

在这篇博文中,您将了解到:
- 什么是 OpenSea 爬虫
- 可以从 OpenSea 自动提取哪些类型的数据
- 如何使用 Python 创建一个 OpenSea 爬虫脚本
- 何时以及为什么需要更高级的解决方案
让我们开始吧!
什么是 OpenSea 爬虫?
OpenSea 爬虫是一种专门从 OpenSea(全球最大的 NFT 市场)获取数据的工具。该工具的主要目标是自动化收集各种与 NFT 相关的信息。通常,它使用自动化浏览器来实时获取 OpenSea 数据,而无需人工操作。
可以从 OpenSea 爬取哪些数据
以下是您可以从 OpenSea 爬取的一些主要数据点:
- NFT 系列名称:NFT 系列的标题或名称。
- 系列排名:根据其表现对该系列进行的排名或位置。
- NFT 图片:与 NFT 系列或单个项目相关的图片。
- 地板价:该系列中项目列出的最低价格。
- 交易量:NFT 系列的总交易量。
- 百分比变化:该系列在指定时间内的价格变化或百分比变化。
- Token ID:该系列中每个 NFT 的唯一标识符。
- 最近成交价:该系列中某个 NFT 的最新成交价格。
- 销售历史:每个 NFT 项目的交易历史,包括以往的价格和买家。
- 出价:对该系列某个 NFT 当前有效的出价。
- 创作者信息:关于 NFT 创作者的详细信息,如用户名或个人资料。
- 特征/属性:NFT 项目的具体特征或属性(例如:稀有度、颜色等)。
- 项目描述:对该 NFT 项目的一段简短说明或信息。
如何爬取 OpenSea:分步指南
在这个分步教程中,您将学习如何构建一个 OpenSea 爬虫。目标是开发一个 Python 脚本,自动从 “Gaming”页面的“Top”部分获取 NFT 系列数据:
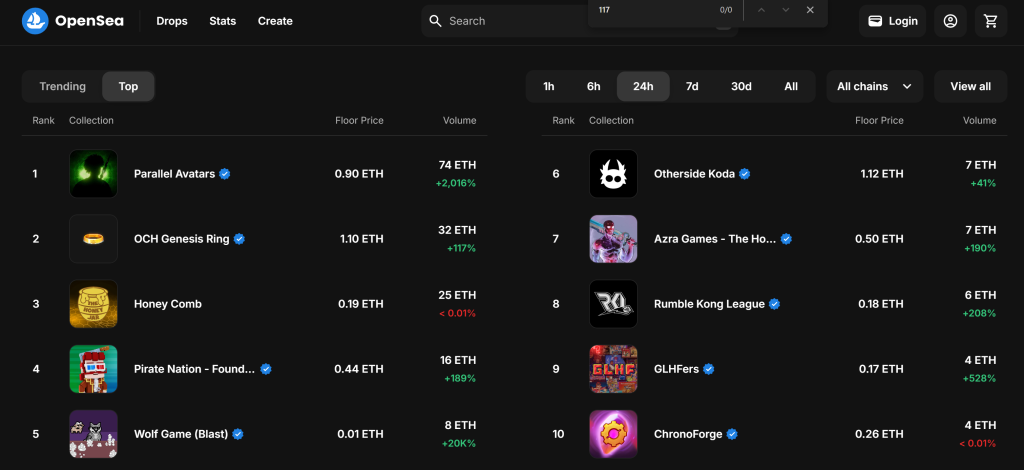
按照以下步骤,看看如何爬取 OpenSea 吧!
