

所有数据都很有价值,而聚合数据是网上最受欢迎的数据类型之一。Google Finance包含大量不同金融市场的聚合数据,可用于从交易机器人到各类报告等多种用途。
让我们开始吧!
先决条件
如果你拥有合适的技能,便可以比较轻松地从 Google Finance 抓取数据。你需要具备以下条件来爬取 Google Finance:
- Python:只需要对 Python 有基础了解即可。你应当知道如何处理变量、函数和循环。
- Python Requests:这是 Python 标准的 HTTP 客户端,用于在网络上发起 GET、POST、PUT 和 DELETE 请求。
- BeautifulSoup:BeautifulSoup 为我们提供了一个高效的 HTML 解析器,用于提取网页中的数据。
如果你尚未安装 Requests 和 BeautifulSoup,可以通过以下命令进行安装:
安装 Requests
pip install requests安装 BeautifulSoup
pip install beautifulsoup4从 Google Finance 抓取哪些内容
下图展示的是 Google Finance 的主页截图,其中包含了许多市场信息的简要概览。我们需要的是关于多个市场的详细信息,而不仅仅是这些简略的数据。
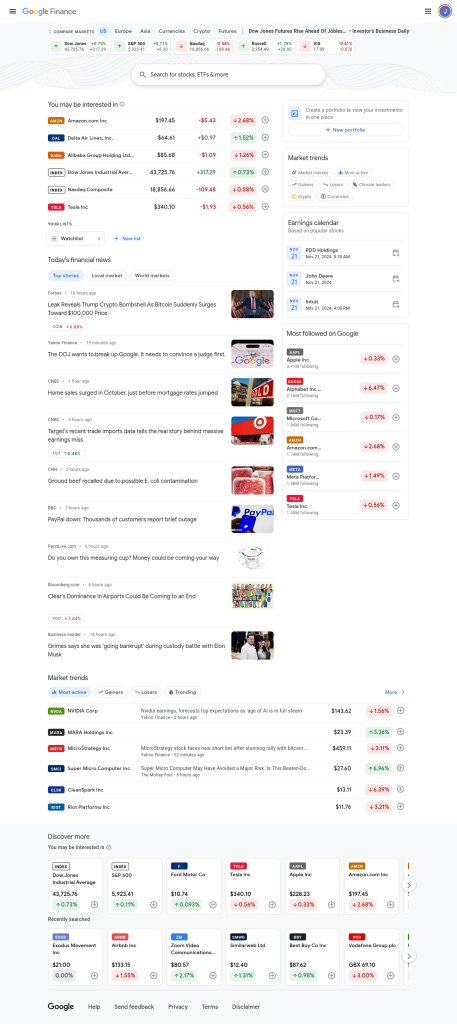
如果你向下滚动页面,会在右侧看到一个名为“Market trends”(市场趋势)的区域。该区域中每一个气泡链接都指向关于特定市场的详细信息页面。我们感兴趣的是以下几个市场:Gainers(涨幅)、Losers(跌幅)、Market indexes(市场指数)、Most active(最活跃)以及Crypto(加密货币)。
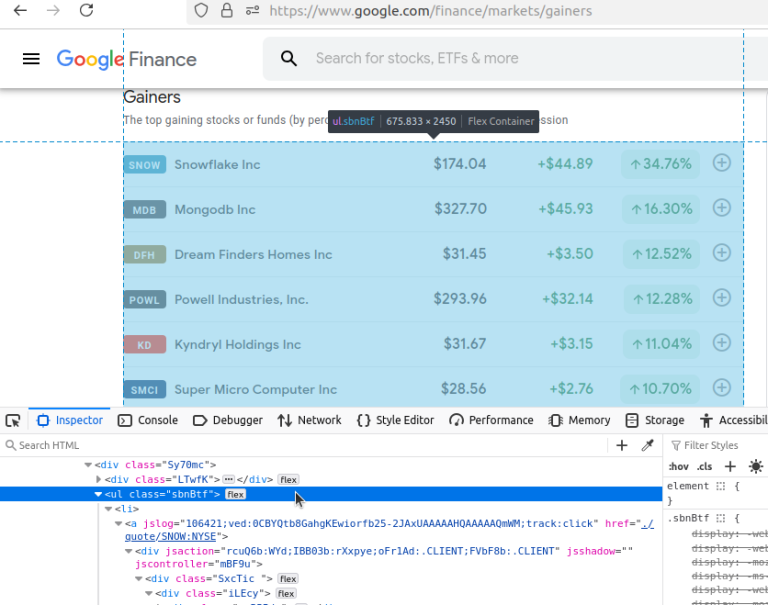
接下来,我们将点击这些页面进行查看。先从Gainers开始。注意地址栏中的网址是:https://www.google.com/finance/markets/gainers。如果你查看开发者控制台,你会发现所有数据都嵌在一个ul(无序列表)中。
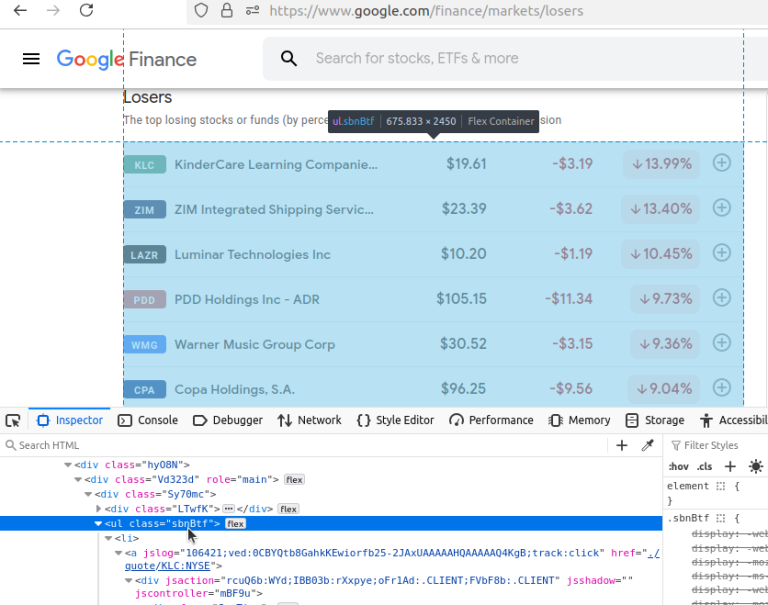
现在,我们再来看看Losers(跌幅)。网址是:https://www.google.com/finance/markets/losers。同样,这里面的数据同样由一个无序列表来呈现。
