

在这篇博客文章中,您将了解到:
- 什么是亚马逊 CAPTCHA,以及它是如何工作的
- 绕过它的三种不同方法
- 对这些技术的全面对比
让我们开始吧!
亚马逊 CAPTCHA:简介
在学习如何绕过它之前,先了解一下亚马逊 CAPTCHA 是什么,以及为什么它会在某些页面出现。
定义
亚马逊 CAPTCHA 是一种反机器人措施,当您使用自动化脚本访问亚马逊页面或在该网站上执行自动化交互时就会出现。大多数情况下,它会以简单的文本型 CAPTCHA 形式出现,要求您输入屏幕上显示的字符:
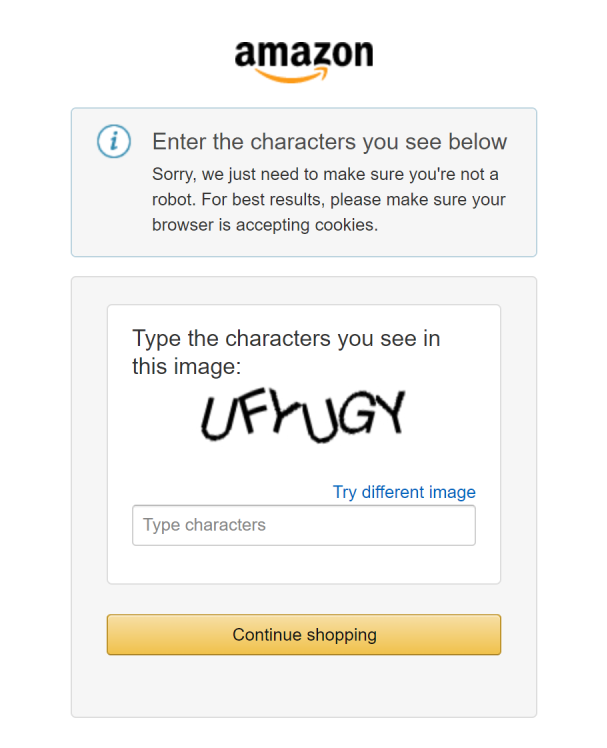
上面的挑战看起来很简单,但足以阻止大多数电商网站爬取脚本。好消息是,它并不是市面上最先进的 CAPTCHA,确实有一些方法可以绕过它。
何时会出现
这里比较棘手的是… 亚马逊 CAPTCHA 的出现并不遵循固定的场景或浏览器配置。有时您会碰到它,有时又没有。
根据我们的测试,使用 Selenium、Puppeteer 和 Playwright 等自动化工具时,最常见会触发 CAPTCHA 的场景包括:
- 直接访问某个亚马逊产品页面
- 执行自动化搜索
- 尝试登录或注册账号
不过,需要注意的是,以上动作并不一定会保证出现 CAPTCHA。虽然您可能觉得这种不确定性是好事,但实际上并非如此!它可能会让您误以为自己的 亚马逊爬取脚本运作正常——直到它突然开始被阻止,且看不出任何原因。
例如,下面这样一个简单的 Selenium 脚本可能会顺利运行,也可能会触发 CAPTCHA:
# pip install selenium
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
# Configure the browser to launch in headless mode
options = Options()
options.add_argument("--headless")
# Initialize the WebDriver to control Chrome
driver = webdriver.Chrome(service=Service(),options=options)
# Connect to the target page (Amazon Kindle product page)
driver.get("https://www.amazon.com/Amazon-Kindle/dp/B0CNV9F72P")
# Take a screenshot of the entire page
driver.save_screenshot("product-page.png")
