

学习如何使用 Pandas、NumPy 和 Matplotlib 在 Python 中执行数据分析。按照分步教程并了解最佳实践,从数据中获取洞察。
在本分步指南中掌握使用 Python 进行数据分析的技能。学习关键库、最佳实践,以及如何从真实的数据集中提取见解。
2025 年:Python 数据分析指南
在本 Python 数据分析指南中,你将了解:
- 为什么使用 Python 来进行数据分析
- Python 常用的数据分析库
- 如何分步骤完成 Python 数据分析
- 分析数据时应遵循的流程
让我们开始吧!
为什么使用 Python 进行数据分析
通常,数据分析主要使用两种编程语言:
具体来说,以下是使用 Python 进行数据分析的主要原因:
- 学习曲线平缓:Python 语法简单且可读性强,对初学者和专家都很友好。
- 多功能性:Python 能处理多种类型和格式的数据,包括 CSV、Excel、JSON、SQL 数据库、Parquet 等。它可从简单的数据清洗任务扩展到复杂的机器学习与深度学习应用。
- 可扩展性:Python 具有可扩展性,可以处理小型数据集,也能执行大规模数据处理。例如,Dask 和 PySpark 等库可轻松应对大数据。
- 社区支持:Python 拥有庞大且活跃的开发者与数据科学家社区,他们共同推动其生态的发展。
- 机器学习和人工智能集成:Python 是机器学习和人工智能领域的首选语言,TensorFlow、PyTorch 和 Keras 等库支持高级分析和预测建模。
- 可复现性与协作:Jupyter Notebooks 能够分享并复现数据分析代码片段,对数据科学协作十分重要。
- 用于不同目的的统一环境:Python 提供在同一环境中完成不同任务的可能性。例如,你可以使用同一个Jupyter Notebook 来抓取网页数据再进行分析。在同一环境中,你也可以使用机器学习模型进行预测。
Python 数据分析的常用库
Python 在数据分析领域广受欢迎,也得益于其庞大的库生态系统。以下是 Python 数据分析中最常见的库:
- NumPy:用于数值计算和多维数组处理。
- Pandas:用于数据操作和分析,特别是表格数据。
- Matplotlib 和 Seaborn:用于数据可视化和创建有洞察力的图表。
- SciPy:用于科学计算和高级统计分析。
- Plotly:用于创建动画图表。
在接下来的指南部分,你将学到它们的具体用法!
Python 数据分析:完整示例
你已经了解了使用 Python 进行数据分析的原因以及支持该任务的常用库。接下来,按照这个分步教程学习如何用 Python 进行数据分析。
在本节中,你将分析来自 Bright Data 免费数据集的 Airbnb 房源信息。
环境要求
要跟随本指南,你需要在本地机器上安装 Python 3.6 或更新版本。
步骤 1:设置环境并安装依赖
假设你将项目的主文件夹命名为 data_analysis/。在完成此步骤后,文件夹将拥有以下结构:
data_analysis/
├── analysis.ipynb
└── venv/其中:
analysis.ipynb是包含所有 Python 数据分析代码的 Jupyter Notebook。venv/是 Python 虚拟环境文件夹。
你可以通过以下命令创建 venv/ 虚拟环境目录:
python -m venv venv在 Windows 上激活它:
