

在本指南中,我们将逐步带你在 Python 中搭建一个本地 MCP 服务器,用于按需抓取亚马逊的商品数据。你将了解到 MCP 的基本原理,如何编写并运行自己的服务器,以及如何与 Claude Desktop 和 Cursor IDE 这类开发者工具连接。最后,我们还会演示如何在真实环境中利用 Bright Data 与 MCP 集成,实现实时、面向 AI 的网络数据。
让我们开始吧。
瓶颈:LLM 为何难以与现实世界交互(以及 MCP 如何解决这一问题)
大型语言模型(LLM)在处理和生成来自庞大训练数据集的文本方面非常强大。然而,它们有一个关键的局限性——无法原生与现实世界交互。这意味着它们无法访问本地文件、无法运行自定义脚本,也无法从网络上获取实时数据。
举个简单例子:让 Claude 从一个实时的亚马逊页面获取商品详情——它无法做到。为什么?因为它没有内置浏览网络或触发外部操作的功能。
如果没有外部工具,LLM 无法执行依赖实时数据或与外部系统集成的实际任务。
这就是 Anthropic 的 Model Context Protocol (MCP) 发挥作用的地方。它能够让 LLM 与外部工具——比如爬虫、API 或脚本——以安全且标准化的方式进行通信。
下面是这个功能的实际表现:在集成了自定义的 MCP 服务器之后,我们可以直接通过 Claude 获取结构化的亚马逊商品数据:
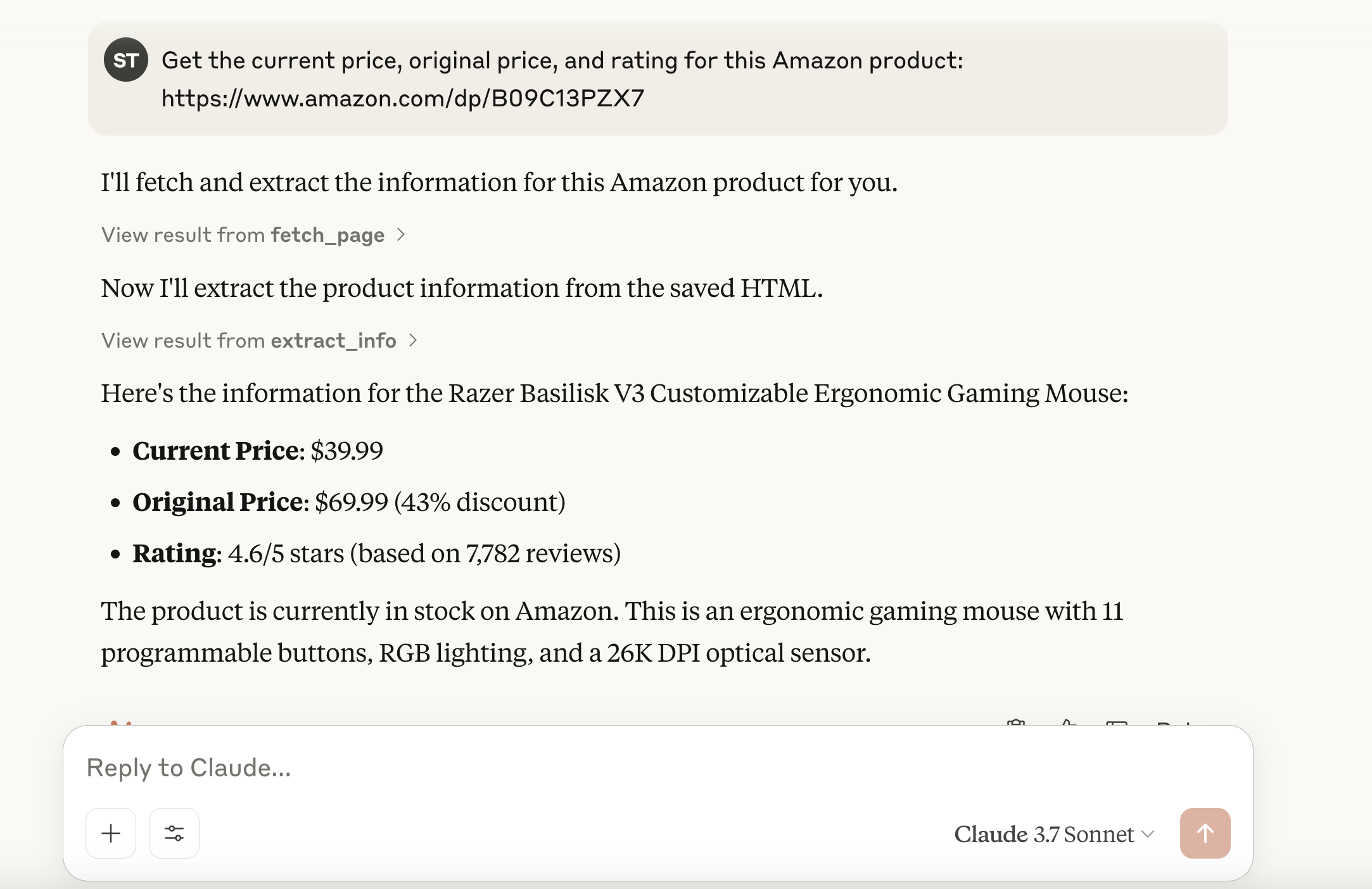
暂时不用担心如何实现——在本指南的后面部分我们会一步步进行讲解。
MCP 有何重要意义?
- 标准化:MCP 为基于 LLM 的系统提供了一个标准化的接口,用于连接外部工具和数据——就像 API 对网络集成所做的一样。这大大减少了自定义集成的需求,加快了开发速度。
- 灵活性和可扩展性:开发者可以替换底层的 LLM 或托管平台,而无需重写工具集成。MCP 支持多种通信方式(如
stdio),能够适配不同的部署场景。 - 增强 LLM 功能:通过将 LLM 与实时数据和外部工具相连接,MCP 使它们的功能超越了静态响应,能够返回当前的相关信息,并根据上下文触发实际操作。
类比:把 MCP 想象成 LLM 的 “USB 接口”。就像 USB 允许各种设备(键盘、打印机、外接硬盘)无需专门的驱动程序就能插到任意兼容机器上那样,MCP 让 LLM 通过统一协议连接到各类工具——每次都无需重新编写专门的集成。
什么是 Model Context Protocol (MCP)?
