

在本指南中,你将学习:
- 什么是 OpenAI Agents SDK
- 为何将它与 Web Unlocker 服务集成是最大化其有效性的关键
- 如何在详细的分步教程中使用 OpenAI Agents SDK 和 Web Unlocker API 在 Python 中构建一个 Agent
让我们开始吧!
什么是 OpenAI Agents SDK?
OpenAI Agents SDK 是 OpenAI 推出的开源 Python 库,用于以简单、轻量且可直接投入生产的方式来构建基于 Agent 的 AI 应用。该库是 OpenAI 早期实验项目 Swarm 的改进演进。
OpenAI Agents SDK 重点提供了少量核心原语,并尽量减少抽象:
- Agents(代理):将大语言模型(LLM)与特定指令和工具结合,以执行任务。
- Handoffs(任务交接):让一个 Agent 在需要时将任务委派给其他 Agent。
- Guardrails(防护):用于验证 Agent 的输入是否符合预期格式或条件。
这些构件再加上 Python 的灵活性,使用户能够轻松定义 Agent 与各种工具之间的复杂交互。
该 SDK 还内置了追踪(tracing)功能,方便可视化、调试和评估 Agent 的工作流。它甚至支持针对特定用例进行模型微调(fine-tuning)。
此类 AI Agent 构建方式的最大局限
大多数 AI Agent 的目标都是自动化网页操作,无论是获取内容还是与页面元素交互。换言之,它们需要以编程方式浏览网络。
除去 AI 模型本身可能的理解偏差之外,这些 Agent 面临的最大 挑战往往来自网站的防护机制。很多网站使用了反爬和反机器人技术,可能会阻止或干扰 AI Agent 的访问。如今,针对 AI 的 CAPTCHA 以及高级机器人检测系统正变得越来越普遍,这一问题尤为突出。
那么,这是否意味着 AI Web Agent 就无法继续了呢?当然不是!
要克服这些障碍,你需要借助类似 Bright Data 的 Web Unlocker API 这样的解决方案来增强 Agent 的网页浏览能力。该工具可与任何 HTTP 客户端或连接互联网的解决方案(包括 AI Agent)配合使用,充当“解锁网页内容”的网关,可从任何网页返回干净且不受阻拦的 HTML。再也不用担心验证码(CAPTCHA)、IP 封禁或被屏蔽的内容。
正因如此,将 OpenAI Agents SDK 与 Web Unlocker API 相结合是构建功能强大、能灵活应对网络环境的 AI Agent 的终极方案!
如何将 Agents SDK 与 Web Unlocker API 集成
在接下来的演示中,你将学习如何将 OpenAI Agents SDK 与 Bright Data 的 Web Unlocker API 相结合,打造一个能够:
- 对任何网页的文本进行摘要
- 从电商网站检索结构化的商品数据
- 从新闻文章中获取关键信息
为实现上述功能,Agent 会指示 OpenAI Agents SDK 使用 Web Unlocker API 来获取任何网页的内容。一旦获取到内容,Agent 会应用 AI 逻辑来提取并按需求格式化数据。
免责声明:以上三种用例只是示例。你可以通过自定义 Agent 的行为,将此方法扩展到更多场景中。
下面的步骤详细说明了如何使用 OpenAI Agents SDK 和 Bright Data 的 Web Unlocker API 在 Python 中构建一个高性能的 AI 爬取 Agent!
前置条件
在开始动手之前,请确保你拥有以下环境:
- 本地安装了 Python 3 及以上版本
- 拥有一个有效的 Bright Data 帐号
- 拥有一个有效的 OpenAI 帐号
- 对 HTTP 请求的工作原理有一定了解
- 对 Pydantic 模型有一些了解
- 对 AI Agent 的基本原理有概念
即使以上环境尚未完全配置好,也无需担心。接下来的章节会带你完成所有设置。
步骤 #1:项目初始化
首先,确认你的系统安装了 Python 3。如果没有,请前往Python 官网下载,并按照针对你操作系统的安装说明进行安装。
打开终端,创建一个新的文件夹来存放爬取 Agent 项目:
mkdir openai-sdk-agentopenai-sdk-agent 文件夹将包含 Python 版本的、基于 Agents SDK 的 Agent 的所有代码。
进入该项目文件夹,并创建一个 虚拟环境:
cd openai-sdk-agent
python -m venv venv在你喜欢的 Python IDE 中加载该项目文件夹。Visual Studio Code + Python 插件或PyCharm 社区版都是不错的选择。
在 openai-sdk-agent 文件夹中新建一个名称为 agent.py 的 Python 文件。此时你的文件夹结构大致如下:
目前,scraper.py 还是空的 Python 脚本,但稍后会包含完整的 AI Agent 逻辑。
在 IDE 的终端里,激活虚拟环境。在 Linux 或 macOS 上,运行:
./env/bin/activate在 Windows 上,运行:
env/Scripts/activate现在一切就绪!你已经为使用 OpenAI Agents SDK 和 Web Unlocker 构建 AI Agent 准备好了 Python 环境。
步骤 #2:安装项目依赖并开始
本项目中将用到以下 Python 库:
openai-agents:OpenAI 的 Agents SDK,用于在 Python 中构建 AI Agent。requests:与 Bright Data 的 Web Unlocker API 交互,获取网页 HTML 内容,以供 AI Agent 使用。更多用法参见我们关于Python Requests 库的指南。pydantic:用于定义结构化输出模型,让 Agent 可以以清晰且经过验证的格式返回数据。markdownify:用于将原始 HTML 内容转成 Markdown。(很快你会了解这样做的好处。)python-dotenv:从.env文件中加载环境变量,用于存储 OpenAI 和 Bright Data 的密钥。
在已经激活的虚拟环境中,安装它们:
pip install requests pydantic openai-agents openai-agents markdownify python-dotenv接着,在 scraper.py 中初始化以下导入以及异步框架的模板代码:
