

在本教程中,你将学习:
- 为什么从网站抓取图像是有用的
- 如何使用 Selenium 在 Python 中从网站抓取图像
让我们开始吧!
为什么要从网站抓取图像?
网络抓取不仅仅是提取文本数据。它可以目标任何类型的数据,包括多媒体文件如图像。特别是,从网站抓取图像在以下几种情况下非常有用:
- 为训练机器学习和人工智能模型获取图像:使用在线下载的图像训练模型,以提高其准确性和有效性。
- 研究竞争对手如何进行视觉传播:通过让你的营销团队访问竞争对手使用的图像,了解趋势和策略。
- 自动从在线提供商获取视觉上吸引人的图像:使用高质量的图像在你的网站和社交媒体平台上实现高参与度,吸引并保持受众的注意力。
Python 抓取图像:逐步指南
要从网页抓取图像,你需要执行以下操作:
- 连接到目标网站
- 选择页面上所有感兴趣的图像 HTML 节点
- 从每个节点中提取图像 URL
- 下载与这些 URL 关联的图像文件
Unsplash 是一个适合这个任务的目标网站,它是互联网上最受欢迎的图像提供商之一。这是搜索关键词“wallpaper”时免费图像的仪表板:
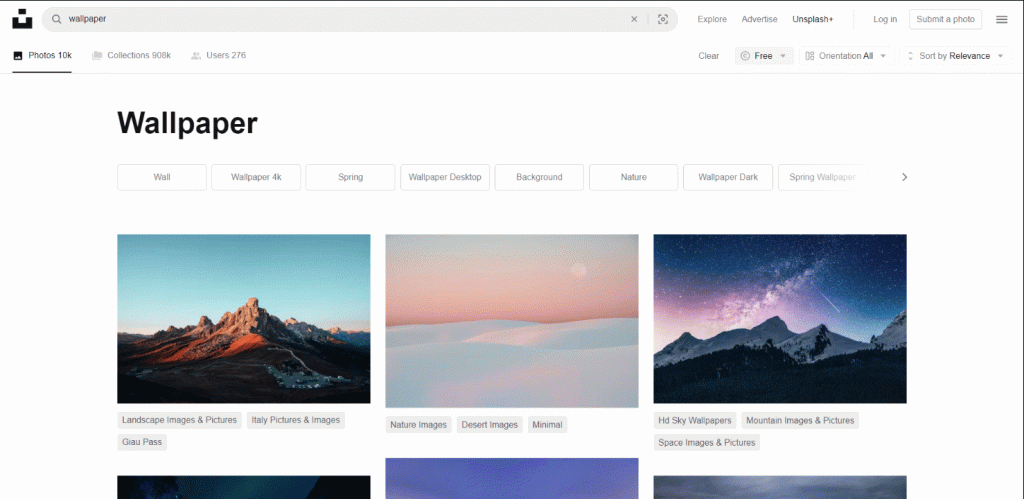
如你所见,页面在用户向下滚动时加载新图像。换句话说,这是一个需要浏览器自动化工具进行抓取的交互式网站。
该页面的 URL 是:
https://unsplash.com/s/photos/wallpaper?license=free现在是时候看看如何在 Python 中从该网站抓取图像了!
