

在本指南中,你将学习:
- 什么是 CloudScraper,以及它可以用于什么
- 为什么你应当在 CloudScraper 中集成代理
- 如何按照分步骤的方式来实现代理配置
- 如何在 CloudScraper 中实现代理轮换
- 如何处理需要身份验证的代理
- 如何使用类似 Bright Data 这类高级代理提供商
让我们开始吧!
什么是 CloudScraper?
CloudScraper 是一个 Python 模块,旨在绕过 Cloudflare 的反机器人页面(通常称为 “I’m Under Attack Mode” 或 IUAM)。它在底层基于 Requests 实现,而 Requests 是最流行的 Python HTTP 客户端之一。
对于 爬取或抓取受 Cloudflare 保护的网站,这个库非常实用。Cloudflare 的反机器人页面当前会检测客户端是否支持 JavaScript,但将来 Cloudflare 可能会引入更多的检测手段。
由于 Cloudflare 会定期更新它的反机器人策略,CloudScraper 也会定期更新以保持可用性。
为什么要在 CloudScraper 中使用代理?
如果你发送过多请求,Cloudflare 可能会封禁你的 IP。同样,Cloudflare 有可能触发更高级的防护机制,即使有 CloudScraper 也不一定能轻易绕过。为缓解此问题,你需要一种可靠的方法来 轮换 IP 地址。
这就是使用 代理服务器 的原因所在。代理在你的爬虫与目标网站之间扮演中间人的角色,用代理服务器的 IP 替换你的真实 IP。如果某个 IP 被封禁,你可以快速切换到新的代理,确保持续访问。
对于在 CloudScraper 中进行网页爬取,代理能带来两个关键好处:
- 提升安全性与匿名性:通过代理进行请求,可以隐藏你的真实身份,降低被检测的风险。
- 避免封禁与中断:代理支持动态地轮换 IP 地址,帮助绕过封禁与速率限制。
将代理与像 CloudScraper 这样的工具结合起来,可以构建一个风险更低、效率更高的爬虫方案。双管齐下,即使目标站点拥有先进的 反爬措施,也能实现安全、顺畅的数据采集。
在 CloudScraper 中设置代理:分步骤指南
在接下来的部分,你将学习如何在 CloudScraper 中使用代理!
步骤 #1:安装 CloudScraper
你可以通过 cloudscraper pip 包来安装 CloudScraper,使用以下命令:
pip install -U cloudscraper请记住,Cloudflare 会不断更新它的反机器人引擎。因此,安装时最好加上 -U 参数,以确保你得到的是最新版本。
步骤 #2:初始化 Cloudscraper
首先导入 CloudScraper:
import cloudscraper接着,使用 create_scraper() 方法创建一个 CloudScraper 实例:
scraper = cloudscraper.create_scraper()scraper 对象的用法与 requests 库中的 Session 对象类似。它可以帮助你在发送 HTTP 请求时绕过 Cloudflare 的反机器人措施。
步骤 #3:集成代理
由于 CloudScraper 是基于 Requests 构建的,因此集成代理的方法与 requests 中完全相同。如果你还不熟悉,可以阅读我们关于 在 Requests 中设置代理的教程。
要在 CloudScraper 中使用代理,你需要定义一个 proxies 字典,然后把它传给 get() 方法,如下所示:
proxies = {
"http": "<YOUR_HTTP_PROXY_URL>",
"https": "<YOUR_HTTPS_PROXY_URL>"
}
# Perform a request through the specified proxy
response = scraper.get("<YOUR_TARGET_URL>", proxies=proxies)get() 方法中的 proxies 参数最终会被传给 Requests,用于将你的请求通过所设置的 HTTP 或 HTTPS 代理服务器发送,这取决于目标 URL 的协议。
步骤 #4:测试 CloudScraper 的代理集成配置
为了演示,我们将请求发送到 HTTPBin 项目的 /ip 端点。该端点会返回调用方的 IP 地址。如果一切正常,返回结果应显示代理服务器的 IP 地址。
在测试时,你可以从某个 免费代理列表 获得一个代理服务器 IP。
警告:免费代理通常不可靠、可能窃取数据或存在潜在安全风险,尤其是在它们不属于 市场上顶级的代理提供商 时。仅建议在学习目的下使用它们。