import asyncio
from agents import Agent, RunResult, Runner, function_tool
import requests
from pydantic import BaseModel
from markdownify import markdownify as md
from dotenv import load_dotenv
# AI agent logic...
async def run():
# Call the async AI agent logic...
if __name__ == "__main__":
asyncio.run(run())很好!下一步,加载环境变量。
步骤 #3:配置环境变量读取
在项目文件夹中添加一个 .env 文件:
该文件将存储你的环境变量,比如 API 密钥和令牌。要从该文件加载环境变量,可使用 dotenv 包中的 load_dotenv():
load_dotenv()然后就能通过 os.getenv() 函数来读取特定环境变量,比如:
os.getenv("ENV_NAME")别忘了导入标准库 os:
import os很好!环境变量读取功能已经就绪。
步骤 #4:配置 OpenAI Agents SDK
要使用 OpenAI Agents SDK,你需要一个有效的 OpenAI API key。如果你还没有,请参见官方指南来生成你的 API key。
拿到 key 之后,将它加入到 .env 文件中:
OPENAI_API_KEY="<YOUR_OPENAI_KEY>"记得将 <YOUR_OPENAI_KEY> 替换为你的真实 Key。
openai-agents SDK 会自动读取 OPENAI_API_KEY 这一环境变量,因此无需额外配置。
步骤 #5:配置 Web Unlocker API
如果还没有,请注册一个 Bright Data 帐号。如果已有,直接登录即可。
然后,查看 Bright Data 官方 Web Unlocker 快速开始文档来获取你的 API 令牌。或者按照以下步骤操作。
在 Bright Data 的“用户仪表板”页面,点击“Get proxy products”选项:
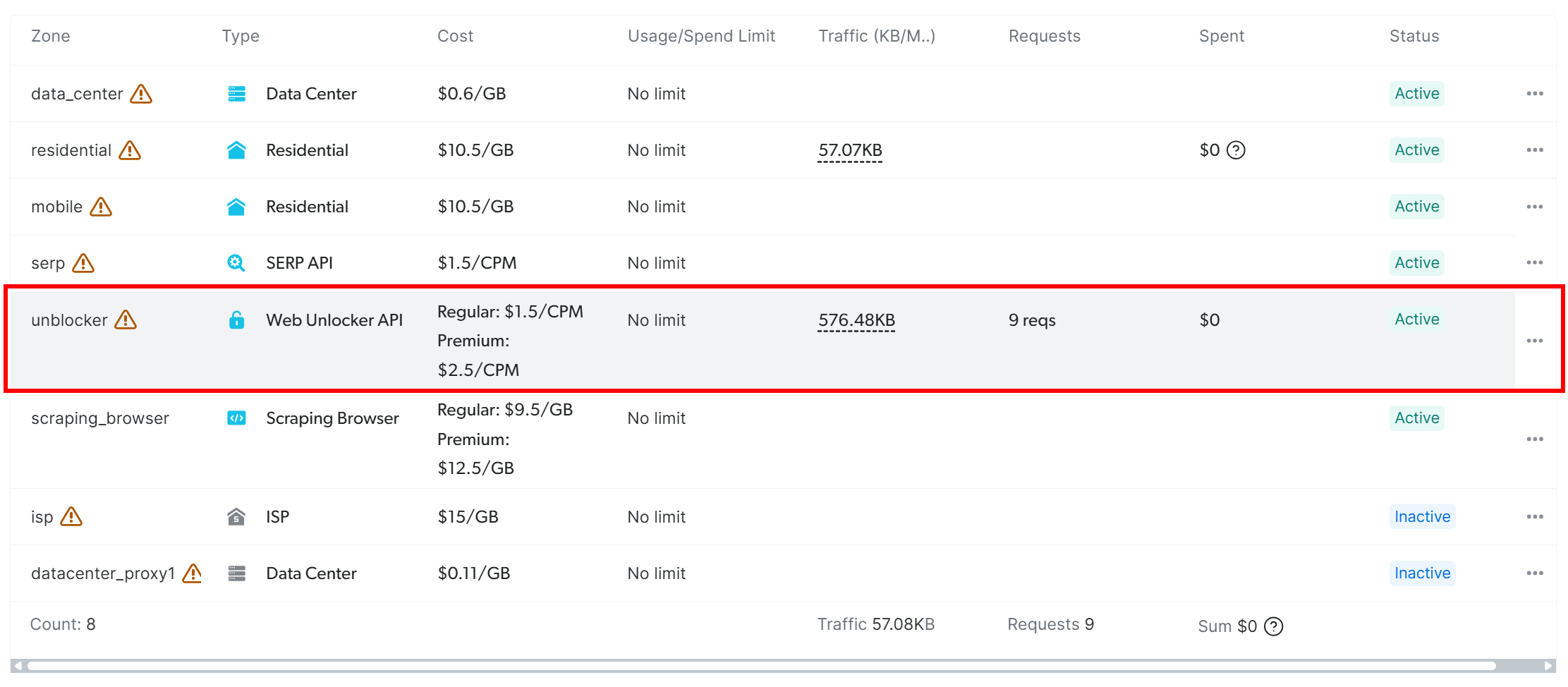
在产品表格中找到标记为 “unblocker” 的一行,然后点击:
进入 “unlocker” 页面后,点击剪贴板图标复制你的 API 令牌:
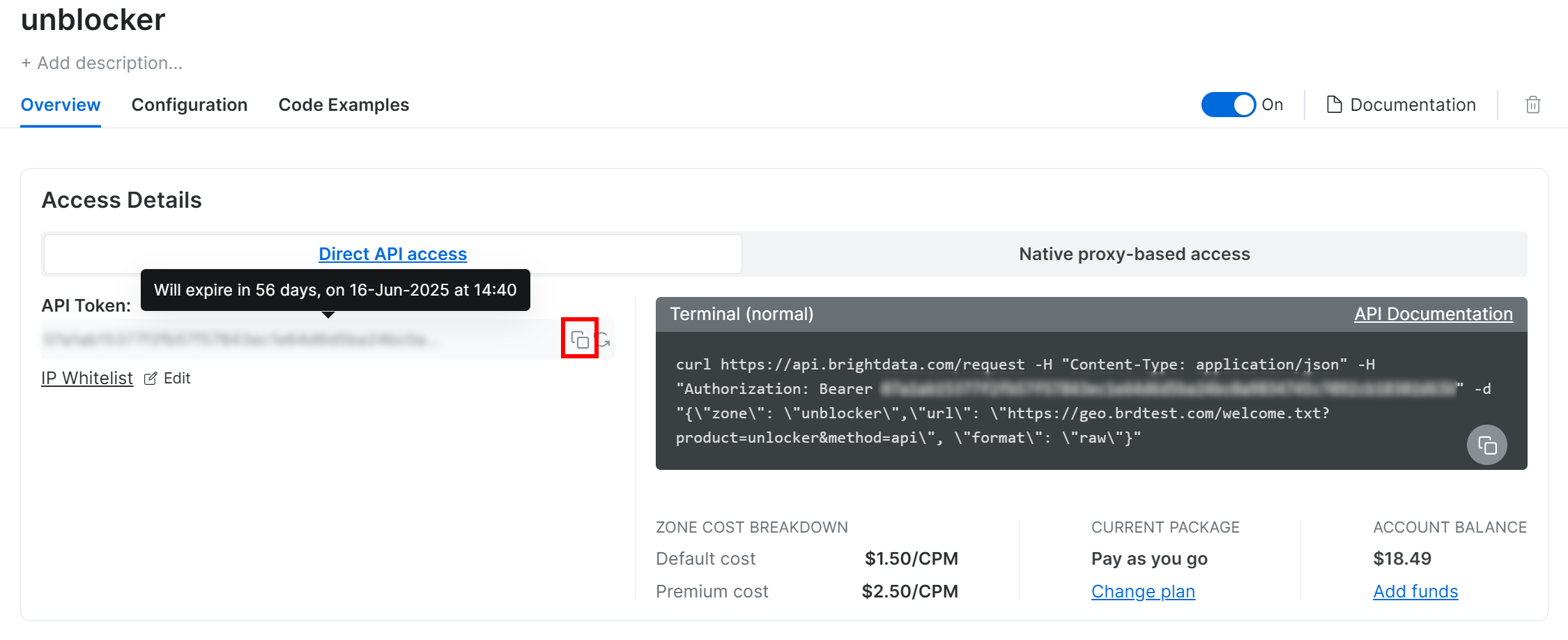
同时,确保右上角的开关处于“On”状态,代表 Web Unlocker 产品已启用。
在 “Configuration(配置)” 选项卡下,为了更好效果,确认以下选项已开启:
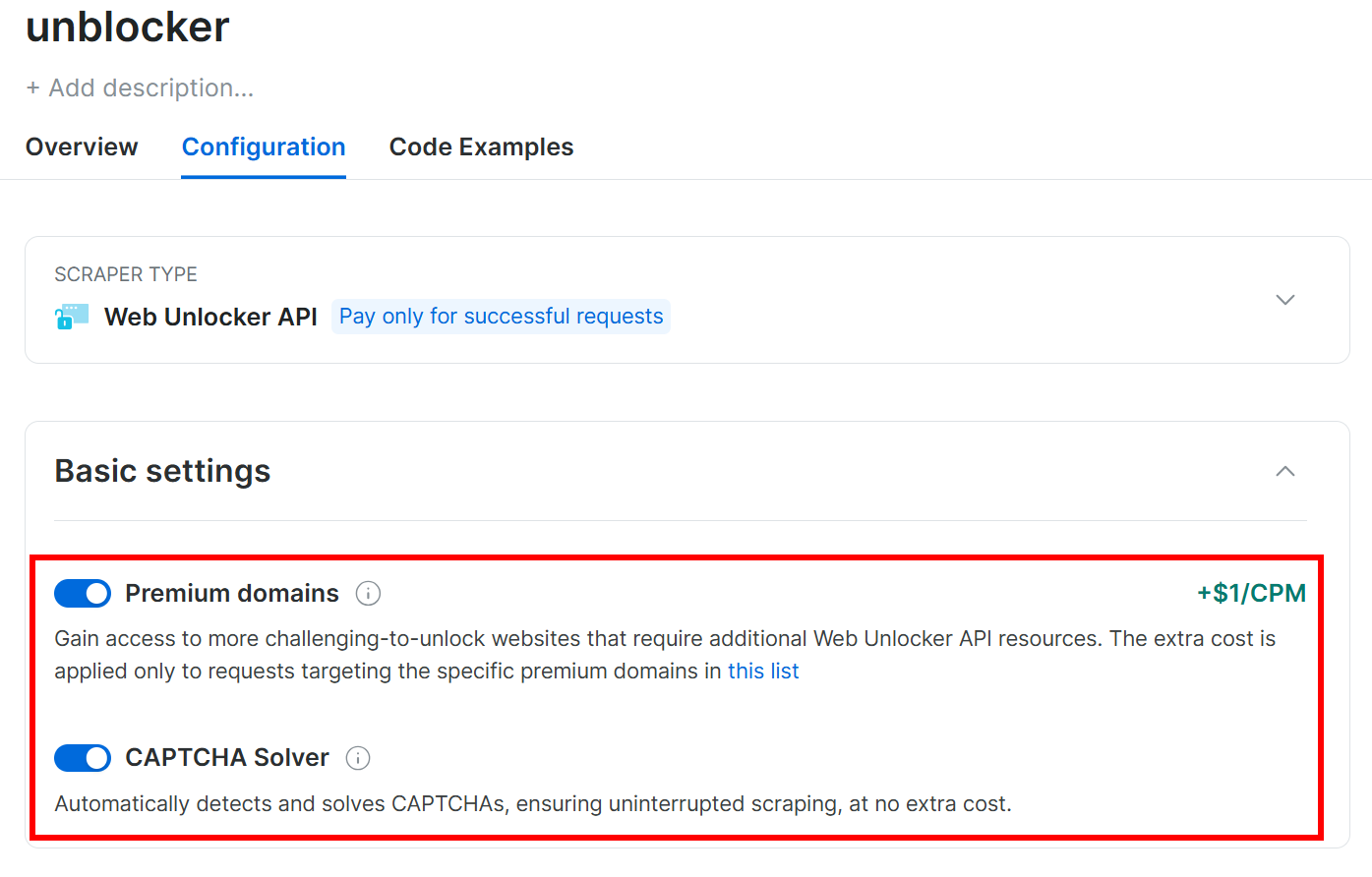
然后在 .env 文件中添加:
BRIGHT_DATA_WEB_UNLOCKER_API_TOKEN="<YOUR_BRIGHT_DATA_WEB_UNLOCKER_API_TOKEN>"将 <YOUR_BRIGHT_DATA_WEB_UNLOCKER_API_TOKEN> 替换为实际的令牌。
好了!现在你已可以在项目中使用 OpenAI SDK 和 Bright Data 的 Web Unlocker API。
步骤 #6:创建网页内容提取函数
创建一个名为 get_page_content() 的函数,实现以下功能:
- 读取环境变量
BRIGHT_DATA_WEB_UNLOCKER_API_TOKEN - 使用
requests向 Bright Data 的 Web Unlocker API 发送请求,传入目标 URL - 获取 API 返回的原始 HTML
- 将 HTML 转换为 Markdown 并返回
实现如下:
@function_tool
def get_page_content(url: str) -> str:
"""
Retrieves the HTML content of a given web page using Bright Data's Web Unlocker API,
bypassing anti-bot protections. The response is converted from raw HTML to Markdown
for easier and cheaper processing.
Args:
url (str): The URL of the web page to scrape.
Returns:
str: The Markdown-formatted content of the requested page.
"""