Model Context Protocol (MCP) 是由 Anthropic 开发的开放标准,帮助大型语言模型(LLM)与外部工具、API 和数据源以一致、安全的方式进行交互。它就像一个通用连接器,使 LLM 能够执行诸如抓取网站、查询数据库或触发脚本等现实任务。
虽然 MCP 是 Anthropic 提出的,但它是开放且可扩展的,意味着任何人都可以实现或为该标准做出贡献。如果你对 检索增强生成(RAG) 有所了解,你会发现它们有异曲同工之处。MCP 将这一理念标准化,通过一个轻量级的 JSON-RPC 交互接口,让模型也能访问实时数据并进行操作。
MCP 的架构:工作原理
MCP 的核心在于,标准化了 AI 模型和外部能力之间的通信。
核心思路:通过一个标准化接口(通常是基于 JSON-RPC 2.0、通过 stdio 等传输方式),让 LLM(经由客户端)能发现并调用由外部服务器提供的工具。
MCP 采用客户端-服务器的架构,包含三个关键组件:
- MCP Host(主机):负责在 LLM 和外部工具之间发起并管理交互的环境或应用。示例包括 Claude Desktop 这类 AI 助手,或 Cursor 这类 IDE。
- MCP Client(客户端):运行在主机内部的组件,用来建立并保持与 MCP 服务器的连接,处理通信协议并管理数据交换。
- MCP Server(服务器):我们(开发者)创建的程序,实现 MCP 协议并向外暴露一组特定的功能。MCP 服务器可能与数据库、网络服务交互,或者在本例中与一个网站(亚马逊)交互。服务器以标准化方式暴露其功能:
- Tools(工具):可调用的函数(例如 scrape_amazon_product、get_weather_data)
- Resources(资源):只读端点,用于读取静态数据(例如获取文件、返回 JSON 记录)
- Prompts(提示):预定义的模板,用于指导 LLM 如何与工具和资源交互
下面是 MCP 的架构图:

在该架构中,host(主机)(如 Claude Desktop 或 Cursor IDE)会生成一个 MCP client(客户端),它随后连接到一个外部 MCP server(服务器)。该服务器暴露了工具、资源和提示,使 AI 可以在需要时与它们进行交互。
简而言之,其工作流程如下:
- 用户发送一条信息,如 “从这个亚马逊链接获取商品信息”。
- MCP 客户端检索注册的工具,找出可处理该任务的工具。
- 客户端向 MCP 服务器发送一个结构化的请求。
- MCP 服务器执行相应的操作(例如启动一个无头浏览器)。
- 服务器将结构化的结果返回给 MCP 客户端。
- 客户端将结果转发给 LLM,LLM 再将结果呈现给用户。
构建一个自定义的 MCP 服务器
现在让我们来使用 Python 搭建一个 MCP 服务器,专门用于抓取亚马逊商品页面。
该服务器将暴露两个工具:一个用于下载 HTML,另一个用于提取结构化信息。你将在 Cursor 或者 Claude Desktop 中通过 LLM 客户端与该服务器进行交互。
步骤 1:搭建环境
首先,确保已安装 Python 3。然后,创建并激活一个虚拟环境:
python -m venv mcp-amazon-scraper
# On macOS/Linux:
source mcp-amazon-scraper/bin/activate
# On Windows:
.mcp-amazon-scraperScriptsactivate安装所需的库:MCP Python SDK、Playwright 和 LXML。
pip install mcp playwright lxml
# Install browser binaries for Playwright
python -m playwright install这样会安装下列内容:
- mcp:MCP 的 Python SDK,用于服务器端和客户端之间的 JSON-RPC 通信
- playwright:浏览器自动化库,支持无头浏览器,以渲染和抓取依赖 JavaScript 的网站
- lxml:快速的 XML/HTML 解析库,让你可以使用 XPath 来轻松解析网页中的特定数据元素
总结而言,mcp(MCP Python SDK)处理所有协议细节,让你能够通过自然语言提示来暴露可以被 Claude 或 Cursor 调用的工具;Playwright 允许我们对网页进行完整渲染(包括 JavaScript);lxml 为我们提供强大的 HTML 解析能力。
步骤 2:初始化 MCP 服务器
创建一个名为 amazon_scraper_mcp.py 的 Python 文件。先导入所需模块,并初始化 FastMCP 服务器:
import os
import asyncio
from lxml import html as lxml_html
from mcp.server.fastmcp import FastMCP
from playwright.async_api import async_playwright
# Define a temporary file path for the HTML content
HTML_FILE = os.path.join(os.getenv("TMPDIR", "/tmp"), "amazon_product_page.html")
# Initialize the MCP server with a descriptive name
mcp = FastMCP("Amazon Product Scraper")
print("MCP Server Initialized: Amazon Product Scraper")这会创建一个 MCP 服务器实例。接下来我们将向其添加工具。
步骤 3:实现 fetch_page 工具
该工具会接收一个 URL 作为输入,利用 Playwright 访问网页,等待内容加载后,下载 HTML 并保存到我们的临时文件中。
@mcp.tool()
async def fetch_page(url: str) -> str:
"""
Fetches the HTML content of the given Amazon product URL using Playwright
and saves it to a temporary file. Returns a status message.
"""
print(f"Executing fetch_page for URL: {url}")
try:
async with async_playwright() as p:
# Launch headless Chromium browser
browser = await p.chromium.launch(headless=True)
page = await browser.new_page()
# Navigate to the URL with a generous timeout
await page.goto(url, timeout=90000, wait_until="domcontentloaded")
# Wait for a key element (e.g., body) to ensure basic loading
await page.wait_for_selector("body", timeout=30000)
# Add a small delay for any dynamic content rendering via JavaScript
await asyncio.sleep(5)
html_content = await page.content()
with open(HTML_FILE, "w", encoding="utf-8") as f:
f.write(html_content)
await browser.close()
print(f"Successfully fetched and saved HTML to {HTML_FILE}")
return f"HTML content for {url} downloaded and saved successfully to {HTML_FILE}."
except Exception as e:
error_message = f"Error fetching page {url}: {str(e)}"
print(error_message)
return error_message这是一个异步函数,使用 Playwright 来处理可能的 JavaScript 渲染场景。@mcp.tool() 装饰器会将此函数注册为 MCP 服务器中的可调用工具。
步骤 4:实现 extract_info 工具
这个工具会读取 fetch_page 保存的 HTML 文件,使用 LXML 和 XPath 选择器解析其中内容,并返回一个包含所提取商品详情的字典。
def _extract_xpath(tree, xpath, default="N/A"):
"""Helper function to extract text using XPath, returning default if not found."""
try:
# Use text_content() to get text from node and children, strip whitespace
result = tree.xpath(xpath)
if result:
return result[0].text_content().strip()
return default
except Exception:
return default
def _extract_price(price_str):
"""Helper function to parse price string into a float."""
if price_str == "N/A":
return None
try:
# Remove currency symbols and commas, handle potential whitespace
cleaned_price = "".join(filter(str.isdigit or str.__eq__("."), price_str))
return float(cleaned_price)
except (ValueError, TypeError):
return None
@mcp.tool()
def extract_info() -> dict:
"""
Parses the saved HTML file (downloaded by fetch_page) to extract
Amazon product details like title, price, rating, features, etc.
Returns a dictionary of the extracted data.
"""
print(f"Executing extract_info from file: {HTML_FILE}")
if not os.path.exists(HTML_FILE):
return {
"error": f"HTML file not found at {HTML_FILE}. Please run fetch_page first."