# Additional scraping logic...
# Release the driver resources
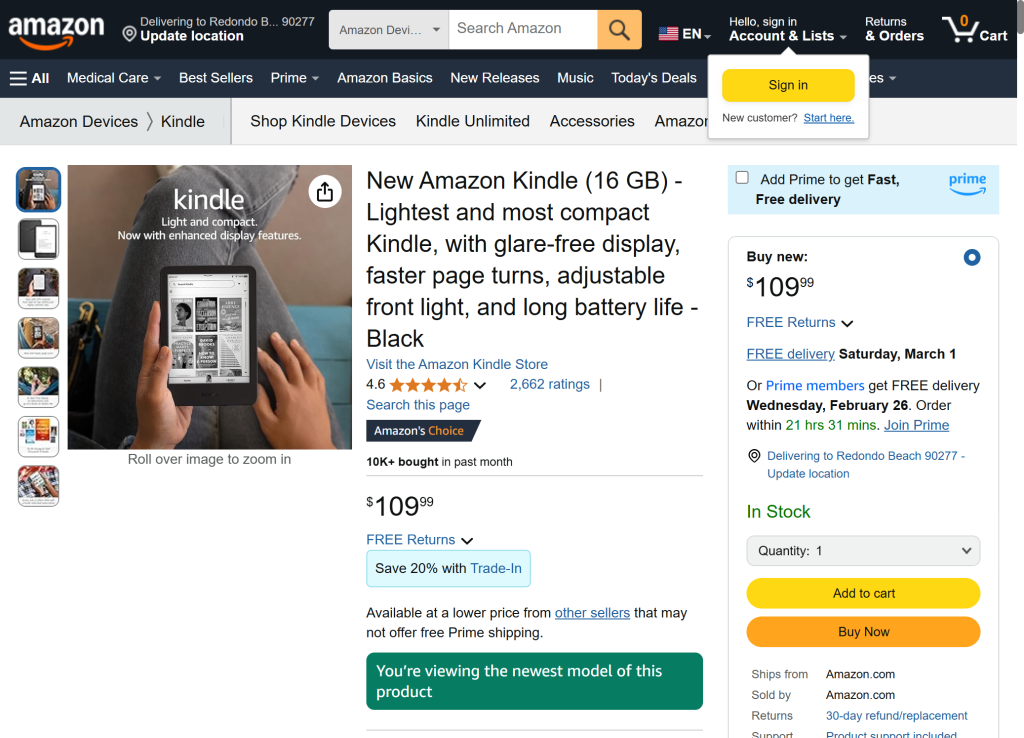
driver.quit()如果运行成功,脚本会生成如下截图:
而如果运行不成功,就会生成:
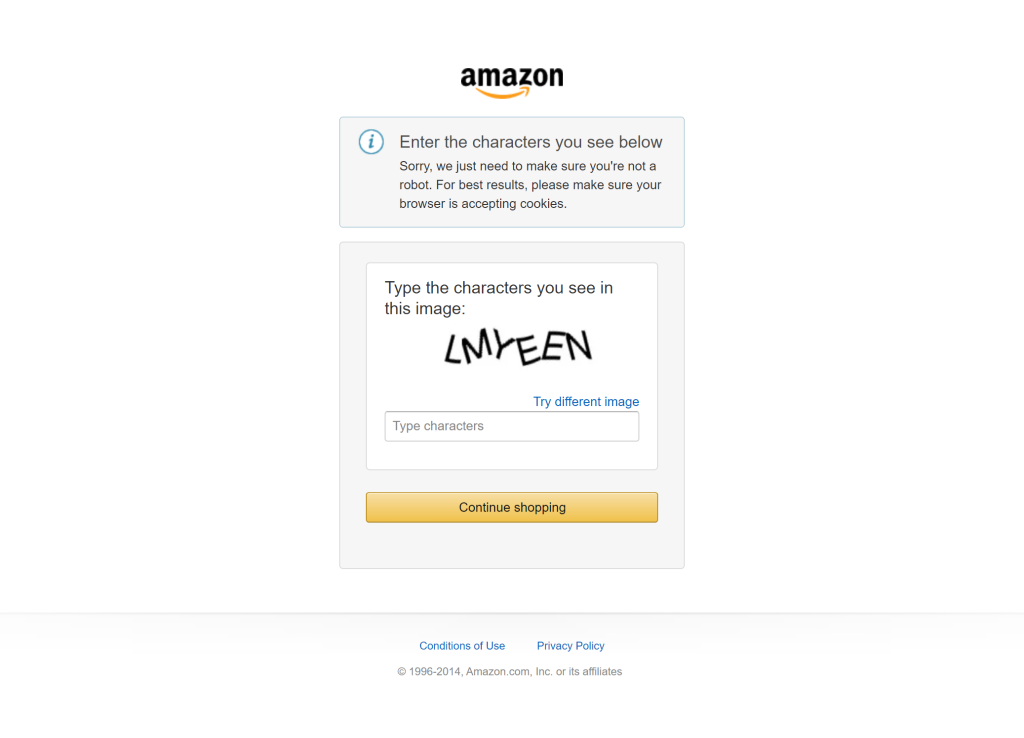
CAPTCHA 出现的不可预测性使得很难开发出能稳定触发挑战的自动化逻辑,而也因此,让它难以被深入研究。但这并不代表无法绕过该 CAPTCHA。
接下来让我们学习如何操作!