# Read the Bright Data's Web Unlocker API token from the envs
BRIGHT_DATA_WEB_UNLOCKER_API_TOKEN = os.getenv("BRIGHT_DATA_WEB_UNLOCKER_API_TOKEN")
# Configure the Web Unlocker API call
api_url = "https://api.brightdata.com/request"
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {BRIGHT_DATA_WEB_UNLOCKER_API_TOKEN}"
}
data = {
"zone": "unblocker",
"url": url,
"format": "raw"
}
# Make the call to Web Uncloker to retrieve the unblocked HTML of the target page
response = requests.post(api_url, headers=headers, data=json.dumps(data))
# Extract the raw HTML response
html = response.text
# Convert the HTML to markdown and return it
markdown_text = md(html)
return markdown_text注意 1:@function_tool 装饰器表示该函数可作为工具(tool)供 Agent 调用,执行某些特定操作。在这里,函数充当了“引擎”,让 Agent 可以获取目标网页的内容。
注意 2:get_page_content() 函数必须显式声明输入类型,否则会出现类似 Error getting response: Error code: 400 - {'error': {'message': "Invalid schema for function 'get_page_content': In context=('properties', 'url'), schema must have a 'type' key... "}} 的错误。
可能会有人问:为什么要将原始 HTML 转换为 Markdown? 原因很简单:为了更高的性能和更低的成本!