}
try:
with open(HTML_FILE, "r", encoding="utf-8") as f:
page_html = f.read()
tree = lxml_html.fromstring(page_html)
# --- XPath Selectors for Amazon Product Details ---
title = _extract_xpath(tree, '//span[@id="productTitle"]')
# Handle different price structures (main price, sale price)
price_whole = _extract_xpath(tree, '//span[contains(@class, "a-price-whole")]')
price_fraction = _extract_xpath(
tree, '//span[contains(@class, "a-price-fraction")]'
)
price_str = (
f"{price_whole}.{price_fraction}"
if price_whole != "N/A"
else _extract_xpath(tree, '//span[contains(@class,"a-offscreen")]')
) # Fallback to offscreen if needed
price = _extract_price(price_str)
# Original price (strike-through)
original_price_str = _extract_xpath(
tree, '//span[@class="a-price a-text-price"]//span[@class="a-offscreen"]'
)
original_price = _extract_price(original_price_str)
# Rating
rating_text = _extract_xpath(tree, '//span[@id="acrPopover"]/@title')
rating = None
if rating_text != "N/A":
try:
rating = float(rating_text.split()[0])
except (ValueError, IndexError):
rating = None
# Review Count
reviews_text = _extract_xpath(tree, '//span[@id="acrCustomerReviewText"]')
review_count = None
if reviews_text != "N/A":
try:
review_count = int(reviews_text.split()[0].replace(",", ""))
except (ValueError, IndexError):
review_count = None
# Availability
availability = _extract_xpath(
tree,
'//div[@id="availability"]//span/text()',
)
# Features (bullet points)
feature_elements = tree.xpath(
'//div[@id="feature-bullets"]//li//span[@class="a-list-item"]'
)
features = [
elem.text_content().strip()
for elem in feature_elements
if elem.text_content().strip()
]
# Calculate Discount
discount = None
if price and original_price and original_price > price:
discount = round(((original_price - price) / original_price) * 100)
extracted_data = {
"title": title,
"price": price,
"original_price": original_price,
"discount_percent": discount,
"rating_stars": rating,
"review_count": review_count,
"features": features,
"availability": availability.strip(),
}
print(f"Successfully extracted data: {extracted_data}")
return extracted_data
except Exception as e:
error_message = f"Error parsing HTML: {str(e)}"
print(error_message) # Added for logging
return {"error": error_message}该函数使用 LXML 的 fromstring 来解析 HTML,并通过健壮的 XPath 选择器找到所需元素。
步骤 5:运行服务器
最后,在 amazon_scraper_mcp.py 脚本结尾处添加以下代码,使用 stdio 作为传输方式启动服务器。这是本地 MCP 服务器与 Claude Desktop 或者 Cursor 等客户端通信的标准方式。
if __name__ == "__main__":
print("Starting MCP Server with stdio transport...")
# Run the server, listening via standard input/output
mcp.run(transport="stdio")完整代码(amazon_scraper_mcp.py)
import os
import asyncio
from lxml import html as lxml_html
from mcp.server.fastmcp import FastMCP
from playwright.async_api import async_playwright
# Define a temporary file path for the HTML content
HTML_FILE = os.path.join(os.getenv("TMPDIR", "/tmp"), "amazon_product_page.html")
# Initialize the MCP server with a descriptive name
mcp = FastMCP("Amazon Product Scraper")
print("MCP Server Initialized: Amazon Product Scraper")
@mcp.tool()
async def fetch_page(url: str) -> str:
"""
Fetches the HTML content of the given Amazon product URL using Playwright
and saves it to a temporary file. Returns a status message.
"""
print(f"Executing fetch_page for URL: {url}")
try:
async with async_playwright() as p:
# Launch headless Chromium browser
browser = await p.chromium.launch(headless=True)
page = await browser.new_page()
# Navigate to the URL with a generous timeout
await page.goto(url, timeout=90000, wait_until="domcontentloaded")
# Wait for a key element (e.g., body) to ensure basic loading
await page.wait_for_selector("body", timeout=30000)
# Add a small delay for any dynamic content rendering via JavaScript
await asyncio.sleep(5)
html_content = await page.content()
with open(HTML_FILE, "w", encoding="utf-8") as f:
f.write(html_content)
await browser.close()
print(f"Successfully fetched and saved HTML to {HTML_FILE}")
return f"HTML content for {url} downloaded and saved successfully to {HTML_FILE}."
except Exception as e:
error_message = f"Error fetching page {url}: {str(e)}"
print(error_message)
return error_message
def _extract_xpath(tree, xpath, default="N/A"):
"""Helper function to extract text using XPath, returning default if not found."""
try:
# Use text_content() to get text from node and children, strip whitespace
result = tree.xpath(xpath)
if result:
return result[0].text_content().strip()
return default
except Exception:
return default
def _extract_price(price_str):
"""Helper function to parse price string into a float."""
if price_str == "N/A":
return None
try:
# Remove currency symbols and commas, handle potential whitespace
cleaned_price = "".join(filter(str.isdigit or str.__eq__("."), price_str))
return float(cleaned_price)
except (ValueError, TypeError):
return None
@mcp.tool()
def extract_info() -> dict:
"""
Parses the saved HTML file (downloaded by fetch_page) to extract
Amazon product details like title, price, rating, features, etc.
Returns a dictionary of the extracted data.
"""
print(f"Executing extract_info from file: {HTML_FILE}")
if not os.path.exists(HTML_FILE):
return {
"error": f"HTML file not found at {HTML_FILE}. Please run fetch_page first."
}
try:
with open(HTML_FILE, "r", encoding="utf-8") as f:
page_html = f.read()
tree = lxml_html.fromstring(page_html)
# --- XPath Selectors for Amazon Product Details ---
title = _extract_xpath(tree, '//span[@id="productTitle"]')
# Handle different price structures (main price, sale price)
price_whole = _extract_xpath(tree, '//span[contains(@class, "a-price-whole")]')
price_fraction = _extract_xpath(
tree, '//span[contains(@class, "a-price-fraction")]'
)
price_str = (
f"{price_whole}.{price_fraction}"
if price_whole != "N/A"
else _extract_xpath(tree, '//span[contains(@class,"a-offscreen")]')
) # Fallback to offscreen if needed
price = _extract_price(price_str)
# Original price (strike-through)
original_price_str = _extract_xpath(
tree, '//span[@class="a-price a-text-price"]//span[@class="a-offscreen"]'
)
original_price = _extract_price(original_price_str)
# Rating
rating_text = _extract_xpath(tree, '//span[@id="acrPopover"]/@title')
rating = None
if rating_text != "N/A":
try:
rating = float(rating_text.split()[0])
except (ValueError, IndexError):
rating = None
# Review Count
reviews_text = _extract_xpath(tree, '//span[@id="acrCustomerReviewText"]')
review_count = None
if reviews_text != "N/A":
try:
review_count = int(reviews_text.split()[0].replace(",", ""))
except (ValueError, IndexError):
review_count = None
# Availability
availability = _extract_xpath(
tree,
'//div[@id="availability"]//span/text()',
)
# Features (bullet points)
feature_elements = tree.xpath(
'//div[@id="feature-bullets"]//li//span[@class="a-list-item"]'
)
features = [
elem.text_content().strip()
for elem in feature_elements
if elem.text_content().strip()
]
# Calculate Discount
discount = None
if price and original_price and original_price > price:
discount = round(((original_price - price) / original_price) * 100)
extracted_data = {
"title": title,
"price": price,
"original_price": original_price,
"discount_percent": discount,
"rating_stars": rating,
"review_count": review_count,
"features": features,
"availability": availability.strip(),
}
print(f"Successfully extracted data: {extracted_data}")
return extracted_data
except Exception as e:
error_message = f"Error parsing HTML: {str(e)}"
print(error_message) # Added for logging
return {"error": error_message}
if __name__ == "__main__":
print("Starting MCP Server with stdio transport...")
