

Google 图片是网络上最难抓取数据的网站之一。虽然该网站没有明确拦截抓取工具,但确实会让您在获取数据时费尽周折……如果想要获取数据,必须付出真正的努力!
相比常规 HTML 抓取,Google 图片的抓取犹如解谜游戏,需要应对动态 CSS 选择器、Base64 编码等各种挑战。
先决条件
要按照本指南抓取 Google 图片,您需要具备 Python 和 Selenium 的基础知识。请确保已安装 Selenium。如有需要,建议您详细了解使用 Python 和 Selenium 抓取网页相关内容。
首先,确保已安装 ChromeDriver 和 Chrome 浏览器。您可以点击此处下载最新版本。
下载 ChromeDriver 时,请确保选择的版本与 Chrome 浏览器版本相匹配。
您可以使用以下命令检查 Chrome 浏览器版本。
google-chrome --version
输出结果应类似于下方内容。
Google Chrome 131.0.6778.139
完成上述步骤后,即可通过 pip 命令安装 Selenium。
pip install selenium
抓取目标
我们不能贸然编写代码,必须先明确抓取目标和提取方法。如前所述,抓取 Google 图片的过程堪比解谜。
我们来分析一张来自 Google 的图片。这张图片实际上嵌入在名为 g-img 的自定义 HTML 标签中。我们需要找出所有这些 g-img 元素。
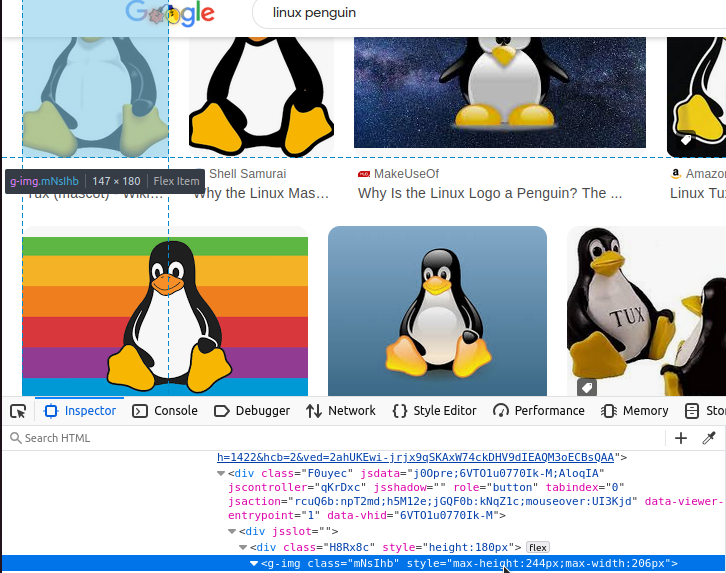
找到所有 g-img 标签后,需要提取其中的 img 元素。下方展示了其中一个示例。
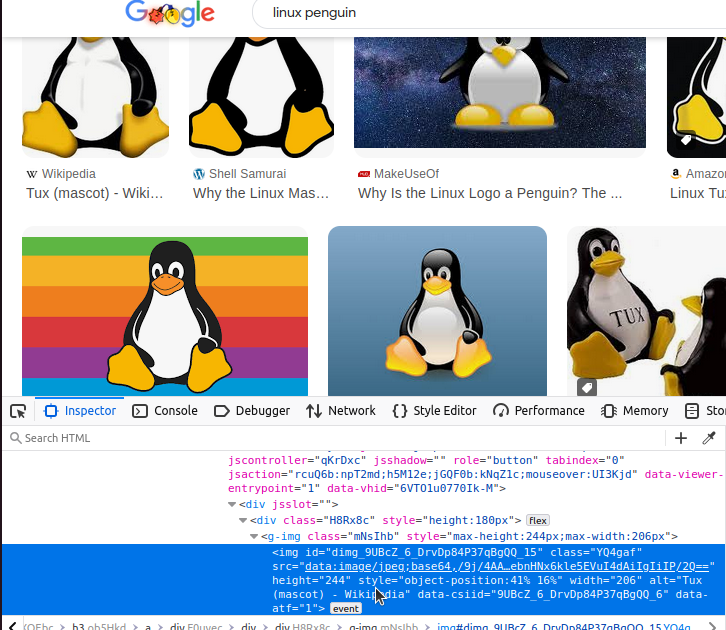
如果仔细查看该 img 元素,就会发现一些不同寻常的特征。它的 src 属性是一个包含大量看似随机字符的奇怪字符串。
data:image/jpeg;base64,/9j/4AAQSkZJRgABAQAAAQABAAD/2wCEAAkGBxAREBUQExAVFhUVFxISEBYXEhISFRAXFRUWFhgWGBUYHSggGBolGxUVITIhJikrLi4uGCAzODMtQygtLysBCgoKDg0OGhAQGzcmHyU1Li8tLzc1LS0tMzAvLSsrLTAwMS0tLS0rLS8tLjAvLy83LS0xLy0tNy0vLS0tLS0yLf/AABEIAPQAzgMBIgACEQEDEQH/xAAcAAEAAgIDAQAAAAAAAAAAAAAABgcFCAEDBAL/xABHEAABAwICBwQFCQUHBAMAAAABAAIDBBEFIQYHEjFBUWETInGRIzJCgaEIFFJicoKSscEzQ6Ky0RUkZJPC4fBjc7PxJTSj/8QAGwEBAAMBAQEBAAAAAAAAAAAAAAEEBQYCAwf/xAAvEQEAAgEDAwICCgMBAAAAAAAAAQIDBAUREiExE0Gh0SIjMjNCUWGBkbFSceEk/9oADAMBAAIRAxEAPwC8UREBERAREQEREBEVI69NYDml2FUzyDYfPXtNjZwuIQeoILrcw36QQZfTvXRT0rnU9ExtRKMnSE+gjPIFpvIR0sM95zCp7GtYmLVRJkrpWjOzIndgwA8LR2uPG5UWRSO2epkedp73OPNzi4+ZXsoserIf2VXPHy2J5GfkVjkQWVo5rpxSnIE5ZVR8Q8COQDkJGD4uDld2hWntDijfQv2ZQLvgfZsrQMiQAbObuzF94vbctbsEwRs0ZPFY2aKejmbLG9zHsO0x7SWuaRxBCgbmIoBqo1hNxSExS2bVxAGQDITNyHatHDMgEcCRzCn6AiIgIiICIiAiIgIiICIiAiIgIiIMXpRjDaKjnq3W9FG54BNtp1rMb73Fo9603qql8sj5ZHFz3uc+Rx3uc4lzifEkrY/5QdcY8IEY/fTxRu+y0Pl/ONq1rQERFIIiIJTguKtgi35rG4ji3bXuFiwxxF7Ej8l8IMjgGMTUVVHVQmz4nBw5OG5zT9UgkHoVuBo/jEVbSxVcR7krA8C4JadzmG2W01wLT1BWlyv75OONF9NUUTj+xe2WL7Mtw5o6Bzb/AH1AuNERAREQEREBERAREQEREBERAREQVB8pJ39yphzncfKN39VSej+j09Y4iMANbbae69h0Ft56K6vlJj+6Uv8A3n/+NeXQinpMMwNmJ1QLw7vRxtteRz3ENB5nLwAbfPcgrTGNEamiaZCGyxW9IACC0c7cLcwclFngXy3cFs9oZpXQYreGShbDKWGRsb2xyNlZexLJABci4uCAc+OdqF1j6PigxOemYD2e0HwD6kgD2tHO1y37qCNsYXENAJJIAAzJJyACn2jugDHgOqHuufYYQA3oXWNz4W9679R2j8dViLzMy7YYi8NNx33Oa0EjlYu+CtPWJp9S4MY6eGlZJM8bewNmNkTLkBziASSSDYDkSSMrhAsR1WFsZmoZXdo0bQikLS2W3sh1hYnrcdQqtxGxeTsbDrkSMsRsOGRyO7Pgtj9C9OosQkFLUUwp5pGudAWPDo6gNF3bLrAhwGeyb5DfwVT67tHjSYiJMtmoZ2gIyu5p2XXHA22fO6CvVaHyd6gtxV7L5PppRbqHxuH5HzVXqxNQjrY0zrFOP4b/AKKRs6iIoBERAREQEREBERAREQEREBERBUPykW/3GmP+II84n/0UVx5r59DqN7RcQVHpvqtD6iJpPvewfeUx+Ue3/wCMgPKqYPOGf+iiOpTSmJsU+F1LC+KQPkaC0vaQ4BskbhwByIvlcnO5F4taKxzPhMRMzxCLarsSkbidEwH1Z/wsexzX+7Zc5THWHo5XYriT6mCNkUbGtgjfJJsumDC4mTZaCWglxsDY2AWewPRqipnSGCEt2y7Nztt7Wn2A/eB/wk71JYVzGr360W6cEdvzlepo+I5uhervBMSwytY+ZscsTwYZnRybTo2uIIcWuAJAcBuByJUL16QyNxuZzvVeyB8PIs7Jrcum216vCOlZtdoGN2yLF2yNojlfesVpPoxS4gwMnYSW3Eb2u2Xx337J3W6EEdFOHf5rMetXt+cfL3+DxbSx+FRur+eokxOgiY5x2KmJzQPZbtNMv3dhrrjldTz5Sc7TUUkYPebHM4jo5zQP5HeSmmhGiOH4W50sbJHzOBaJZHNeWNO8MDQ0NvbfYnrZUnrRr6qfE5ZKiJ0Rs1sLHFp2YhfZs5tw652iSCRckcFvafWYNR93bn+/4Vr47V8wiasDUS62Nw9WTj/83H9FX6m2peXZxykN8iZmnrtQSAfGytPDatERQCIiAiIgIiICIiAiIgIiICIiCt9f8G1gznW9SaF/hcln+tV7q6oWx0zX2G1L33niRchovyA/Mq0ddse1gVV0+buHuqIr/C6o3Vk6okmfCyQgMidM1pzFw9jbeB29yo7hgvnwzWk/9ffT5K0vzZcNKshTi5UZw/HGjuyMc1wyNml4v7s/gstDjMI3F58Ipf1bZcPkw5K24mGra0THZINwXRPK1jS5zgAMySbALES4+45Mhdfm8ho8bC5PwWNmL5HB0rtojNrQLMZ4N59Tcr1fH1ee0PFaS9VRikr3gsOxGObRtSdTf1R03/kqs1v1QfUQj22xnaP1S87Iv4h3mrMZG53qj38Aqw1sYNJDURzlxc2VmyPqOYc2+BDgfe7kt/aNFkrljLavERHb9VfVZadHRWeZQRZXRTEhS11NUk2EU0T3/YDhtj8N1ltCo4JduCRoJdm08V59KtG/mvfabsJt4Lpmc29BXKheqHSIV2FQuJvJCPm017k7UYGy4k79phYb8yeSmigEREBERAREQEREBERAREQEReDHcYgoqd9TO/ZjjF3HiTwa0cXE5