步骤 #1:项目初始化
在开始之前,确保您的计算机上安装了 Python 3。如果没有安装,请 下载并按照安装说明进行操作。
使用以下命令创建一个项目文件夹:
mkdir opensea-scraperopensea-scraper 文件夹就是您 Python OpenSea 爬虫的项目目录。
在终端中进入该目录,并在其中初始化一个 虚拟环境:
cd opensea-scraper
python -m venv venv在您喜欢的 Python IDE 中加载此项目文件夹。 Visual Studio Code(配合 Python 插件)或 PyCharm Community Edition都可以。
在项目文件夹中创建一个 scraper.py 文件,现在您的文件夹结构应如下所示:
此时,scraper.py 是一个空的 Python 脚本,但很快就会包含爬虫的核心逻辑。
在 IDE 的终端中,激活虚拟环境。Linux 或 macOS 上执行以下命令:
./env/bin/activate在 Windows 上,则执行:
env/Scripts/activate太好了!现在您已经在一个用于网页爬取的 Python 环境中。
步骤 #2:选择爬虫库
在开始编写代码之前,您需要先确定用于提取所需数据的 最佳爬虫工具。为此,您应首先进行一些初步测试来分析目标网站的行为,步骤如下:
- 以无痕模式打开目标页面,以避免预先存储的 cookie 和偏好影响分析。
- 在页面任意位置右键单击并选择“Inspect”(检查)以打开浏览器的开发者工具。
- 进入“Network”选项卡。
- 刷新页面并进行交互,比如点击 “1h” 或 “6h” 按钮。
- 在“Fetch/XHR”选项卡中监控网络活动。
通过这样的方式,您可以了解该网页是如何加载并动态渲染数据的:
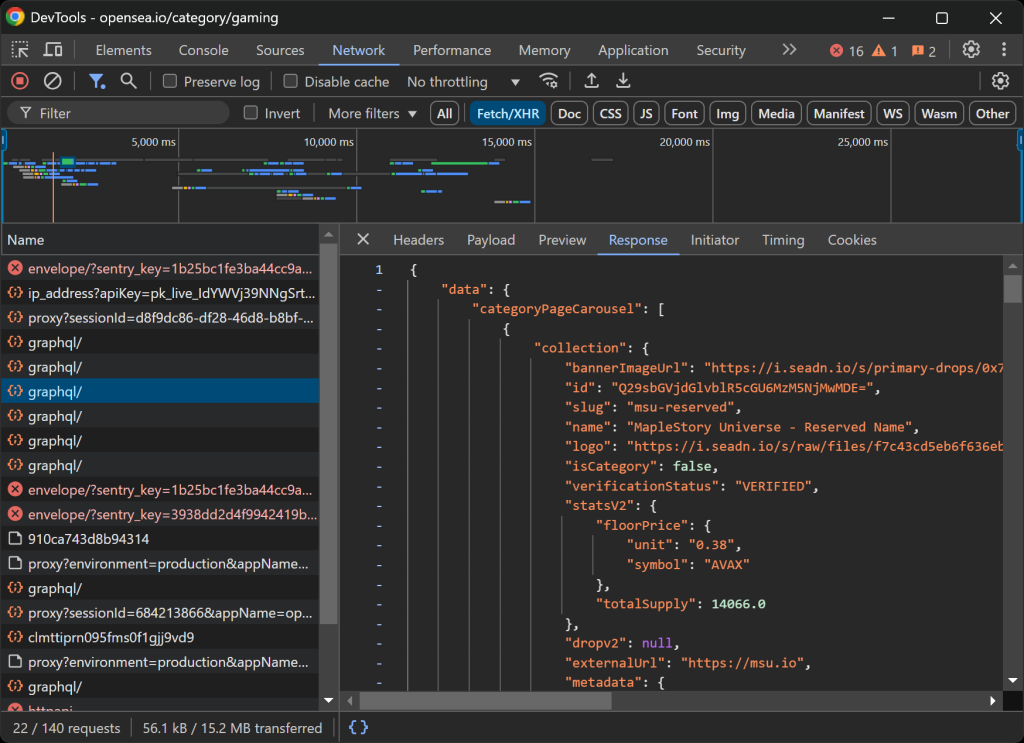
在这里,您可以查看页面实时发起的所有 AJAX 请求。通过检查这些请求,您会发现 OpenSea 从服务器动态获取数据。此外,进一步分析会发现某些按钮交互会触发 JavaScript 渲染,以动态更新页面内容。
这表明要成功爬取 OpenSea,需要使用像 Selenium 这样的浏览器自动化工具!
