

在本指南中,您将学习以下内容:
- 什么是 AliExpress 爬虫以及它的工作原理
- 可以从 AliExpress 自动获取哪些类型的数据
- 如何使用 Python 来构建一个 AliExpress 爬虫脚本
让我们开始吧!
什么是 AliExpress 爬虫?
AliExpress 爬虫会自动从 AliExpress 页面获取指定数据。它通过模拟用户浏览的方式来访问并解析 AliExpress 页面,将网页内容转换成可使用的格式(如 CSV 或 JSON),并控制翻页等交互操作。它的最终目的是提取结构化信息,例如产品图片、产品详情、用户评价、价格等等。
如果您想深入了解如何构建网络爬虫,请阅读我们的 如何构建一个爬虫机器人指南。
可从 AliExpress 抓取的数据:分步指南
AliExpress 上包含了大量信息,例如:
- 产品详情:名称、描述、图片、价格范围、卖家信息等。
- 用户评价:评分、产品评论等。
- 分类和标签:产品类目、相关标签或标记。
现在让我们学习如何抓取这些数据吧!
在 Python 中爬取 AliExpress
本教程将手把手指导如何构建一个爬取 AliExpress 的脚本。
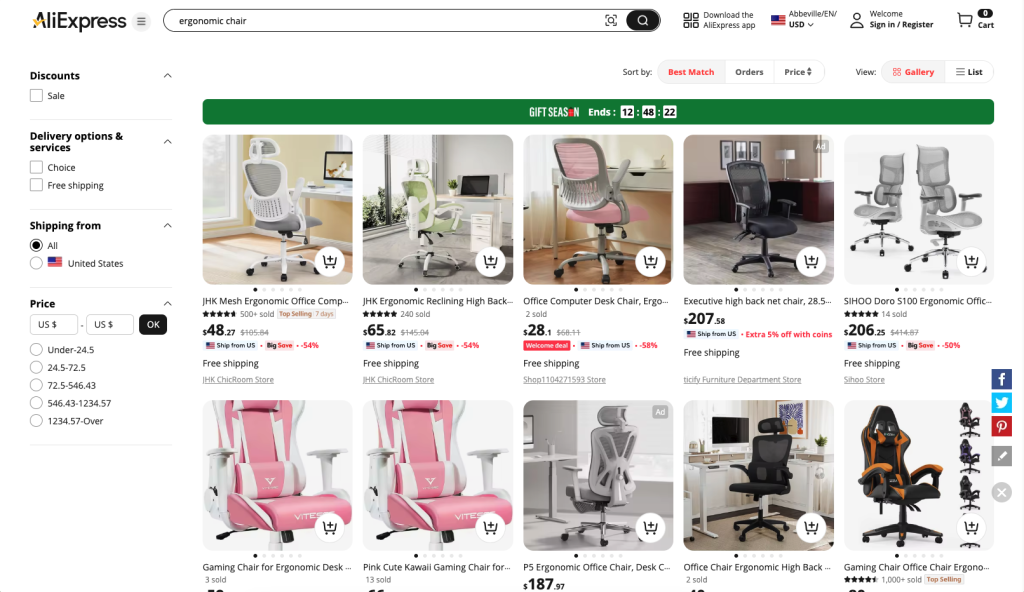
我们的目标是带您完成一个能自动从 AliExpress “ergonomic chair” 页面获取信息的 Python 脚本:
步骤 #1:项目初始化
首先,请确保您的本地计算机安装了 Python 3。如果还未安装,可从 Python 官方文档下载并按照安装向导进行配置。
然后,使用下面的命令在您的终端中创建一个项目目录:
mkdir aliexpress-scraper该目录将用于存放您的 Python 代码。
在终端中进入该目录,并在其中创建一个 虚拟环境:
cd aliexpress-scraper
python -m venv env接下来,使用您喜欢的 Python IDE(例如 带有 Python 插件的 Visual Studio Code)打开该项目文件夹。
在 IDE 的终端中,激活这个虚拟环境。如果您使用的是 macOS 或 Linux,执行以下命令:
.env/bin/activate在 Windows 上,则执行:
env/Scripts/activate很好!