# Run the server, listening via standard input/output
mcp.run(transport="stdio")集成自定义的 MCP 服务器
现在服务器脚本已经准备好,我们来把它连接到像 Claude Desktop 和 Cursor 这样的 MCP 客户端。
连接到 Claude Desktop
步骤 1: 打开 Claude Desktop。
步骤 2: 进入 Settings → Developer → Edit Config。这会在默认的文本编辑器中打开 claude_desktop_config.json 文件。
步骤 3: 在 mcpServers 这个键下,为你的服务器添加一个配置项。请务必将 args 中的路径替换成你 amazon_scraper_mcp.py 文件的绝对路径。
{
"mcpServers": {
"amazon_product_scraper": {
"command": "python", // Or python3 if needed
"args": ["/full/path/to/your/amazon_scraper_mcp.py"], // <-- IMPORTANT: Use the correct absolute path
}
}
}步骤 4: 保存 claude_desktop_config.json 文件,彻底关闭并重新打开 Claude Desktop 使配置生效。
步骤 5: 现在在 Claude Desktop 里,你应该可以看到聊天输入区有一个小工具图标(类似锤子 🔨)。
步骤 6: 点击它会列出 “Amazon Product Scraper” 及其包含的 fetch_page 和 extract_info 工具。

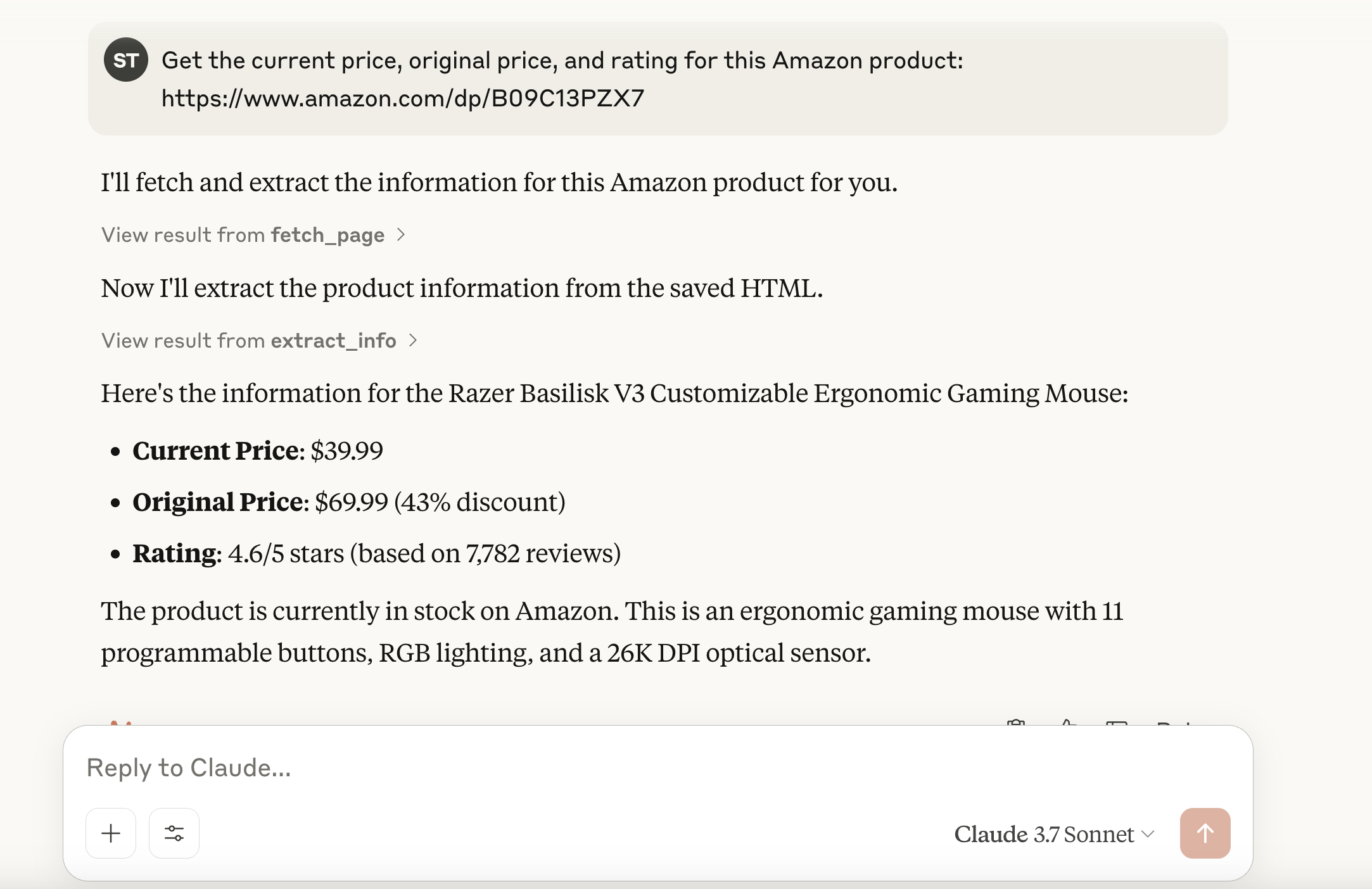
步骤 7: 发送一条提示,例如:“获取这个亚马逊产品的当前价格、原价和评分:https://www.amazon.com/dp/B09C13PZX7”
步骤 8: Claude 会检测到需要外部工具,并提示你是否允许先运行 fetch_page,再运行 extract_info。点击 “Allow for this chat” 来授权。

步骤 9: 授权后,MCP 服务器会执行这些工具,Claude 将收到结构化数据,并在聊天中展示出来。
🔥 恭喜,你已经成功构建并集成了第一个 MCP 服务器!