HTML 中有很多多余的部分,包含脚本、样式和元数据,这些往往并不是 AI Agent 所需的核心内容。如果你的 Agent 只需要文本、链接和图像等要点,Markdown 格式可大幅简化冗余。
具体而言,HTML 转成 Markdown 后,可将输入体积减少多达 99%,进而:
- 节省 Token,降低使用 OpenAI 模型的成本
- 减少处理时间,因为模型在较小的输入上运行更快
如需了解更多,可阅读这篇文章:“为什么新的 AI Agent 纷纷选择 Markdown 而不是 HTML?”
步骤 #7:定义数据模型
OpenAI SDK Agents 需要 Pydantic 模型来定义输出数据的结构。回想一下,我们的 Agent 最终会返回三种可能的结果:
- 页面摘要
- 商品信息
- 新闻文章信息
因此,我们定义三个对应的 Pydantic 模型:
class Summary(BaseModel):
summary: str
class Product(BaseModel):
name: str
price: Optional[float] = None
currency: Optional[str] = None
ratings: Optional[int] = None
rating_score: Optional[float] = None
class News(BaseModel):
title: str
subtitle: Optional[str] = None
authors: Optional[List[str]] = None
text: str
publication_date: Optional[str] = None注意:Optional 的使用可以让 Agent 更通用。并非所有页面都会同时包含上述所有字段,因此使用可选字段可避免因缺少信息而导致解析报错。
别忘了从 typing 中导入 Optional 和 List:
from typing import Optional, List很好!现在可以开始编写 Agent 的逻辑部分了。
步骤 #8:初始化 Agent 逻辑
我们可使用 Agent 类(来自 openai-agents SDK)来定义三个特化 Agent:
summarization_agent = Agent(
name="Text Summarization Agent",
instructions="You are a content summarization agent that summarizes the input text.",
tools=[get_page_content],
output_type=Summary,
)
product_info_agent = Agent(
name="Product Information Agent",
instructions="You are a product parsing agent that extracts product details from text.",
tools=[get_page_content],
output_type=Product,
)
news_info_agent = Agent(
name="News Information Agent",
instructions="You are a news parsing agent that extracts relevant news details from text.",
tools=[get_page_content],
output_type=News,
)每个 Agent 都:
- 包含了一段指令,告诉模型它将执行的任务。
- 使用
get_page_content()工具来获取输入数据(即网页内容)。 - 输出结果对应到其中一个(
Summary、Product或News)Pydantic 模型。
为了自动将用户请求路由到适合的特化 Agent,我们还需要一个更高层次的 Agent:
routing_agent = Agent(
name="Routing Agent",
instructions=(
"You are a high-level decision-making agent. Based on the user's request, "
"hand off the task to the appropriate agent."
),
handoffs=[summarization_agent, product_info_agent, news_info_agent],
)这是我们在 run() 函数中使用的顶层代理,用以驱动整个 AI Agent 逻辑。
步骤 #9:实现执行循环
在 run() 函数中,加入如下循环调用我们的 AI Agent:
# Keep iterating until the use type "exit"
while True:
# Read the user's request
request = input("Your request -> ")
# Stops the execution if the user types "exit"
if request.lower() in ["exit"]:
print("Exiting the agent...")
break
# Read the page URL to operate on
url = input("Page URL -> ")
# Routing the user's request to the right agent
output = await Runner.run(routing_agent, input=f"{request} {url}")
# Conver the agent's output to a JSON string
json_output = json.dumps(output.final_output.model_dump(), indent=4)
print(f"Output -> n{json_output}nn")上面这个循环会不断接收用户的输入,并根据请求把它路由到最匹配的 Agent(摘要、商品或新闻),将请求与目标 URL 合并,然后执行逻辑,最后使用 json 格式打印出结构化结果。导入 json:
import json非常棒!现在你已经完成了 OpenAI Agents SDK 与 Bright Data 的 Web Unlocker API 的集成。
步骤 #10:合并所有功能
最后,你的 scraper.py 文件应包含以下完整内容:
import asyncio
from agents import Agent, RunResult, Runner, function_tool
import requests
from pydantic import BaseModel
from markdownify import markdownify as md
from dotenv import load_dotenv
import os
from typing import Optional, List
import json
# Load the environment variables from the .env file
load_dotenv()
# Define the Pydantic output models for your AI agent
class Summary(BaseModel):
summary: str
class Product(BaseModel):
name: str
price: Optional[float] = None
currency: Optional[str] = None
ratings: Optional[int] = None
rating_score: Optional[float] = None
class News(BaseModel):
title: str
subtitle: Optional[str] = None
authors: Optional[List[str]] = None
text: str
publication_date: Optional[str] = None
@function_tool
def get_page_content(url: str) -> str:
"""
Retrieves the HTML content of a given web page using Bright Data's Web Unlocker API,
bypassing anti-bot protections. The response is converted from raw HTML to Markdown
for easier and cheaper processing.
Args:
url (str): The URL of the web page to scrape.
Returns:
str: The Markdown-formatted content of the requested page.
