

Etsy 是一个出了名难以爬取的网站。它们采用多种阻止策略,并拥有当今网络上最复杂的机器人拦截系统之一。从详细的请求头分析,到源源不断的验证码(CAPTCHA),Etsy 成为了全世界所有爬虫的噩梦。但一旦你能突破这些障碍,Etsy 的爬取反而会变得相对简单。
如果你能够成功爬取 Etsy,你就能获取到这个互联网庞大商城中极其丰富的小型商业数据。按照下面的步骤,你很快就能熟练地爬取 Etsy。我们将学习如何爬取 Etsy 以下类型的页面。
- 搜索结果
- 产品页面
- 店铺页面
开始上手
Python Requests 和 BeautifulSoup 将会是这篇教程中的主要工具。你可以使用以下命令来安装它们。Requests 可以让我们发送 HTTP 请求并与 Etsy 的服务器进行通信,BeautifulSoup 则能够帮助我们使用 Python 来解析网页。我们建议你在此之前先阅读一下我们关于 如何使用 BeautifulSoup 进行网页爬取 的指南。
安装 Requests
pip install requests安装 BeautifulSoup
pip install beautifulsoup4可以从 Etsy 上爬取哪些数据
如果你查看 Etsy 的页面结构,你可能会发现它有一堆嵌套的元素,看起来很混乱,不过只要知道去哪里找,问题就能迎刃而解。Etsy 的页面使用了 JSON 数据 来在浏览器中渲染页面。 如果你能找到这些 JSON 数据,就能获得它们用来构建页面的所有信息,而无需过于深入地研究文档中的 HTML。
搜索结果
Etsy 的搜索页面里包含多个 JSON 对象。如下图所示,所有这些数据都在一个 script 元素内,且带有 type="application/ld+json" 属性。如果仔细观察,这些 JSON 数据中包含一个名为 itemListElement 的数组。只要我们能将这个数组提取出来,我们就能拿到用于构建页面的所有数据。
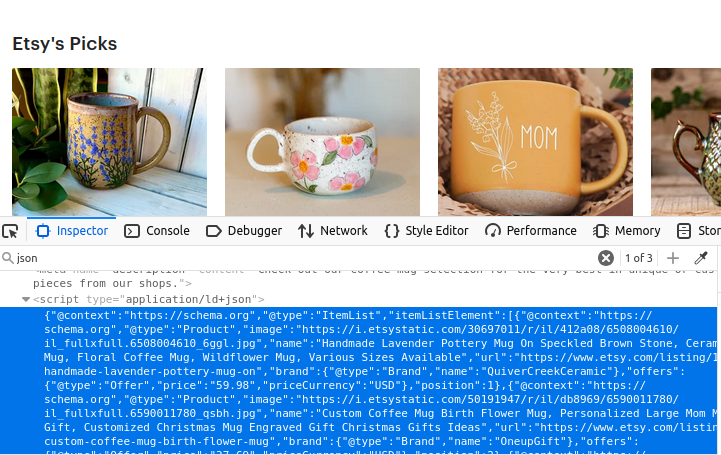
产品信息
它的产品页面与上述情况并没有太大差别。如下图所示,我们依旧能看到一个带有 type="application/ld+json" 属性的 script 标签,其中包含了用来构建产品页面的全部信息。
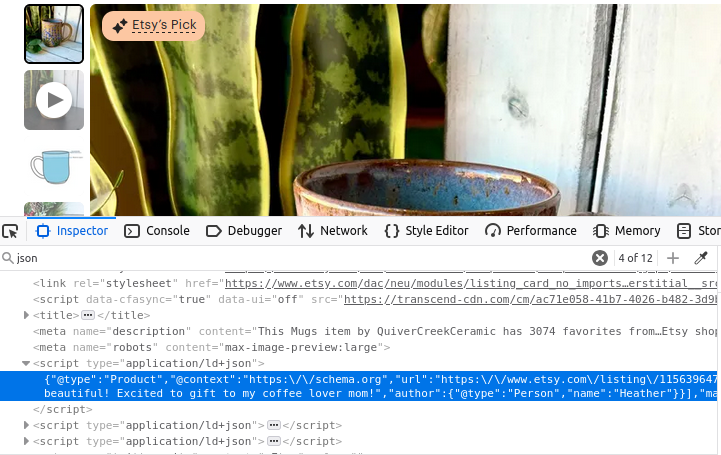
店铺
你大概已经猜到了,店铺页面也采用同样的方式。找到页面上第一个带有 type="application/ld+json" 的 script 元素,你就能拿到你所需的数据。
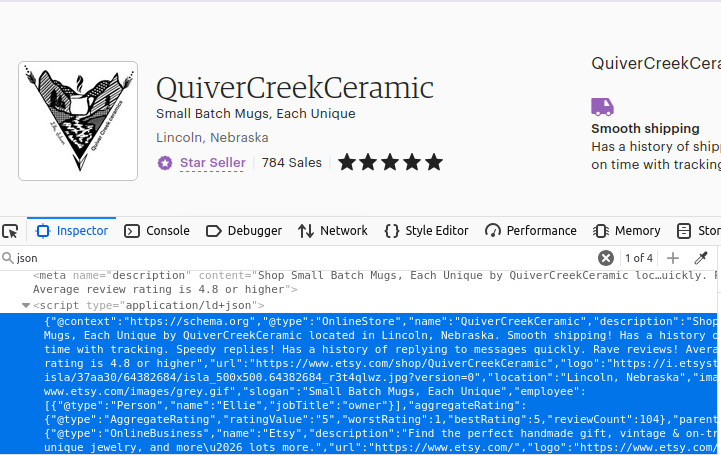
如何使用 Python 来爬取 Etsy
下面我们会介绍如何搭建所需的全部模块。正如之前提到过的,Etsy 使用多种方式来阻止我们访问该站点。我们使用 Web Unlocker 作为应对这些拦截的瑞士军刀。它不仅能帮助管理代理连接,还能替我们自动处理出现的验证码(CAPTCHA)。 你当然可以尝试在没有代理的情况下进行,但在我们最初的测试中,我们无法在没有 Web Unlocker 的帮助下突破 Etsy 的封锁。
一旦你拥有了一个 Web Unlocker 实例,就可以通过创建一个简单的 dict 来设置代理。我们使用 Bright Data 的 SSL 证书来加密传输过程中的数据。下面的示例代码中,我们设置了 SSL 证书 的路径,并使用用户名、区域(zone)和密码来构建代理 URL。我们的代理是通过定制的 URL 来将所有请求转发到 Bright Data 的代理服务 之一。
path_to_cert = "bright-data-cert.crt"
proxies = {
'http': 'http://brd-customer-<YOUR-USERNAME>-zone-<YOUR-ZONE-NAME>:<YOUR-PASSWORD>@brd.superproxy.io:33335',
'https': 'http://brd-customer-<YOUR-USERNAME>-zone-<YOUR-ZONE-NAME>:<YOUR-PASSWORD>@brd.superproxy.io:33335'
}搜索结果
要获取搜索结果,我们通过代理发送请求,然后用 BeautifulSoup 来解析返回的 HTML 文档。我们在 script 标签里找到所需的数据,并将其当作 JSON 对象加载。然后,从该 JSON 中返回 itemListElement 字段。
