

AI 并不是有意识的。AI 使用的是一组算法的简单组合,这些算法并不会“思考”或“感知”。这种简化的过程被称为“模型”。得益于新的训练方法,模型变得更聪明、更高效,并在我们的日常生活中越来越普及。
如果你对如何训练自己的 AI感到好奇,继续阅读,了解此过程的宏观概念。
什么是 AI 训练(以及为什么你应该关心)?
我们通过训练过程来“教”AI 模型。人类首先学会吃东西、走路和说话;LLM(大型语言模型)则先学会基础的数学、阅读和语句结构。就像人类在上学时先学习日常技能(如算术和阅读),然后可能还会学习自己一辈子都用不到的知识,AI 也会经历类似的过程。一旦模型能够处理输入并生成输出,接下来它就会通过比我们人类所能想象的规模更庞大的数据集进行训练。
得益于新的训练方法,这些数据集正变得更小。更小的数据集意味着更小的模型。更优质的数据可以孕育更精简、更强大的 AI。谷歌和微软已经开始推出带有内置 AI 的笔记本电脑。随着计算能力的提升,模型也在变得更高效。不久之后,AI 可能会在智能手机硬件上本地运行。到 2050 年,你或许能跟你的烤面包机进行深层次的哲学对话。
现实世界中的 AI 训练
AI 模型已经在很多你意想不到的地方使用。如今我们都对聊天机器人和图像生成器耳熟能详,但 AI 和机器学习在真实世界中的应用范围远远不止这些。
- 医疗保健:模型被越来越多地用于医疗数据的训练。它们可加快诊断速度,并检测医生很少遇到的罕见病。
- 制药:模型可创建假想化合物并分析其有效性。与传统方法相比,这种“虚拟试验”可以节省数年甚至数十年的反复试验时间。
- 金融:在 2010 年代后期,人们意识到 AI 模型在分析交易模式方面非常高效。如今,无论是加密货币还是股票,AI 驱动的交易都已成为行业标准。
- 娱乐:Netflix、Spotify 甚至 YouTube 都使用训练好的模型来为你推荐新内容。这些模型会分析你的媒体消费行为,从而准确预测你下一步会喜欢什么。还记得以前的 Netflix 推荐多么糟糕吗?它们的改进和 AI 的崛起几乎是同步的。
- 航空航天:NASA 使用 AI 模型来分析行星数据,用于更好地研究地球和遥远的行星。
上面列举的只是冰山一角。零样本学习(zero-shot learning)如今能让 AI 在从未见过的数据上做出决策。随着新的训练方法不断涌现,高质量模型也在不断融入你的日常生活。想象一下一个能够完美烹饪食物的烤箱——这一天已经不远了!
AI 模型训练过程
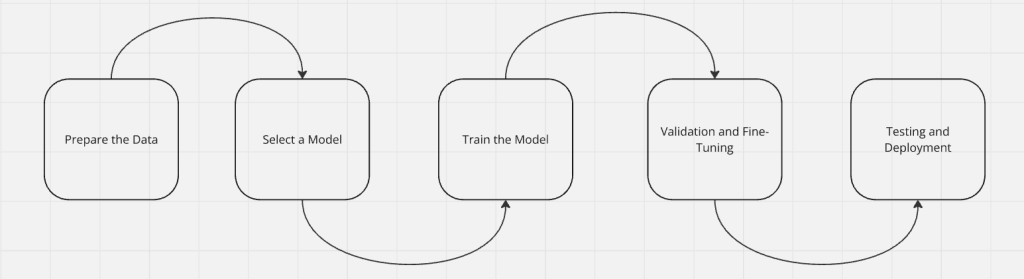
当我们教一个孩子阅读时,我们不会直接给她一本百科全书然后就不管了。我们会先教她字母,然后是单词,接着是完整的句子;从句子到段落,再到整本书。AI 模型的训练也是这样的循序渐进过程。首先,模型学会处理输入(读取数据),然后再学会生成输出。经过足够的训练后,模型能开始自主学习。一旦我们对它进行了微调,就会对模型进行测试并将其部署到真实环境中。
步骤 1:准备数据
模型需要数据。在选择模型之前,首先要确定用于训练的数据。数据应当干净、格式良好,并能反映真实世界的模式。
原始数据通常是杂乱、存在不一致并且可能不完整的。在将其输入到模型之前,需要对数据进行清洗和格式化。无论你的模型是基于表格等结构化数据,还是基于文本、视频等完全非结构化数据,数据的质量和相关性都至关重要。你不会用打高尔夫的数据来训练一个能自己做饭的烤箱吧!