"""
# Read the Bright Data's Web Unlocker API token from the envs
BRIGHT_DATA_WEB_UNLOCKER_API_TOKEN = os.getenv("BRIGHT_DATA_WEB_UNLOCKER_API_TOKEN")
# Configure the Web Unlocker API call
api_url = "https://api.brightdata.com/request"
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {BRIGHT_DATA_WEB_UNLOCKER_API_TOKEN}"
}
data = {
"zone": "unblocker",
"url": url,
"format": "raw"
}
# Make the call to Web Uncloker to retrieve the unblocked HTML of the target page
response = requests.post(api_url, headers=headers, data=json.dumps(data))
# Extract the raw HTML response
html = response.text
# Convert the HTML to markdown and return it
markdown_text = md(html)
return markdown_text
# Define the individual OpenAI agents
summarization_agent = Agent(
name="Text Summarization Agent",
instructions="You are a content summarization agent that summarizes the input text.",
tools=[get_page_content],
output_type=Summary,
)
product_info_agent = Agent(
name="Product Information Agent",
instructions="You are a product parsing agent that extracts product details from text.",
tools=[get_page_content],
output_type=Product,
)
news_info_agent = Agent(
name="News Information Agent",
instructions="You are a news parsing agent that extracts relevant news details from text.",
tools=[get_page_content],
output_type=News,
)
# Define a high-level routing agent that delegates tasks to the appropriate specialized agent
routing_agent = Agent(
name="Routing Agent",
instructions=(