AIILr9xZkOEugJ79TJHGwXF7RvbK53gNho++FWmoqgc+pqphuZA2M+MkjXD4ROUY010oqcYre1LXWJEVJC3vdm0mzWgD1nuNrniTyAA2J1b6GjDcPbA6xmkPa1Lhu2yLBgPJosOpueKCM43hDnHtYsnDeN21/usQ2vmZk5r/eCrDxGhLTcDJY8s6fBZ+p27Fnt1T2lZxam1I48ovBPM/wBWM+JFh8Vl6LDHHN5v0G5ZyloXP4LOUWFtbmVGn2zBhnq45n9TJqr3jjxDH4fhFxmLBYbWLoV89w+WOMXlZ6anHEvYD3B9ppc3xcDwU7a2y5WgrNJqOqdE8SNNiMwsvjukslVG2MtAAzPUqR67NF/mOJOlY20NVtTx8mvv6Vn4iHcgJAOCr9ehP9TGlow/EBHI60FTsxSkmwY6/o5D4Elp4WeTwW0S0eWyepPToV1MKOd/95gaACTc1EQsA+/FzcgfceJtAs5ERAREQEREBERAREQEREHTWVUcMbpZHhjGNL3ucbBrQLkkrVrWjp7JitRZpLaWIn5vHu2juMrxxceA9kZcSTI9eOnpqpjhsDj2ELvTuBynlb7OW9jD5uF+DSqmAQXT8n/Q4Pc7FZm3DCY6QHcXbny+71R12uQV7LE6KYcylooKZm6KNjD1cB3nHqXXPvWWUD4liDhYheP+y2XvZe4my+GyZoEUIbuC7EXBcOaDlF8GVvMLrfVMHFBBNeWCipwp8gF5KYiobz2R3ZB4bLi77gWsS3Jqo21DXwvzZKx8Thza9pafgVp1UQOje6Nws5jnMcORabH4hTA617MIxOalnjqYXlskTg9juvEHmCLgjiCQvGikbc6v9NIMVphKyzZWWbUxXziceI5sNjY+I3ghShaaaLaQz4fVMqoHWc3JzbnZlYfWjeOLTb3EAjMBba6LY/DiFJHVwnuvGbT60bhk5juoPnkRkQoGWREQEREBERAREQFDtbGkxw7DJJWOtLIRBTni17wbu6bLQ5w6gc1MVQPyj8W26qmowTaON0z88i6V2y0EcwIz+NBT8UZcbAXK92j9BJPVwwxt2nukaAOGRuSTyABJ6Bc1TOxjDPbeNp5+i3g33/l4q7NQmhojpziUze/NdtOCPViBzdY/ScPJoPFBZdDBJvuQFlGMtxuvpFA4cF008fE+5d6IC+HRAr7RB5JcPaeJXgnwt4zabrNIgjrHuYcxZVRrp0EbsnFqVlrm9bG0ZAn9+B1PrW4na+kVek9O14sQseaMWdE9odG8OY9pF2va4WLSOIIJCkaewBju647J4O4Hx5eK4qaV8Zs4eB4HqCs1pxo47D8QmpMy1rtqEn2o395hvxNjY9WleWmuxuxILxH3mO/tN/UKRiFZ2onS40lb8zkd6GqIa25yjn3MPTa9Q8zsclXeI0ZieWndvaeBB3ELzMeWkOBIIIIINiCNxB4FBvAij+gOP/2hh0FUbbbmbM1srSM7r8uALgSOhCkCgEREBERAREQcOcALk2AzJ5LUvSPFxiGK1FaT6Lbc5u/9lGNlmR3EtaMuZV6a7dJ/mWGuia601VeCPmGW9K/3NOzfgXtWt0g7OnA4ym5+yy2XmR5IPdo3hUmJ4jFT5gzSd8j93GM3kfZY028AtvaWnZFG2JjQ1jGtZG0ZBrWgBoA5AAKkPk4YJd9TXuHqhtNEerrPk99hH+Iq9EkERFA4Llyul57wXcgIiICIiAuCLrlEFM/KHwhtqWuAFw51NIbZkEGSPPoWy/iVS1lcx0eytiddFF2uCVOWcfZSt6bEjdo/hLlqupgZk+mpL+1CdnrsHNv6j3LDLL4FmydvNgPkf91iCpF3fJuxuzqmgcd9qqIdRaOTP/K8irzWpeqnFfmuMUr72a+TsH8iJh2Yv0DnNPuW2igEREBERAXBK5UA126Quo8Ke1htJUOFM0je1rgTI78LS3xcEFG61NKv7SxF8jXXhi9DTcixpN3/AHnXN+WyOCj2LO/ZjlG34ucV5IIi9waOKymk1EYnRA8Ym+Yc4H9PNSNktTeGfN8GphazpQ6of17RxLT+DYHuU1XhwOkENLBCBYRxRRjpsMa39F7l5BERB0O9cLvXT7a7kBERAREQEREEf1gx7WE1w/w1QfwxuP6LUBbg6futhVcf8LUjzicP1WnymBmcDyinf9VjR7yT+iwyy7z2dG1vGRxefAd0flf3rEKR9wTOY5r2mzmkOaeRabg+YW7FFUCWNko3Pa148HAEfmtJFuJoG8nCqEnf81pb/wCUxQM6iIgIiICp/wCUlA40dLJ7LZnMPi+MkfyOVwKJ6cVEbwylLWvO0yV1wDsbJuwjk6+fu6r4anUVwY5yW9nvHjm9orDWCPRyv2O1bSzbO8ERuv47O+3Wy7p3uqaexzkhubcS0+sLcxYHzWwjGCyg+n+inaA1lMNmdgu8NH7do4EfTHA8d3K2LpN+jJk6MteInxPz+a5l0XTXms8r3CKktVutwEtosQeBubBUE5dGSnh0f581dq6BQEREHQD313rot313oCIiAiIgIiwOPY/2EjYWgFxbtuJuQ0EkDLiTY+XVfLPmphpN7+IeqUm88Q8OtepEeC1jucXZ/wCY9sf+paq0tJtDac8MbzOZPQDitl9ML4hQyUsr9hjtlz3Mb3gI3B+4m29oWsL3X8BkOgXy0muxarn0/bz24esmK2P7TL1vZTEWl2Q0BrRa4sBYZ3XWzAZnC8Za/wAHWPkVilksCqZGSAtdYceSuPm8E8LmOLXNLSN4IstzdHKE09HT053xQwxHxZG1p/Ja46P4f/aWJQNsOzhfHJUvO4Rh4Jb1LrW+PBbPNcCLg3BzBGYK8Res2msT3jzCeJ45coiL0h0VtZHCwySODWjj+gHErAHTOG+UMpHOzBf+JebTtxLoWcO+4jmRsgeQJ81iooQBuXO7nu2TBlnHj9mhp9LS9OqzL1emeVo4DtcC8gAe5u/zCjtOHve6WQkucbuJ4/8AOS93ZDkvprQFharcc2oji8rmPDTH9mHIXzI24X2ioPspLWZo183m+cxt9HKe+AMo3/0dv8b8ws5qv1sPoQ2krC6SmFmxvzdJSjgLb3xjlvA3XsAp/jeGMqIXwvF2vBH/AK6/0WvWMYa+mmfA/e05G1g4cHDxC7XZtd6+L07far8YZGrw9FuqPEtzKOqjmjbLE9r2PAcx7SHNcDxBC7lqfoBrAqsKk7pMlO43lgc47J+sw+w/qMjxBsLbN6M6Q02IUzaqnftMdkQcnxuG9j28HC48bgi4IK2VRky3O6+kRQCIiAiIg65JQ3eoHpZIHVzSOMTPg+RSjFnFQzGf/ss+wP5nLO3WP/NP7LOk+8h94iCYXN+k1zfMWWtUsZa4tcLFpLXDiCDYhbNTsu1QHSTQqCoeZM2PPrObazurmneeossXaNZTBNov4ld1WGckRNfZUK76GmllkbFE0ue82a1u8/7deCndNq2G136gkcmxhp8y4/kp9ozo7T0gtFGAT6zjm93i48OgyWvqN3w46/Q7z8FTHo72n6XaDQnRltBS7BIMr7PneOJG5oP0W3PvJPGysDQ6pc5kkZN9hwI6B98vMOPvWEAyWQ0YnEczmHLtALfabew8ifJYm3am062L3nvbmJ/fx8eFvUY49GYiPCWIiLsGSienbbGB3WRvmGn9CsXEclltYB9FF/3f9Dv