venvScriptsactivate在 macOS/Linux 上执行:
source venv/bin/activate在激活的虚拟环境中,安装所有所需的库:
pip install pandas jupyter matplotlib seaborn numpy要创建 analysis.ipynb 文件,你需要先进入 data_analysis/ 文件夹:
cd data_analysis然后使用以下命令初始化一个新的 Jupyter Notebook:
jupyter notebook现在你可以在浏览器中通过 http://locahost:8888 访问 Jupyter Notebook App。
在界面中点击 “New > Python 3 (ipykernel)” 来创建一个新的文件:
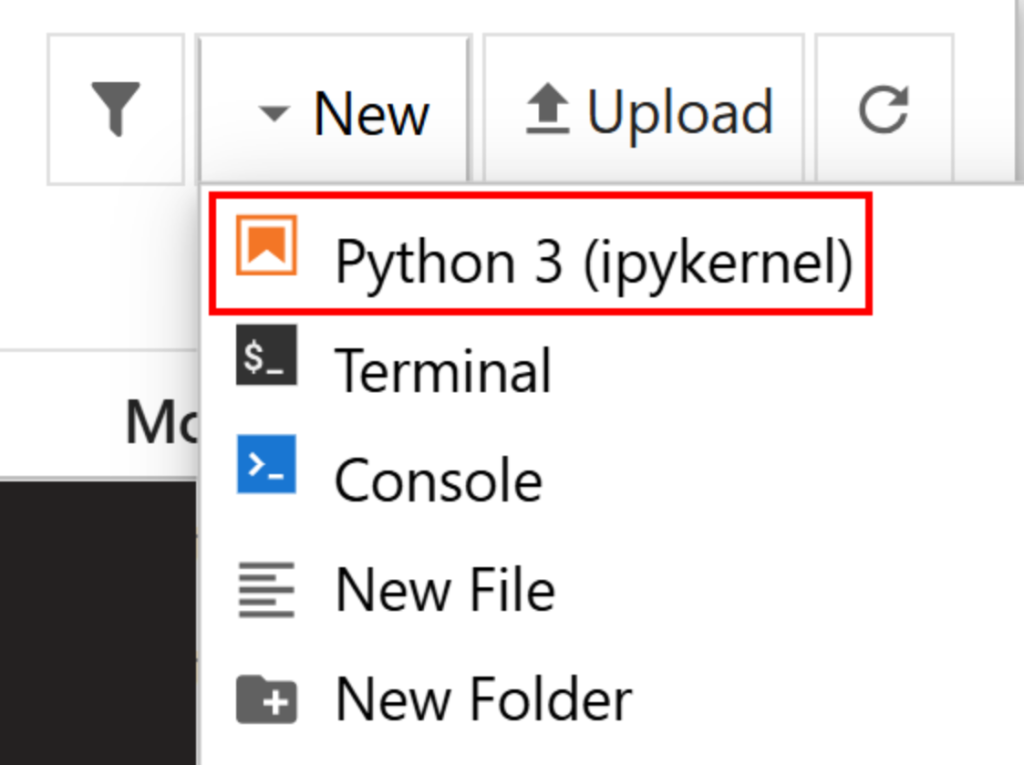
默认情况下,新文件名为 untitled.ipynb。你可以在控制台中将其重命名:
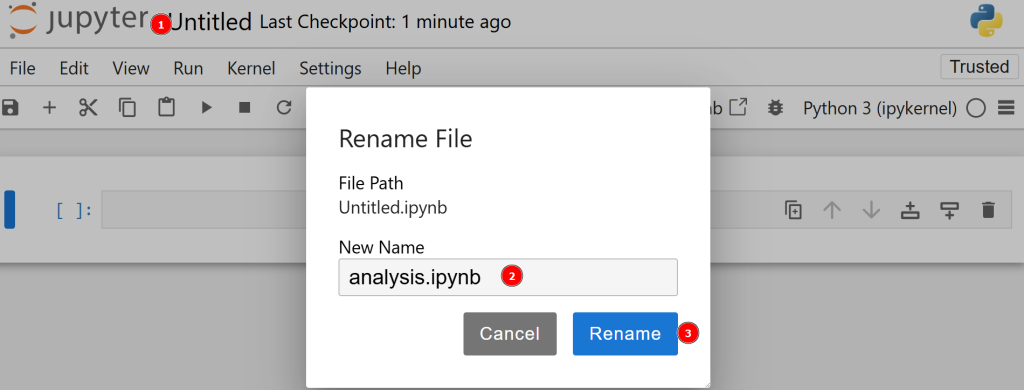
很好!至此,你已经为 Python 数据分析设置好了环境。
步骤 2:下载并打开数据
本教程中使用的数据集来自 Bright Data 的数据集市场。要下载该数据集,你可以在平台上免费注册,并进入你的用户仪表盘。然后,依次进入 “Web Datasets > Dataset” 查找数据集市场:
向下滚动并在页面中寻找 “Airbnb Properties Information” 卡片:
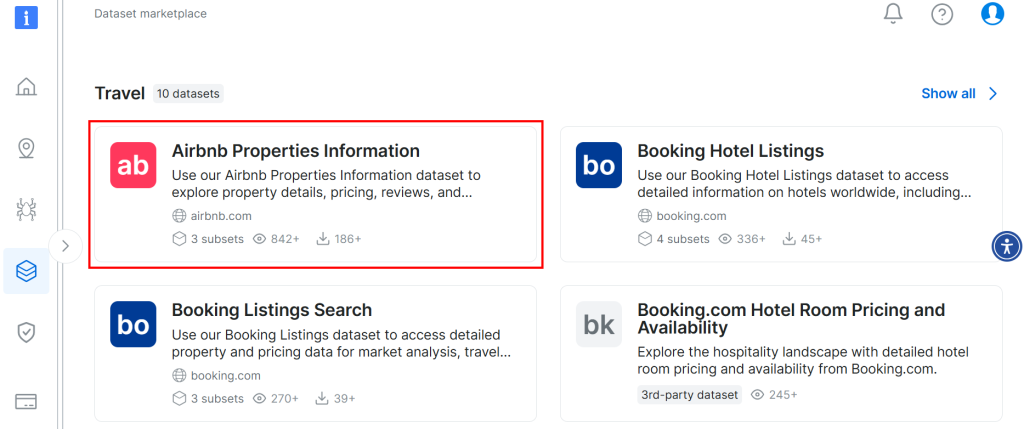
点击 “Download sample > Download as CSV” 即可下载数据集:
你可以将下载好的文件重命名,比如叫 airbnb.csv。在 Jupyter Notebook 中打开 CSV 文件,代码如下:
import pandas as pd
# Open CSV
data = pd.read_csv("airbnb.csv")
# Show head
data.head()具体说明如下:
read_csv()方法将 CSV 文件读取为 pandas 数据集。head()方法显示该数据集的前 5 行。
预期输出如下所示:
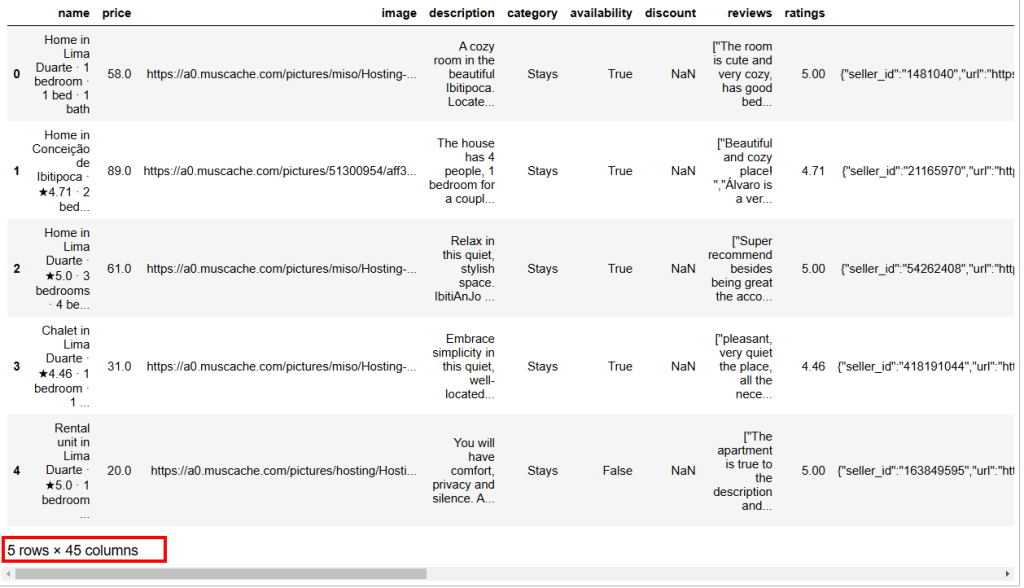
如你所见,该数据集包含 45 列。虽然可以向右滚动查看更多列,但由于列数量较多,依旧有部分列被隐藏。
要完整显示所有列,请在单独的 cell 中输入:
# Show all columns
pd.set_option("display.max_columns", None)
# Display the data frame
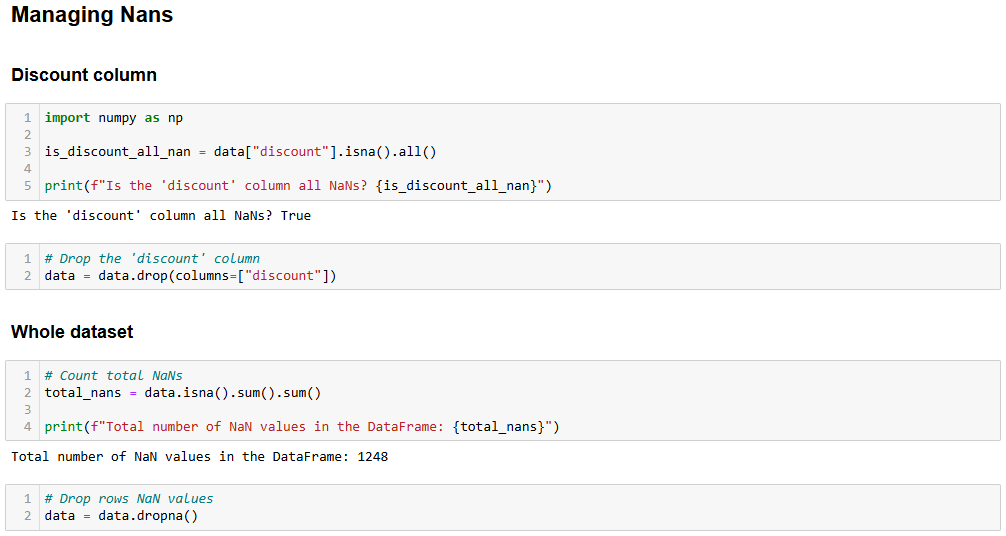
print(data)步骤 3:处理 NaN
在计算中,NaN 表示 “Not a Number”。在使用 Python 进行数据分析时,可能遇到数值空缺、字符串类型数据原本应该是数字,或已经标记为 NaN 的情况(比如上图中的 discount 列)。
你的目标是分析数据,因此必须妥善处理 NaN。一般有三种应对方式:
- 删除所有包含
NaN的行。 - 将某列的
NaN替换为该列中其他数字的均值。 - 寻找新的数据来丰富源数据集。
在本例中,我们为了简单起见,采用第一种方式。