"You are a high-level decision-making agent. Based on the user's request, "
"hand off the task to the appropriate agent."
),
handoffs=[summarization_agent, product_info_agent, news_info_agent],
)
async def run():
# Keep iterating until the use type "exit"
while True:
# Read the user's request
request = input("Your request -> ")
# Stops the execution if the user types "exit"
if request.lower() in ["exit"]:
print("Exiting the agent...")
break
# Read the page URL to operate on
url = input("Page URL -> ")
# Routing the user's request to the right agent
output = await Runner.run(routing_agent, input=f"{request} {url}")
# Conver the agent's output to a JSON string
json_output = json.dumps(output.final_output.model_dump(), indent=4)
print(f"Output -> n{json_output}nn")
if __name__ == "__main__":
asyncio.run(run())就这样!不到 100 行 Python 代码就构建了一个 AI Agent,可:
- 摘要任何网页内容
- 从任意电商网站中提取商品信息
- 从任意在线新闻中抽取新闻详情
现在让我们看看它是如何工作的吧!
步骤 #11:测试 AI Agent
运行命令:
python agent.py就能启动你的 AI Agent。假设你想要摘要 Bright Data AI 服务中心 的页面,只需输入:

结果会是类似下面这样、以 JSON 格式返回的内容:

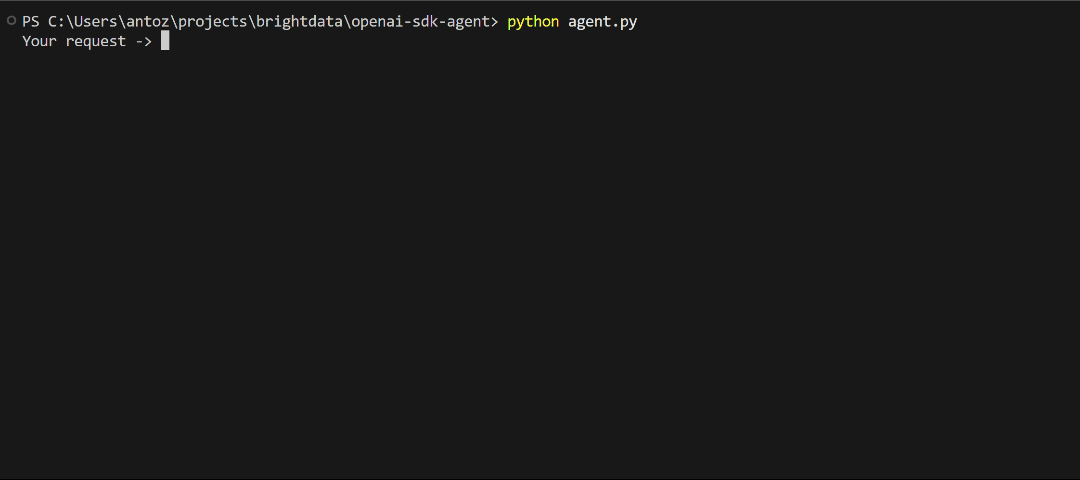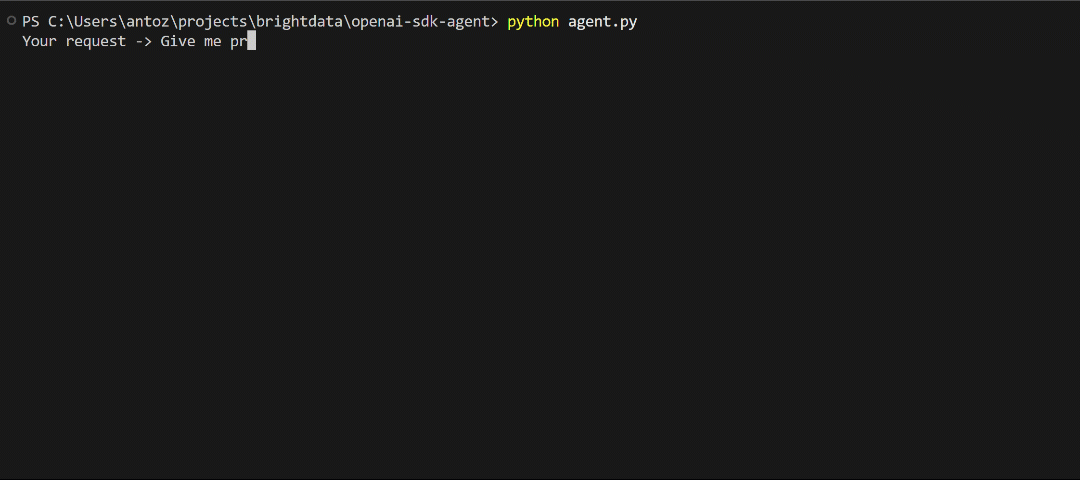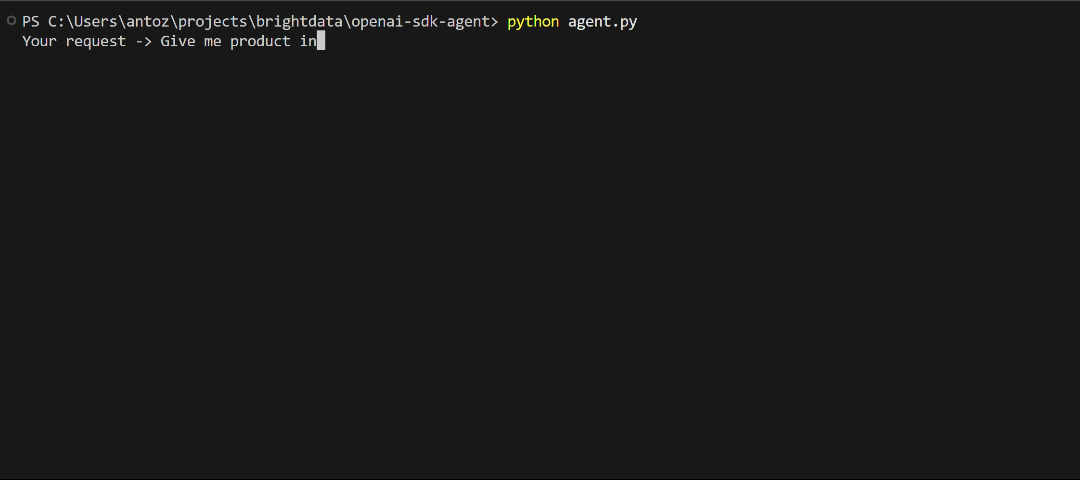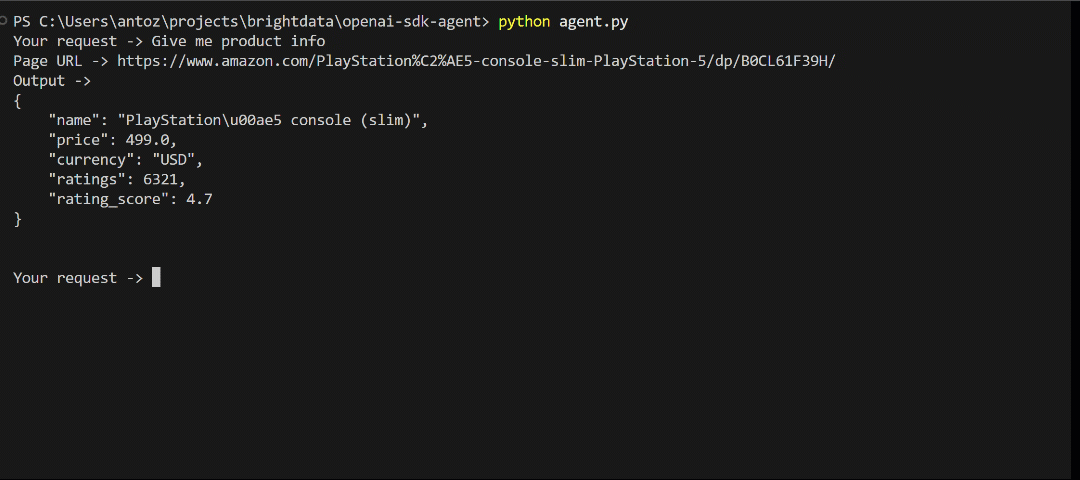
再比如,你想从 亚马逊 PS5 产品页面获取商品数据:
通常情况下,亚马逊的验证码(CAPTCHA)和反爬机制会阻止你的请求。但借助 Web Unlocker API,你的 AI Agent 可以无需担心被封锁:
返回内容可能如下:
{
"name": "PlayStationu00ae5 console (slim)",
"price": 499.0,
"currency": "USD",
"ratings": 6321,
"rating_score": 4.7
}这就是亚马逊页面上的真实产品信息!