高质量数据能缩短训练时间,并带来体积较小但足够智能的模型。我们提供的数据集市场能提供开箱即用的干净数据。
步骤 2:选择训练模型
你需要根据想要构建的 AI 类型来选择合适的训练模型。可能会使用以下某种模型——或者它们的组合。
- 大型语言模型(LLM):通常用于聊天机器人。它们在海量数据集上进行训练,旨在自然地处理人类语言。LLM 通过在训练数据的基础上进行预测来阅读和生成文本。ChatGPT、Claude 和 DeepSeek 都是这类模型的示例。
- 卷积神经网络(CNN):这些模型用于分析图像和视频。实际案例包括 ResNet、EfficientNet 和 YOLO(You Only Look Once)。
- 循环神经网络(RNN)和 Transformer:这些模型在预测、语音识别和序列化数据方面表现出色。GPT 和 BERT 都是常见的例子,而 LLM 实际上是由 Transformer 演变而来。
- 决策树和随机森林:非常适合数据分类和预测建模,多用于金融模型和风险评估。示例包括 XGBoost、CatBoost 和 Scikit-learn 的 DecisionTreeClassifier。
- 强化学习模型:Deep Q-Network(DQN)、AlphaGo,以及 PPO(Proximal Policy Optimization)都使用强化学习。当你的 AI 模型需要随着时间推移不断学习策略时,强化学习是理想的选择。Roomba(扫地机器人)就是通过强化学习来在客厅里导航并避开家具的。
步骤 3:训练模型
训练是一个缓慢的过程,类似于学习一项新技能。它需要在练习、反馈和调整的不断循环中进行。模型会不断改进,直到能够完成它所设定的目标。
- 输入与处理:模型接收数据(标注或未标注)进行处理。
- 学习与调整:模型在处理数据的过程中发现关联并进行归纳。我们对模型作出反馈,以提升其准确性和决策能力。
- 调参:在初步调整开始见效后,我们就可以进行更精细的调整,也就是微调。在这一阶段,模型已经能够高效执行许多任务,但尚未达到可投入生产的水准。
步骤 4:验证与微调
想象一下,你从未开过车就去考驾照。你也许只在驾驶课上通过了笔试,知道油门可以让车加速、刹车可以让车减速、方向盘可以控制方向。然而,真正上车后,你很可能会发现自己并没有准备好:踩油门和刹车的时机不对,转弯幅度太大——砰!你的第一场车祸就这样发生了。开车不仅需要理论,还需要实践经验。
在验证和微调阶段,模型会在真实世界的场景中接受测试。这可能包括深层对话、金融建模、图像生成等。模型需要练习并提升实际应用能力。此时,开发者会做出更精确的调整,保证模型能够正常运行。正如开车时不会猛踩刹车,而是平缓地踩下并平稳停车;同样,AI 模型也需要在输出结果时与目标需求高度匹配。
步骤 5:测试与部署
你会使用从未测试过的药物吗?虽然理论数据看起来可行,但副作用未知,有效性也未经证实。这样做听起来相当危险,对吗?
你也不想使用一个从未经过测试的模型。在 2010 年代后期,一些在社交媒体上训练得不完善的 AI 被投入生产,随后带来了企业尴尬和社交舆论的负面影响。如果能进行充分的测试,这些问题本可以避免。
“给人一个火堆,他能取暖一天;把人点着,他能取暖一辈子——或者直到未测试的原型在他面前爆炸为止。” ——特里·普拉切特(Terry Pratchett)
一旦模型经过严格的测试,就可以投入部署。如果测试失败,我们就会做进一步的修正,直到测试通过。
模型训练面临的挑战
AI 训练并不总是一帆风顺,其中有许多陷阱需要避免。AI 训练中最大的几个问题,实际上和一般软件开发中的常见问题类似:
- 低质量或被污染的数据:如果用垃圾数据来训练模型,就会得到“垃圾”模型。
- 弱或缺失的测试:你需要尽可能对各种情况进行测试,否则,就会落得像上面普拉切特引用中的那个人。
- “黑箱”问题:神经网络常被称为“黑箱”。我们并不完全了解它是如何工作的,只知道一个神经元会被激活并与其他神经元通信。要调试神经网络,几乎就像让尼安德特人用木棒来做脑外科手术一样困难。
模型训练的未来
AI 训练的方式正在以我们意想不到的方式发展。现在,你甚至可以问一个大型语言模型如何构建另一个大型语言模型,它也会告诉你。很快,AI 模型就能直接训练其他 AI 模型。好在它们并没有情感,否则“人类员工帮助训练替代者”可就惨了。
受益于少样本学习(few-shot learning),训练数据与 AI 模型都在不断缩小。每天都会出现更高效的全新方法,更加智能的模型正在更弱的硬件上运行。随着每一次训练上的突破,我们离那个具备哲学思考能力的烤面包机——以及其他更有用的东西——又近了一步。
结论
如果缺乏正确的训练,AI 模型只会以失败告终。我们已经取得巨大进步,但这仅仅是开始。随着 AI 不断融入我们的日常生活,未来十年里出现的创新将超过我们的想象。几年前,ChatGPT 3.5 就已震撼世界,但那还只是序曲。如果你正在考虑训练自己的 AI 模型,可以看看我们的AI 工具。
如果你想获取自己的数据,不妨试试我们的网络爬虫,为你的模型实时获取真实世界的数据。立即开始免费试用吧!