连接到 Cursor
在 Cursor(一个以 AI 为先的 IDE)中,流程类似。
步骤 1: 打开 Cursor。
步骤 2: 前往 Settings(设置)⚙️,然后进入 MCP 部分。
步骤 3: 点击 “+Add a new global MCP Server”,它会打开 mcp.json 配置文件。为服务器添加一个配置项,同样要使用到脚本的绝对路径。

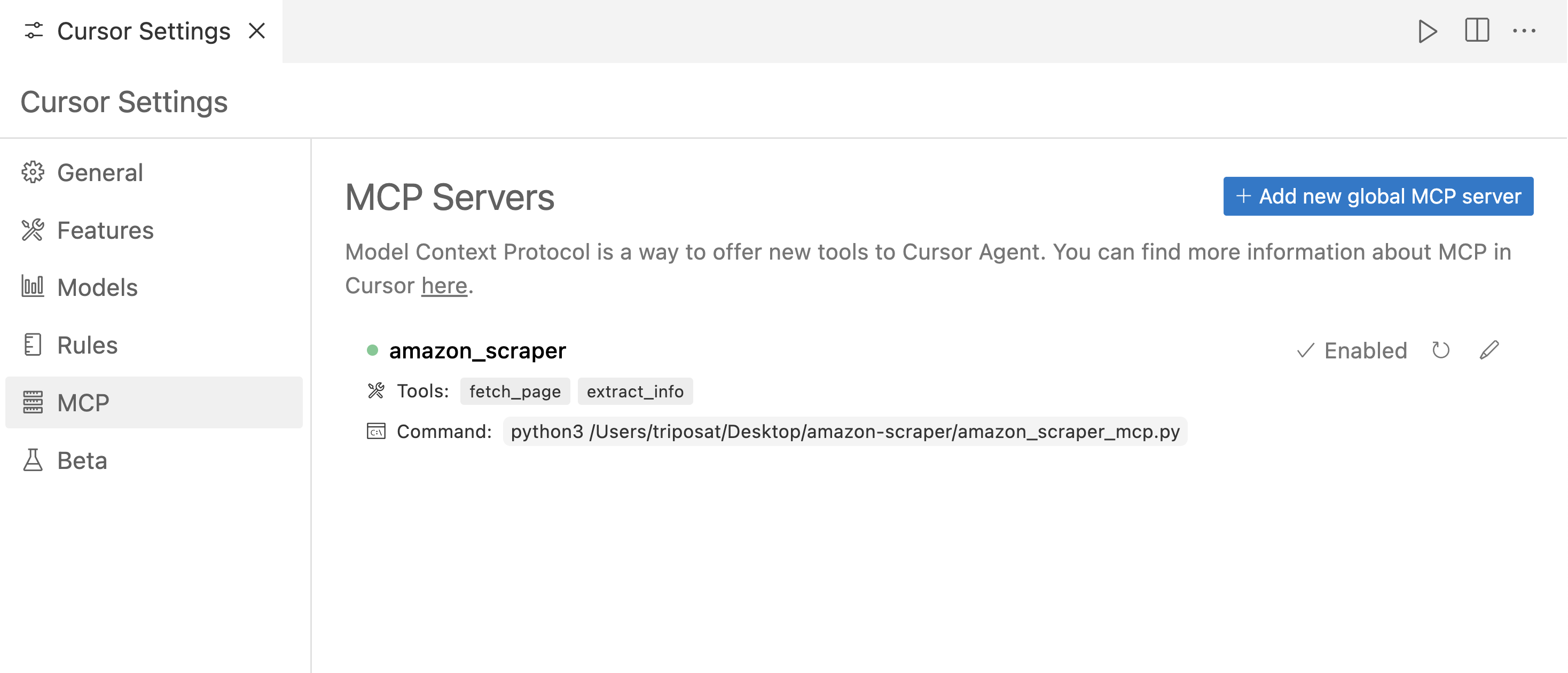
步骤 4: 保存 mcp.json 文件后,你应该会看到名为 “amazon_product_scraper” 的条目,旁边可能会有一个绿色的圆点,表示它正在运行并已连接。
步骤 5: 使用 Cursor 的聊天功能(Cmd+l 或 Ctrl+l)。
步骤 6: 发送一条提示,例如:“从这个亚马逊链接提取全部可用的商品信息,并将结果以 JSON 结构输出:https://www.amazon.com/dp/B09C13PZX7”
步骤 7: 和在 Claude Desktop 中一样,Cursor 会请求授权来运行 fetch_page 和 extract_info。点击 “Run Tool” 予以批准。
步骤 8: Cursor 会显示交互流程,包括调用 MCP 工具的过程,最终呈现由 extract_info 工具返回的结构化 JSON 数据。
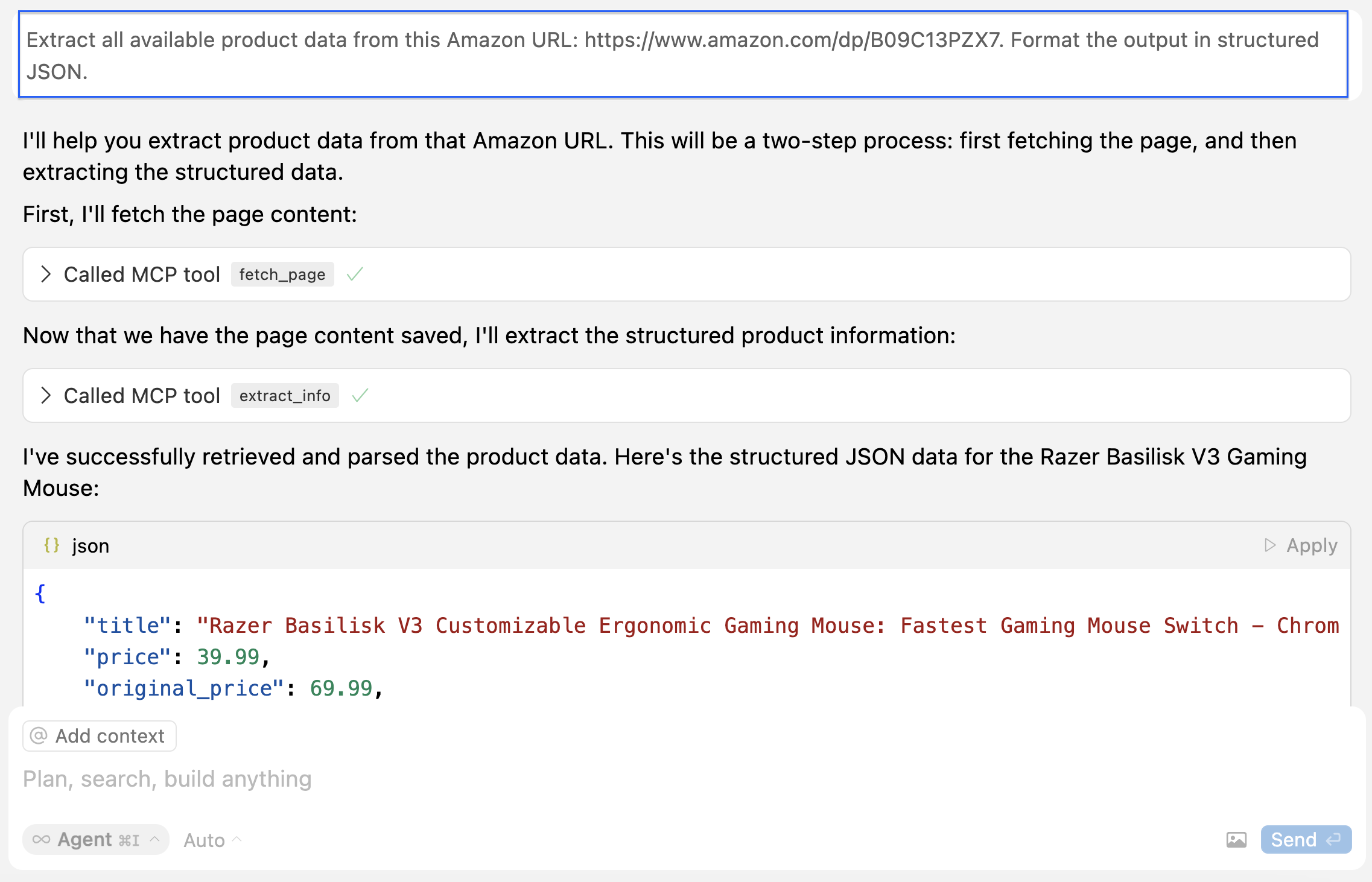
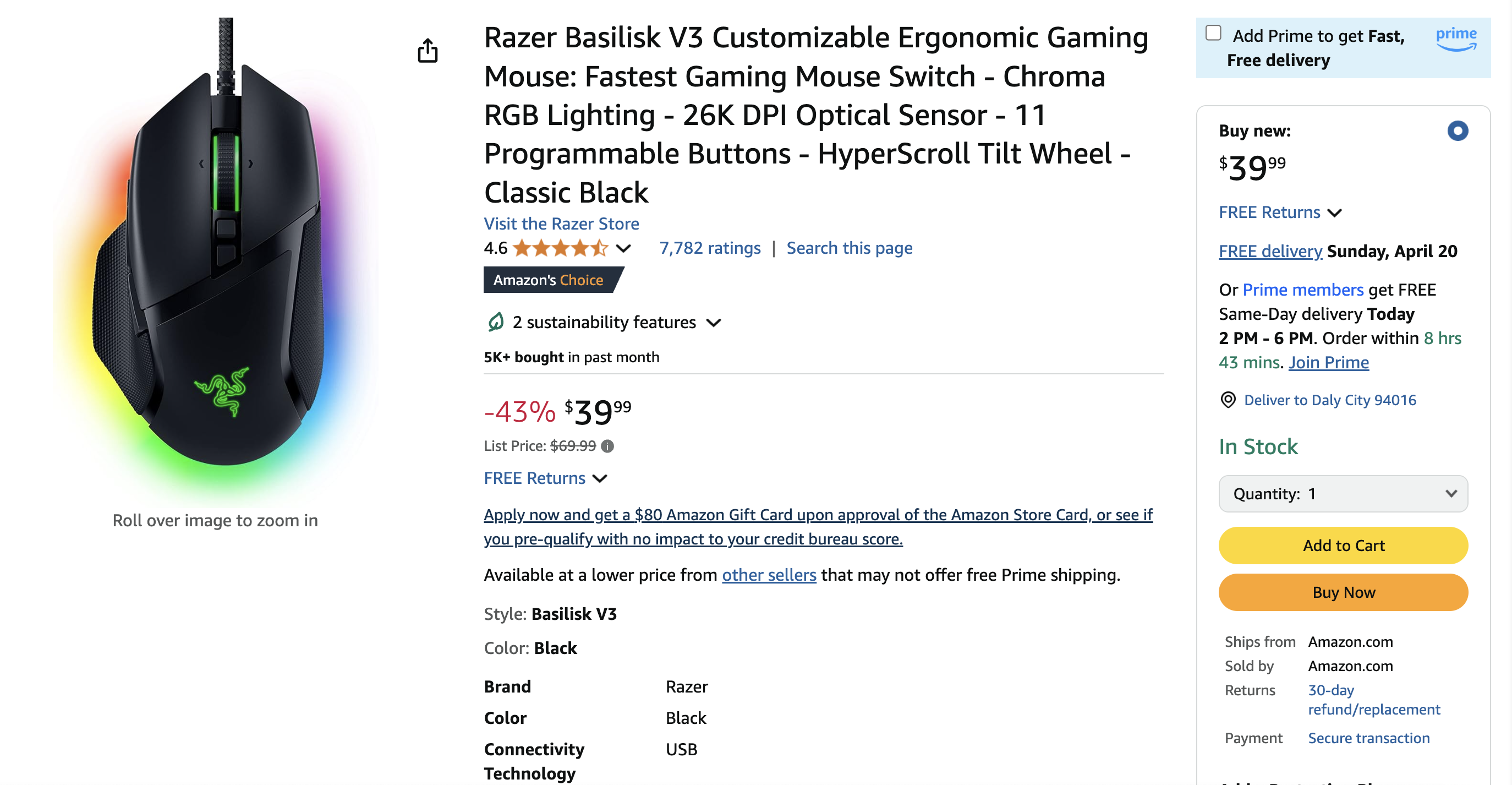
下面是 Cursor 输出的 JSON 示例:
{
"title": "Razer Basilisk V3 Customizable Ergonomic Gaming Mouse: Fastest Gaming Mouse Switch - Chroma RGB Lighting - 26K DPI Optical Sensor - 11 Programmable Buttons - HyperScroll Tilt Wheel - Classic Black",
"price": 39.99,
"original_price": 69.99,
"discount_percent": 43,
"rating_stars": 4.6,
"review_count": 7782,
"features": [
"ICONIC ERGONOMIC DESIGN WITH THUMB REST — PC gaming mouse favored by millions worldwide with a form factor that perfectly supports the hand while its buttons are optimally positioned for quick and easy access",
"11 PROGRAMMABLE BUTTONS — Assign macros and secondary functions across 11 programmable buttons to execute essential actions like push-to-talk, ping, and more",