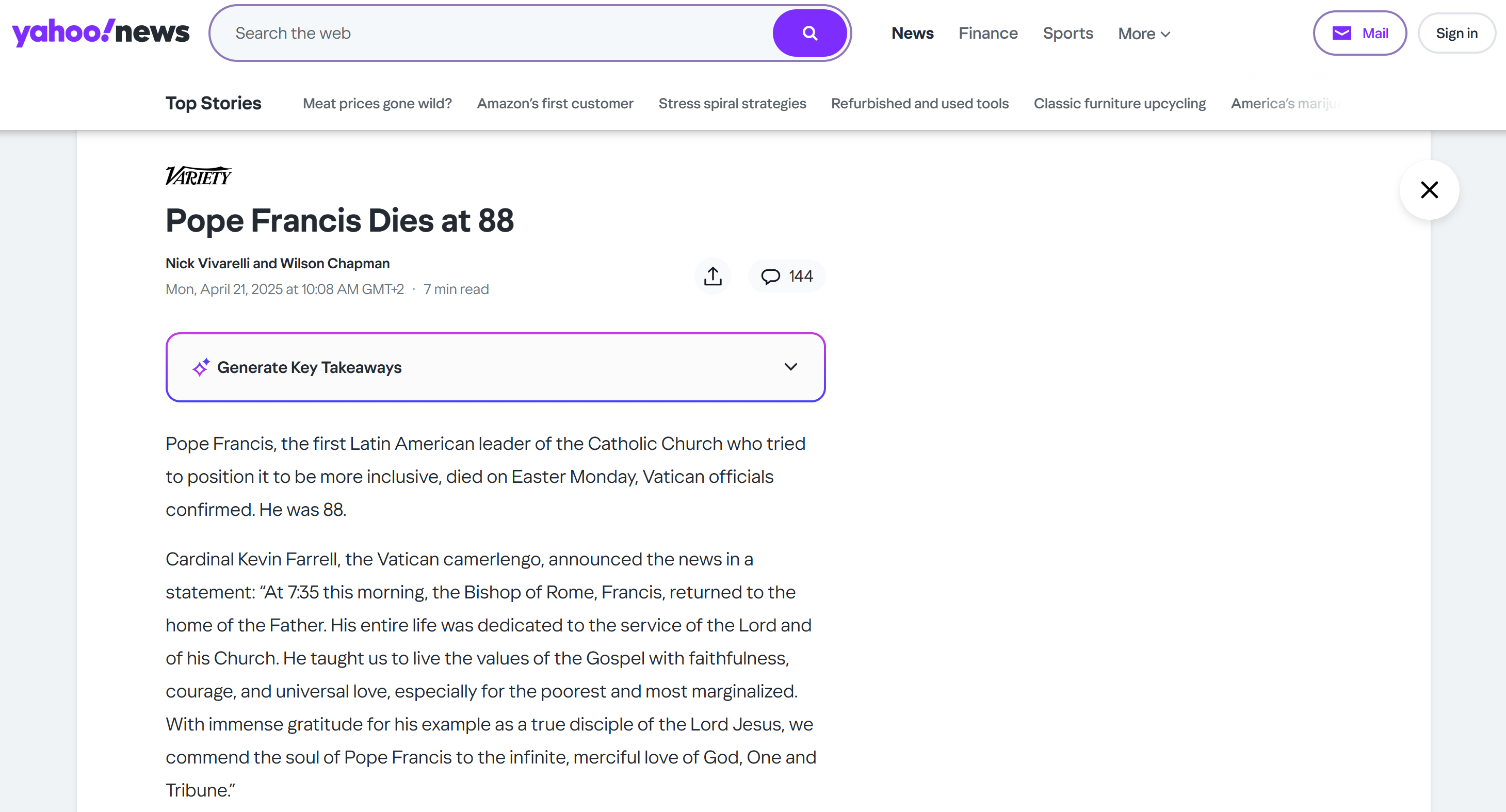
最后,如果想从Yahoo News 的某篇文章中获取结构化的新闻内容:
可以这样输入:
Your request -> Give me news info
Page URL -> https://www.yahoo.com/news/pope-francis-dies-88-080859417.html结果会是类似:
{
"title": "Pope Francis Dies at 88",
"subtitle": null,
"authors": [
"Nick Vivarelli",
"Wilson Chapman"
],
"text": "Pope Francis, the 266th Catholic Church leader who tried to position the church to be more inclusive, died on Easter Monday, Vatican officials confirmed. He was 88. (omitted for brevity...)",
"publication_date": "Mon, April 21, 2025 at 8:08 AM UTC"
}同样,由于有 Web Unlocker,访问新闻页面也并未被阻。
结论
在本篇文章中,你学习了如何结合使用 OpenAI Agents SDK 与网页解锁(Web Unlocker)服务来构建一个高效的 Python Web Agent。
实操表明,将 OpenAI SDK 与 Bright Data 的 Web Unlocker API 相结合,可以打造出能在任何网页上可靠运行的 AI Agent。以上只是 Bright Data 的产品与服务赋能强大 AI 集成方案的示例之一。
你可以探索我们在 AI Agent 开发领域的解决方案:
- 自治型 AI Agent:可实时搜索、访问并与任意网站交互,提供强大的 API。
- 垂直领域 AI 应用:从特定行业来源提取数据,自定义数据管道。
- 基础模型:访问合规、网络规模的数据集,用于预训练、评估与微调。
- 多模态 AI:利用全球最大规模的图像、视频与音频库,为 AI 优化。
- 数据供应商:连接优质供应方,批量获取高质量、适配 AI 的数据集。
- 数据包:直接获取精心整理的现成数据集——结构化、补充并带注释。
详情请访问我们完整的 AI 产品页面。
快来注册 Bright Data 帐号,体验我们的所有产品与服务,助力 AI Agent 开发!
支持支付宝等多种支付方式



