

在本指南中,您将学习:
- 数据集的定义
- 创建数据集的最佳方法
- 如何在 Python 中创建数据集
- 如何在 R 中创建数据集
让我们深入探讨吧!
什么是数据集?
数据集是与特定主题、主题或行业相关的数据集合。数据集可以包含各种类型的信息——包括数字、文本、图像、视频和音频——并可以以 CSV、JSON、XLS、XLSX 或 SQL 等格式存储。
本质上,数据集由针对特定目的的结构化数据组成。
创建数据集的五大策略
探索创建数据集的五种最佳策略,分析它们的工作原理以及优缺点。
策略一:外包任务
建立和管理一个用于创建数据集的业务部门可能不可行或不实际,特别是如果您缺乏内部资源或时间。在这种情况下,创建数据集的有效策略是将任务外包。
外包涉及将数据集创建过程委托给外部专家或专业机构,而不是内部处理。这种方法使您能够利用在数据收集、清理和格式化方面有经验的专业人士或组织的技能。
您应该将数据集创建外包给谁?许多公司提供即用型数据集或定制的数据收集服务。有关更多详细信息,请参阅我们的最佳数据集网站指南。
这些提供商使用高级技术确保检索到的数据准确无误,并根据您的规格进行格式化。虽然外包使您能够专注于业务的其他重要方面,但选择一个能满足您质量期望的可靠合作伙伴至关重要。
优点:
- 您无需担心任何事情
- 来自任何网站、任何格式的数据集
- 历史或最新数据
缺点:
- 您无法完全控制数据检索过程
- 可能存在与 GDPR 和 CCPA 相关的数据合规性问题
- 可能不是最具成本效益的解决方案
策略二:从公共 API 检索数据
许多平台,从社交媒体网络到电商网站,都提供公开的 API,暴露大量数据。例如,X 的 API可访问关于公共账户、帖子和回复的信息。
从公共 API 检索数据是创建数据集的有效技术。原因是这些端点以结构化格式返回数据,使得根据它们的响应生成数据集更容易。毫不奇怪,API 是数据来源的最佳策略之一。
通过利用这些 API,您可以直接从知名平台快速收集大量可信数据。主要的缺点是您需要遵守 API 的使用限制和服务条款。
优点:
- 访问官方数据
- 简单集成到任何编程语言中
- 直接从源头获取结构化数据
缺点:
- 并非所有平台都有公开的 API
- 您必须遵守 API 提供商施加的限制
- 这些 API 返回的数据可能会随着时间而变化
策略三:寻找开放数据
开放数据指的是免费公开共享的数据集。这些数据主要用于研究和科学论文,但也可满足业务需求,如市场分析。
开放数据是可信的,因为它由政府、非营利组织和学术机构等知名来源提供。这些组织提供涵盖广泛主题的开放数据存储库,包括社会趋势、健康统计、经济指标、环境数据等。
您可以从以下热门网站获取开放数据:
- Data.gov:美国联邦数据的综合存储库。
- 欧盟开放数据门户:提供整个欧洲的数据集。
- 世界银行开放数据:提供全球经济和发展数据。
- 联合国数据:提供各种全球社会和经济指标的数据集。
- AWS 开放数据注册表:一个通过 AWS 资源发现和共享数据集的平台。
开放数据是创建数据集的流行方式,因为它通过提供免费可用的数据,消除了数据收集的需要。不过,您必须审查数据的质量、完整性和许可条款,以确保其满足您项目的要求。
优点:
- 免费数据
- 即用型、大型、完整的数据集
- 由政府机构等可信来源支持的数据集
缺点:
- 通常只提供对历史数据的访问
- 需要一些工作才能为您的业务获得有用的洞察
- 您可能无法找到您感兴趣的数据
策略四:从 GitHub 下载数据集
GitHub 托管着众多包含各种用途数据集的存储库,从机器学习和数据科学到软件开发和研究。这些数据集由个人和组织共享,以获得反馈并为社区做出贡献。
在某些情况下,这些 GitHub 存储库还包括处理、分析和探索数据的代码。
一些值得注意的存储库包括:
- Awesome Public Datasets:一个精心策划的涵盖各种领域(包括金融、气候和体育)的高质量数据集集合。它是寻找与特定主题或行业相关的数据集的中心。
- Kaggle 数据集:Kaggle 是数据科学竞赛的知名平台,在 GitHub 上托管了一些数据集。用户可以通过从 GitHub 存储库开始,只需点击几下即可创建 Kaggle 数据集。
- 其他开放数据存储库:一些组织和研究小组使用 GitHub 托管开放数据集。
这些存储库提供了现成的数据集,可直接使用或根据需要进行调整。访问它们只需一个 git clone 命令或点击“下载”按钮。
优点:
- 即用型数据集
- 用于分析和与数据交互的代码
- 可供选择的多种不同类别的数据
缺点:
- 可能存在许可问题
- 这些存储库大多未及时更新
- 通用数据,未针对您的需求定制
策略五:使用网络爬虫创建您自己的数据集
网络爬虫是从网页提取数据并将其转换为可用格式的过程。
通过网络爬虫创建数据集是一种流行的方法,原因如下:
- 访问大量数据:网络是世界上最大的数据来源。爬虫使您能够利用这一广泛的资源,收集可能无法通过其他方式获得的信息。
- 灵活性:您可以选择要检索的数据、生成数据集的格式,并控制数据的更新频率。
- 定制化:根据您的特定需求定制数据提取,例如从公共数据集中未涵盖的利基市场或专业主题中提取数据。
以下是网络爬虫的典型工作方式:
- 确定目标网站
- 检查其网页以制定数据提取策略
- 创建脚本连接到目标页面
- 解析页面的 HTML 内容
- 选择包含感兴趣数据的 DOM 元素
- 从这些元素中提取数据
- 将收集的数据导出为所需的格式,例如 JSON、CSV 或 XLSX
请注意,进行网络爬虫的脚本可以用几乎任何编程语言编写,例如 Python、JavaScript 或 Ruby。了解更多,请阅读我们的网络爬虫最佳语言文章。此外,查看最佳网络爬虫工具。
由于大多数公司都知道其数据的价值,即使在其网站上公开访问,也会使用反机器人技术保护它。这些解决方案可以阻止您的脚本发出的自动请求。在我们的教程中了解如何绕过这些措施,执行不被阻止的网络爬虫。
另外,如果您对网络爬虫与从公共 API 获取数据的区别感兴趣,请查看我们的网络爬虫与 API文章。
优点:
- 来自任何网站的公共数据
- 您可以控制数据提取过程
- 具有成本效益的解决方案,可用于大多数编程语言
缺点:
- 反机器人和反爬虫解决方案可能会阻止您
- 需要一些维护
- 可能需要自定义数据聚合逻辑
如何在 Python 中创建数据集
Python 是数据科学的领先语言,因此是创建数据集的热门选择。正如您将看到的,在 Python 中创建数据集只需几行代码。
在这里,我们将专注于抓取Bright Data 数据集市场中所有可用数据集的信息:
按照引导式教程来实现目标!
欲了解更多详细的操作方法,请探索我们的Python 网络爬虫指南。
步骤1:安装和设置
我们假设您已经在您的机器上安装了Python 3+,并已设置了一个 Python 项目。
首先,您需要为此项目安装所需的库:
- requests:用于发送 HTTP 请求并检索网页关联的 HTML 文档。
- Beautiful Soup:用于解析 HTML 和 XML 文档并从网页中提取数据。
- pandas:用于操作数据并将其导出为 CSV 数据集。
在项目文件夹中激活的虚拟环境中打开终端,运行:
pip install requests beautifulsoup4 pandas安装后,您可以在 Python 脚本中导入这些库:
import requests
from bs4 import BeautifulSoup
import pandas as pd步骤2:连接到目标网站
检索您要从中提取数据的页面的 HTML。使用 requests 库向目标网站发送 HTTP 请求并检索其 HTML 内容:
url = 'https://brightdata.com/products/datasets'
headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.0.0 Safari/537.36' }
response = requests.get(url=url, headers=headers)有关更多详细信息,请参阅我们的指南,了解如何在 Python requests 中设置用户代理。
步骤3:实现爬虫逻辑
有了 HTML 内容后,使用 BeautifulSoup 解析它,并从中提取您需要的数据。选择包含感兴趣数据的 HTML 元素,并从中获取数据:
# parse the retrieved HTML
soup = BeautifulSoup(response.text, 'html.parser')
# where to store the scraped data
data = []
# scraping logic
dataset_elements = soup.select('.datasets__loop .datasets__item--wrapper')
for dataset_element in dataset_elements:
dataset_item = dataset_element.select_one('.datasets__item')
title = dataset_item.select_one('.datasets__item--title').text.strip()
url_item = dataset_item.select_one('.datasets__item--title a')
if (url_item is not None):
url = url_item['href']
else:
url = None
type = dataset_item.get('aria-label', 'regular').lower()
data.append({
'title': title,
'url': url,
'type': type
})步骤4:导出为 CSV
使用 pandas 将爬取的数据转换为DataFrame,并将其导出为 CSV 文件。
df = pd.DataFrame(data, columns=data[0].keys())
df.to_csv('dataset.csv', index=False)步骤5:执行脚本
您的最终 Python 脚本将包含以下代码行:
import requests
from bs4 import BeautifulSoup
import pandas as pd
# make a GET request to the target site with a custom user agent
url = 'https://brightdata.com/products/datasets'
headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.0.0 Safari/537.36' }
response = requests.get(url=url, headers=headers)
# parse the retrieved HTML
soup = BeautifulSoup(response.text, 'html.parser')