9lhqX1QuL32vGpmf9f02NHP1UO5ERYq0IiIOCFXmtXRvtYvnUbe/H69hm5m8+W/z5qxF1zRhwIIyORVjSam2nyxkr7PnlxxesxLV9WVqEx2SDFG0oJMdU17Xt4B8bHSMf491zfvdFzWap6qeolFI+HZB2hG97mPa08R3bFoOW+4y6XsDVZqpfh0/z2qkY+YNc2FkdyyLaFnPLiAS7ZJFgLC533y/QsOauWkXp4lh3rNZ4laiIi9vIiIgIiIMTi7VXc2KxVFU7snbQi9C5w9UvaS52yeIG0BfmCsBrc1oNkLqKhku3Ns9Q05O4FkR5c38eGWZxurNlqdvUvP8AER+izt1njTys6SPrFnNbcLyzUy9cO5fdlxkTw12OjpF7YorLssuUm0yC65WX/MdF2IoQzeC47tWimNnbmv3B/Q8nfms+q/nAsu/CNKexJjlJcy3cO9zTyvxFr+Fl0u3btM8Y838/P5qGfSfip/D602qhJURwA/swXP8AtPtYeIAv95eaJtgsBHXF8z5Hes5znHpc7vdu9yzMdUCsPcsts2abrmCnRSIelF8NkBX1dZz7OUXC5QFwuUQYrEZZIXNniNnxm45EcWkcQdynej+PQVkYdG4bYAMse0C+I8iN9rg2PFQvExdpVU6ZCSIiohkfHJGe69j3MeA7I2c0gjOy6TY9TNZ9OfEqOsxRMdTZ9FrPgmunFoAGyujqG/8AUZsvAtuD47eZBUrpflAN/eYaR1ZUg/wmMfmuq4Za7UVK1PygIx+zw5x+1UBtvcGG6jONa8MTmBbCyGnB3FrTLIPvP7v8KDYDHMcpaKIzVM7ImDcXHNxtezWjN7ugBK191ka2Zq8OpaYOhpjdrze0tQOIdb1WH6I38TnYV7imJz1MhlnmfK8+095ebb7C+4Z7hkvIgK49B4NmKNvJrb+Nrn4qn4WbTg3mQPM2V2aMEZLH3m31cQu6KPpTKaw7l9rriOS+7rkWk5XBK+XyALH1dcBxUxWZS9z5gF55a5o4qOVuL9V78G0crauztnsoz7cgIuObWb3fAdVcw6LJlniIfO+StPMuK7FhbepLodo24g1FSz1haONwzAJB2nDgchYeKzGBaJU1KQ+xkkH7x9iQfqt3N/Pqs+uh0W11xT1X7z+TPzarqjiqI43oOyWR0sMnZucS5zS3aYSd5GYLbnx8FG63Ryvgz7LtGjjGdv8Ahyd8FaSKzn23Bl7zHE/o+dNTkoppuJFp2XXBG8EEEeIK9UeKjmrTq6GKUWkiY8cnMa63msDW6C0Ml9lj4yeMbyP4XXaPJZeXYv8AGVquuj3hFI8SB4r1x1bTxX1XaupRnBVA8myNLf423/lUexDCsQpM5IHFo9tnpGW5nZzaPEBZ2bZ8tO/D711VLe6TB4XDngKJ0uOg8V6H4uLb1nTpbxPh94tDIYlUCxVcaVh8rXRxsc97rBrWNL3HMbmjMrOYrjAsc1OdU+jkkYdXzNLXSt2IGnItjJDi8jhtENt0H1lu7VpLReLSqarLHTwo6h1cYzMLsw+YfbDYfhIWrJxanscIzpWt8aiD/S4raRF1DKauSanMbAypmHoKiDPzcF459VmNs30Dz9mSB/8AK8ra9EGm1ZoriMN+0oKlgG8mnlDfxWssOVvCvBiWC0tSLT00Mo/6kTJLeG0MkGmdCfSx/bZ/MFa2A1lrKxMW1O4PMdpkT4HXvtQyEC4+o/aaB0ACqrGMPnw+pdTygggkxutZsrL917eYPwNxwWbuOGclYWtLfplYVPiAtvXY6v6qCUuL5b16XYt1XN20dolpxkqklViXVYhjpqmUQwtL3u3AcBxJPADmV4sNhqK2YQQN2nH1jubGPpPd7I/PcLq59FdGoaGLYb3pHWM0hFnSHkOTRwH5m5Wlott6p5t4V8+piscR5Y3RfQeGmtLNaWbfci7Iz9Rp3n6xz5WUtRF0NMdaRxWGZa02nmRERe3kREQEREBERBH8a0Moaolz4th53yRns3E8zbJx+0Cqb0ioBT1HYse4tva7iCd/QAfBEVLV46cc8d1jDaeeOVi6GaCUIayqe10r/WaJCHMYRxDAACftXtwU/RFapWKxxEPjaZme4iIvbyIiICIiAvBjOC01ZH2VRC2Ru8XGbTuu1wzaeoIREFO6faF01B3oXy55hrnNcG9B3b28SV1avdFYK93pnyADOzHNaHW4G7SfIhcoqk46+rxw+8Wno5XPhGEU9JH2UETY27zbe483OObj1JK9yIrcRw+AiIgIiIP/2Q==
该字符串的开头部分(data:image/jpeg;base64,)揭示了关键信息,其中 jpeg 表明这是 JPEG 文件,base64 则表明使用了 Base64 编码方式。对该字符串进行解码,实际上会得到图片的二进制数据。由于图片的二进制数据直接嵌入在网页中,我们无法追踪图片的真实来源。但是,我们可以通过将二进制数据写入文件来还原图片。
使用 Python 抓取 Google 图片
明确抓取目标之后,即可着手编写抓取工具代码了。在接下来的章节中,我们将逐步构建抓取工具,并详细讲解代码的功能。
立即开始
首先,创建新的 Python 文件。我们先从基本的导入语句和结构开始。
from selenium import webdriver
from selenium.webdriver.common.by import By
from time import sleep
import base64
from pathlib import Path
options = webdriver.ChromeOptions()
"""
Our actual scraping logic will go here
"""
if __name__ == "__main__":
scrape_images("linux penguin", 100)
- 从 Selenium 中导入
webdriver和By,其中webdriver用于控制浏览器,By用于查找页面上的元素。 - 使用
sleep让抓取工具暂停一段时间。例如,如果想让抓取工具等待一秒钟,可以使用sleep(1)。 - 想必您已经猜到,
base64将用于解码图片二进制数据。 - 使用
Path将图片写入存放结果的文件夹。 - 通过
options = webdriver.ChromeOptions(),在 Selenium 中使用自定义设置。这主要是为了确保 Selenium 以无头模式运行。通过无头模式,我们可以在不渲染实际浏览器界面的情况下运行抓取工具,这样可以节省宝贵的资源。
抓取 Google 图片
接下来,我们将编写抓取函数。下方代码包含了整个抓取工具的实现。请特别关注 scrape_images()。
from selenium import webdriver
from selenium.webdriver.common.by import By
from time import sleep
import base64
from pathlib import Path
options = webdriver.ChromeOptions()
def scrape_images(keyword, batch_size, headless=True):
if headless:
options.add_argument("--headless")
formatted_keyword = keyword.replace(" ", "+")
folder_name = keyword.replace(" ", "-")
output_folder = Path(f"results-{folder_name}")
output_folder.mkdir(parents=True, exist_ok=True)