Selenium 允许您以编程方式控制浏览器,模拟真实用户的交互行为,从而有效地提取数据。现在,让我们安装并开始使用它吧。
步骤 #3:安装并设置 Selenium
可以通过 selenium pip 包来获取 Selenium。在激活的虚拟环境中运行以下命令安装 Selenium:
pip install -U selenium想了解如何使用浏览器自动化工具,可阅读我们的 Selenium 网页爬取指南。
在 scraper.py 中导入 Selenium 并初始化一个 WebDriver 对象来控制 Chrome:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
# Create a Chrome web driver instance
driver = webdriver.Chrome(service=Service())上面的代码片段创建了一个 WebDriver 实例,用于与 Chrome 进行交互。请注意,OpenSea 使用了可检测无头浏览器的反爬虫措施,并会阻止此类请求。具体来说,服务器会返回 “Access Denied” 页面。
这意味着您不能在此爬虫中使用 --headless 标志。如果您有其他需求,可以考虑使用 Playwright Stealth 或 SeleniumBase 作为替代。
由于 OpenSea 会根据浏览器窗口大小进行自适应布局,因此最大化浏览器窗口,以确保渲染的是桌面版页面:
driver.maximize_window()最后,一定要妥善关闭 WebDriver,以释放资源:
driver.quit()做得好!您现在已经完成了在 OpenSea 爬取所需的基本环境配置。
步骤 #4:访问目标页面
使用 Selenium WebDriver 提供的 get() 方法,让浏览器进入目标页面:
driver.get("https://opensea.io/category/gaming")此时,您的 scraper.py 文件应包含以下内容:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
# Create a Chrome web driver instance
driver = webdriver.Chrome(service=Service())
# To avoid the responsive rendering
driver.maximize_window()
# Visit the target page
driver.get("https://opensea.io/category/gaming")
# Scraping logic...
# close the browser and release its resources
driver.quit()在脚本的最后一行设置一个调试断点并运行脚本。您将看到如下界面:
“Chrome 正在被自动测试软件控制” 这条信息表明 Chrome 正在被 Selenium 正常控制。干得不错!
步骤 #5:与网页交互
默认情况下,“Gaming” 页面会显示 “Trending” (趋势)NFT 系列:
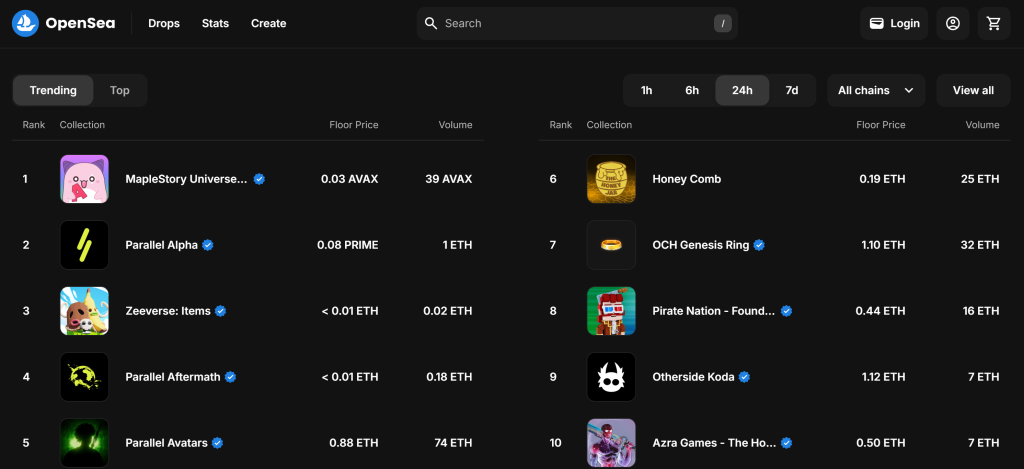
但我们关注的是 “Top” NFT 系列,也就是说,需要让 OpenSea 爬虫点击 “Top” 按钮,如下所示:
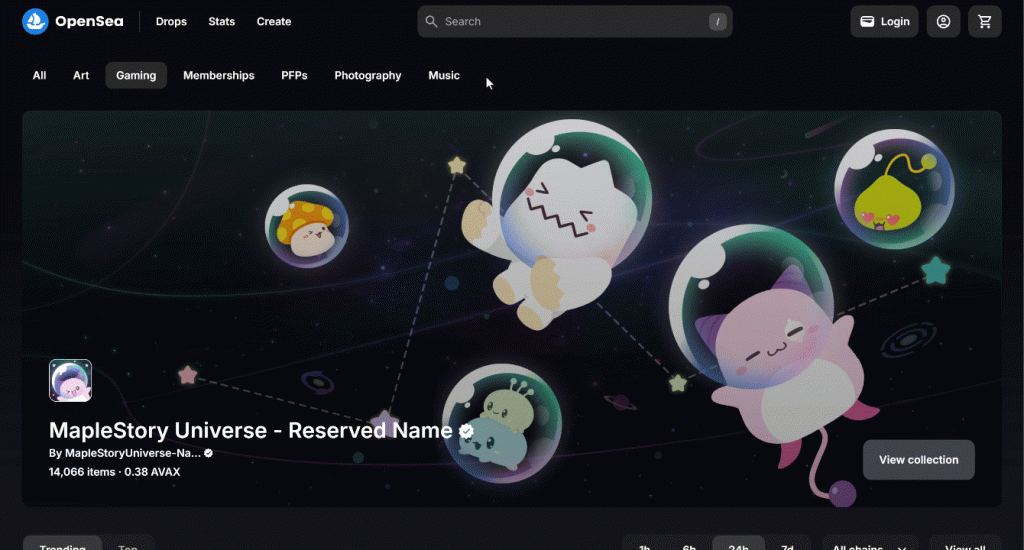
