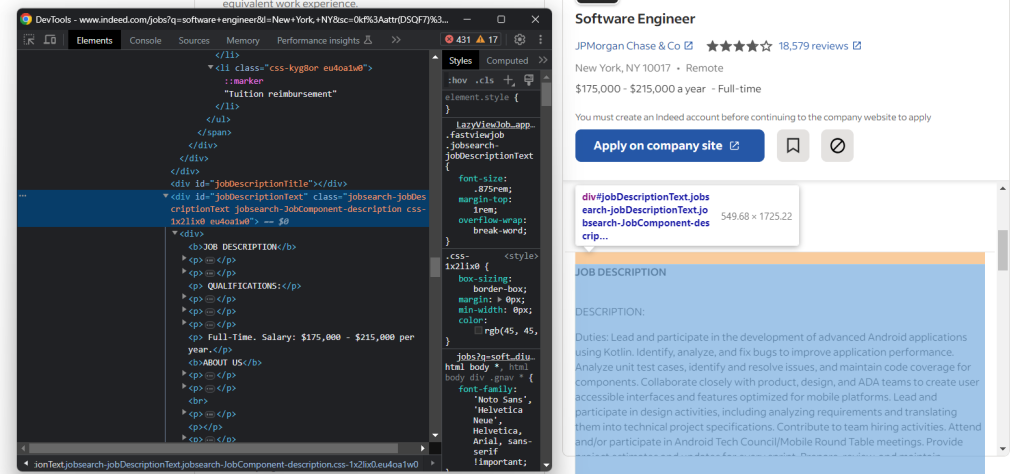
通过以下方式提取描述文本:
try:
description_element = job_details_element.find_element(By.ID, "jobDescriptionText")
description = description_element.text
except NoSuchElementException:
pass填充job字典并将其添加到jobs列表中:
job["posted_at"] = posted_at
job["applications"] = applications
job["title"] = title
job["company_name"] = company_name
job["company_rating"] = company_rating
job["company_reviews"] = company_reviews
job["location"] = location
job["location_type"] = location_type
job["apply_link"] = apply_link
job["pay"] = pay
job["job_type"] = job_type
job["benefits"] = benefits
job["description"] = description
jobs.append(job)你还可以添加一个日志指令以验证脚本是否按预期工作:
print(job)运行脚本:
python scraper.py这将产生类似于以下的输出:
{'posted_at': '17 days ago', 'applications': '50+', 'title': 'Software Support Engineer', 'company_name': 'Integrated DNA Technologies (IDT)', 'company_rating': '3.5', 'company_reviews': '95', 'location': 'New York, NY 10001', 'location_type': 'Remote', 'apply_link': 'https://www.indeed.com/applystart?jk=c00120130a9c933b&from=vj&pos=bottom&mvj=0&jobsearchTk=1h9fpft0fj3t3800&spon=0&sjdu=YmZE5d5THV8u75cuc0H6Y26AwfY51UOGmh3Z9h4OvXiYhWlsa56nLum9aT96NeA9XAwdulcUk0atwlDdDDqlBQ&vjfrom=tp-semfirstjob&astse=bcf3778ad128bc26&assa=2447', 'pay': '$80,000 - $100,000 a year', 'job_type': 'Full-time', 'benefits': ['401(k)', '401(k) matching', 'Dental insurance', 'Health insurance', 'Paid parental leave', 'Paid time off', 'Parental leave', 'Vision insurance'], 'description': "Integrated DNA Technologies (IDT) is the leading manufacturer of custom oligonucleotides and proprietary technologies for (omitted for brevity...)"}太棒了!你刚刚学会了如何从网站上抓取职位发布信息。
步骤9:抓取多个职位页面
典型的Indeed职位搜索会生成一个分页列表,其中包含数十个结果。看如何抓取每个页面!