首先,你需要检查 discount 列的所有值是否都是 NaN。如果是,就可以删除整个列。以下代码可以实现检查:
import numpy as np
is_discount_all_nan = data["discount"].isna().all()
print(f"Is the 'discount' column all NaNs? {is_discount_all_nan}")在这个示例中,isna().all() 用来查看 discount 列(通过 data["discount"] 筛选得到)是否全部为 NaN。
运行后会得到结果 True,说明 discount 列的值全为 NaN。因此可将其删除:
data = data.drop(columns=["discount"])这样,原始数据集就被新的数据集覆盖,现在没有 discount 列了。
然后你可以分析整个数据集,检查是否还有其他 NaN 值:
total_nans = data.isna().sum().sum()
print(f"Total number of NaN values in the data frame: {total_nans}")输出结果如下:
Total number of NaN values in the data frame: 1248这说明数据框中还有 1248 个 NaN。要删除所有包含至少一个 NaN 的行,可执行:
data = data.dropna()现在 data 数据框中已经没有 NaN 值了,不用担心它会对分析结果造成偏差。
可使用以下命令确认是否操作成功:
print(data.isna().sum().sum())预期结果是 0。
步骤 4:数据探索
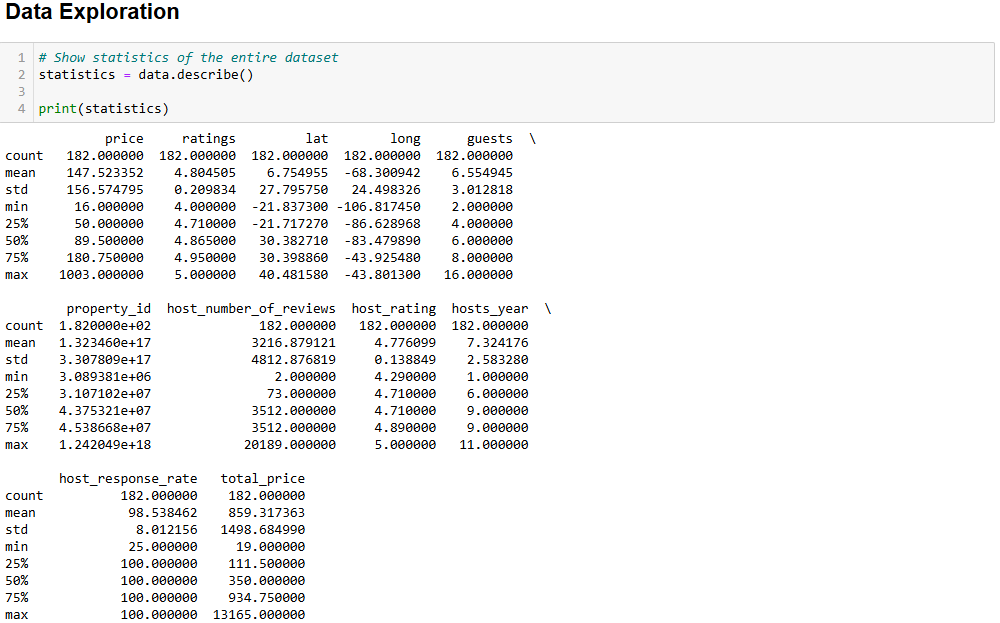
在可视化 Airbnb 数据之前,你需要先熟悉它。一个很好的做法是先查看数据的统计信息:
# Show statistics of the entire dataset
statistics = data.describe()
# Print statistics
print(statistics)预期结果如下:
price ratings lat long guests
count 182.000000 182.000000 182.000000 182.000000 182.000000
mean 147.523352 4.804505 6.754955 -68.300942 6.554945
std 156.574795 0.209834 27.795750 24.498326 3.012818
min 16.000000 4.000000 -21.837300 -106.817450 2.000000
25% 50.000000 4.710000 -21.717270 -86.628968 4.000000
50% 89.500000 4.865000 30.382710 -83.479890 6.000000
75% 180.750000 4.950000 30.398860 -43.925480 8.000000
max 1003.000000 5.000000 40.481580 -43.801300 16.000000
property_id host_number_of_reviews host_rating hosts_year
count 1.820000e+02 182.000000 182.000000 182.000000