result_count = 0
driver = webdriver.Chrome(options=options)
driver.get(f"https://www.google.com/search?q={formatted_keyword}")
sleep(1)
list_items = driver.find_elements(By.CSS_SELECTOR, "div[role='listitem']")
list_items[1].click()
while result_count < batch_size:
driver.execute_script("window.scrollBy(0, 300);")
sleep(1)
img_tags = driver.find_elements(By.CSS_SELECTOR, "g-img > img")
for img_tag in img_tags:
src = img_tag.get_attribute("src")
if not src or not src.startswith("data:image/"):
continue
base64_binary = src.split("base64,")[-1]
mime_type = src.split(";")[0].split(":")[1]
file_extension = mime_type.split("/")[-1]
if file_extension == "gif":
continue
alt_text = img_tag.get_attribute("alt") or "image"
filename = f"{alt_text}-{result_count}.{file_extension}"
image_binary = base64.b64decode(base64_binary)
output_path = output_folder.joinpath(filename)
with open(output_path, "wb") as file:
file.write(image_binary)
result_count+=1
print(f"Saved: {filename}")
driver.quit()
if __name__ == "__main__":
scrape_images("linux penguin", 100)
- 将
headless设置为默认值True。如果将其设置为False,则会在屏幕上显示一个真实的浏览器窗口。这对调试非常有用。 - 删除实际
keyword中的空格,创建formatted_keyword和folder_name,这样可以避免文件存储时出现问题。 - 使用
webdriver.Chrome(options=options)启动浏览器。 - 使用
driver.get(f"https://www.google.com/search?q={formatted_keyword}")跳转到keyword对应的 Google 搜索结果页面。 - 接下来需要点击图片选项卡,只需找到所有具有 role=
listitem属性的div元素即可。然后使用list_items[1].click()点击第二个元素,即图片选项卡。 - 使用
while循环反复运行抓取代码,直至找到所需的全部图片。 - 使用
driver.execute_script("window.scrollBy(0, 300);")运行 JavaScript 代码,将页面向下滚动 300 像素。滚动后,使用sleep()暂停一秒钟,等待内容加载。 - 使用
driver.find_elements(By.CSS_SELECTOR, "g-img > img")查找所有嵌套在g-img标签中的img标签。 - 接下来,遍历找到的所有
img元素。 - 如果
img的 src 属性不是以data:image/开头,则可以使用continue跳过该元素;否则,就提取其src属性。 - 使用基本的字符串分割方法提取编码后的二进制数据和文件扩展名(如 JPEG、PNG 等)。如果扩展名是 GIF,则跳过。由于某些原因,GIF 图片在写入文件时无法显示。
- 使用