首先,检查页面并注意Indeed的行为。具体来说,当有下一个页面可用时,它会显示以下元素。
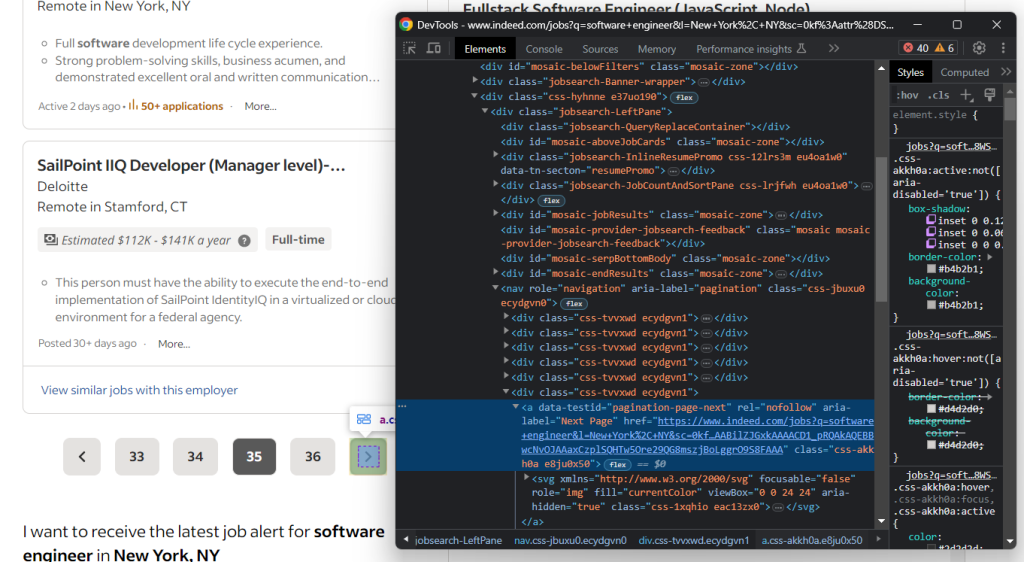
否则,下一个页面元素会消失:
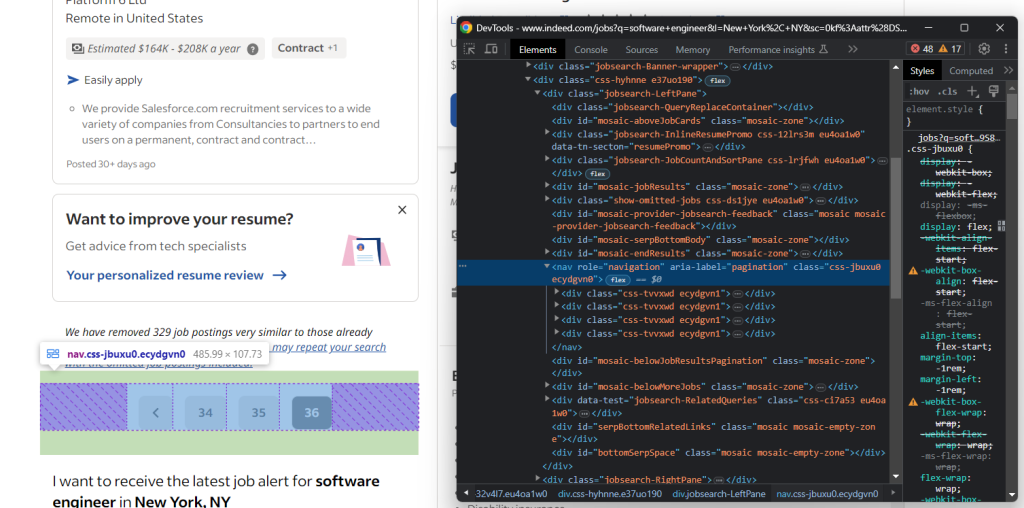
请记住,Indeed可能返回包含数百个职位空缺的列表。由于你不希望脚本永远运行,因此请考虑为要抓取的页面数量设置一个限制。
在Selenium中实现网页爬行:
pages_scraped = 0
pages_to_scrape = 5
while pages_scraped < pages_to_scrape:
job_cards = driver.find_elements(By.CSS_SELECTOR, ".cardOutline")
for job_card in job_cards:
# scraping logic...
pages_scraped += 1
# if this is not the last page, go to the next page
# otherwise, break the while loop
try:
next_page_element = driver.find_element(By.CSS_SELECTOR, "a[data-testid=pagination-page-next]")
next_page_element.click()
except NoSuchElementException:
breakIndeed抓取器现在将保持循环,直到到达最后一页或经过5页。
步骤10:将抓取的数据导出为JSON
目前,抓取的数据存储在Python字典列表中。导出为JSON以便于共享和读取。
首先,创建一个输出对象:
output = {
"date": datetime.now().strftime('%Y-%m-%d %H:%M:%S'),
"jobs": jobs
}date属性是必需的,因为职位发布的发布日期格式为“<X> days ago”。没有有关抓取职位数据的日期上下文,理解它将很困难。
请记得导入datetime:
from datetime import datetime然后,使用以下命令导出它:
import json
# scraping logic...
with open("jobs.json", "w") as file:
json.dump(output, file, indent=4)上面的代码段使用open()初始化一个jobs.json输出文件,并通过json.dump()用JSON数据填充它。请查看我们的文章,了解有关如何在Python中解析和序列化JSON数据的更多信息。
json包来自Python标准库,因此你甚至不需要安装额外的依赖项即可实现目标。
哇!你从包含网页中的原始职位数据开始,现在拥有了半结构化的JSON数据。你已经准备好查看整个Indeed抓取Python脚本了。
步骤11:将所有内容整合在一起
以下是完整的scraper.py文件:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.common import NoSuchElementException
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import random
import time
from datetime import datetime
import json
# set up a controllable Chrome instance
# in headless mode
service = Service()
options = webdriver.ChromeOptions()
options.add_argument("--headless=new")
driver = webdriver.Chrome(
service=service,
options=options
)
# open the target page in the browser
driver.get("https://www.indeed.com/jobs?q=software+engineer&l=New+York%2C+NY&sc=0kf%3Aattr%28DSQF7%29%3B&radius=100")
# set the window size to make sure pages
# will not be rendered in responsive mode
driver.set_window_size(1920, 1080)
# a data structure where to store the job openings
# scraped from the page
jobs = []
pages_scraped = 0
pages_to_scrape = 3
while pages_scraped < pages_to_scrape:
# select the job posting cards on the page
job_cards = driver.find_elements(By.CSS_SELECTOR, ".cardOutline")
for job_card in job_cards:
# initialize a dictionary to store the scraped job data
job = {}
# initialize the job attributes to scrape
posted_at = None
applications = None
title = None
company_name = None
company_rating = None
company_reviews = None
location = None
location_type = None
apply_link = None
pay = None
job_type = None
benefits = None
description = None
# get the general job data from the outline card
try:
date_element = job_card.find_element(By.CSS_SELECTOR, ".date")
date_element_text = date_element.text
posted_at_text = date_element_text
if "•" in date_element_text:
date_element_text_array = date_element_text.split("•")
posted_at_text = date_element_text_array[0]
applications = date_element_text_array[1] \
.replace("applications", "") \
.replace("in progress", "") \
.strip()
posted_at = posted_at_text \
.replace("Posted", "") \
.replace("Employer", "") \
.replace("Active", "") \
.strip()
except NoSuchElementException:
pass
# close the anti-scraping modal
try:
dialog_element = driver.find_element(By.CSS_SELECTOR, "[role=dialog]")
close_button = dialog_element.find_element(By.CSS_SELECTOR, ".icl-CloseButton")
close_button.click()
except NoSuchElementException:
pass
# load the job details card
job_card.click()
# wait for the job details section to load after the click
try:
title_element = WebDriverWait(driver, 5) \
.until(EC.presence_of_element_located((By.CSS_SELECTOR, ".jobsearch-JobInfoHeader-title")))
title = title_element.text.replace("\n- job post", "")
except NoSuchElementException:
continue
# extract the job details
job_details_element = driver.find_element(By.CSS_SELECTOR, ".jobsearch-RightPane")
try:
company_link_element = job_details_element.find_element(By.CSS_SELECTOR, "div[data-company-name='true'] a")
company_name = company_link_element.text
except NoSuchElementException:
pass
try:
company_rating_element = job_details_element.find_element(By.ID, "companyRatings")
company_rating = company_rating_element.get_attribute("aria-label").split("out")[0].strip()
company_reviews_element = job_details_element.find_element(By.CSS_SELECTOR, "[data-testid='inlineHeader-companyReviewLink']")
company_reviews = company_reviews_element.text.replace(" reviews", "")
except NoSuchElementException:
pass
try:
company_location_element = job_details_element.find_element(By.CSS_SELECTOR,
"[data-testid='inlineHeader-companyLocation']")
company_location_element_text = company_location_element.text
location = company_location_element_text
if "•" in company_location_element_text:
company_location_element_text_array = company_location_element_text.split("•")
location = company_location_element_text_array[0]
location_type = company_location_element_text_array[1]
except NoSuchElementException:
pass
try:
apply_link_element = job_details_element.find_element(By.CSS_SELECTOR, "#applyButtonLinkContainer button")
apply_link = apply_link_element.get_attribute("href")