mean 1.323460e+17 3216.879121 4.776099 7.324176
std 3.307809e+17 4812.876819 0.138849 2.583280
min 3.089381e+06 2.000000 4.290000 1.000000
25% 3.107102e+07 73.000000 4.710000 6.000000
50% 4.375321e+07 3512.000000 4.710000 9.000000
75% 4.538668e+07 3512.000000 4.890000 9.000000
max 1.242049e+18 20189.000000 5.000000 11.000000
host_response_rate total_price
count 182.000000 182.000000
mean 98.538462 859.317363
std 8.012156 1498.684990
min 25.000000 19.000000
25% 100.000000 111.500000
50% 100.000000 350.000000
75% 100.000000 934.750000
max 100.000000 13165.000000 describe() 方法会显示所有数值型列的统计信息,这是理解数据的第一步。例如,host_rating 列包含以下有趣的统计结果:
- 数据集中有 182 条评价(
count值)。 - 最高评分是 5,最低评分是 4.29,平均评分是 4.77。
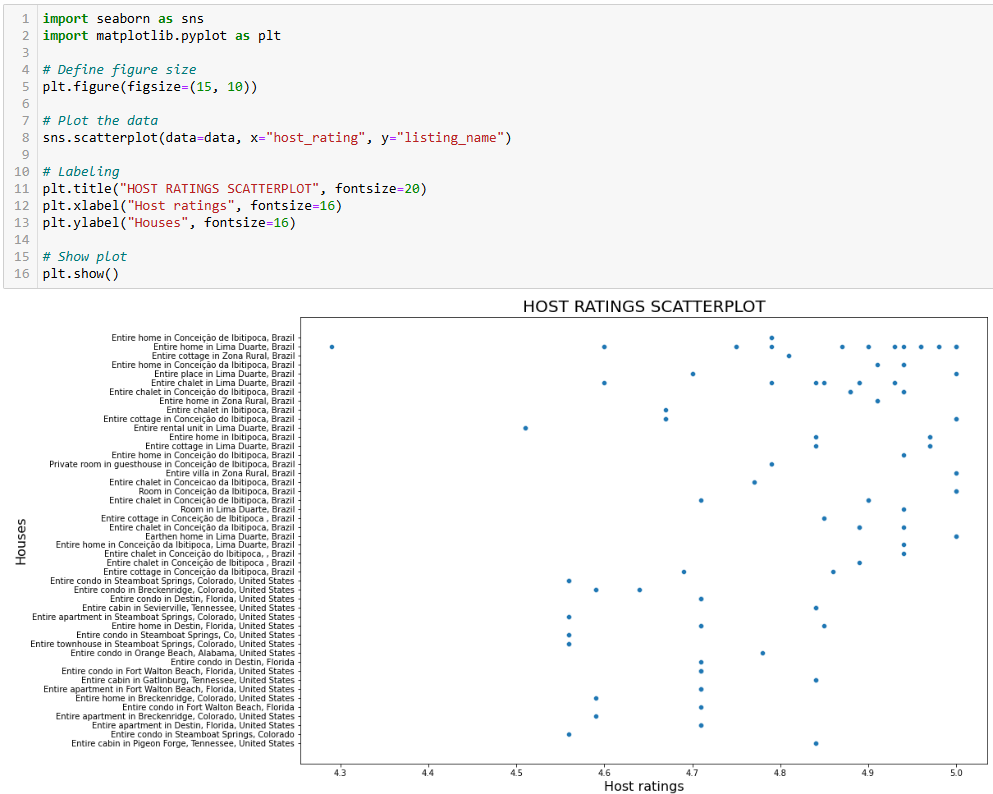
如果想更深入地了解 host_rating 列中是否存在一些特殊的分布,可以画一张散点图。下面是使用 seaborn 画散点图的示例:
import seaborn as sns
import matplotlib.pyplot as plt
# Define figure size
plt.figure(figsize=(15, 10))
# Plot the data
sns.scatterplot(data=data, x="host_rating", y="listing_name")
# Labeling
plt.title("HOST RATINGS SCATTERPLOT", fontsize=20)
plt.xlabel("Host ratings", fontsize=16)
plt.ylabel("Houses", fontsize=16)
# Show plot
plt.show()上述代码:
- 通过
figure()方法定义图像大小(单位英寸)。 - 使用
scatterplot()绘制散点图,其中:data=data表示使用data数据框。x="host_rating"将房东评分放在横轴。y="listing_name"将房源名字放在纵轴。
预期结果如下图所示:
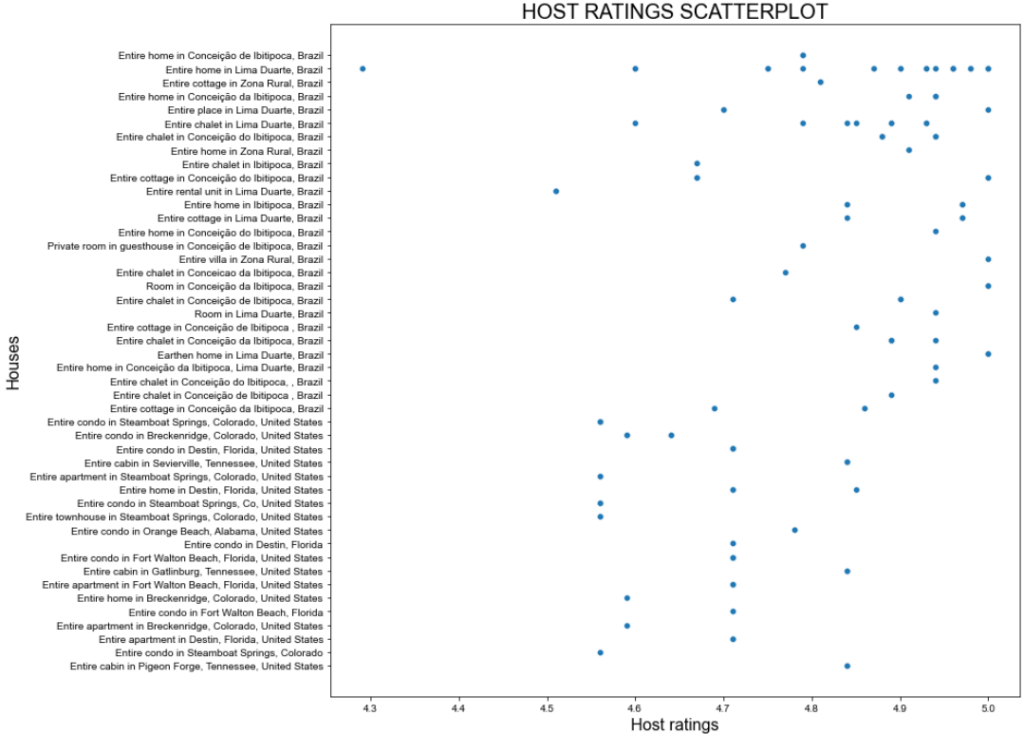
这张图虽然不错,但我们还可以进一步优化!
步骤 5:数据转换与可视化
上一步的散点图显示房东评分并无特别明显的模式,但多数评分都高于 4.7 分。
假设你计划去度假,想要住评分较高的地方,就会产生一个问题:“入住评分至少为 4.8 的房源要花多少钱?”
要回答这个问题,你首先需要转换数据!
