
网页抓取是一种可以用于从网页提取数据的技术。当目标网站不提供API、API无法使用或不返回您想要的确切数据时,网页抓取尤其有用。
正则表达式(简称“Regex”)是一种用于从文本中提取数据的强大语法模式,通常用于网页抓取。Regex定义了一种可以在文本中匹配的模式,广泛用于查找和提取文本信息。因此,它在网页抓取中被广泛应用。
在本文中,您将学习如何在Python中使用正则表达式进行网页抓取。本文结束后,您将了解如何抓取静态和动态网站,并理解可能遇到的一些限制。
什么是正则表达式
正则表达式是使用匹配特定模式的标记来定义的。详细描述所有标记超出了本文的范围,但下表列出了几个常用标记,您可能会遇到:
| 标记 | 匹配 |
|---|---|
| 任何非特殊字符 | 给定的字符 |
^ |
字符串的开始 |
$ |
字符串的结束 |
. |
除n外的任何字符 |
* |
零个或多个前一个元素的出现 |
? |
前一个元素的零个或一个出现 |
+ |
前一个字符的一个或多个出现 |
{Digit} |
前一个元素的确切次数 |
d |
任何数字 |
s |
任何空白字符 |
w |
任何单词字符 |
D |
d的反向 |
S |
s的反向 |
W |
w的反向 |
要了解更多关于正则表达式的信息并进行实际操作,请访问regexr.com。此外,这篇文章分享了一些优化正则表达式性能的重要提示。
在Python中使用正则表达式进行网页抓取
在本教程中,您将构建一个简单的Python网页抓取器,使用正则表达式从网页中提取数据。
首先,为您的项目创建一个目录:
mkdir web_scraping_with_regex
cd web_scraping_with_regex然后创建一个Python虚拟环境:
python -m venv venv并激活它:
source ./venv/bin/activate要编写网页抓取器,您需要安装两个库:
requests用于获取网页beautifulsoup4用于解析HTML内容并查找元素
运行以下命令安装这些库:
pip install beautifulsoup4 requests注意:在抓取任何网站之前,请查看其条款和条件,确保您被允许抓取该网站。如果禁止抓取,请勿进行抓取。
抓取电子商务网站
在本节中,您将构建一个网页抓取器来抓取一个简单的虚拟电子商务网站。您将抓取第一页并提取书籍的标题和价格。
为此,请创建一个名为scraper.py的文件并导入所需的模块:
import requests
from bs4 import BeautifulSoup
import re注意:
re模块是一个内置的Python模块,用于处理正则表达式。
接下来,您需要对目标网页进行GET请求以获取页面的HTML内容:
page = requests.get('https://books.toscrape.com/')将这些数据传递给Beautiful Soup,解析网页的HTML结构:
soup = BeautifulSoup(page.content, 'html.parser')为了了解HTML中元素的结构,您可以使用检查元素工具。打开网页并按Ctrl + Shift + I打开检查器。如截图所示,产品存储在li元素中,类名为col-xs-6 col-sm-4 col-md-3 col-lg-3。书名可以从a元素的title属性中找到,价格存储在类名为price_color的p元素中:
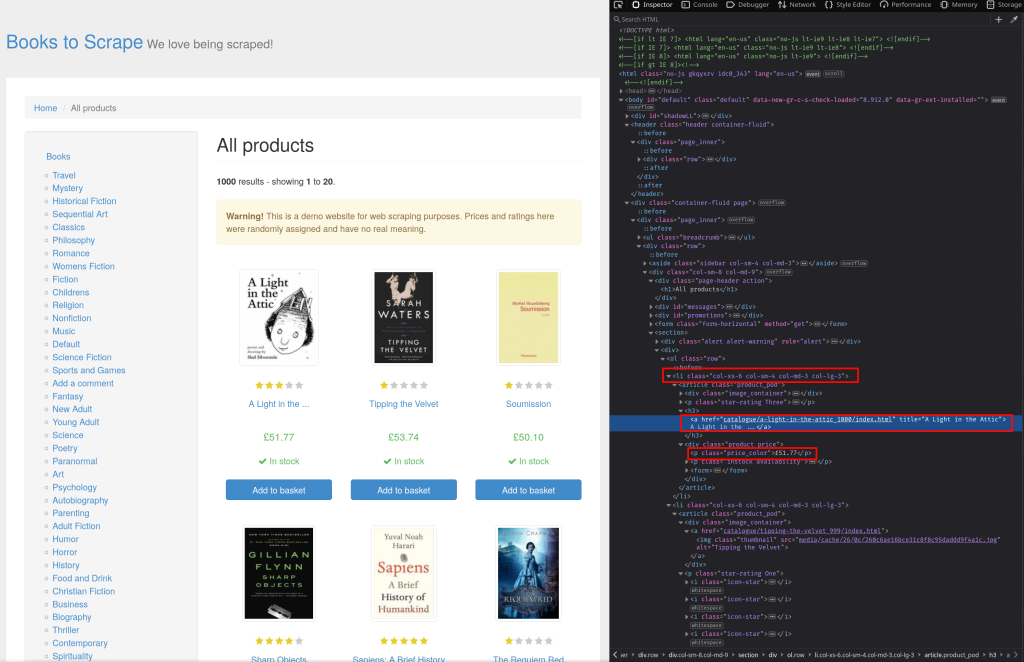
使用Beautiful Soup的find_all方法查找所有类名为col-xs-6 col-sm-4 col-md-3 col-lg-3的li元素:
books = soup.find_all("li", class_="col-xs-6 col-sm-4 col-md-3 col-lg-3")
content = str(books)现在,content变量包含了li元素的HTML文本,您可以使用正则表达式提取书名和价格。
第一步是构建一个匹配书名和价格的正则表达式。为此,您需要再次使用检查元素。
观察书名存储在a元素的title属性中,a元素如下所示:
<a href="..." title="...">要匹配title 后面的双引号内容,使用经典的.*?正则表达式。.匹配单个字符,*匹配前一个元素的零个或多个出现(在这种情况下,匹配.的任何字符),?匹配前一个元素的零个或一个出现(在这种情况下,匹配.*的任何字符)。它们一起用于匹配双引号中的内容,完整表达式如下:
<a href=".*?" title="(.*?)"括号括住.*?用于创建一个捕获组。捕获组记住关于模式匹配的信息,在复杂表达式中用于识别和引用已匹配的模式。然而,在这种情况下,捕获组用于提取匹配的文本。如果没有捕获组,文本仍然会匹配,但您无法访问匹配的文本。
要提取价格,使用相同的正则表达式(.*?)。价格存储在类名为price_color的p元素中,所以完整的正则表达式是<p class="price_color">(.*?)</p>。
定义这两个模式:
re_book_title = r'<a href=".*?" title="(.*?)"'
re_prices = r'<p class="price_color">(.*?)</p>'注意:如果您想知道为什么
?在.*后面是必要的,这个Stack Overflow回答解释了?的作用。
现在,您可以使用re.findall()从HTML字符串中查找所有正则表达式匹配项:
titles = re.findall(re_book_title, content)
prices = re.findall(re_prices, content)最后,迭代匹配项并打印结果:
for i in zip(titles, prices):