步骤#1:入门
要跟随本教程,请确保你在机器上安装了 Python 3。否则,下载安装程序,双击它,然后按照说明进行操作。
使用以下命令初始化你的 Python 图像抓取项目:
mkdir image-scraper
cd image-scraper
python -m venv env这将在image-scraper文件夹中创建一个 Python 虚拟环境。
在你选择的 Python IDE 中打开项目文件夹。PyCharm Community Edition或Visual Studio Code with the Python扩展都可以。
在项目文件夹中创建一个scraper.py文件,并初始化如下:
print('Hello, World!')现在,此文件是一个简单的脚本,它打印“Hello, World!”但它很快就会包含图像抓取逻辑。
通过按 IDE 的运行按钮或运行以下命令来验证脚本是否有效:
python scraper.py你的终端中应出现以下消息:
Hello, World!太棒了!你现在有了一个 Python 项目。接下来的步骤中实现抓取图像的逻辑。
步骤#2:安装 Selenium
Selenium是一个很好的图像抓取库,因为它可以处理具有静态和动态内容的网站。作为一个浏览器自动化工具,它可以渲染需要 JavaScript 执行的页面。了解更多内容请参考我们的Selenium 网络抓取指南。
与 HTML 解析器如BeautifulSoup相比,Selenium 可以定位更多网站并涵盖更多用例。例如,它也适用于依赖用户交互加载新图像的图像提供商。这正是本指南的目标网站 Unsplash 的情况。
在安装 Selenium 之前,你需要激活 Python 虚拟环境。在 Windows 上,使用此命令实现:
envScriptsactivate在 macOS 和 Linux 上,运行以下命令:
source env/bin/activate在环境终端中,使用以下pip命令安装Selenium WebDriver 包:
pip install selenium安装过程需要一段时间,请耐心等待。
太棒了!你已经具备了在 Python 中抓取图像所需的一切。
步骤#3:连接到目标网站
通过添加以下行导入 Selenium 和控制 Chrome 实例所需的类到scraper.py
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from selenium.webdriver.chrome.options import Options你现在可以使用以下代码初始化无头模式的 Chrome WebDriver 实例:
# to run Chrome in headless mode
options = Options()
options.add_argument("--headless") # comment while developing
# initialize a Chrome WerbDriver instance
# with the specified options
driver = webdriver.Chrome(
service=ChromeService(),
options=options
)如果你希望 Selenium 启动一个带有 GUI 的 Chrome 窗口,请注释掉--headless选项。这将允许你实时跟踪脚本在页面上执行的操作,这对于调试非常有用。在生产环境中,保持--headless选项激活以节省资源。
不要忘记在脚本结束时关闭浏览器窗口:
# 关闭浏览器并释放其资源
driver.quit()某些页面根据用户设备的屏幕大小以不同方式显示图像。为了避免响应式内容的问题,请最大化 Chrome 窗口:
driver.maximize_window()现在,你可以使用get()方法指示 Chrome 通过 Selenium 连接到目标页面:
url = "https://unsplash.com/s/photos/wallpaper?license=free"
driver.get(url)将所有代码整合在一起,你会得到:
from selenium import webdriver
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from selenium.webdriver.chrome.options import Options
# to run Chrome in headless mode
options = Options()
options.add_argument("--headless")
# initialize a Chrome WerbDriver instance
# with the specified options
driver = webdriver.Chrome(
service=ChromeService(),
options=options
)
# to avoid issues with responsive content
driver.maximize_window()
# the URL of the target page
url = "https://unsplash.com/s/photos/wallpaper?license=free"