首先,右键单击 “Top” 按钮并选择 “Inspect”,以查看它的 HTML 结构:
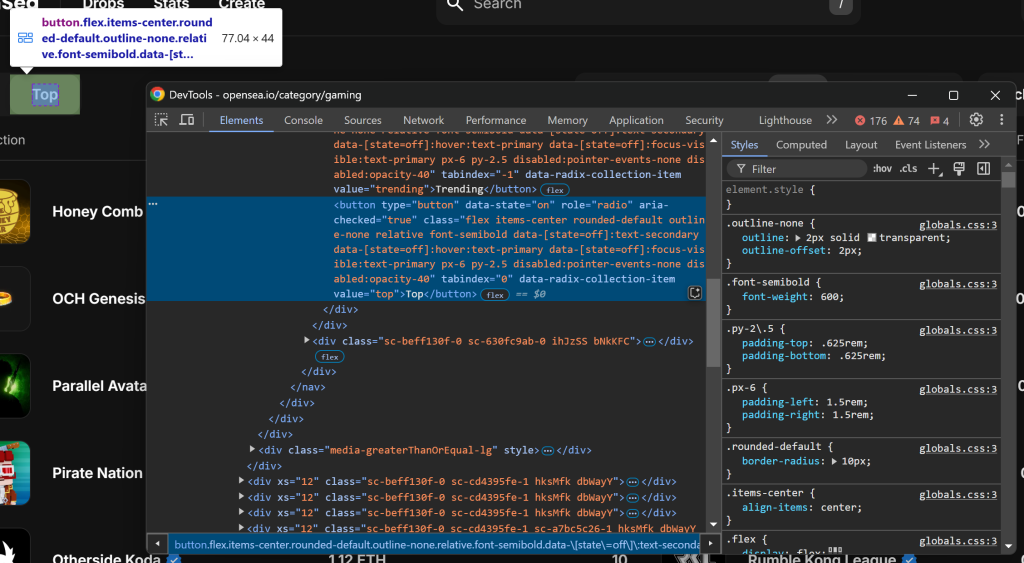
可以通过 [value="top"] 的 CSS 选择器来定位它。然后使用 Selenium 提供的 find_element() 方法,并调用 click():
top_element = driver.find_element(By.CSS_SELECTOR, "[value=\"top\"]")
top_element.click()要使上述代码正常工作,别忘了先导入 By:
from selenium.webdriver.common.by import By很好!这几行代码就可以模拟所需的交互。
步骤 #6:准备爬取 NFT 系列
目标页面会在所选类别下显示排名前 10 的 NFT 系列。因为这是一个列表,所以先创建一个空数组来存储爬取到的信息:
nft_collections = []然后,检查单个 NFT 系列条目的 HTML 结构:
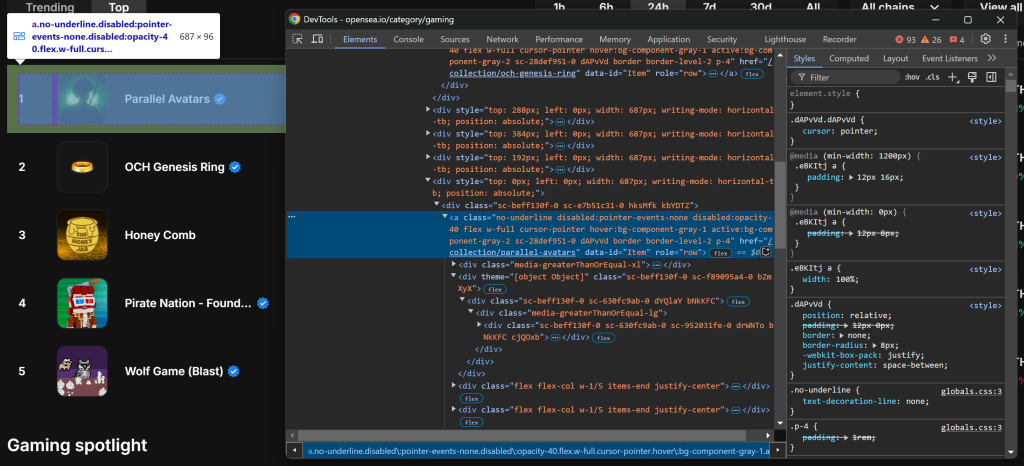
您可以通过使用 a[data-id="Item"] 的 CSS 选择器来选中所有的 NFT 系列条目。因为在元素的类名中有些看起来是随机生成的,所以尽量避免直接依赖它们。相反,可以利用 data-* 属性,因为它们通常用于测试并且具有较好的稳定性。
使用 find_elements() 来获取所有的 NFT 系列条目:
item_elements = driver.find_elements(By.CSS_SELECTOR, "a[data-id=\"Item\"]")然后,遍历这些元素,为每个元素编写数据提取逻辑:
for item_element in item_elements:
# Scraping logic...很好!您已经准备好开始从 OpenSea 的 NFT 元素中提取数据了。
步骤 #7:爬取 NFT 系列元素
先查看单个 NFT 系列条目:
.png)
HTML 结构相对复杂,但可以提取以下信息:
- 通过
img[alt="Collection Image"]获取系列图片 - 通过
[data-id="TextBody"]获取系列排名 - 通过
[tabindex="-1"]获取系列名称
这些元素并没有独特或稳定的属性,所以需要依靠可能不那么稳固的选择器。先实现这三个属性的爬取逻辑:
image_element = item_element.find_element(By.CSS_SELECTOR, "img[alt=\"Collection Image\"]")
image = image_element.get_attribute("src")
rank_element = item_element.find_element(By.CSS_SELECTOR, "[data-id=\"TextBody\"]")
rank = int(rank_element.text)
name_element = item_element.find_element(By.CSS_SELECTOR, "[tabindex=\"-1\"]")
name = name_element.text.text 属性可以获取所选元素的文本内容。由于 rank 之后需要用于排序,因此先将其转换为整数。而 .get_attribute("src") 会获取 src 属性的值,从而提取图片 URL。