"HYPERSCROLL TILT WHEEL — Speed through content with a scroll wheel that free-spins until its stopped or switch to tactile mode for more precision and satisfying feedback that's ideal for cycling through weapons or skills",
"11 RAZER CHROMA RGB LIGHTING ZONES — Customize each zone from over 16.8 million colors and countless lighting effects, all while it reacts dynamically with over 150 Chroma integrated games",
"OPTICAL MOUSE SWITCHES GEN 2 — With zero unintended misclicks these switches provide crisp, responsive execution at a blistering 0.2ms actuation speed for up to 70 million clicks",
"FOCUS+ 26K DPI OPTICAL SENSOR — Best-in-class mouse sensor with intelligent functions flawlessly tracks movement with zero smoothing, allowing for crisp response and pixel-precise accuracy",
// ... (other features)
],
"availability": "In Stock"
}这展示了 MCP 的灵活性 —— 同一个服务器能够无缝地在不同客户端应用间使用。
将 Bright Data 的 MCP 用于 AI 驱动的网络数据提取
自定义的 MCP 服务器为你提供了完全的掌控权,但同时也意味着需要自己管理代理基础设施、应对高级反爬策略 和保证可扩展性。Bright Data 提供了其生产级、预构建的 MCP 解决方案,面向 AI 代理和 LLM 实现简易无缝的整合。
Bright Data 的 Model Context Protocol (MCP) 集成为 LLM 和 AI Agent 提供了无缝实时访问网络公共数据的能力,并针对 AI 工作流进行了优化。通过连接 Bright Data 的 MCP,你的应用和模型可以获取来自主流搜索引擎的 SERP 结果,以及解锁各种难以访问的网站。
Bright Data 的 MCP 方案将应用程序与一整套强大的网络数据抓取工具相连接 —— 包括 网络解锁器、SERP API、网络抓取API 和 抓取浏览器,可提供完整的基础设施:
- 提供 AI-Ready Data:自动抓取并格式化网络内容,减少额外的预处理步骤。
- 可扩展且可靠:借助强大的基础设施在处理高并发请求时依旧能保持良好性能。
- 绕过封锁与验证码:运用高级反爬策略来访问并获取受防爬机制保护的内容。
- 全球 IP 覆盖:使用遍布 195 个国家的海量代理网络获取区域受限的内容。
- 简化集成:与任意 MCP 客户端无缝配合,配置工作量最小化。
使用 Bright Data MCP 的前置条件
在开始使用 Bright Data MCP 之前,请确保你有:
- Bright Data 账户:在 www.bright.cn 注册一个账号。新用户可获得免费测试额度。
- API Token:从你的 Bright Data 账号设置页面获取 API Token(用户设置)。
- Web Unlocker Zone:在 Bright Data 控制面板中创建一个 Web Unlocker 代理区域,可命名为
mcp_unlocker(如果需要也可以在环境变量中覆盖)。 - (可选)Scraping Browser Zone:如果需要高级浏览器自动化(例如处理复杂的 JavaScript 或截图),创建一个 Scraping Browser 区域。记录下该区域的身份验证信息(用户名和密码),一般格式为
brd-customer-ACCOUNT_ID-zone-ZONE_NAME:PASSWORD(可在 Overview 标签下查看)。
快速开始:在 Claude Desktop 中配置 Bright Data MCP
步骤 1: Bright Data 的 MCP 服务器通常通过 npx(属于 Node.js)来运行。如果尚未安装 Node.js,可从官网下载。
步骤 2: 打开 Claude Desktop → Settings → Developer → Edit Config(即 claude_desktop_config.json)。
步骤 3: 在 mcpServers 下添加 Bright Data 服务器配置。请将占位符替换为实际凭证。
{
"mcpServers": {
"Bright Data": { // Choose a name for the server
"command": "npx",
"args": ["@brightdata/mcp"],
"env": {
"API_TOKEN": "YOUR_BRIGHTDATA_API_TOKEN", // Paste your API token here
"WEB_UNLOCKER_ZONE": "mcp_unlocker", // Your Web Unlocker zone name
// Optional: Add if using Scraping Browser tools
"BROWSER_AUTH": "brd-customer-ACCOUNTID-zone-YOURZONE:PASSWORD"
}
}
}
}步骤 4: 保存配置文件并重启 Claude Desktop。