# visit the target page in the controlled browser
driver.get(url)
# close the browser and free up its resources
driver.quit()在有头模式下启动图像抓取脚本。它将在关闭 Chrome 之前显示以下页面的一部分:
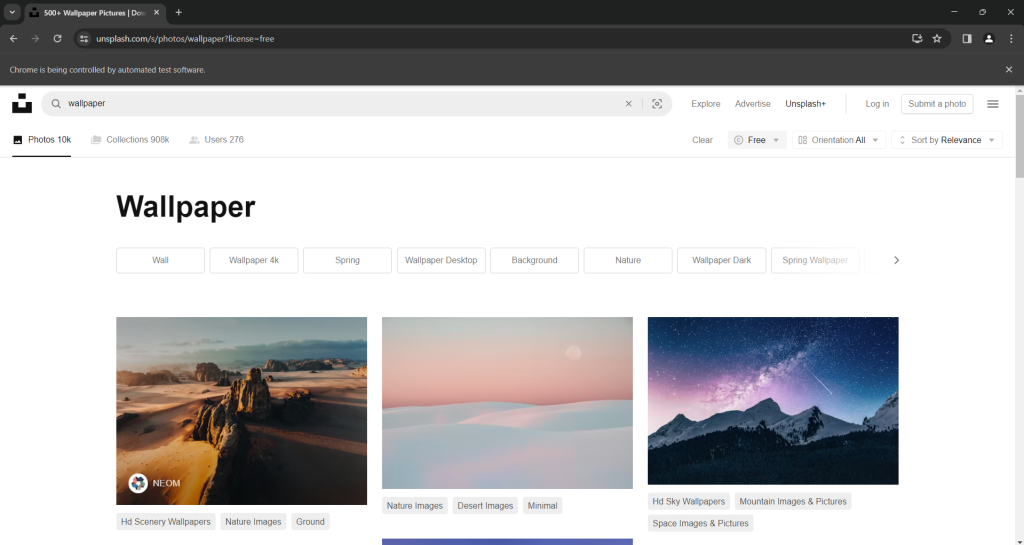
消息“Chrome is being controlled by automated test software”表示 Selenium 正在按预期操作 Chrome 窗口。
非常棒!现在查看页面的 HTML 代码,了解如何从中提取图像。
步骤#4:检查目标网站
在深入研究 Python 抓取图像逻辑之前,你必须检查目标页面的 HTML 源代码。只有这样,你才能理解如何定义有效的节点选择逻辑,并找到提取所需数据的方法。
因此,在浏览器中访问目标网站,右键点击一个图像,并选择“检查”选项以打开开发者工具:
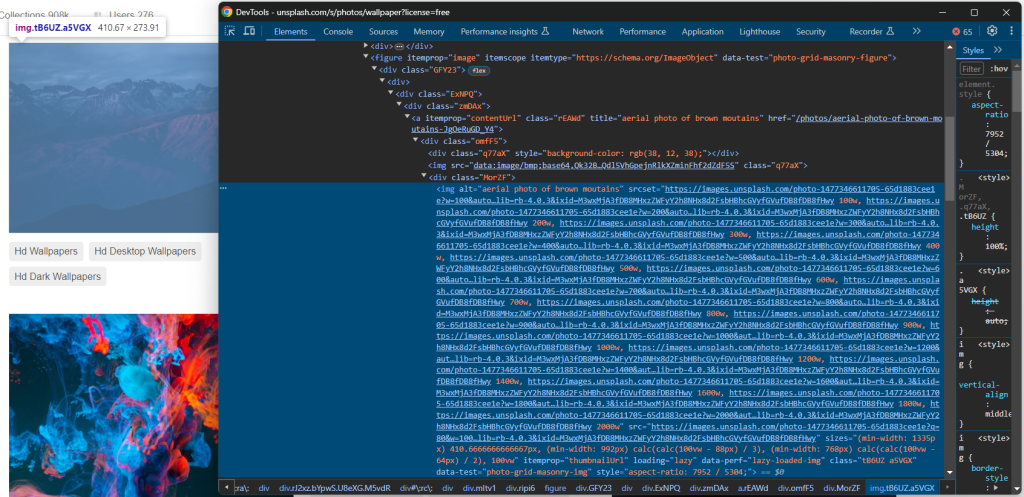
这里,你可以注意到几个有趣的事实。
首先,图像包含在<img> HTML 元素中。这意味着选择感兴趣的图像节点的 CSS 选择器是:
[data-test="photo-grid-masonry-img"]其次,图像元素同时具有传统的src属性和srcset属性。如果你不熟悉后者,srcset指定了多个源图像以及一些提示,以帮助浏览器根据响应断点选择合适的图像。
具体来说,srcset属性的值具有以下格式:
<image_source_1_url> <image_source_1_size>, <image_source_1_url> <image_source_2_size>, ...其中:
<image_source_1_url>,<image_source_2_url>等是不同尺寸图像的 URL。<image_source_1_size>,<image_source_2_size>等是每个图像源的尺寸。允许的值是像素宽度(例如200w)或像素比例(例如1.5x)。
在现代响应式网站上,图像同时具有这两个属性的情况相当普遍。直接定位src中的图像 URL 不是最佳方法,因为srcset可能包含更高质量的图像 URL。
从上述 HTML 中,你还可以看到所有图像 URL 都是绝对的。因此,你不需要将网站的基本 URL 连接到它们。
下一步,你将学习如何使用 Selenium 在 Python 中提取正确的图像。
步骤#5:检索所有图像 URL
使用findElements()方法选择页面上所有所需的 HTML 图像节点:
image_html_nodes = driver.find_elements(By.CSS_SELECTOR, "[data-test="photo-grid-masonry-img"]")要使该指令有效,需要导入以下内容:
from selenium.webdriver.common.by import By接下来,初始化一个包含从图像元素中提取的 URL 的列表:
image_urls = []遍历image_html_nodes中的节点,收集src中的 URL 或srcset中的最大图像 URL(如果存在),并将其添加到image_urls:
for image_html_node in image_html_nodes:
try:
# use the URL in the "src" as the default behavior
image_url = image_html_node.get_attribute("src")
# extract the URL of the largest image from "srcset",
# if this attribute exists
srcset = image_html_node.get_attribute("srcset")
if srcset is not None:
# get the last element from the "srcset" value
srcset_last_element = srcset.split(", ")[-1]
# get the first element of the value,
# which is the image URL
image_url = srcset_last_element.split(" ")[0]
# add the image URL to the list
image_urls.append(image_url)
except StaleElementReferenceException as e:
continue请注意,Unsplash 是一个相当动态的网站,当你执行此循环时,一些图像可能不再在页面上。为防止该错误,请捕获StaleElementReferenceException。
再次,不要忘记添加以下导入:
from selenium.common.exceptions import StaleElementReferenceException你现在可以使用以下命令打印抓取的图像 URL:
print(image_urls)当前的scraper.py文件应包含:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