操作思路是:筛选出评分大于 4.8 的数据并创建一个新的数据框,仅包含 listing_name(房源名称)和 total_price(总价格)两个列。
获取这个子集并查看统计信息:
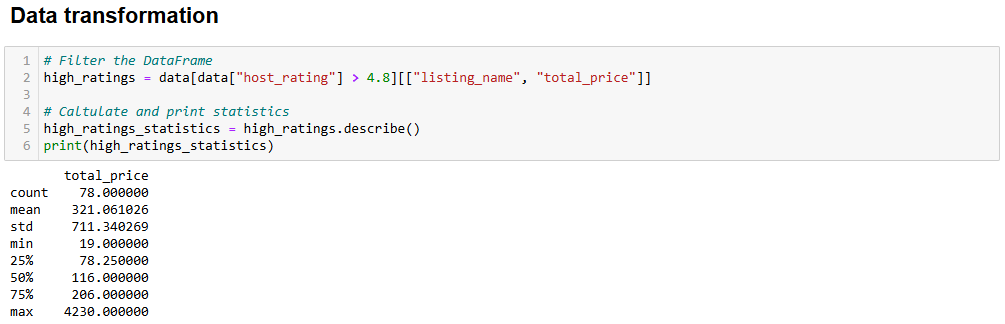
# Filter the DataFrame
high_ratings = data[data["host_rating"] > 4.8][["listing_name", "total_price"]]
# Caltulate and print statistics
high_ratings_statistics = high_ratings.describe()
print(high_ratings_statistics)上面这段代码中新数据框 high_ratings 的生成逻辑如下:
data["host_rating"] > 4.8:筛选出原数据集中房东评分大于 4.8 的行。[["listing_name", "total_price"]]:从筛选后的结果中仅保留listing_name和total_price两列。
预期输出如下:
total_price
count 78.000000
mean 321.061026
std 711.340269
min 19.000000
25% 78.250000
50% 116.000000
75% 206.000000
max 4230.000000可以看出,这些房源的平均总价是 321 美元,最低 19 美元,最高 4230 美元。这值得进一步分析!
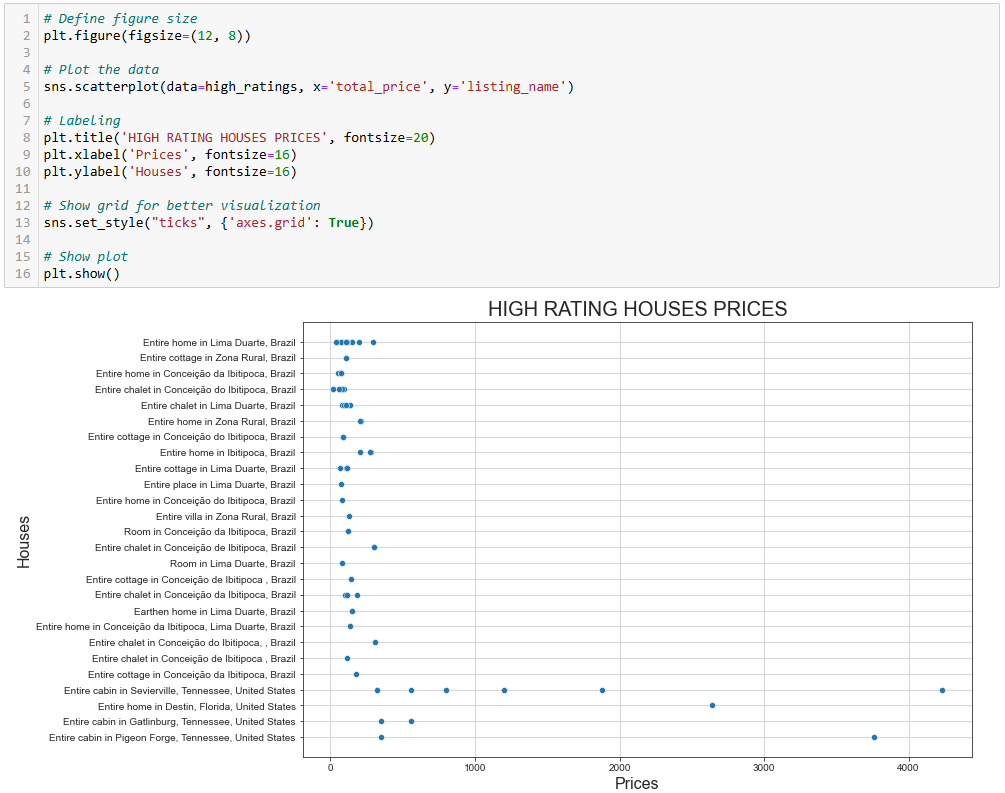
我们可以用之前的代码范例再绘制一次散点图,只需将变量换成所需的列:
# Define figure size
plt.figure(figsize=(12, 8))
# Plot the data
sns.scatterplot(data=high_ratings, x='total_price', y='listing_name')
# Labeling
plt.title('HIGH RATING HOUSES PRICES', fontsize=20)
plt.xlabel('Prices', fontsize=16)
plt.ylabel('Houses', fontsize=16)