绕过亚马逊 CAPTCHA 的三大技巧
本章将探讨三种解决亚马逊 CAPTCHA 的不同方法:
- 使用隐身浏览器
- 使用 AI
- 使用 CAPTCHA 解码服务
若想了解其他方法,请参阅我们的Python 绕过 CAPTCHA 教程。
让我们一一展开!
方法一:使用隐身浏览器
您在浏览亚马逊时有多少次遇到过 CAPTCHA?很有可能很少,甚至从未遇到过。这表明,普通真实用户并不会大量受到亚马逊反机器人、反爬虫系统的干扰。
一如大多数场景,“预防胜于治疗”。这里的目标不是尝试去破解 CAPTCHA,而是尽量避免它出现。要点在于将浏览器自动化逻辑配置得尽可能地模拟真实用户访问亚马逊网页的行为。
要实现这一点,可以使用带有“隐身”插件的浏览器来修改自动化相关的浏览器设置,避免泄露信息并降低机器人识别的可能性。一些常见的工具包括:
- SeleniumBase:一个基于 Python 的自动化框架,自带隐身功能,能在 Selenium 中绕过机器人检测。
- Playwright Stealth:针对 Playwright Extra 的插件,可通过修改浏览器设置来规避反机器人系统的检测。
- Puppeteer Stealth:针对 Puppeteer Extra 的插件,通过调整浏览器指纹使其更像真人。
undetected-chromedriver:一个已补丁的 Selenium WebDriver,能帮助绕过反机器人机制的检测。
在本节中,我们将重点放在 SeleniumBase,因为它可以很好地配合 Python 使用。当然,您也可以轻松使用其他任意工具。
要安装 SeleniumBase,请运行:
pip install seleniumbase然后,您可以如下修改之前的 Selenium 脚本以使用 SeleniumBase:
from seleniumbase import Driver
# Initialize the SeleniumBase driver
driver = Driver(uc=True) # Enables stealth mode
# Connect to the target Amazon page
driver.get("https://www.amazon.com/Amazon-Kindle/dp/B0CNV9F72P")
# Take a screenshot of the entire page
driver.save_screenshot("product-page.png")
# Additional scraping logic...
# Release the driver resources
driver.quit()很好!这样就大幅降低了遇到亚马逊 CAPTCHA 的几率。
方法二:使用 AI 进行识别
如果您浏览一系列亚马逊 CAPTCHA,就会觉得让 AI 来解决它们并非难事:
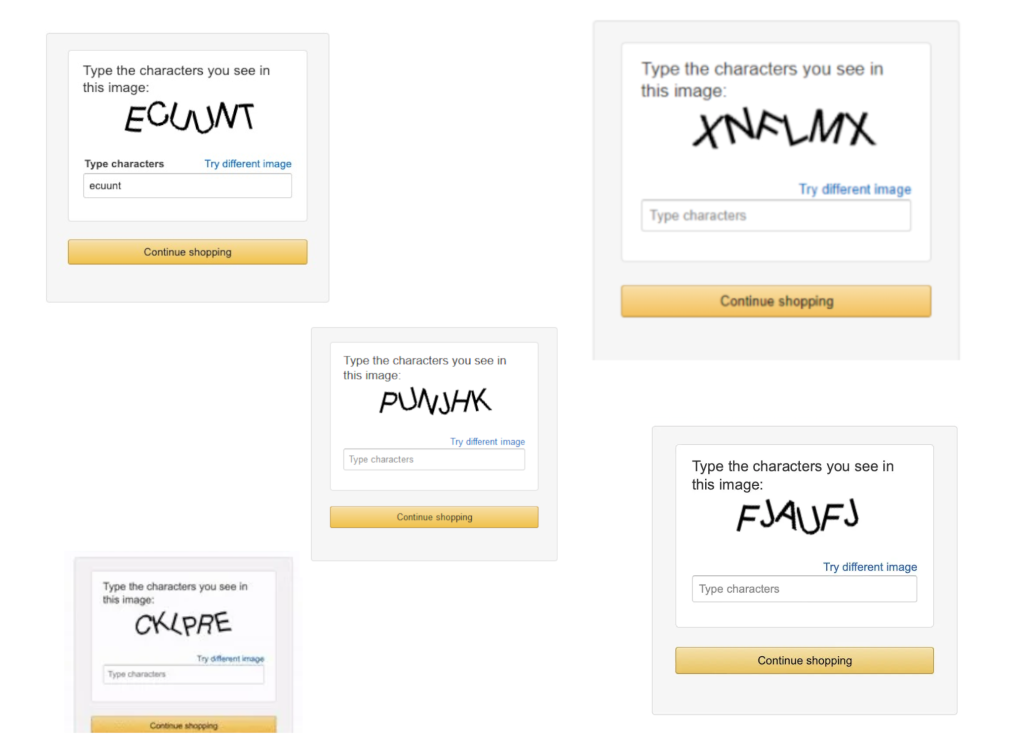
毕竟,和当今市场上更先进、更复杂的 CAPTCHA 相比,简单的文本识别挑战确实看起来有些过时:
因此,思路如下:
- 对 CAPTCHA 页面进行截图
- 将截图提交给 ChatGPT 或其他 AI 模型
- 获取 AI 的识别结果,并用它去填写并通过 CAPTCHA