以下是Market indexes(市场指数)页面的截图。这个页面有点特殊,它包含多个ul元素,需要在代码中做一些适配。网址是:https://www.google.com/finance/markets/indexes。你是不是开始注意到它们都有相似的模式了?
Most active(最活跃)页面如下所示。依旧是目标数据被嵌在ul中。网址是:https://www.google.com/finance/markets/most-active。
最后,我们来看一下Crypto(加密货币)页面。和之前类似,数据位于一个ul中。网址是:https://www.google.com/finance/markets/cryptocurrencies。
以上页面的目标数据都包含在无序列表ul中。要提取数据,我们需要定位ul元素,然后从中获取li(列表项)。观察一下基础网址:https://www.google.com/finance/markets。每个页面都来自markets这个路由端点,其对应的格式是:https://www.google.com/finance/markets/{NAME_OF_MARKET}。我们一共有 5 个数据集和 5 个网址,结构都相同。这样只需通过少量变量就能抓取大量数据。
使用 Python 手动爬取 Google Finance
如果你能避免被阻拦,就可以使用 Python 的 Requests 和 BeautifulSoup 抓取 Google Finance。我们不仅要爬取数据,还需要存储数据。我们有多个端点,但它们都来自同一个基础网址:https://google.com/finance/markets/。每次抓取页面时,都需要找到ul元素并提取每个ul中的所有li元素。
下面我们来介绍脚本中用到的基础函数:write_to_csv()和scrape_page()。顾名思义,这两个函数分别用于“写入 CSV 文件”和“抓取页面”。
独立函数
先看一下 write_to_csv():
def write_to_csv(data, filename):
if type(data) != list:
data = [data]
print("Writing to CSV...")
filename = f"google-finance-{filename}.csv"
mode = "w"
if Path(filename).exists():
mode = "a"
print("Writing data to CSV File...")