print(f"{i[0]}: {i[1]}")您可以使用python scraper.py运行此代码。输出如下所示:
A Light in the Attic: £51.77
Tipping the Velvet: £53.74
Soumission: £50.10
Sharp Objects: £47.82
Sapiens: A Brief History of Humankind: £54.23
The Requiem Red: £22.65
The Dirty Little Secrets of Getting Your Dream Job: £33.34
The Coming Woman: A Novel Based on the Life of the Infamous Feminist, Victoria Woodhull: £17.93
The Boys in the Boat: Nine Americans and Their Epic Quest for Gold at the 1936 Berlin Olympics: £22.60
The Black Maria: £52.15
Starving Hearts (Triangular Trade Trilogy, #1): £13.99
Shakespeare's Sonnets: £20.66
Set Me Free: £17.46
Scott Pilgrim's Precious Little Life (Scott Pilgrim #1): £52.29
Rip it Up and Start Again: £35.02
Our Band Could Be Your Life: Scenes from the American Indie Underground, 1981-1991: £57.25
Olio: £23.88
Mesaerion: The Best Science Fiction Stories 1800-1849: £37.59
Libertarianism for Beginners: £51.33
It's Only the Himalayas: £45.17抓取维基百科页面
现在,让我们构建一个抓取器,可以抓取维基百科页面并提取所有链接的信息。
创建一个名为wiki_scraper.py的新文件。像之前一样,首先导入库、进行GET请求并解析内容:
import requests
from bs4 import BeautifulSoup
import re
page = requests.get('https://en.wikipedia.org/wiki/Web_scraping')
soup = BeautifulSoup(page.content, 'html.parser')要查找所有链接,使用find_all()方法:
links = soup.find_all("a")
content = str(links)链接文本存储在title属性中,链接URL存储在href属性中。您可以使用相同的正则表达式(.*?)提取信息。完整的表达式如下:
<a href="(.*?)" title="(.*?)">.*?</a>注意第三个.*?不在捕获组中,因为您对标签的内容不感兴趣。
像之前一样,使用findall()查找所有匹配项并打印结果:
re_links = r'<a href="(.*?)" title="(.*?)">.*?</a>'
links = re.findall(re_links, content)
for i in links:
print(f"{i[0]} => {i[1]}")使用python wiki_scraper.py运行时,输出如下:
OUTPUT TRUNCATED FOR BREVITY
/wiki/Category:Web_scraping => Category:Web scraping
/wiki/Category:CS1_maint:_multiple_names:_authors_list => Category:CS1 maint: multiple names: authors list
/wiki/Category:CS1_Danish-language_sources_(da) => Category:CS1 Danish-language sources (da)
/wiki/Category:CS1_French-language_sources_(fr) => Category:CS1 French-language sources (fr)
/wiki/Category:Articles_with_short_description => Category:Articles with short description
/wiki/Category:Short_description_matches_Wikidata => Category:Short description matches Wikidata
/wiki/Category:Articles_needing_additional_references_from_April_2023 => Category:Articles needing additional references from April 2023
/wiki/Category:All_articles_needing_additional_references => Category:All articles needing additional references
/wiki/Category:Articles_with_limited_geographic_scope_from_October_2015 => Category:Articles with limited geographic scope from October 2015