def etsy_search(keyword):
encoded_keyword = urlencode({"q": keyword})
url = f"https://www.etsy.com/search?{encoded_keyword}"
response = requests.get(url, proxies=proxies, verify=path_to_cert)
soup = BeautifulSoup(response.text, "html.parser")
script = soup.find("script", attrs={"type": "application/ld+json"})
full_json = json.loads(script.text)
return full_json["itemListElement"]产品信息
提取产品信息的方式几乎相同。唯一的区别在于,这里没有 itemListElement。我们用 listing_id 来生成目标 URL,然后提取整个 JSON 对象。
def etsy_product(listing_id):
url = f"https://www.etsy.com/listing/{listing_id}/"
response = requests.get(url, proxies=proxies, verify=path_to_cert)
soup = BeautifulSoup(response.text, "html.parser")
script = soup.find("script", attrs={"type": "application/ld+json"})
return json.loads(script.text)店铺
店铺的提取方式与产品页面的逻辑相同。我们使用 shop_name 来构造 URL,获取响应后,同样找到 JSON,加载为 JSON,并返回页面数据。
def etsy_shop(shop_name):
url = f"https://www.etsy.com/shop/{shop_name}"
response = requests.get(url, proxies=proxies, verify=path_to_cert)
soup = BeautifulSoup(response.text, "html.parser")
script = soup.find("script", attrs={"type": "application/ld+json"})
return json.loads(script.text)数据存储
刚提取出来的数据已经是结构化的 JSON。我们可以通过 Python 的基础文件操作和 json.dumps() 来将其写入文件。设置 indent=4,能够让文件在供人阅读时更加美观。
with open("products.json", "w") as file:
json.dump(products, file, indent=4)整合所有功能
现在我们已经知道怎样构建所有必要的组件。下面的代码会使用我们刚才编写的函数,并返回我们需要的 JSON 格式数据。随后,我们将每个对象写入各自的 JSON 文件中。
import requests
import json
from bs4 import BeautifulSoup
from urllib.parse import urlencode
# Proxy and certificate setup (HARD-CODED CREDENTIALS)
path_to_cert = "bright-data-cert.crt"
proxies = {
'http': 'http://brd-customer-<YOUR-USERNAME>-zone-<YOUR-ZONE-NAME>:<YOUR-PASSWORD>@brd.superproxy.io:22225',
'https': 'http://brd-customer-<YOUR-USERNAME>-zone-<YOUR-ZONE-NAME>:<YOUR-PASSWORD>@brd.superproxy.io:22225'
}
def fetch_etsy_data(url):
"""Fetch and parse JSON-LD data from an Etsy page."""