# where to store the scraped data
data = []
# scraping logic
dataset_elements = soup.select('.datasets__loop .datasets__item--wrapper')
for dataset_element in dataset_elements:
dataset_item = dataset_element.select_one('.datasets__item')
title = dataset_item.select_one('.datasets__item--title').text.strip()
url_item = dataset_item.select_one('.datasets__item--title a')
if (url_item is not None):
url = url_item['href']
else:
url = None
type = dataset_item.get('aria-label', 'regular').lower()
data.append({
'title': title,
'url': url,
'type': type
})
# export to CSV
df = pd.DataFrame(data, columns=data[0].keys())
df.to_csv('dataset.csv', index=False)运行它,您的项目文件夹中将出现以下 dataset.csv 文件:
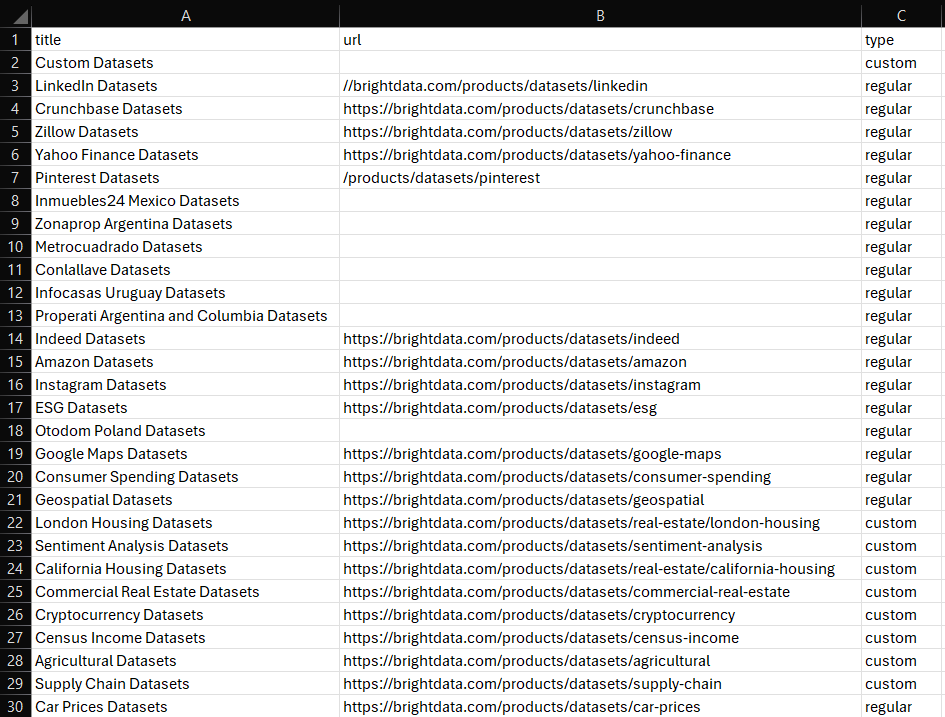
就是这样!您现在知道了如何在 Python 中创建数据集。
如何在 R 中创建数据集
R 是研究人员和数据科学家广泛采用的另一种语言。以下是在 R 中创建数据集的等效脚本,遵循我们之前在 Python 中看到的内容:
library(httr)
library(rvest)
library(dplyr)
library(readr)
# make a GET request to the target site with a custom user agent
url <- "https://brightdata.com/products/datasets"
headers <- add_headers(`User-Agent` = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.0.0 Safari/537.36")
response <- GET(url, headers)
# parse the retrieved HTML
page <- read_html(response)
# where to store the scraped data
data <- tibble()
# scraping logic
dataset_elements <- page %>%
html_nodes(".datasets__loop .datasets__item--wrapper")
for (dataset_element in dataset_elements) {
title <- dataset_element %>%
html_node(".datasets__item .datasets__item--title") %>%
html_text(trim = TRUE)
url_item <- dataset_element %>%
html_node(".datasets__item .datasets__item--title a")
url <- if (!is.null(url_item)) {
html_attr(url_item, "href")
} else {
""
}
type <- dataset_element %>%
html_attr("aria-label", "regular") %>%
tolower()
data <- bind_rows(data, tibble(
title = title,
url = url,
type = type
))
}
# export to CSV
write_csv(data, "dataset.csv")欲获得更多指导,请参阅我们的R 语言网络爬虫教程。
结论
在这篇博客文章中,您学习了如何创建数据集。您了解了什么是数据集,并探索了创建数据集的不同策略。您还看到了如何在 Python 和 R 中应用网络爬虫策略。
Bright Data 拥有一个大型、快速且可靠的代理网络,为许多财富 500 强公司和超过 20,000 名客户服务。该网络用于从网络中以道德方式检索数据,并在广泛的数据集市场中提供,包括:
- 商业数据集:来自 LinkedIn、CrunchBase、Owler 和 Indeed 等关键来源的数据。
- 电商数据集:来自亚马逊、沃尔玛、塔吉特、Zara、Zalando、Asos 等的数据。
- 房地产数据集:来自 Zillow、MLS 等网站的数据。
- 社交媒体数据集:来自 Facebook、Instagram、YouTube 和 Reddit 的数据。
- 金融数据集:来自雅虎财经、Market Watch、Investopedia 等的数据。
如果这些预制选项无法满足您的需求,请考虑我们的自定义数据收集服务。
除此之外,Bright Data 提供了广泛的强大爬虫工具,包括网络爬虫 API和爬虫浏览器。
立即注册,看看 Bright Data 的哪些产品和服务最适合您的需求。