如果查看 CAPTCHA 的 HTML,您会发现文本输入字段可以用 .a-span12 CSS 选择器来获取。基于这一点,我们可以用以下方法来让 AI 绕过亚马逊 CAPTCHA:
import os
import time
import base64
from openai import OpenAI
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
def encode_image(image_path):
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode("utf-8")
def solve_amazon_captcha(driver, timeout=5):
client = OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
captcha_elements = driver.find_elements(By.CSS_SELECTOR, "a-span12")
# If the CAPTCHA has been detected
if len(captcha_elements) > 0:
print("CAPTCHA detected!")
# Take a screenshot of the CAPTCHA page
driver.maximize_window()
screenshot_path = "captcha.png"
driver.save_screenshot(screenshot_path)
print("Attempting to solve the CAPTCHA...")
# Feed the screenshot to the AI for CAPTCHA solving
base64_image = encode_image(screenshot_path)
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "Extract the text from this CAPTCHA. Return only the text."},
{"type": "image_url", "image_url": {"url": f"data:image/png;base64,{base64_image}"}},
],
}
],
)
# Get the CAPTCHA text
captcha_text = response.choices[0].message.content.strip()
# Select teh CAPTCHA input text and fill it out
# with the AI generated text
input_element = captcha_elements[0]
input_element.send_keys(captcha_text, Keys.ENTER)
print("CAPTCHA solved!")
print(f"Wait up to {timeout} seconds for page reload...")