with open(filename, mode) as file:
writer = csv.DictWriter(file, fieldnames=data[0].keys())
if mode == "w":
writer.writeheader()
writer.writerows(data)
print(f"Successfully wrote {filename} to CSV...")- 该函数接收一个由
dict组成的列表,如果参数data不是list,则将其转换为list。 - 生成的文件名称加上“google-finance-”前缀,例如
filename = f"google-finance-{filename}.csv"。 - 默认使用写入模式
"w",但如果文件已经存在,则改用追加模式"a"。 csv.DictWriter(file, fieldnames=data[0].keys())用于初始化 CSV 写入器。- 如果是写入模式(文件尚不存在),则通过
writer.writeheader()写入表头。 - 最后使用
writer.writerows(data)将列表数据写入 CSV 文件。
下面来看主要的爬取函数 scrape_page(),这里是核心流程。我们将请求发送到一个格式化后的 URL,然后用BeautifulSoup解析返回的 HTML。接着,我们创建一个名为scraped_data的空list来保存提取到的数据。我们先获取页面中的所有ul元素,再从ul中提取li。需要注意的是,每个li中的文本嵌套在多个div元素内部,并且我们提取到的列表会包含一些重复内容。为此,我们只取第3、6、8和11项,并将它们append()到scraped_data。
下面是 scrape_page() 函数:
def scrape_page(endpoint: str):
response = requests.get(f"https://google.com/finance/markets/{endpoint}")
soup = BeautifulSoup(response.text, "html.parser")
tables = soup.find_all("ul")
scraped_data = []
for table in tables:
list_elements = table.find_all("li")
for list_element in list_elements:
divs = list_element.find_all("div")
asset = {
"ticker": divs[3].text,
"name": divs[6].text,
"currency": divs[8].text[0] if endpoint != "cryptocurrencies" else "n/a",
"price": divs[8].text,
"change": divs[11].text
}
scraped_data.append(asset)
write_to_csv(scraped_data, endpoint)- 发送 GET 请求到
requests.get(f"https://google.com/finance/markets/{endpoint}")。 - 使用 BeautifulSoup 的 HTML 解析器:
soup = BeautifulSoup(response.text, "html.parser")。 - 查找页面上的所有
ul元素:tables = soup.find_all("ul")。 scraped_data = []用于存储抓取结果。- 循环遍历所有
ul,对每个ul做以下操作:- 查找所有
li:table.find_all("li")。 - 再循环遍历所有
li并找到其内部的所有div元素,得到divs。 - 从
divs的第3、6、8和11项提取文本,组合成一个dict。 - 如果是加密货币(cryptocurrencies),则其
currency字段改为n/a。 - 将
dict添加到scraped_data列表里。
- 查找所有
- 完成数据解析后,调用
write_to_csv(scraped_data, endpoint)将结果保存到 CSV 文件,文件名即端点名称。
抓取 Google Finance 数据
我把上面的函数放进一个脚本,从而让一切运行起来。除了上述函数外,我们还维护了一个endpoints列表,并在main函数中执行它。你可以复制下面的代码试着跑一下!
import requests
from bs4 import BeautifulSoup
import csv
from pathlib import Path
endpoints = ["gainers", "losers", "indexes", "most-active", "cryptocurrencies"]
def write_to_csv(data, filename):
if type(data) != list:
data = [data]
print("Writing to CSV...")
filename = f"google-finance-{filename}.csv"
mode = "w"
if Path(filename).exists():
mode = "a"
print("Writing data to CSV File...")
with open(filename, mode) as file:
writer = csv.DictWriter(file, fieldnames=data[0].keys())
if mode == "w":
writer.writeheader()
writer.writerows(data)
print(f"Successfully wrote {filename} to CSV...")
def scrape_page(endpoint: str):
response = requests.get(f"https://google.com/finance/markets/{endpoint}")
soup = BeautifulSoup(response.text, "html.parser")
tables = soup.find_all("ul")
scraped_data = []
for table in tables:
list_elements = table.find_all("li")
for list_element in list_elements:
divs = list_element.find_all("div")
asset = {
"ticker": divs[3].text,
"name": divs[6].text,
"currency": divs[8].text[0] if endpoint != "cryptocurrencies" else "n/a",
"price": divs[8].text,
"change": divs[11].text
}
scraped_data.append(asset)
write_to_csv(scraped_data, endpoint)
if __name__ == "__main__":
for endpoint in endpoints:
print("---------------------")
scrape_page(endpoint) 运行上面的代码后,输出结果类似如下:
---------------------
Writing to CSV...
Writing data to CSV File...
Successfully wrote google-finance-gainers.csv to CSV...