接下来,关注 .w-1/5 列:
.png)
数据结构如下:
- 第一个
.w-1/5列包含地板价。 - 第二个
.w-1/5列包含交易量和百分比变化,它们位于不同的元素中。
使用下面的逻辑来提取这些值:
floor_price_element = item_element.find_element(By.CSS_SELECTOR, ".w-1\\/5")
floor_price = floor_price_element.text
volume_column = item_element.find_elements(By.CSS_SELECTOR, ".w-1\\/5")[1]
volume_element = volume_column.find_element(By.CSS_SELECTOR, "[tabindex=\"-1\"]")
volume = volume_element.text
percentage_element = volume_column.find_element(By.CSS_SELECTOR, ".leading-sm")
percentage = percentage_element.text 请注意,无法直接使用 .w-1/5,而需要将 / 转义为 \\/。
就是这样!用于获取 NFT 系列的 OpenSea 爬取逻辑已经完成。
步骤 #8:收集爬取到的数据
目前,从每个条目中获取的数据分布在若干变量中。可以将它们组合到一个新的 nft_collection 对象中:
nft_collection = {
"rank": rank,
"image": image,
"name": name,
"floor_price": floor_price,
"volume": volume,
"percentage": percentage
}然后别忘了将其添加到 nft_collections 列表中:
nft_collections.append(nft_collection)在 for 循环外,对爬取到的数据进行升序排序:
nft_collections.sort(key=lambda x: x["rank"])非常好!现在只剩下将这些信息导出到更加易读的文件格式,例如 CSV。
步骤 #9:将爬取到的数据导出到 CSV
Python 原生支持导出 CSV 等格式。可以通过以下代码实现:
csv_filename = "nft_collections.csv"
with open(csv_filename, mode="w", newline="", encoding="utf-8") as file:
writer = csv.DictWriter(file, fieldnames=nft_collections[0].keys())
writer.writeheader()
writer.writerows(nft_collections)此代码片段会将 nft_collections 列表中的数据导出到名为 nft_collections.csv 的文件中。它使用 Python 的 csv 模块来创建一个 writer 对象,并以结构化的格式写入数据。每条记录都以一行的形式存储,列标题对应 nft_collections 列表中字典的键。
在此之前,先导入 Python 标准库中的 csv:
imprort csv步骤 #10:整合所有内容