假设你的代理服务器 URL 如下所示:
http://202.159.35.121:443你可以像下面这样将其集成进 CloudScraper:
import cloudscraper
# Create a CloudScraper instance
scraper = cloudscraper.create_scraper()
# Specify your proxy
proxies = {
"http": "http://202.159.35.121:443",
"https": "http://202.159.35.121:443"
}
# Make a request through the proxy
response = scraper.get("https://httpbin.io/ip", proxies=proxies)
# Print the response from the "/ip" endpoint
print(response.text)如果配置正确,你会看到类似如下的结果:
{
origin: "202.159.35.121:1819"
}可以注意到,返回结果中的 IP 与代理服务器的 IP 相吻合。
注意: 免费代理服务器通常寿命较短。因此,当你阅读这篇文章时,示例中使用的代理可能已经无法使用。
做得好!你已经完成了一个简单的 CloudScraper 代理集成。
如何实现代理轮换
在 CloudScraper 中使用代理可以隐藏你的 IP 地址。然而,如果过多请求来自同一个 IP(无论是你的真实 IP 还是代理 IP),目标站点仍然可能会封禁这个 IP。
为 避免 IP 封禁,定期轮换代理 IP 至关重要。通过将请求分散到多个不同 IP,可以让你的流量看起来来自不同用户,从而减少被检测的可能性。
要实现代理轮换,首先需要从可靠的提供商处获取一组代理,并将其存储在一个数组中:
proxy_list = [
{"http": "<YOUR_PROXY_URL_1>", "https": "<YOUR_PROXY_URL_1>"},
# ...
{"http": "<YOUR_PROXY_URL_n>", "https": "<YOUR_PROXY_URL_n>"},
]然后使用 random.choice() 方法从列表中随机选择一个代理:
random_proxy = random.choice(proxy_list)别忘了先从 Python 的标准库中导入 random:
import random之后,只需将这个随机选择的代理传给 get() 请求即可:
response = scraper.get("<YOUR_TARGET_URL>", proxies=random_proxy)如果一切设置正确,每次运行脚本时都会使用列表中的不同代理。下面是完整代码:
import cloudscraper
import random
# Create a Cloudscraper instance
scraper = cloudscraper.create_scraper()
# List of proxy URLs (replace with actual proxy URLs)
proxy_list = [
{"http": "<YOUR_PROXY_URL_1>", "https": "<YOUR_PROXY_URL_1>"},
# ...
{"http": "<YOUR_PROXY_URL_n>", "https": "<YOUR_PROXY_URL_n>"},
]
# Randomly select a proxy from the list
random_proxy = random.choice(proxy_list)
# Make a request using the randomly selected proxy
# (replace with the actual target URL)
response = scraper.get("<YOUR_TARGET_URL>", proxies=random_proxy)恭喜!你已经在 CloudScraper 中集成了代理轮换功能。
在 CloudScraper 中使用需要身份验证的代理
大多数代理提供商都会提供需要身份验证的代理服务器,以确保只有付费用户可以访问。通常,你需要提供用户名和密码才能访问这些代理服务器。
要在 CloudScraper 中使用需要身份验证的代理,需要在代理 URL 中直接包含相应的凭证。其格式如下:
<PROXY_PROTOCOL>://<YOUR_USERNAME>:<YOUR_PASSWORD>@<PROXY_IP_ADDRESS>:<PROXY_PORT>基于这种格式,你可以这样在 CloudScraper 中配置代理:
import cloudscraper
# Create a Cloudscraper instance
scraper = cloudscraper.create_scraper()
# Define your authenticated proxy
proxies = {
"http": "<PROXY_PROTOCOL>://<YOUR_USERNAME>:<YOUR_PASSWORD>@<PROXY_IP_ADDRESS>:<PROXY_PORT>",
"https": "<PROXY_PROTOCOL>://<YOUR_USERNAME>:<YOUR_PASSWORD>@<PROXY_IP_ADDRESS>:<PROXY_PORT>"
}
# Perform a request through the specified authenticated proxy
response = scraper.get("<YOUR_TARGET_URL>", proxies=proxies)太棒了!接下来看看如何在 Cloudflare 中使用高级代理。
在 Cloudscraper 中集成高级代理
如果你想在生产环境中进行可靠的网页抓取,应该选择像 Bright Data 这样的顶级代理提供商。Bright Data 拥有覆盖全球范围的 72+ 百万 IP,分布在 195 个国家,并支持四种主要类型的代理:
- 数据中心代理
- 住宅代理
- 移动代理
- ISP 代理
Bright Data 具备自动 IP 轮换、100% 稳定在线、以及长效会话等特性,在市场上被视为领先的代理服务商。
要将 Bright Data 的代理集成到 CloudScraper,请先创建账户或登录账号。在仪表板中点击表格中的 “Residential” 区域:
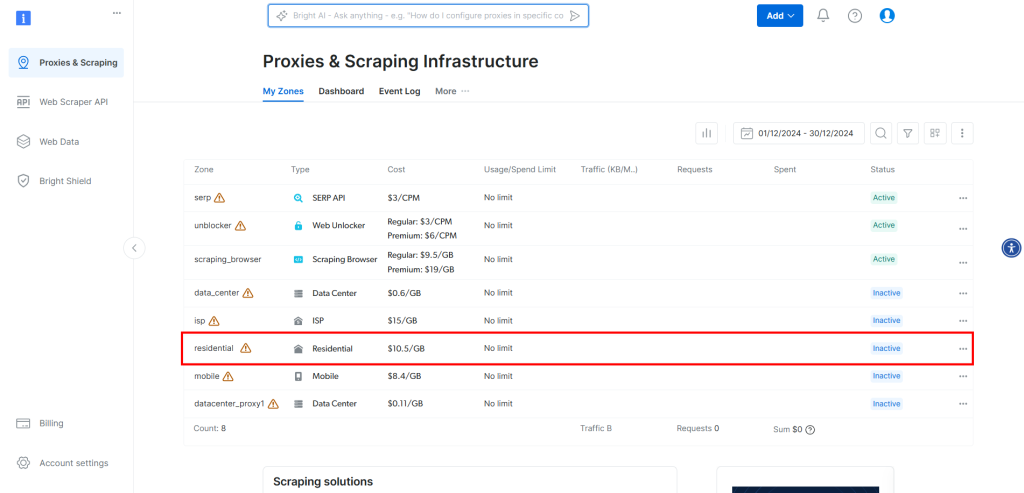
在这里,点击开关启用代理:

此时,你会看到如下界面:

在 “Access Details” 部分,复制代理主机、用户名以及密码:
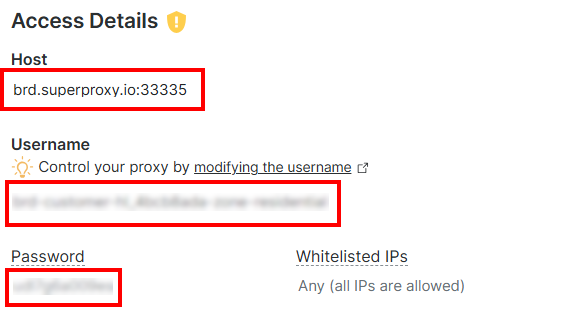
你的 Bright Data 代理 URL 将类似如下:
http://<PROXY_USERNAME>:<PROXY_PASSOWRD>@brd.superproxy.io:33335现在,将该代理集成到 CloudScraper 中:
import cloudscraper
# Create CloudScraper instance
scraper = cloudscraper.create_scraper()
# Define the Bright Data proxy
proxies = {
"http": "http://<PROXY_USERNAME>:<PROXY_PASSOWRD>@brd.superproxy.io:33335",
"https": "http://<PROXY_USERNAME>:<PROXY_PASSOWRD>@brd.superproxy.io:33335"
}
# Perform a request using the proxy
response = scraper.get("https://httpbin.io/ip", proxies=proxies)
# Print the repsonse
print(response.text)请注意,Bright Data 的住宅代理会自动轮换 IP,因此每次运行脚本时都会得到不同的 IP。
完成!这样就成功在 CloudScraper 中集成了代理。
结论
在本教程中,你学习了如何让 CloudScraper 与代理结合使用以获得最佳效果。你不仅掌握了在这个 Python 抓取绕过 Cloudflare 的工具中进行基础代理集成的方法,还了解了更高级的技巧,比如代理轮换。
若想获得更佳的结果,使用高质量代理提供商提供的 IP 服务器就容易得多,例如 Bright Data。
Bright Data 拥有全球最佳的代理服务器,为世界 500 强企业与超过 20,000 家客户服务。其全球代理网络包括:
- 数据中心代理 – 超过 770,000 个数据中心 IP。
- 住宅代理 – 覆盖 195 多个国家/地区的 72M+ 住宅 IP。
- ISP 代理 – 超过 700,000 个 ISP IP。
- 移动代理 – 超过 7M 个移动 IP。
总体而言,这是一套规模庞大且稳定性极高的代理网络。
立即创建一个 Bright Data 免费账号,亲身试用我们的代理服务器吧。


