

在本指南中,您将了解到:
- Cloudflare是什么
- 为什么其WAF解决方案会对您的抓取脚本构成挑战
- 如何使用一体化解决方案绕过Cloudflare WAF
- 如何应对它所运用的每项主要反机器人措施
让我们开始吧!
Cloudflare是什么?
Cloudflare是一家网络基础设施和安全公司,互联网上其中一个最大的网络就是由其运营。它提供一套全面的服务,旨在使网站更快和更安全。
Cloudflare的核心目的主要是发挥CDN(内容分发网络)的功能,在一个全球网络上缓存网站内容,以缩短加载时间并减少延迟。此外,它还提供其他功能,包括DDoS(分布式拒绝服务)防御、WAF(网络应用程序防火墙)、机器人管理、DNS服务等。
通过与Cloudflare的网络集成,网站可以快速增强安全性和优化性能。这使得Cloudflare成为全球数以百万计的网站的首选解决方案。
Cloudflare WAF概述
WAF是网络应用程序防火墙的简称,它是一种安全系统,能过滤和监控网络应用程序与互联网之间的HTTP流量。它有助于保护网站免受DDoS、跨站点脚本(XSS)、SQL注入等恶意活动的攻击。
Cloudflare WAF尤其著名,是世界上使用最广泛的WAF解决方案之一。Cloudflare如此受欢迎,是因为其CDN功能被广泛采用。如果网站已经在Cloudflare上,只需点击几下即可启用WAF(使用默认配置)。
Cloudflare WAF实施的主要反机器人技术和技巧包括:
- 速率限制:限制一个IP在特定时间范围内可以发出的请求数量,以阻止DDoS攻击和防止暴力破解企图。
- JavaScript挑战:验证访客是否可以执行JavaScript(这是真实用户的典型行为)。
- Turnstile CAPTCHA:向疑为机器人者发出CAPTCHA验证码测试。
- IP信誉:维护信誉数据库,以能立即屏蔽可疑IP地址。
- 行为分析 :监控访客行为以检测自动模式或异常活动。
受Cloudflare WAF保护的网站通常会采用一种或多种反机器人解决方案来阻止自动请求。这些防御措施的组合,使得抓取受Cloudflare保护的网站变得特别具有挑战性。
在抓取网站时避開Cloudflare屏蔽的首选解决方案
探索在受Cloudflare保护的网站上进行网页抓取的首选方法,了解其最佳解决方案和构思。
完全绕过Cloudflare
别忘了,Cloudflare能发挥CDN的作用,这意味着它会在分布于多个地理位置的服务器上缓存和分发网站内容。因此,要访问通过Cloudflare分发的网站,通常只能通过CDN网络中的服务器进行。
现在,想象一下,如果您能够找出CDN背后的网站服务器的IP地址。结果就是您可以与该网站进行交互,完全绕过Cloudflare。毕竟,Cloudflare只能评估通过其网络的请求。
要做到这一点,可以查看SecurityTrails等DNS历史记录查询工具,以找出任何揭示原始服务器IP地址的DNS历史记录。获得IP后,您可以尝试直接向服务器发送请求,避开Cloudflare。
问题是,服务器可能会有额外的配置,只能接受来自Cloudflare的IP范围的请求。在这种情况下,直接连接网站而不被屏蔽,几乎是不可能的。此外,要成功找到原始服务器IP也非常困难,可能性很低。