以下是您最终的 OpenSea 爬虫代码:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
import csv
# Create a Chrome web driver instance
driver = webdriver.Chrome(service=Service())
# To avoid the responsive rendering
driver.maximize_window()
# Visit the target page
driver.get("https://opensea.io/category/gaming")
# Select the "Top" NFTs
top_element = driver.find_element(By.CSS_SELECTOR, "[value=\"top\"]")
top_element.click()
# Where to store the scraped data
nft_collections = []
# Select all NFT collection HTML elements
item_elements = driver.find_elements(By.CSS_SELECTOR, "a[data-id=\"Item\"]")
# Iterate over them and scrape data from them
for item_element in item_elements:
# Scraping logic
image_element = item_element.find_element(By.CSS_SELECTOR, "img[alt=\"Collection Image\"]")
image = image_element.get_attribute("src")
rank_element = item_element.find_element(By.CSS_SELECTOR, "[data-id=\"TextBody\"]")
rank = int(rank_element.text)
name_element = item_element.find_element(By.CSS_SELECTOR, "[tabindex=\"-1\"]")
name = name_element.text
floor_price_element = item_element.find_element(By.CSS_SELECTOR, ".w-1\\/5")
floor_price = floor_price_element.text
volume_column = item_element.find_elements(By.CSS_SELECTOR, ".w-1\\/5")[1]
volume_element = volume_column.find_element(By.CSS_SELECTOR, "[tabindex=\"-1\"]")
volume = volume_element.text
percentage_element = volume_column.find_element(By.CSS_SELECTOR, ".leading-sm")
percentage = percentage_element.text
# Populate a new NFT collection object with the scraped data
nft_collection = {
"rank": rank,