from selenium.common.exceptions import StaleElementReferenceException
# to run Chrome in headless mode
options = Options()
options.add_argument("--headless")
# initialize a Chrome WerbDriver instance
# with the specified options
driver = webdriver.Chrome(
service=ChromeService(),
options=options
)
# to avoid issues with responsive content
driver.maximize_window()
# the URL of the target page
url = "https://unsplash.com/s/photos/wallpaper?license=free"
# visit the target page in the controlled browser
driver.get(url)
# select the node images on the page
image_html_nodes = driver.find_elements(By.CSS_SELECTOR, "[data-test="photo-grid-masonry-img"]")
# where to store the scraped image url
image_urls = []
# extract the URLs from each image
for image_html_node in image_html_nodes:
try:
# use the URL in the "src" as the default behavior
image_url = image_html_node.get_attribute("src")
# extract the URL of the largest image from "srcset",
# if this attribute exists
srcset = image_html_node.get_attribute("srcset")
if srcset is not None:
# get the last element from the "srcset" value
srcset_last_element = srcset.split(", ")[-1]
# get the first element of the value,
# which is the image URL
image_url = srcset_last_element.split(" ")[0]
# add the image URL to the list
image_urls.append(image_url)
except StaleElementReferenceException as e:
continue
# log in the terminal the scraped data
print(image_urls)
# close the browser and free up its resources
driver.quit()运行脚本以抓取图像,你将得到类似以下的输出:
[
'https://images.unsplash.com/photo-1707343843598-39755549ac9a?w=2000&auto=format&fit=crop&q=60&ixlib=rb-4.0.3&ixid=M3wxMjA3fDF8MHxzZWFyY2h8MXx8d2FsbHBhcGVyfGVufDB8fDB8fHwy',
# omitted for brevity...
'https://images.unsplash.com/photo-1507090960745-b32f65d3113a?w=2000&auto=format&fit=crop&q=60&ixlib=rb-4.0.3&ixid=M3wxMjA3fDB8MHxzZWFyY2h8MjB8fHdhbGxwYXBlcnxlbnwwfHwwfHx8Mg%3D%3D'
]搞定了!上述数组包含要检索的图像的 URL。现在只剩下了解如何在 Python 中下载图像。
步骤#6:下载图像
在 Python 中下载图像的最简单方法是使用标准库中的url.request包的urlretrieve()方法。该方法将由 URL 指定的网络对象复制到本地文件。
通过在scraper.py文件顶部添加以下行导入url.request:
import urllib.request在项目文件夹中创建一个images目录:
mkdir images这是脚本将写入图像文件的地方。
现在,遍历抓取图像 URL 的列表。对于每个图像,生成递增的文件名,并使用urlretrieve()下载图像:
image_name_counter = 1
# download each image and add it
# to the "/images" local folder
for image_url in image_urls:
print(f"downloading image no. {image_name_counter} ...")