except NoSuchElementException:
pass
for div in job_details_element.find_elements(By.CSS_SELECTOR, "#jobDetailsSection div"):
if div.text == "Pay":
pay_element = div.find_element(By.XPATH, "following-sibling::*")
pay = pay_element.text
elif div.text == "Job Type":
job_type_element = div.find_element(By.XPATH, "following-sibling::*")
job_type = job_type_element.text
try:
benefits_element = job_details_element.find_element(By.ID, "benefits")
benefits = []
for benefit_element in benefits_element.find_elements(By.TAG_NAME, "li"):
benefit = benefit_element.text
benefits.append(benefit)
except NoSuchElementException:
pass
try:
description_element = job_details_element.find_element(By.ID, "jobDescriptionText")
description = description_element.text
except NoSuchElementException:
pass
# store the scraped data
job["posted_at"] = posted_at
job["applications"] = applications
job["title"] = title
job["company_name"] = company_name
job["company_rating"] = company_rating
job["company_reviews"] = company_reviews
job["location"] = location
job["location_type"] = location_type
job["apply_link"] = apply_link
job["pay"] = pay
job["job_type"] = job_type
job["benefits"] = benefits
job["description"] = description
jobs.append(job)
# wait for a random number of seconds from 1 to 5
# to avoid rate limiting blocks
time.sleep(random.uniform(1, 5))
# increment the scraping counter
pages_scraped += 1
# if this is not the last page, go to the next page
# otherwise, break the while loop
try:
next_page_element = driver.find_element(By.CSS_SELECTOR, "a[data-testid=pagination-page-next]")
next_page_element.click()
except NoSuchElementException:
break
# close the browser and free up the resources
driver.quit()
# produce the output object
output = {
"date": datetime.now().strftime('%Y-%m-%d %H:%M:%S'),
"jobs": jobs
}
# export it to JSON
with open("jobs.json", "w") as file:
json.dump(output, file, indent=4)在不到200行代码中,你刚刚构建了一个功能齐全的网页抓取器,以抓取Indeed上的职位数据。
使用以下命令运行它:
python scraper.py等待几分钟,直到脚本完成
在抓取过程结束时,jobs.json文件将出现在你的项目根文件夹中。打开它,你将看到:
{
"date": "2023-09-02 19:56:44",
"jobs": [
{
"posted_at": "7 days ago",
"applications": "50+",
"title": "Software Engineer - All Levels",
"company_name": "Listrak",
"company_rating": "3",
"company_reviews": "5",
"location": "King of Prussia, PA",
"location_type": "Remote",
"apply_link": "https://www.indeed.com/applystart?jk=f27ade40cc1a3686&from=vj&pos=bottom&mvj=0&jobsearchTk=1h9bge7mbhdj0800&spon=0&sjdu=YmZE5d5THV8u75cuc0H6Y26AwfY51UOGmh3Z9h4OvXgPYWebWpM-4nO05Ssl8I8z-BhdrQogdzP3xc9-PmOQTQ&vjfrom=vjs&astse=16430083478063d1&assa=2381",
"pay": null,
"job_type": null,
"benefits": [
"Gym membership",
"Paid time off"
],
"description": "About Listrak:\nWe are a SaaS company that offers an integrated digital marketing platform trusted by 1,000+ leading retailers and brands for email, text message marketing, identity resolution, behavioral triggers and cross-channel orchestration. Our HQ is in (omitted for brevity...)"
},
// omitted for brevity...
{
"posted_at": "9 days ago",
"applications": null,
"title": "Software Engineer, Front End (Hybrid-Remote)",
"company_name": "Weill Cornell Medicine",
"company_rating": "3.4",
"company_reviews": "41",
"location": "New York, NY 10021",
"location_type": "Remote",
"apply_link": "https://www.indeed.com/applystart?jk=1a53a17f1faeae92&from=vj&pos=bottom&mvj=0&jobsearchTk=1h9bge7mbhdj0800&spon=0&sjdu=YmZE5d5THV8u75cuc0H6Y26AwfY51UOGmh3Z9h4OvXgZADiLYj9Y4htcvtDy_iaWMIfcMu539kP3i1FMxIq2rA&vjfrom=vjs&astse=90a9325429efdf13&assa=4615",
"pay": "$99,800 - $123,200 a year",
"job_type": null,
"benefits": null,
"description": "Title: Software Engineer, Front End (Hybrid-Remote)\nTitle: Software Engineer, Front End (Hybrid-Remote)\nLocation: Upper East Side\nOrg Unit: Olivier Elemento Lab\nWork Days: Monday-Friday\nExemption Status: Exempt\nSalary Range: $99,800.00 - $123,200.00\nAs (omitted for brevity...)"
}
}恭喜你!你刚刚学会了如何使用Python抓取Indeed!
结论
在本教程中,你了解了Indeed是网络上最好的职位门户之一以及如何从中提取数据。特别是,你看到了如何构建一个可以从中检索职位空缺数据的Python抓取器。
如本教程所示,抓取Indeed并不是一件容易的事。该站点具有狡猾的反抓取保护措施,可能会阻止你的脚本。当处理此类站点时,你需要一个可控的浏览器,该浏览器能够自动处理验证码、指纹识别、自动重试等。这正是我们新推出的抓取浏览器解决方案的全部内容!
不想处理网页抓取,但对职位数据感兴趣?探索我们的Indeed数据集和我们的职位发布数据集。
不确定需要哪种产品?与我们的数据专家交谈。