# Show grid for better visualization
sns.set_style("ticks", {'axes.grid': True})
# Show plot
plt.show()生成的图表如下:
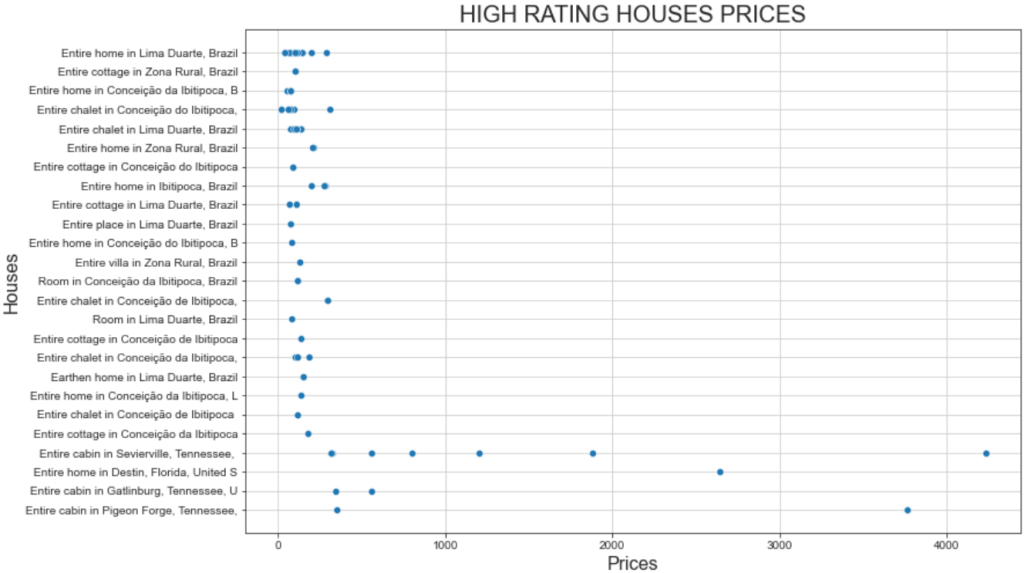
这张图揭示了两个有趣的现象:
- 大部分房源价格主要集中在 500 美元以下。
- “Entire Cabin in Sevierville”和 “Entire Cabin in Pigeon” 的价格远高于 1000 美元。
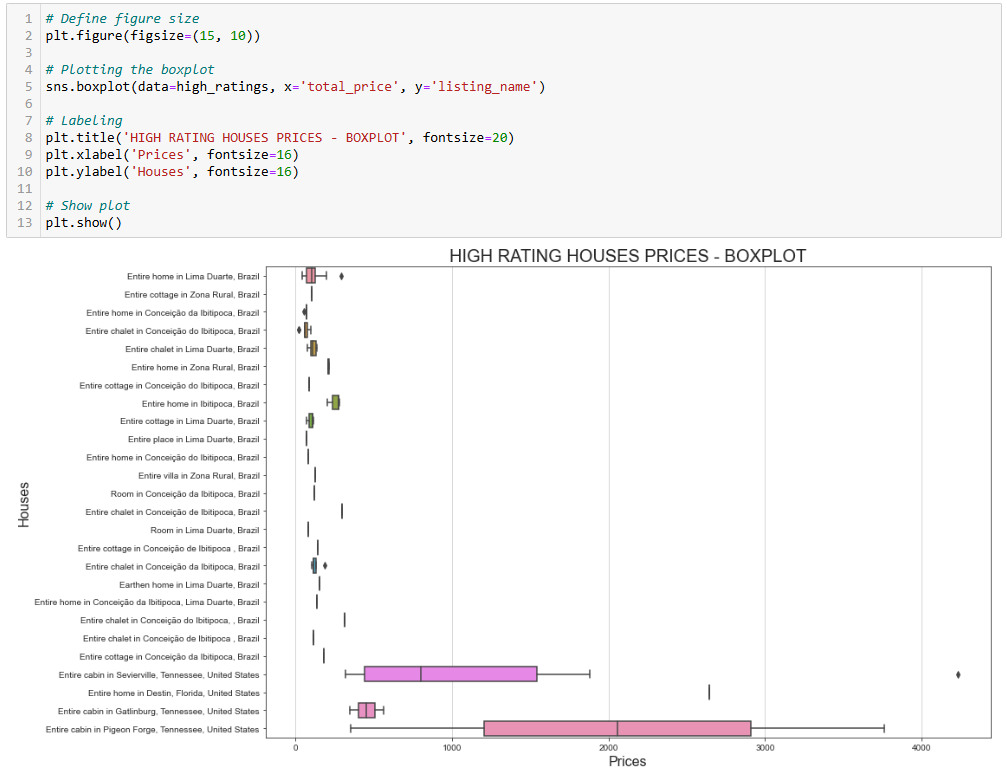
若想更好地可视化价格区间,可以使用箱线图(box plot):
# Define figure size
plt.figure(figsize=(15, 10))
# Plotting the boxplot
sns.boxplot(data=high_ratings, x='total_price', y='listing_name')
# Labeling
plt.title('HIGH RATING HOUSES PRICES - BOXPLOT', fontsize=20)
plt.xlabel('Prices', fontsize=16)
plt.ylabel('Houses', fontsize=16)
# Show plot
plt.show()这次生成的图表如下:
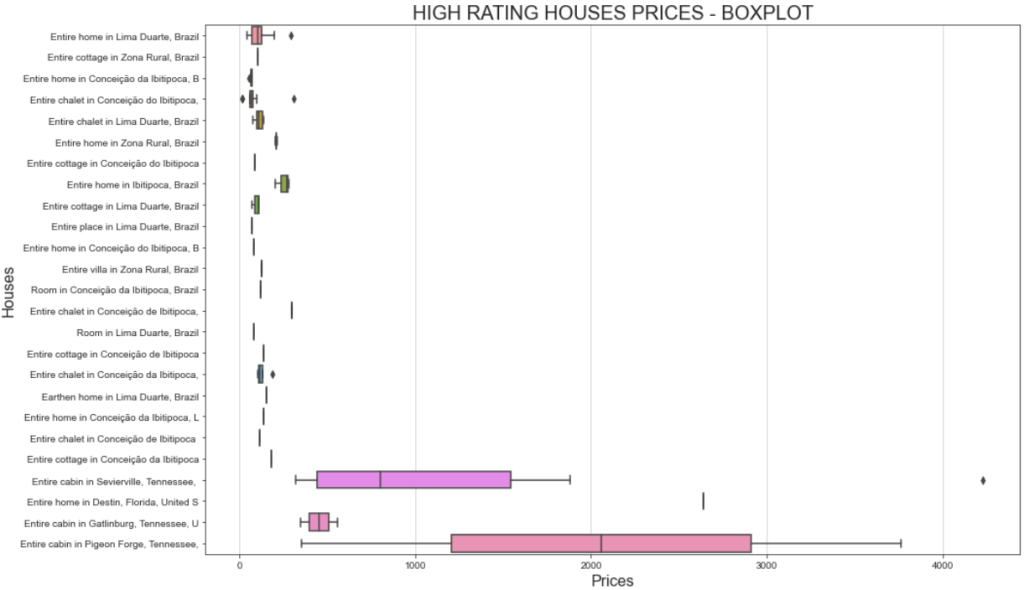
如果你想知道为什么同一个房源有不同价格,记住我们上一步筛选的是用户评分,这意味着不同用户在不同价位入住后给出了评分。
此外,Sevierville 的整套小木屋(Entire Cabin)价格跨度较大,从不到 1000 美元到超过 4000 美元,这很可能和入住时长有关。该原始数据集中有个名为 travel_details 的列,其中包含入住时长的信息。价格大幅变化说明有旅客租住的时间更久。要搞清更多细节,可以进一步在 Python 中挖掘。
步骤 6:通过相关矩阵进行更深入的探索
Python 数据分析的过程就是不断提出问题并在已有数据中寻找答案。可视化相关矩阵是激发新问题的好办法之一。
相关矩阵是一张表格,显示不同变量之间的相关系数。最常见的相关系数是皮尔逊相关系数(PCC),用于衡量两个变量之间的线性相关性,其取值范围为 -1 到 +1:
- +1:如果一个变量的值增大,另一个变量也以线性关系增大。
- -1:如果一个变量的值增大,另一个变量则以线性关系减小。
- 0:无法确定两者之间的线性关系(需进一步的非线性分析)。
在统计学中,线性相关程度往往这样分类:
- 0.1-0.5:低相关。
- 0.6-1:高度相关。
- 0:无相关。
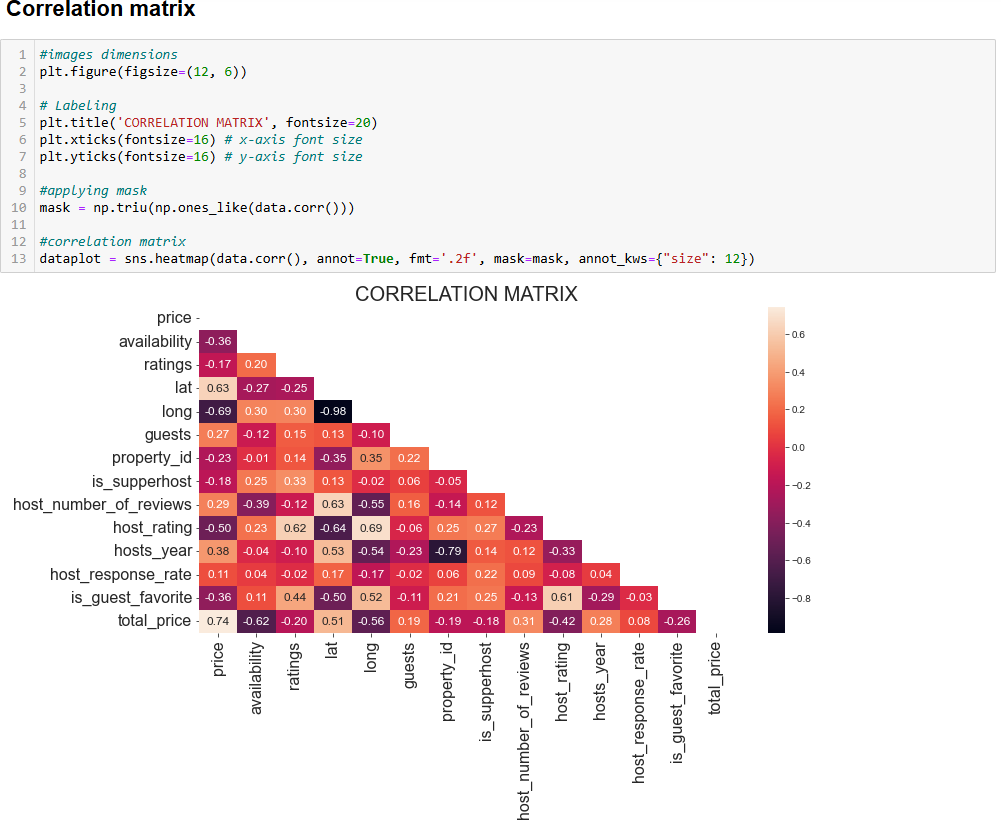
以下代码可显示 data 数据框的相关矩阵:
# Set the images dimensions
plt.figure(figsize=(12, 10))
# Labeling
plt.title('CORRELATION MATRIX', fontsize=20)
plt.xticks(fontsize=16) # x-axis font size
plt.yticks(fontsize=16) # y-axis font size
# Applying mask
mask = np.triu(np.ones_like(data.corr()))
# Correlation matrix
dataplot = sns.heatmap(data.corr(), annot=True, fmt='.2f', mask=mask, annot_kws={"size": 12})上面的代码功能如下:
np.triu()用于对矩阵进行上三角处理,以便更美观地显示为三角形而非方形。sns.heatmap()用于绘制热力图,其内的data.corr()会计算各列之间的皮尔逊相关系数。
下图是你会看到的效果:
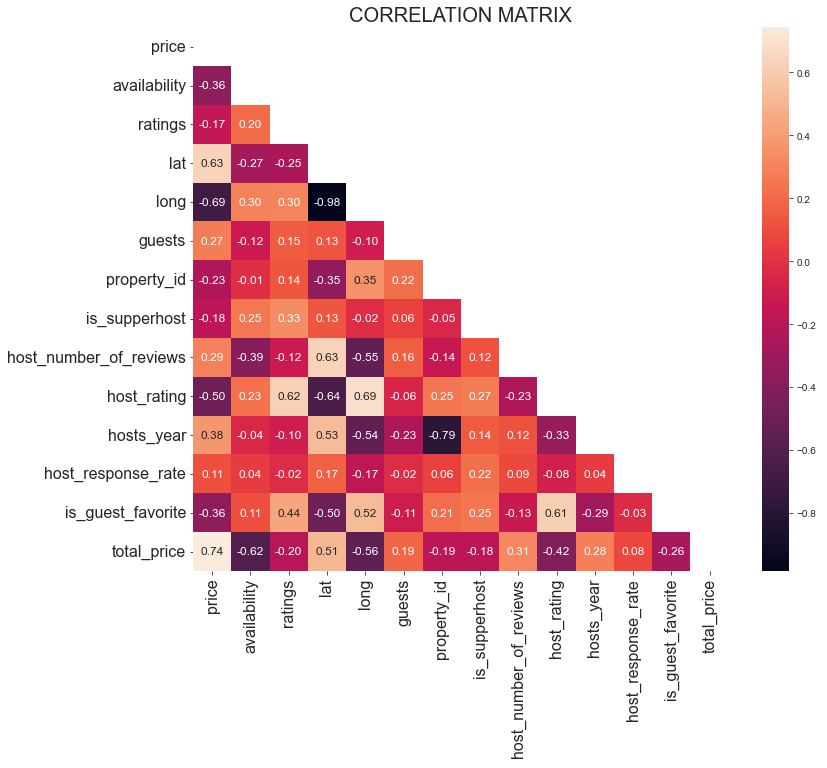
在解释相关矩阵时,核心思路是寻找高度相关的变量,这将成为你后续深入探索的起点。例如:
lat和long的相关系数约为 -0.98,表明它们在定位地理位置时高度相关,这合情合理。host_rating和long的相关系数约为 -0.69,这很有意思,意味着房东评分与经度之间存在较强的负相关关系。看起来某些区域的房东评分普遍更高。lat与price的相关系数约为 0.63,而long与price的相关系数约为 -0.69,表示地理位置确实对价格有较大影响。
同时,你也应关注不相关或低相关的变量。比如 is_supperhost 和 price 的相关系数约为 -0.18,说明超级房东并不一定收费更高。
了解完这些主要概念后,轮到你亲自探索并分析你的数据了!