try:
response = requests.get(url, proxies=proxies, verify=path_to_cert)
response.raise_for_status()
except requests.exceptions.RequestException as e:
print(f"Request failed: {e}")
return None
soup = BeautifulSoup(response.text, "html.parser")
script = soup.find("script", attrs={"type": "application/ld+json"})
if not script:
print("JSON-LD script not found on the page.")
return None
try:
return json.loads(script.text)
except json.JSONDecodeError as e:
print(f"JSON parsing error: {e}")
return None
def etsy_search(keyword):
"""Search Etsy for a given keyword and return results."""
encoded_keyword = urlencode({"q": keyword})
url = f"https://www.etsy.com/search?{encoded_keyword}"
data = fetch_etsy_data(url)
return data.get("itemListElement", []) if data else None
def etsy_product(listing_id):
"""Fetch product details from an Etsy listing."""
url = f"https://www.etsy.com/listing/{listing_id}/"
return fetch_etsy_data(url)
def etsy_shop(shop_name):
"""Fetch shop details from an Etsy shop page."""
url = f"https://www.etsy.com/shop/{shop_name}"
return fetch_etsy_data(url)
def save_to_json(data, filename):
"""Save data to a JSON file with error handling."""
try:
with open(filename, "w", encoding="utf-8") as file:
json.dump(data, file, indent=4, ensure_ascii=False, default=str)
print(f"Data successfully saved to {filename}")
except (IOError, TypeError) as e:
print(f"Error saving data to {filename}: {e}")
if __name__ == "__main__":
# Product search
products = etsy_search("coffee mug")
if products:
save_to_json(products, "products.json")
# Specific item
item_info = etsy_product(1156396477)
if item_info:
save_to_json(item_info, "item.json")
# Etsy shop
shop = etsy_shop("QuiverCreekCeramic")
if shop:
save_to_json(shop, "shop.json")下面是 products.json 的一些示例数据。
{
"@context": "https://schema.org",
"@type": "Product",
"image": "https://i.etsystatic.com/34923795/r/il/8f3bba/5855230678/il_fullxfull.5855230678_n9el.jpg",
"name": "Custom Coffee Mug with Photo, Personalized Picture Coffee Cup, Anniversary Mug Gift for Him / Her, Customizable Logo-Text Mug to Men-Women",
"url": "https://www.etsy.com/listing/1193808036/custom-coffee-mug-with-photo",
"brand": {
"@type": "Brand",
"name": "TheGiftBucks"
},
"offers": {
"@type": "Offer",
"price": "14.99",
"priceCurrency": "USD"
},
"position": 1
},考虑使用数据集
我们的 datasets(数据集) 提供了一个替代自建爬虫的好方法。你可以直接购买 现成的 Etsy 数据集 或者其他 电商类数据集,从而完全摆脱自己爬虫的过程!只要你拥有一个账号,就可以前往我们的数据集市场。
在搜索框中输入 “Etsy”,然后点击 Etsy 数据集。

这样你就可以直接获取数百万条来自 Etsy 的数据……随时可用。你甚至可以下载样本数据来体验一下。
总结
在本教程中,我们详细探讨了如何爬取 Etsy。你学会了如何集成代理来突破限制,并且学习了如何使用 Web Unlocker 来对付最严格的机器人拦截。你知道了如何提取需要的数据,也掌握了如何进行存储。你还了解了 我们预制的数据集,从而无需自己爬取数据。不管你想如何获取数据,我们都能为你提供帮助。
立即注册并开始免费试用吧。



技术写作者
 6 years experience
6 years experience
Jacob Nulty 是一位常驻底特律的软件开发者和技术写作者,探索人工智能与人类哲学,具备 Python、Rust 和区块链方面的经验。