/wiki/Category:United_States-centric => Category:United States-centric
/wiki/Category:All_articles_with_unsourced_statements => Category:All articles with unsourced statements
/wiki/Category:Articles_with_unsourced_statements_from_April_2023 => Category:Articles with unsourced statements from April 2023抓取动态网站
到目前为止,您抓取的所有网页都是静态的。抓取动态网页稍微困难一些,因为它需要一个浏览器自动化工具,例如Selenium。以下是一个示例,抓取OpenWeatherMap主页的伦敦天气,并使用正则表达式和Selenium抓取当前温度:
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import re
driver = webdriver.Firefox()
driver.get("https://openweathermap.org/city/2643743")
elem = WebDriverWait(driver, 10).until( EC.presence_of_element_located((By.CSS_SELECTOR, ".current-temp")))
content = elem.get_attribute('innerHTML')
re_temp = r'<span .*?>(.*?)</span>'
temp = re.findall(re_temp, content)
print(repr(temp))
driver.close()此代码使用Selenium启动Firefox实例,并使用CSS选择器选择当前温度元素。然后使用正则表达式<span .*?>(.*?)</span>提取温度。
如果您需要更多信息来帮助您开始使用Selenium抓取动态网页,请查看本教程。
正则表达式在网页抓取中的限制
正则表达式是用于模式匹配和提取文本信息的强大工具。开发人员通常学习正则表达式并尝试使用它进行网页抓取。然而,正则表达式本身并不适合网页抓取。正则表达式作用于文本,对HTML结构没有概念或理解。这意味着结果高度依赖于HTML代码的编写方式。例如,在维基百科示例中,您可能已经注意到一些链接未正确提取:

如果您编辑Python代码并添加print(content)打印Beautiful Soup返回的HTML字符串,您会看到罪魁祸首a看起来像这样:
<a href="#cite_ref-9">^</a>在这里,title属性缺失,但在正则表达式中,您假定结构为<a href="(.*?)" title="(.*?)">.*?</a>。由于正则表达式不了解HTML元素,它没有抛出错误或停止匹配,而是.*?模式盲目地匹配字符,直到能够匹配" title="(.*?)">.*?</a>完成模式。这导致吞噬了接下来的几个a标签,显示使用正则表达式如果HTML代码编写方式出乎意料可能导致意外效果。
此外,HTML不是正规语言,这意味着仅使用正则表达式无法解析任意HTML数据。这个Stack Overflow回答是开发人员中的经典讽刺,针对尝试使用正则表达式解析HTML的开发人员。然而,有些情况下,您可以使用正则表达式解析和抓取HTML数据。
例如,如果您有一组已知、有限的HTML代码,并且完全了解代码的结构,您可以使用正则表达式提取信息。例如,如果您知道HTML中的所有a标签都有href和title属性,并符合固定模式,您可以使用正则表达式提取信息。然而,更好且更可靠的解决方案是使用Beautiful Soup等HTML解析器查找元素并从中提取文本数据。
一旦提取了文本数据,您可以使用正则表达式进一步处理它。例如,这里是修改后的维基百科抓取器,使用Beautiful Soup提取href和title属性,然后使用正则表达式过滤掉包含非字母数字字符的标签:
import requests
from bs4 import BeautifulSoup
import re
page = requests.get('https://en.wikipedia.org/wiki/Web_scraping')
soup = BeautifulSoup(page.content, 'html.parser')
links = soup.find_all("a")
for link in links:
href = link.get('href')
title = link.get('title')
if title == None:
title = link.string
if title == None:
continue
pattern = r"[a-zA-Z0-9]"
if re.match(pattern, title):
print(f"{href} => {title}")结论
正则表达式是用于在文本数据中查找模式的强大工具。由于其强大性,它经常用于网页抓取以提取信息。
在本文中,您学习了什么是正则表达式,以及如何使用它与Beautiful Soup结合抓取电子商务网站、维基百科和动态网页。您还了解了一些正则表达式的限制以及如何最好地与其他工具结合使用。
即使您充分利用正则表达式,网页抓取仍然充满挑战。重复网页抓取可能导致抓取器的IP地址被封锁。您还可能遇到CAPTCHA,可能阻止抓取器正常工作。Bright Data提供强大的代理,可以绕过IP封禁。其全球代理网络包括数据中心代理、住宅代理、ISP代理和移动代理。通过Web Unlocker,您可以绕过机器人检测并解决CAPTCHA,无任何麻烦。立即开始免费试用!