file_name = f"./images/{image_name_counter}.jpg"
# download the image
urllib.request.urlretrieve(image_url, file_name)
print(f"images downloaded successfully to "{file_name}"n")
# increment the image counter
image_name_counter += 1这是在 Python 中下载图像所需的一切。print()指令不是必需的,但对于了解脚本的操作非常有用。
哇!你刚刚学习了如何从网站抓取图像到 Python 中。是时候看看抓取图像 Python 脚本的完整代码了。
步骤#7:整合所有内容
这是最终scraper.py的代码:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
from selenium.common.exceptions import StaleElementReferenceException
import urllib.request
# to run Chrome in headless mode
options = Options()
options.add_argument("--headless")
# initialize a Chrome WerbDriver instance
# with the specified options
driver = webdriver.Chrome(
service=ChromeService(),
options=options
)
# to avoid issues with responsive content
driver.maximize_window()
# the URL of the target page
url = "https://unsplash.com/s/photos/wallpaper?license=free"
# visit the target page in the controlled browser
driver.get(url)
# select the node images on the page
image_html_nodes = driver.find_elements(By.CSS_SELECTOR, "[data-test="photo-grid-masonry-img"]")
# where to store the scraped image url
image_urls = []
# extract the URLs from each image
for image_html_node in image_html_nodes:
try:
# use the URL in the "src" as the default behavior
image_url = image_html_node.get_attribute("src")
# extract the URL of the largest image from "srcset",
# if this attribute exists
srcset = image_html_node.get_attribute("srcset")
if srcset is not None:
# get the last element from the "srcset" value
srcset_last_element = srcset.split(", ")[-1]
# get the first element of the value,
# which is the image URL
image_url = srcset_last_element.split(" ")[0]
# add the image URL to the list
image_urls.append(image_url)
except StaleElementReferenceException as e:
continue
# to keep track of the images saved to disk
image_name_counter = 1
# download each image and add it
# to the "/images" local folder
for image_url in image_urls:
print(f"downloading image no. {image_name_counter} ...")
file_name = f"./images/{image_name_counter}.jpg"
# download the image
urllib.request.urlretrieve(image_url, file_name)
print(f"images downloaded successfully to "{file_name}"n")
# increment the image counter
image_name_counter += 1
# close the browser and free up its resources
driver.quit()太棒了!你可以用不到 100 行代码构建一个自动化脚本,从网站下载图像。
使用以下命令执行它:
python scraper.pyPython 图像抓取脚本将在终端中记录以下字符串:
downloading image no. 1 ...
images downloaded successfully to "./images/1.jpg"
# omitted for brevity...
downloading image no. 20 ...