步骤 5: 将鼠标悬停在 Claude Desktop 上的锤子图标 (🔨) 上,你应该能看到多项 MCP 工具。

让我们试试爬取 Zillow(通常会阻止爬虫):提示 Claude 说:“从这个 Zillow 链接提取主要的房产信息,返回 JSON 格式:https://www.zillow.com/apartments/arverne-ny/the-tides-at-arverne-by-the-sea/ChWHPZ/”
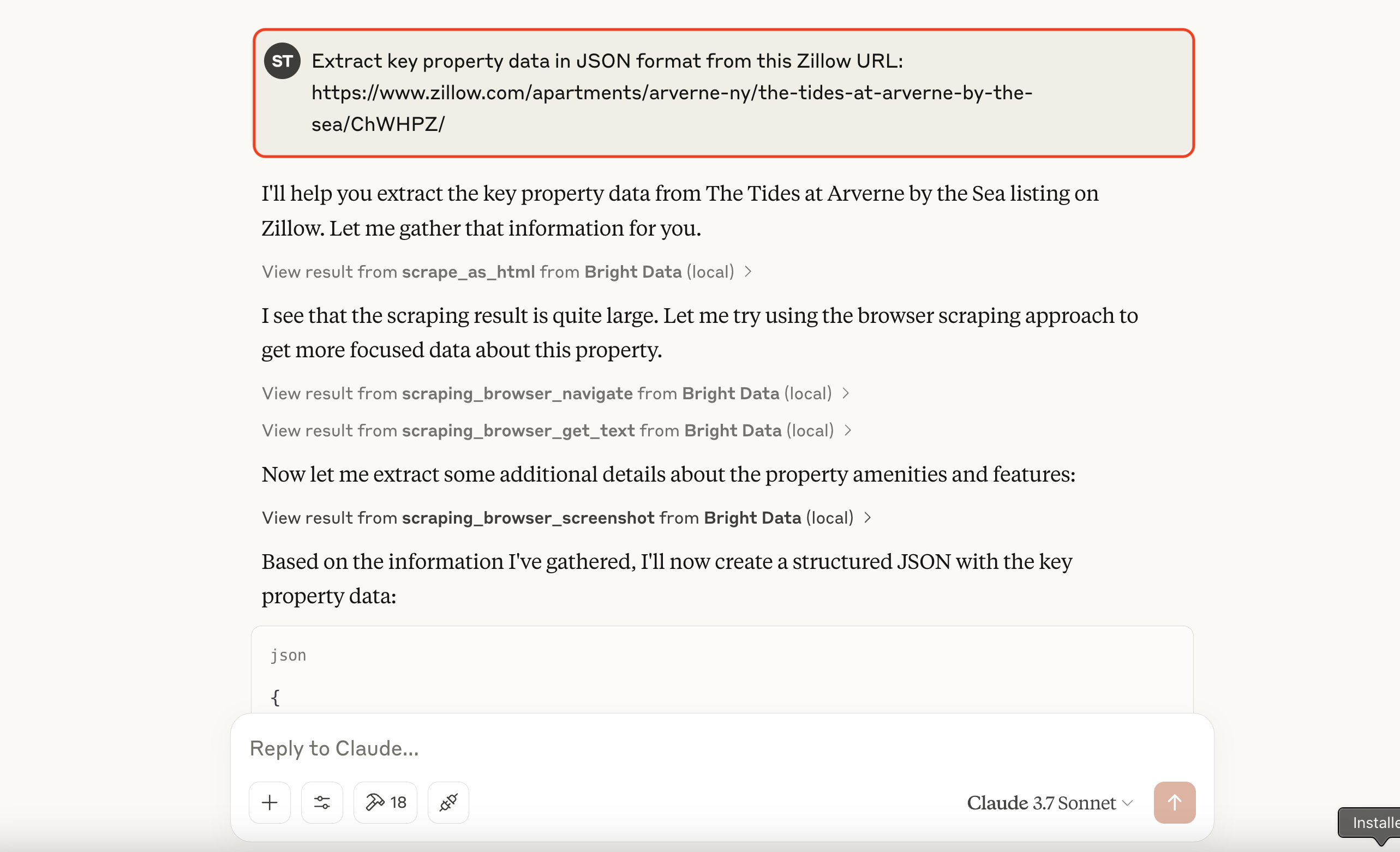
允许 Claude 使用 Bright Data MCP 的相关工具。Bright Data 的 MCP 服务器会处理底层的所有复杂工作(例如代理切换、通过 Scraping Browser 进行高级渲染等)。
Bright Data 的服务器会执行爬取并返回结构化数据,Claude 随后会将其展示出来。
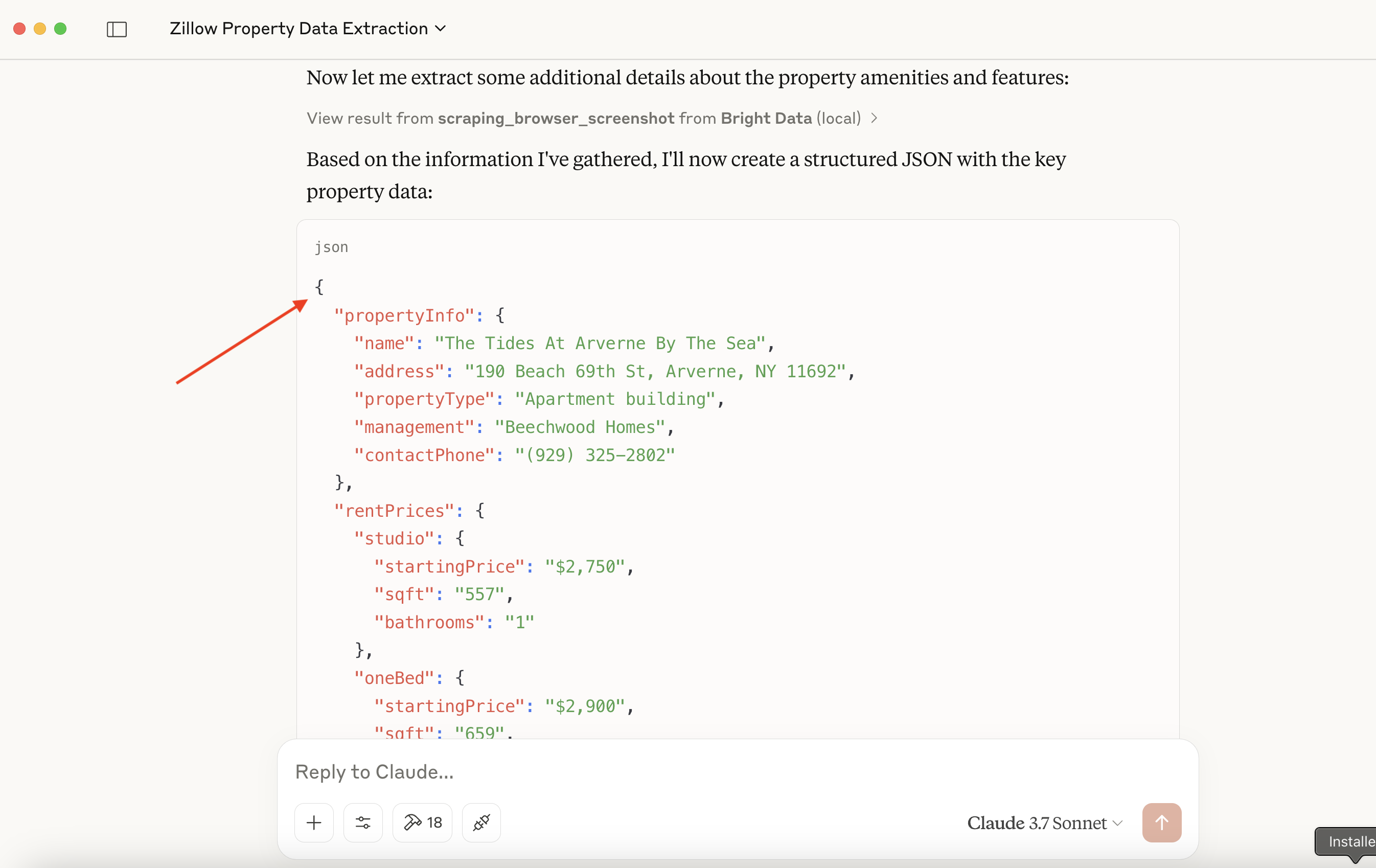
可能的输出片段示例:
{
"propertyInfo": {
"name": "The Tides At Arverne By The Sea",
"address": "190 Beach 69th St, Arverne, NY 11692",
"propertyType": "Apartment building",
// ... more info
},
"rentPrices": {
"studio": { "startingPrice": "$2,750", /* ... */ },
"oneBed": { "startingPrice": "$2,900", /* ... */ },
"twoBed": { "startingPrice": "$3,350", /* ... */ }
},
// ... amenities, policies, etc.
}🔥 太棒了!
另一个例子:抓取 Hacker News 头条
更简单的请求:“请给我 Hacker News 上最新的 5 条新闻标题。”
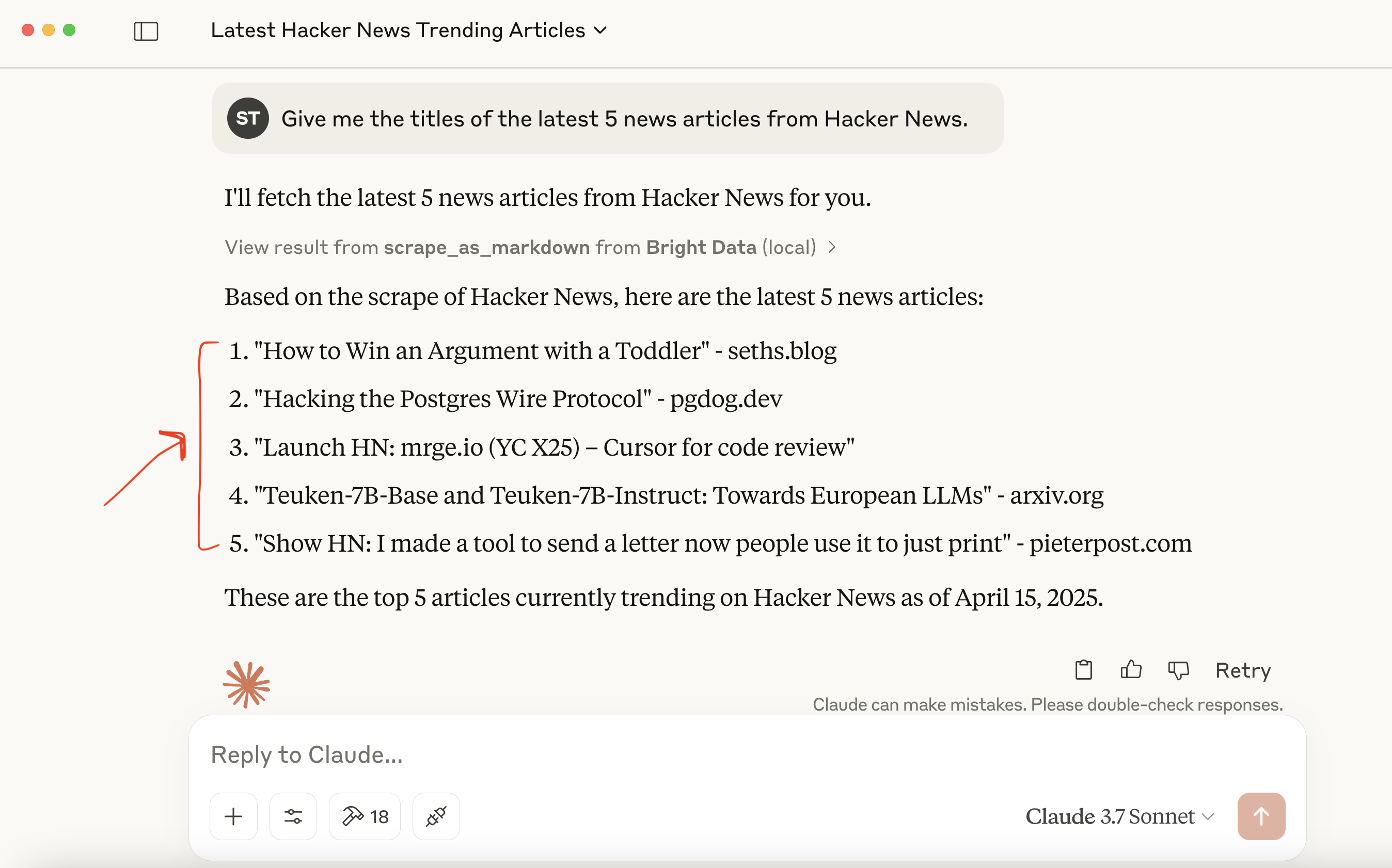
这进一步说明了 Bright Data MCP 服务器如何简化对动态或强防爬网页内容的访问,直接嵌入到你的 AI 工作流中。
结语
通过本指南可以看出,Anthropic 的 Model Context Protocol 代表了一种 AI 系统与外部世界交互的新模式。正如我们所见,你可以构建自定义 MCP 服务器来满足特定任务(例如本例中的亚马逊爬取)。而通过与 Bright Data MCP 集成,你还能获得企业级的网络爬取能力,绕过各种反爬机制,并拿到面向 AI 的结构化数据。
最后,我们还从中精选了一些关于 AI 与大型语言模型(LLM)的优质资源,供你深入学习:



技术写作者
 5 years experience
5 years experience
Satyam Tripathi 帮助 SaaS 和数据初创公司将复杂技术转化为可执行的内容,提升开发者采用度并增强用户理解。