---------------------
Writing to CSV...
Writing data to CSV File...
Successfully wrote google-finance-losers.csv to CSV...
---------------------
Writing to CSV...
Writing data to CSV File...
Successfully wrote google-finance-indexes.csv to CSV...
---------------------
Writing to CSV...
Writing data to CSV File...
Successfully wrote google-finance-most-active.csv to CSV...
---------------------
Writing to CSV...
Writing data to CSV File...
Successfully wrote google-finance-cryptocurrencies.csv to CSV...如果在 VSCode 中运行脚本,你会在爬取完成后看到相应的 CSV 文件,它们在下图中被高亮显示。
下面是在ONLYOFFICE中打开这些文件时的截图。
Most Active
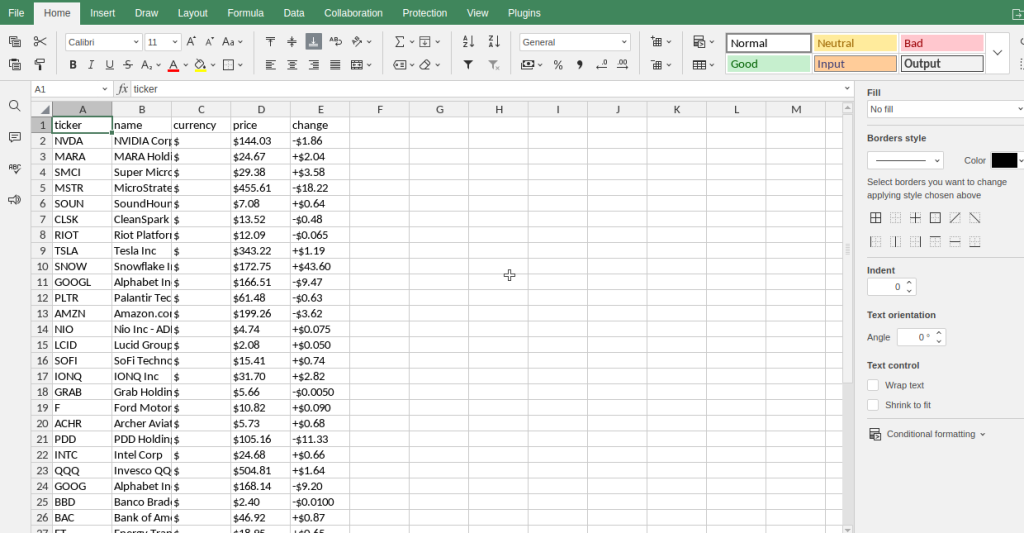
Losers
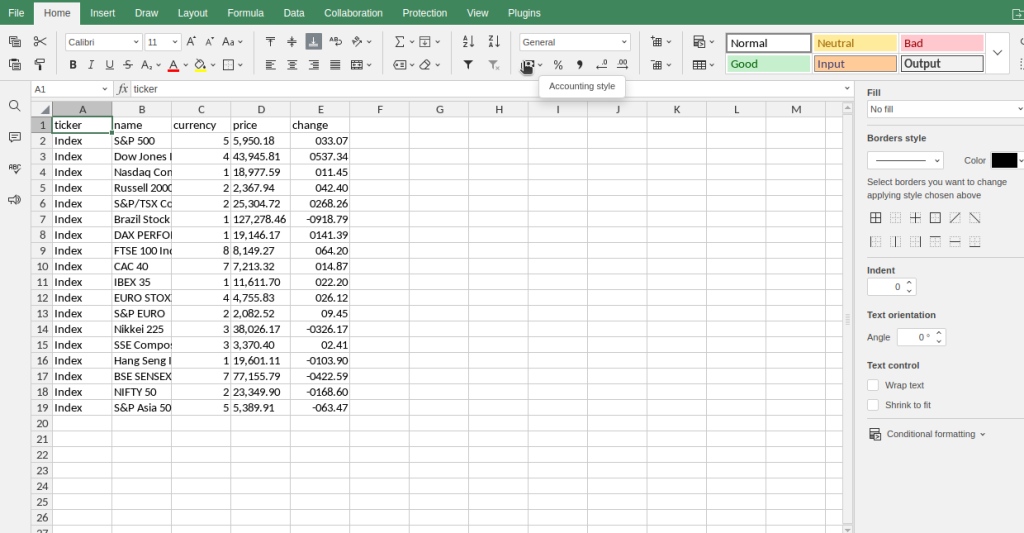