# Wait up to 5 seconds for a page reload
time.sleep(timeout)要使用 solve_amazon_captcha() 函数,需要安装 openai 依赖:
pip install openai此外,还需将您的 OpenAI API 密钥设置为名为 OPENAI_API_KEY 的全局环境变量。
如下方式可调用这个基于 AI 的 CAPTCHA 解决函数:
driver = webdriver.Chrome()
driver.get("https://www.amazon.com/Amazon-Kindle/dp/B0CNV9F72P")
solve_amazon_captcha(driver)
driver.quit()现在,脚本会以类似人工的方式来解决 CAPTCHA。
如果想了解如何使用 Gemini 实现类似方案,可查看GitHub 上的 Genaptcha 项目。
方法三:集成 CAPTCHA 解决服务
如果您希望在尽量减少对 AI 模型调用的同时获得最高的识别准确率(因为图像处理会消耗大量 token,成本也随之上升),那么可以将前面提到的两种方案结合:
- 减少亚马逊显示 CAPTCHA 的频率
- 只在确有出现时才进行破解
然而,这种混合方法也带来了一些问题:
- 额外的依赖:您需要隐身浏览器自动化工具、OpenAI 客户端以及正确的环境配置。
- 不稳定性:隐身插件今天有效,但明天在反机器人升级后就可能失效。因此要保证定期更新相关依赖。此外,LLM 模型有时会输出不一致的结果,也是一种潜在风险。同时,如果亚马逊未来升级为更复杂的 CAPTCHA,AI 也可能难以识别。
- 需要重试逻辑:为了确保 CAPTCHA 真正完成,需要在 AI 失败时进行重试。
- 速度较慢:AI 处理需要时间,加上等待 CAPTCHA 出现和消失,也会拖慢自动化/爬取流程。
- 维护成本:您需要持续确保所有已选技术配置正确并保持可用。
这样看来,直接用一个 CAPTCHA 解码服务的方式岂不是更简单?尤其当该功能直接内置在您所选择的抓取浏览器(基于云端的爬取专用浏览器)中时。此服务针对网络爬取进行了高度优化,旨在最大化性能,同时不必让您自己管理基础设施。该专用浏览器具有 IP 轮换、自动重试、先进的反机器人机制,以及当然也包括内置的CAPTCHA 解决功能。
在 我们的文档 中,可查看如何与 Selenium、Playwright 和 Puppeteer 轻松整合,就像使用任何其它浏览器一样简单。
绕过亚马逊 CAPTCHA 的最佳方式
下面回顾一下本文讨论的亚马逊 CAPTCHA 技术:
| 方法 | CAPTCHA 规避 | CAPTCHA 识别 | 维护需求 | 额外手动逻辑 | 成本 |
|---|---|---|---|---|---|
| 隐身浏览器 | ✔️ | ❌ | 需要 | 需要 | 免费 |
| AI 识别 | ❌ | ✔️ | 需要 | 需要 | 💲 |
| CAPTCHA 解码服务 | ✔️ | ✔️ | 不需要,因为服务在云端运行 | 不需要,因为所有功能已集成于工具 | 💲 |
以下是它们各自的优势与缺点概述。
方法一:使用隐身浏览器
👍 优点:
- 免费且开源
👎 缺点:
- 本质上是避免 CAPTCHA,而不是真正破解
- 依赖补丁浏览器,可能不稳定
- 需要持续维护
方法二:使用 AI 进行识别
👍 优点:
- 能够有效解决文本型 CAPTCHA
👎 缺点:
- 结果不稳定,对复杂 CAPTCHA 的识别效果较差
- 检测页面上是否有 CAPTCHA 本身也很棘手
- 调用 AI 需要付费
方法三:集成 CAPTCHA 解码服务
👍 优点:
- 效率极高
- 可与任意浏览器自动化工具或 HTTP 客户端无缝结合
- 不需要重试逻辑、浏览器配置或其他手动操作
👎 缺点:
- 付费服务
总结
在这篇文章中,您了解到为什么亚马逊可能会用 CAPTCHA 阻止您,以及如何在爬取脚本中应对它。不幸的是,CAPTCHA 出现的时机并不稳定,导致难以被研究。不过,好在仍有一些技术手段可以避免或绕过它,本文列举了三种最常用的方式。
如上所述,最有效的方案是使用自带 CAPTCHA 解码功能的 Bright Data 抓取浏览器,并且它能与 Selenium、Playwright 和 Puppeteer 无缝结合。
如果您想要更简单的方案,还可以考虑:
- 亚马逊 CAPTCHA 解码服务:专门针对亚马逊的 CAPTCHA 解码服务,并依托于我们的 网络解锁器。
- 亚马逊爬取工具:针对亚马逊页面设计的专属爬取端点。只需调用,即可获取所需数据,且已按您喜好的格式解析好。
- 亚马逊数据集:可直接使用的成品数据集,包含您关注的数据,无需自己动手爬取。
立即创建 Bright Data 免费账号,立享免费试用,探索我们的爬取方案和数据集。
支持支付宝等多种支付方式