步骤 7:整合所有内容
最终,你的 Jupyter Notebook 可能类似如下所示:
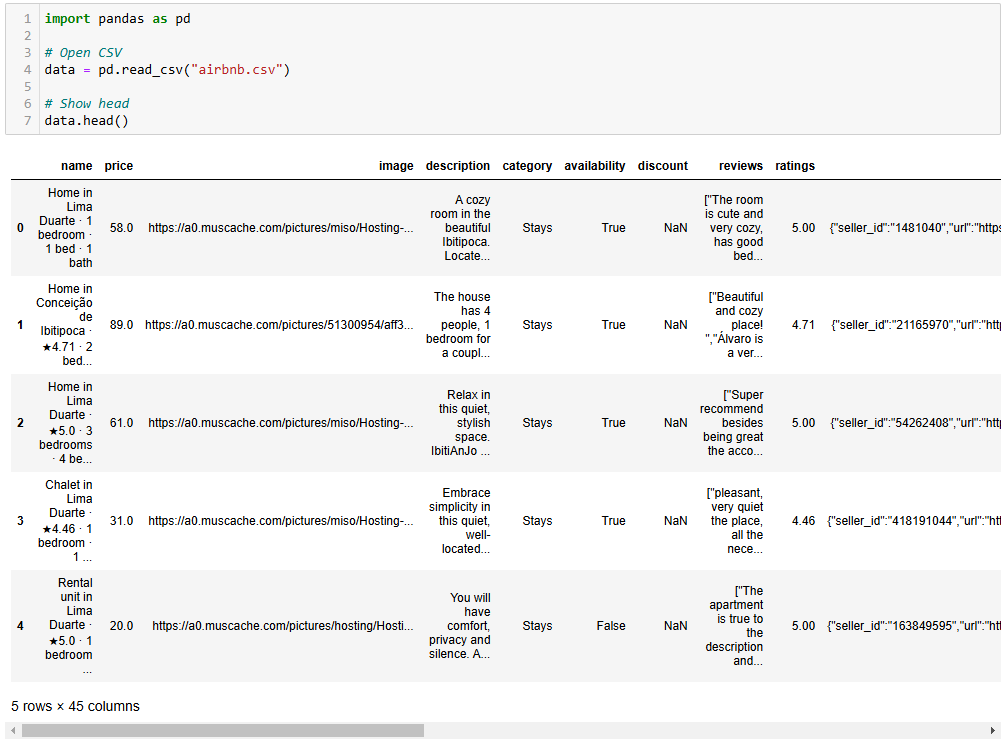
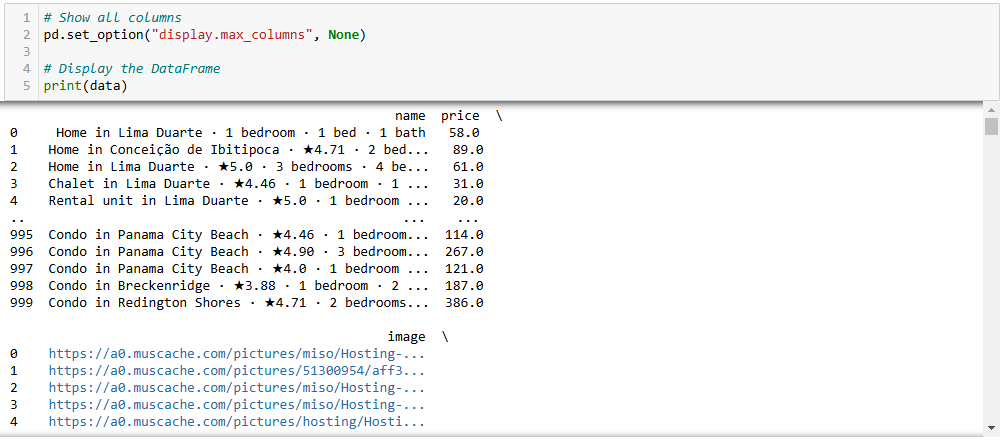
可以看到,Notebook 中分了多个单元格,每个单元格都有相应的输出。
Python 数据分析的流程
前面的小节带你了解了如何使用 Python 分步完成数据分析。虽然看起来像机会驱动的步骤,但其实背后有一套最佳实践:
- 数据获取:如果你非常幸运,所需数据保存在现成的数据库中,那就很简单。如果没有,你需要通过流行的数据采集方法(例如爬虫)来获取数据。
- 数据清洗:处理
NaN、聚合数据,并对初始数据集做初步筛选。 - 数据探索:数据探索(有时也称数据发现)是 Python 数据分析中最关键的部分,需要借助基本图表来帮助你了解数据结构并发掘它可能呈现的模式。
- 数据操作:在大致了解数据后,需要对其进行进一步操作,包括过滤和(在类似 SQL 的场景下)将多个数据集合并成一个。
- 数据可视化:这是最后一步,通过对处理后的数据集进行多种图表可视化,向他人展示数据所蕴含的价值。
总结
在这篇 Python 数据分析指南中,你了解了为什么要用 Python 来分析数据,以及可以借助哪些常用库来完成该任务。你还看到如何通过分步教程,以及要遵循的流程来完成 Python 中的数据分析。
你见识到了 Jupyter Notebook 在创建数据子集、可视化以及挖掘洞察方面的强大功能,并且一切都在同一个环境下完成。那去哪里能找到现成的数据集呢?Bright Data 已为你准备好一切!
Bright Data 拥有一个速度快且可靠的代理网络,被众多财富 500 强企业以及超过 20,000 个客户使用,以合法合规的方式从网络中获取数据,并提供在庞大会数据集市场,可供你选择:
- 商业数据集:来自 LinkedIn、CrunchBase、Owler 和 Indeed 等主要数据源。
- 电商数据集:来自 Amazon、Walmart、Target、Zara、Zalando、Asos 等。
- 房产数据集:来自 Zillow、MLS 等网站。
- 社交媒体数据集:包含 Facebook、Instagram、YouTube、Reddit 等平台的数据。
- 金融数据集:包括 Yahoo Finance、Market Watch、Investopedia 等在内的数据。
立即创建一个 Bright Data 免费账号,探索我们的数据集吧。
支持支付宝等多种支付方式