images downloaded successfully to "./images/20.jpg"浏览/images文件夹,你将看到脚本自动下载的图像:
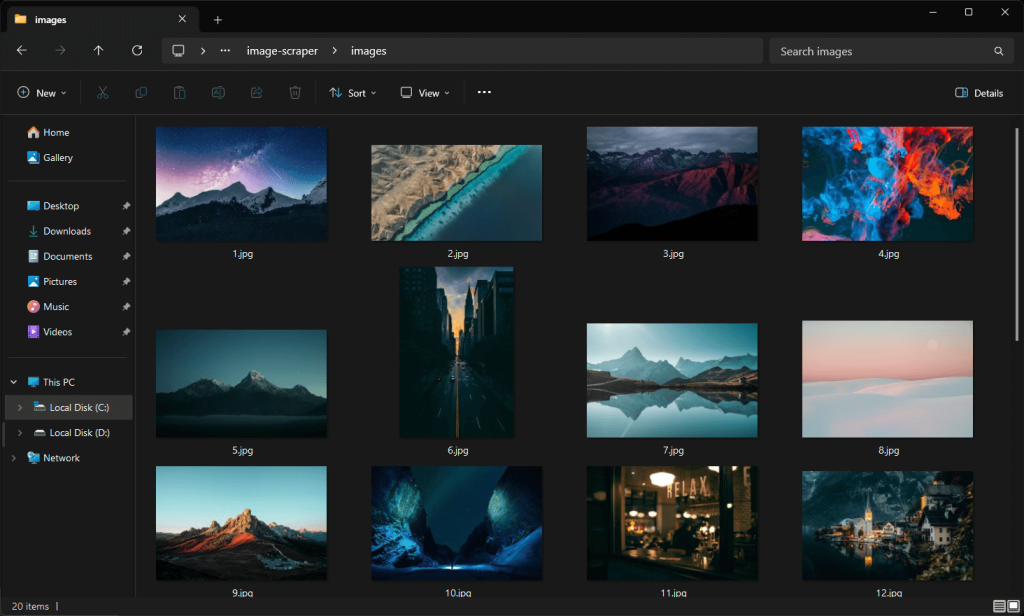
注意,这些图像与之前 Unsplash 页面截图中的图像不同,因为该网站不断接收更新内容。
大功告成!任务完成。
步骤#8:后续步骤
尽管我们已经达到了目标,但仍有一些可能的改进可以提升你的 Python 脚本。最重要的是:
- 将图像 URL 导出到 CSV 或存储在数据库中:这样,你将能够在将来下载或使用它们。
- 避免下载已经在
/images文件夹中的图像:这种改进通过跳过已下载的图像来节省网络资源。 - 抓取元数据信息:检索标签和作者信息对于获取下载图像的完整信息非常有用。了解更多内容请参考我们的Python 网络抓取指南。
- 抓取更多图像:模拟无限滚动交互,加载更多图像并全部下载。
结论
在本指南中,你了解了为什么从网站抓取图像是有用的以及如何在 Python 中实现它。特别是,你看到了一个逐步教程,介绍了如何构建一个 Python 抓取图像脚本 ,该脚本可以自动从网站下载图像。如本指南所示,这并不复杂,只需要几行代码。
同时,你不应忽视反机器人系统。Selenium 是一个很好的工具,但它无法对抗如此先进的技术。这些技术可以检测到你的脚本是机器人,并阻止其访问网站的图像。
为了避免这种情况,你需要一个能够渲染 JavaScript 并且能够处理指纹识别、CAPTCHA 和反抓取的工具。这正是Bright Data 的抓取浏览器所做的!
与我们的数据专家讨论我们的抓取解决方案。
常见问题
从网站抓取图像合法吗?
从网站抓取图像本身并不是非法活动。与此同时,重要的是只下载公共图像,遵守抓取的robots.txt文件,并遵守网站的条款和条件。许多人认为网络抓取是不合法的,但这是一个误区。了解更多内容请参阅我们的文章关于网络抓取的八大误区。
下载图像的最佳 Python 库是什么?
在静态内容网站上,一个 HTTP 客户端如requests和一个 HTML 解析器如beautifulsoup4就足够了。在动态内容网站或高度交互页面上,你需要一个浏览器自动化工具如 Selenium 或 Playwright。查看最佳无头浏览器工具的列表。
如何解决urllib.request中的“HTTP Error 403: Forbidden”错误?
HTTP 403 错误的发生是因为目标网站识别出urllib.request发出的请求是来自自动脚本。解决这个问题的有效方法是将User-Agent头设置为真实世界的值。使用urlretrieve()方法时,可以这样做:
opener = urllib.request.build_opener()
user_agent_string = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36"
opener.addheaders = [("User-Agent", user_agent_header)]
urllib.request.install_opener(opener)
# urllib.request.urlretrieve(...)


技术写作
 5.5 years experience
5.5 years experience
Antonello是一名软件工程师,但他更喜欢称自己为技术传教士。通过写作传播知识是他的使命。