Indexes
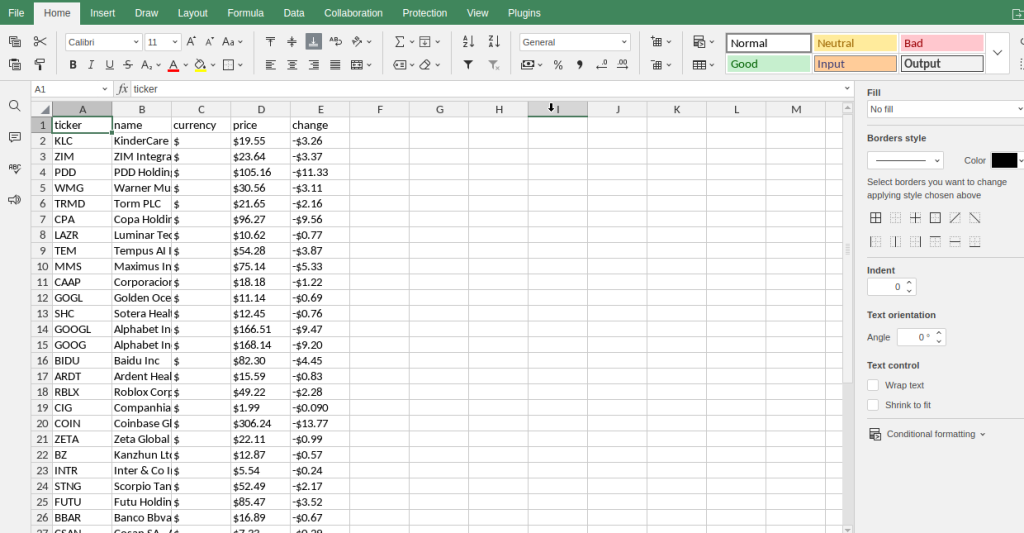
Gainers
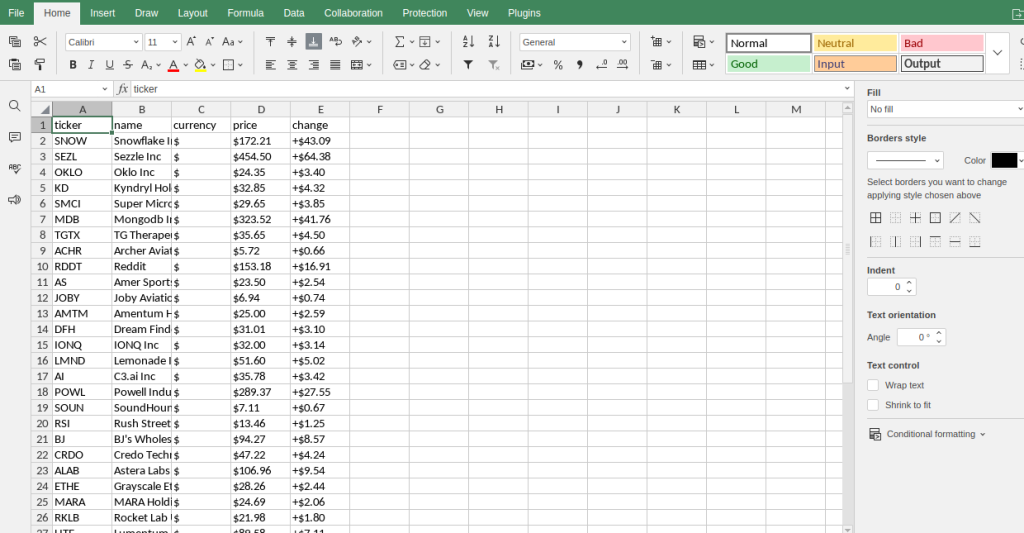
Cryptocurrencies
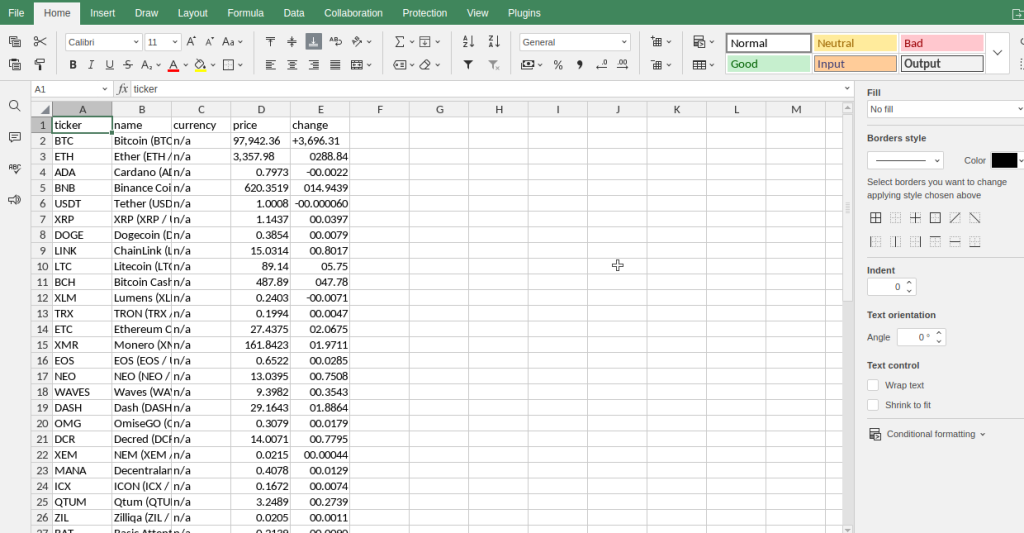
高级技巧
处理分页
在传统情况下,分页通常通过数字来加载新的页面。但对 Google Finance 来说,我们使用endpoints数组来处理分页。endpoints列表中的每个条目都代表一个我们要爬取的页面。再次看看这个列表,更多关于如何处理网页抓取中的分页可以参考这篇内容。
endpoints = ["gainers", "losers", "indexes", "most-active", "cryptocurrencies"]然后再看看这个列表是如何被使用的。传统的分页通常会给出一个端点或者查询参数,用数字来表示页码。但在这个爬虫脚本中,我们直接将页面端点嵌入到基础 URL 中:
response = requests.get(f"https://google.com/finance/markets/{endpoint}")减少被封锁的风险
在我们的测试中,并没有遇到封锁的问题。但在实际情况下,仍有可能被封。你可以使用多种策略来降低被封锁的风险。
伪造 User Agent
当你向网站发出请求(无论是通过浏览器还是 Python Requests),你的 HTTP 客户端都会发送一个 user-agent 字符串给网站服务器,以标识请求软件。要在 Python 中伪造一个 user-agent,我们可以创建自定义的 user-agent 字符串,然后将其加入请求头:
USER_AGENT = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36"
headers = {
"User-Agent": USER_AGENT
}
response = requests.get(f"https://google.com/finance/markets/{endpoint}", headers=headers)延时请求
控制请求的时间间隔往往很有效。如果一个请求在一分钟内访问了 200 个页面,很明显不像是人工访问。为了规避速率限制并模拟真实流量,可以在爬虫中让每次请求之间休眠一段随机或固定的时间。这样可以让爬虫表现得更人性化。首先,你需要从time导入sleep:
from time import sleep然后,在每次请求后等待几秒:
response = requests.get(f"https://google.com/finance/markets/{endpoint}")
sleep(5)考虑使用 Bright Data
抓取互联网数据可能会耗费大量精力。Bright Data 是优质数据集提供商之一。如果你使用我们提供的数据集,就无需亲自编写爬虫,拿到数据后直接下载即可。我们也理解并不是所有人都愿意在爬虫上投入时间。
我们暂时没有 Google Finance 数据集,但我们提供了 Yahoo Finance 数据集。Yahoo Finance 的金融数据更加全面,可以满足你对 Google Finance 类似的需求。下面介绍一下如何购买这个数据集。
创建账户
首先,你需要注册一个账户。前往我们的注册页面进行注册。
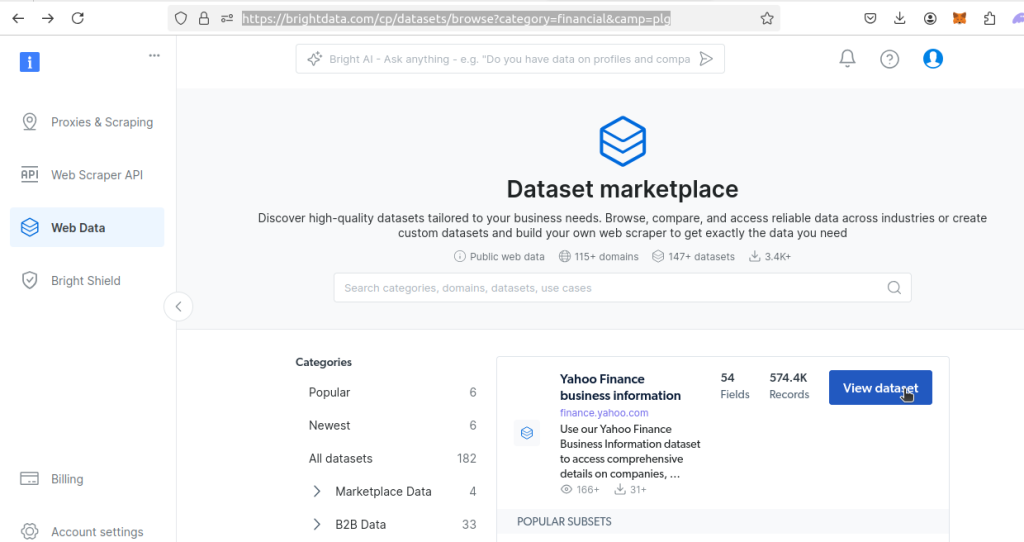
下载 Bright Data 数据集
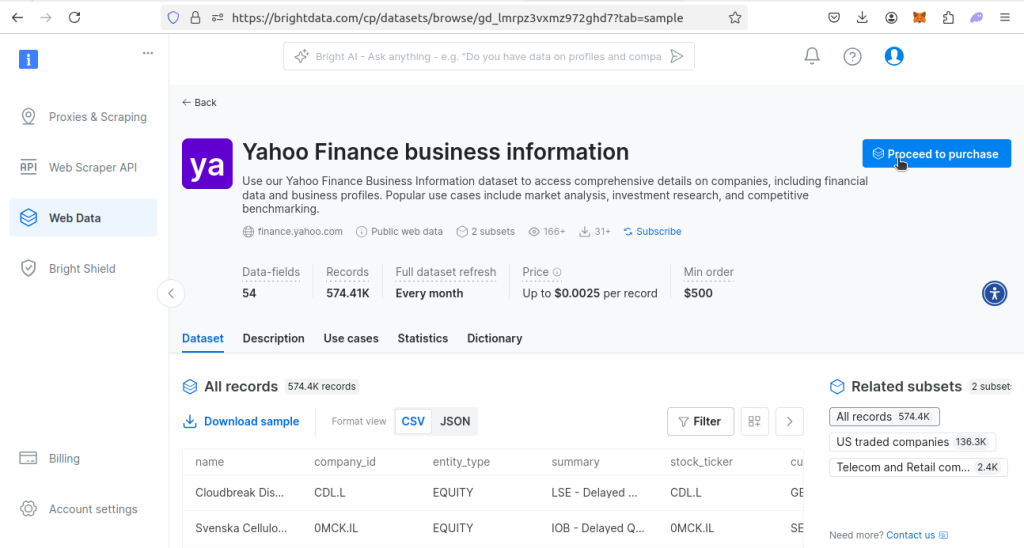
然后,前往我们的金融数据集页面,找到Yahoo Finance 数据集,点击View dataset。
进入该数据集页面后,你可以下载示例数据集,也可以直接购买。价格是每条记录 $0.0025,最低购买金额 $500。如果你需要这个数据集,就点击Proceed to purchase并完成付款流程。
我们预制的数据集已经为你做好了爬取工作,获取数据后就能直接使用!
总结
到这里你已经学会了!你现在知道如何从 Google Finance 中抓取聚合数据,也知道如何通过我们的 Yahoo Finance 数据集快速获取类似信息。通过本文,你应该了解了如何使用 Python Requests 和 BeautifulSoup 创建基本的爬虫,并知道在使用 BeautifulSoup 解析 HTML 时如何运用 find_all() 等方法来获取页面对象。
我们还深入探讨了如何处理基于端点的分页,以及可能遇到封锁时的应对策略。你可以将这些知识应用到自己的爬虫项目中,也可以直接使用我们的预制数据集节省大量时间。
立即注册并开始免费的试用,包括获取免费数据集样本。