免费Cloudflare解算器
在网上可以找到几个为绕过Cloudflare而设计的免费开源库。其中一些最受欢迎的包括:
- cloudscraper:一个处理Cloudflare反机器人挑战的Python模块。
- Cfscrape: 一个轻量级PHP模块,用于绕过Cloudflare的反机器人网页。
- Humanoid: 一个Node.js软件包,用于绕过Cloudflare的JavaScript反机器人挑战。
虽然这些解决方案可能仅暂时有效,但请记住,防抓取是一种猫捉老鼠般的游戏。由于Cloudflare不断更新其保护机制,今天有效的方法明天可能就行不通。
这些项目中的大多数已经多年没有更新,这一点都不奇怪。原因是,开发人员因难以跟上Cloudflare的更新而放弃。
高级Cloudflare解算器
在大多数情况下,抓取受Cloudflare保护的网站的最佳解决方案,是使用高级产品。因其有收费,确保了抓取领域专家会提供定期更新,所以针对Cloudflare防御的应对方法能保持高度可靠。
除此之外,还有像Bright Data这样的顶级供应商提供全天候技术支持,帮助您解决任何问题。如果您正在寻找专业的Cloudflare抓取解决方案,请试试我们的Scraping Browser。
它是建基于云的可扩展GUI浏览器,可与Playwright、Puppeteer、Selenium和任何其他无头浏览器库集成。为了保证应对Cloudflare的高效率,它还具有IP轮换、CAPTCHA验证码破解能力、User-Agent轮换等功能。
抓取受Cloudflare保护的网站:绕过反机器人程序的DIY方法
破解Cloudflare很困难,尤其是当您不想使用高级一体化解决方案时。如果您想选择此途径,您必须考虑到Cloudflare所有防御机器人的措施,并找到应对方法。
在本节中,您将看到一些最有用的高级技巧,可以用来避开Cloudflare并抓取受其WAF保护的网站。请查看我们有关如何避开Cloudflare的指南,以获取详细说明。
让我们开始吧!
JavaScript渲染
Cloudflare用来检测机器人的最常用技术之一是JavaScript挑战。这些是嵌入在网页中的JavaScript脚本,由浏览器在渲染期间执行。它们执行特定的检查,以确定访客是机器人的可能性:
如果Cloudflare根据这些挑战的结果怀疑您是机器人,它会向您显示一个CAPTCHA验证码。否则,您将被允许访问网页内容。
因此,要针对受Cloudflare保护的网页进行抓取,您需要使用浏览器自动化工具,如Playwright、Selenium或Puppeteer等。这些工具使您能够指示浏览器像普通用户一样与网页进行交互。请参阅我们的使用Playwright进行网页抓取指南,了解更多信息。
问题是,无头浏览器的默认配置可能导致其被反机器人检测系统识别出来。为了避免这种情况,您应该使用Playwright Stealth或Puppeteer Stealth(通过Puppeteer Extra)之类的库来帮助掩盖无头浏览器活动。
CAPTCHA验证码破解
如果Cloudflare认为您可能是机器人,会尝试使用Turnstile CAPTCHA验证码来阻止您:
根据配置,CAPTCHA验证码可能是像上述那样的简单点击测试,也可能是更复杂的拼图,如下所示:
CAPTCHA验证码的自动破解是很复杂的,因为CAPTCHA验证码是专门为区分机器人和人类而设计的测试。如果您的无头浏览器遇到这样的难题,您可以尝试我们在使用Python绕过CAPTCHA指南中概述的技术。
要获得更可靠的解决方案,可以考虑Bright Data的Cloudflare Turnstile Solver,无论您在抓取脚本中使用哪种技术,此解算器都能运行,快速地自动为您解析Cloudflare Turnstile CAPTCHA验证码。
绕过速率限制
如果您在短时间内从同一IP发出的请求过多,Cloudflare很可能会暂时甚至永久封禁您的IP。这会造成问题,因为您的抓取操作会因而中断,IP的声誉会受损。
上述的技术称为速率限制,用于阻止DDoS攻击和不想要的自动请求。由于您的IP与所连接的网络绑定,因此无法轻易更改。实施IP轮换以避免封禁的唯一有效方法,是使用代理服务。
您可以使用住宅代理等解决方案,让脚本的请求看起来好像是来自特定位置的真实设备。我们提供住宅代理服务,欢迎查阅更多信息。
浏览器伪装
即使在无头模式下,浏览器也会消耗大量资源。因此,如果围绕受Cloudflare保护的网站使用浏览器自动化工具构建抓取操作,流程可能需要极多资源。这可能需要多台服务器和复杂的架构。
为了避免这种麻烦,并且在Cloudflare的WAF被配置为不过于激进的情况下,您可以尝试另一种方法。有一个构思是从模仿真实浏览器的HTTP客户端发出自动请求,这被称为浏览器伪装。
其目标是使您的HTTP请求看起来尽可能和来自普通浏览器的请求相似。您可以设置特定的HTTP标头(例如User-Agent),以实现此效果。要了解更多信息,请参阅我们的网页抓取最佳User-Agent指南。
在更复杂的情况中,仅靠这个技巧可能还不够。Cloudflare仍然可以用TLS指纹识别检测到您的请求是来自HTTP客户端而不是浏览器:
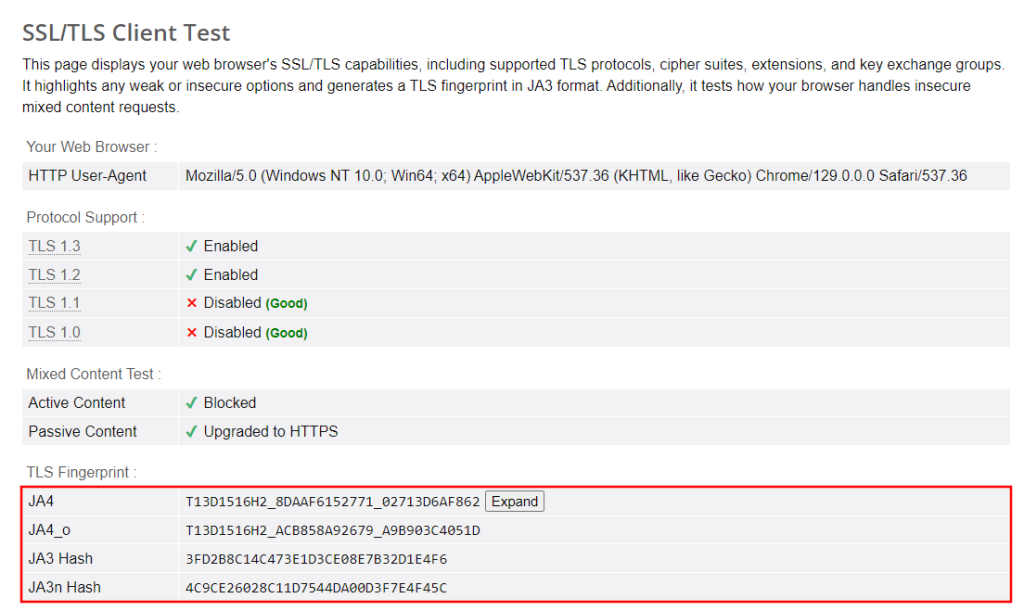
如果您不熟悉这个概念,简单说明一下:TLS指纹识别是根据客户端通过TLS建立安全连接的方式来识别客户端。要复制浏览器的TLS指纹,您可以使用像curl-impersonate这样的HTTP客户端(详见我们的专门教程)。
结论
在本文中,您看到了一些针对受Cloudflare保护的网站进行抓取的技巧和窍门。Cloudflare是市场上最受欢迎的CDN服务,它还提供先进的反机器人解决方案。如本文所述,要绕过Cloudflare的反抓取措施并不容易,但也非不可能。
无论您选择哪种方法,请记住,使用专业、快速和可靠的抓取解决方案,一切都会变得更容易,这些解决方案包括:
- Web Unlocker:自动绕过速率限制、指纹识别和其他反机器人限制,实现无缝的公共网络数据收集。
- Scraping Browser:完全托管的浏览器,可自动解锁网站,让您轻松抓取动态网页数据。
有了Bright Data丰富全面的抓取工具套件,从受Cloudflare保护的网站提取数据变得前所未有的简单!
请即注册,了解Bright Data哪种解决方案最适合您的需求。立即开始免费试用!