"image": image,
"name": name,
"floor_price": floor_price,
"volume": volume,
"percentage": percentage
}
# Add it to the list
nft_collections.append(nft_collection)
# Sort the collections by rank in ascending order
nft_collections.sort(key=lambda x: x["rank"])
# Save to CSV
csv_filename = "nft_collections.csv"
with open(csv_filename, mode="w", newline="", encoding="utf-8") as file:
writer = csv.DictWriter(file, fieldnames=nft_collections[0].keys())
writer.writeheader()
writer.writerows(nft_collections)
# close the browser and release its resources
driver.quit()看吧!不足 100 行的代码已经足以打造一个简单的 Python OpenSea 爬虫脚本。
在终端中使用以下命令来运行它:
python scraper.py过一会儿,您就会在项目文件夹中看到名为 nft_collections.csv 的文件:
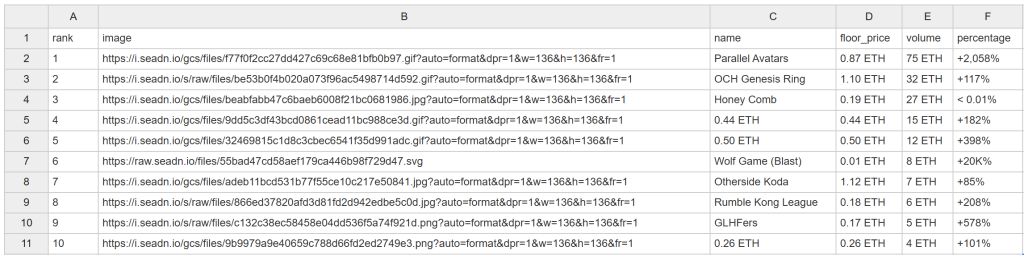
恭喜!您已经如愿以偿地完成了 OpenSea 的爬取。
轻松获取 OpenSea 数据
OpenSea 提供的内容远不止 NFT 系列排名。它还为每个 NFT 系列和其中的单个项目提供了详细页面。由于 NFT 价格经常波动,您的爬虫脚本需要频繁自动运行,以获取最新数据。然而,大多数 OpenSea 页面都采用了严格的 反爬虫措施,这使得数据抓取变得困难。
正如我们之前看到的,使用无头浏览器行不通,这意味着您不得不在浏览器界面打开的情况下持续消耗资源。而且,在尝试与页面上的其他元素交互时,您可能会遇到问题:
例如,数据加载可能会卡住,浏览器中的 AJAX 请求可能被屏蔽,从而导致 403 Forbidden 错误:
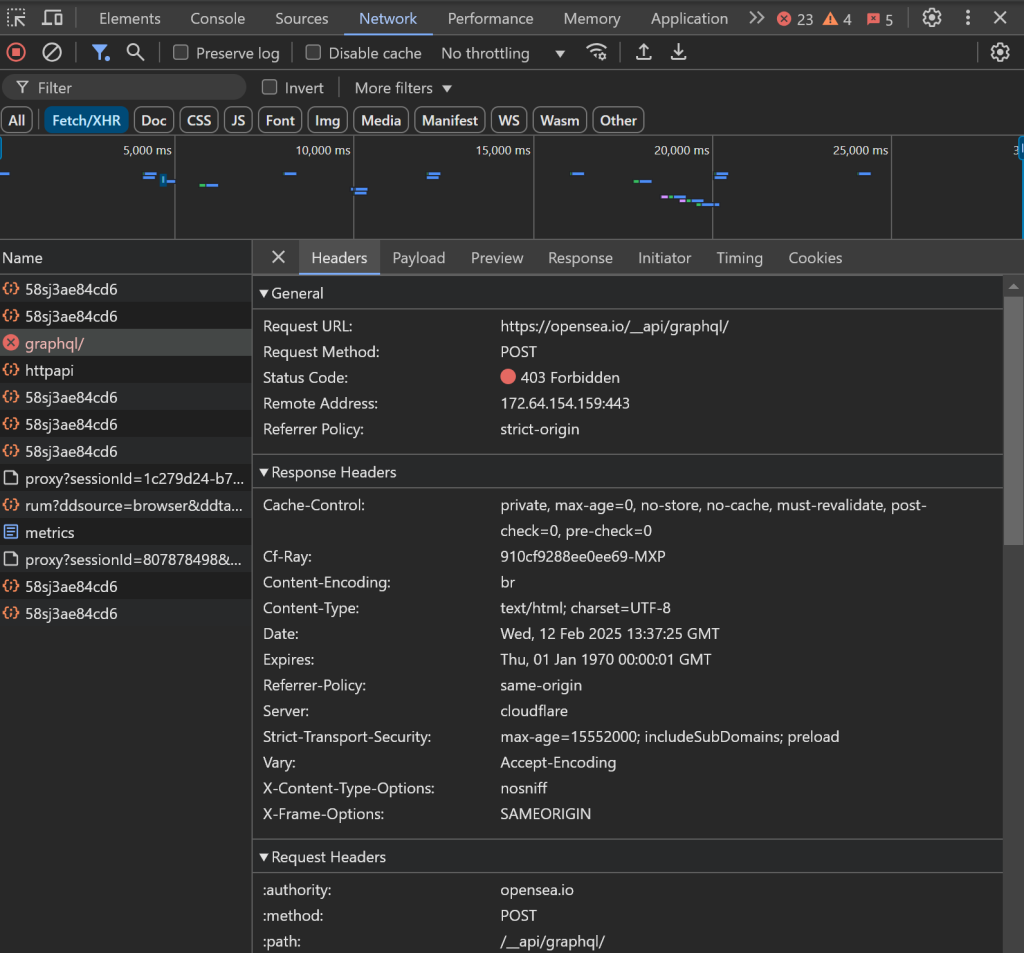
这是因为 OpenSea 拥有高级的反爬虫措施,可以阻止 爬虫机器人。
这些问题让没有正确工具的情况下去爬取 OpenSea 显得十分力不从心。而解决之道是:使用 Bright Data 的 OpenSea Scraper 专用方案,通过简单的 API 调用或无代码方式获取网站数据,并且不会被阻止!
结语
在这个分步教程中,您了解了什么是 OpenSea 爬虫,以及它能收集的各种数据类型。您还用不到 100 行代码完成了一个 Python 脚本来爬取 OpenSea 的 NFT 数据。
真正的挑战在于 OpenSea 的严格反爬虫措施,它可以阻止自动化浏览器的正常访问。我们提供的 OpenSea Scraper 可以通过 API 或无代码方式方便地获取公共 NFT 数据,包括名称、描述、Token ID、当前价格、最近成交价、历史记录、报价等等。
马上注册一个免费的 Bright Data 账号,启动我们的 Scraper API 吧!