base64.b64decode(base64_binary)将图片解码成机器可读的二进制数据。
运行代码后,项目文件夹中会出现一个新文件夹,其中应该包含了所有下载的图片。
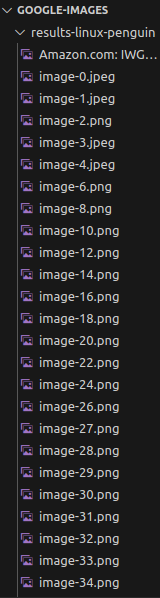
建议使用 Bright Data
我们的 SERP API 可解析 Google 图片,省去了您自己解析的麻烦。它甚至能提取图片元数据,让图片保持其原有的名称。当然,该 API 完全可扩展,能够处理海量请求。
首先,注册我们的 SERP API。
准备就绪后,完成 zone 的创建。
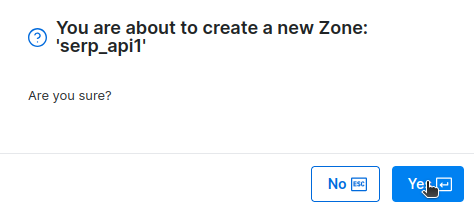
在“访问详情”下,找到凭据信息。
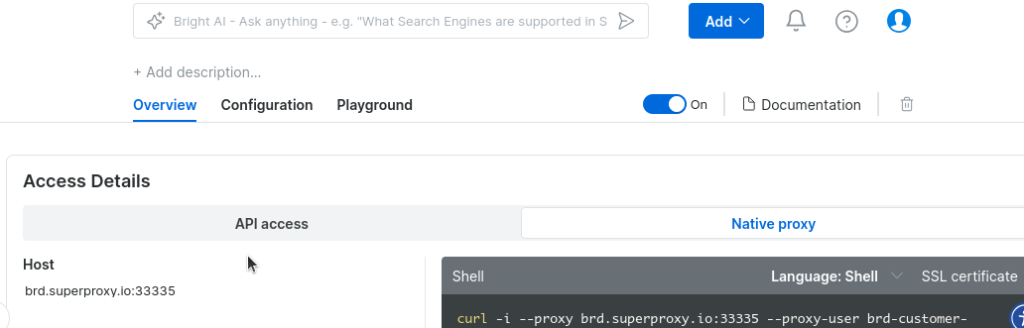
将以下代码复制并粘贴到 Python 文件中。将 proxy_auth 中的凭据替换为您自己的凭据,即可运行。
import requests
import base64
from pathlib import Path
import json
proxy = "brd.superproxy.io:33335"
proxy_auth = "brd-customer-<your-customer-id>-zone-<your-zone-name>:<your-zone-password>"
proxy_url = f"http://{proxy_auth}@{proxy}"
def scrape_images(keyword):
formatted_keyword = keyword.replace(" ", "+")
folder_name = keyword.replace(" ", "-")
output_folder = Path(f"serp-results-{folder_name}")
output_folder.mkdir(parents=True, exist_ok=True)
url = f"https://www.google.com/search?q={formatted_keyword}&tbm=isch&brd_json=1"
response = requests.get(
url,
proxies={"http": proxy_url, "https": proxy_url},
verify=False
)
images = response.json()["images"]
result_count = 0
for image in images:
image_binary = base64.b64decode(image["source_logo"].split("base64,")[-1])
title = image["title"].replace(" ", "-").replace("/", "").strip(".")
file_extension = image["source_logo"].split(";")[0].split(":")[1].split("/")[-1]
if file_extension == "gif":
continue
filename = f"{title}.{file_extension}"
with open(output_folder.joinpath(filename), "wb") as file:
file.write(image_binary)
print(f"Saved: {filename}")
if __name__ == "__main__":
scrape_images("linux penguin")
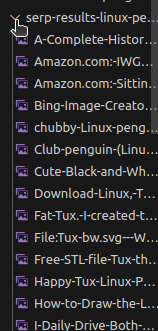
运行代码后,您会再次获得一堆图片。不同的是,这次的图片都带有名称。
结语
总而言之,Google 图片的抓取过程就像是在缺少部分拼图的情况下解谜。我们的 Google Images API 能够获取元数据,无需使用 Selenium!
如果您需要从其他来源抓取图片,我们还提供 Instagram Image API、Shutterstock Scraper和各种结构化数据集。立即注册,寻找最适合您需求的产品,更有免费试用等着您!