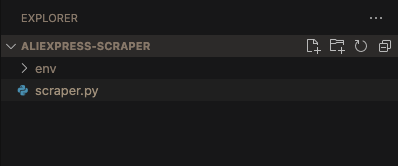
在项目根目录下,创建一个名为 scraper.py 的文件。此时,您的项目文件夹结构应如下所示:
完美!您的 AliExpress 爬虫 Python 环境已经就绪。
步骤 #2:选择爬虫库
当前的目标是判断 AliExpress 使用的是动态页面还是静态页面。请在浏览器的隐私模式或无痕模式下打开目标 AliExpress 页面,然后在页面空白处右键选择“Inspect(检查)”,在弹出的开发者工具中选择“Network”选项卡,应用“Fetch/XHR”过滤器,并刷新该页面:
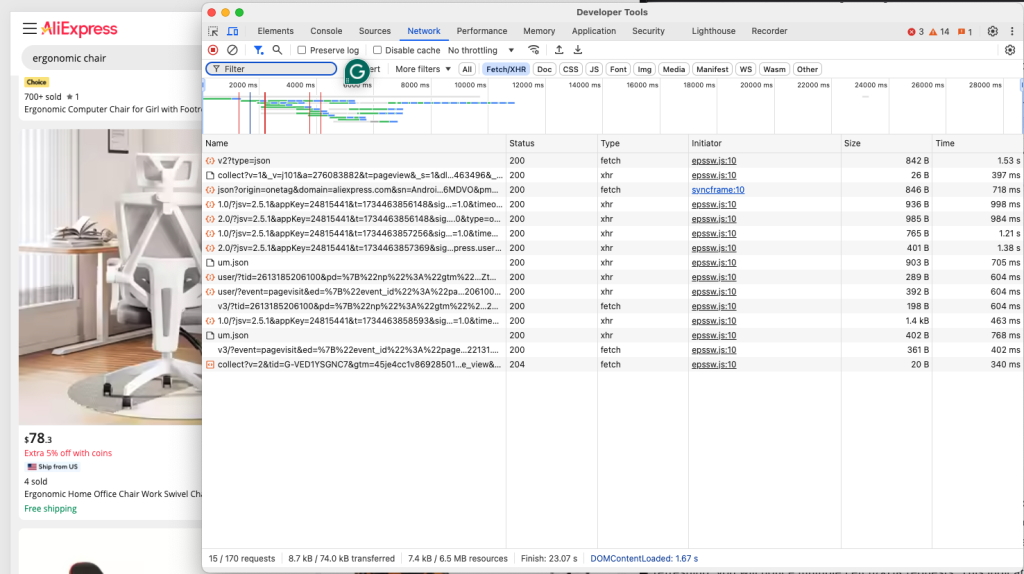
在 DevTools 中查看页面是否发送了任何动态请求。刷新后,您会注意到多个 Fetch/XHR 请求,这表明该页面通过动态请求来加载额外的内容。如果比较页面的 DOM 和服务器返回的 HTML,您还会发现 AliExpress 使用了 JavaScript 来进行渲染。
要有效爬取 AliExpress,您需要使用像 Selenium这样的浏览器自动化工具,因为目标页面依赖 JavaScript 渲染。对于初学者,我们的 Selenium 爬虫教程是一个不错的起点。
通过 Selenium,您可以操作浏览器、模拟用户交互,从而爬取动态渲染内容。安装并开始使用它吧!
步骤 #3:安装并配置 Selenium
在已经激活的虚拟环境中,使用以下命令安装 Selenium:
pip install -U selenium接着,在 scraper.py 文件中从 Selenium 导入 WebDriver 并进行初始化。
from selenium import webdriver
# Initialize Chrome driver
driver = webdriver.Chrome()
# scraping logic...
# Close the driver
driver.quit()上面的代码使用 WebDriver 初始化了一个 Chrome 实例。值得注意的是,AliExpress 具备反爬措施,可能会阻止无头(headless)浏览器访问其网站。
因此,不建议设置 --headless 标志。您可以考虑采用其他方式,比如 Playwright Stealth。
完成上述配置后,您就可以正式开始爬取 AliExpress 了。接下来让我们看看如何连接到目标页面。
步骤 #4:连接到目标页面
通过 Selenium WebDriver 对象提供的 get() 方法来访问目标页面。此时,您的 scraper.py 文件应如下所示:
from selenium import webdriver
# Initialize Chrome driver
driver = webdriver.Chrome()
# Url of the target page
url = "https://www.aliexpress.com/w/wholesale-ergonomic-chair.html?spm=a2g0o.productlist.search.0"
# Connect to the target page
driver.get(url)
# scraping logic...
# Close the driver
driver.quit()在最后一行处下一个调试断点并启动脚本进行调试。此时,您应看到由脚本自动打开的 Chrome 浏览器,如下图所示:
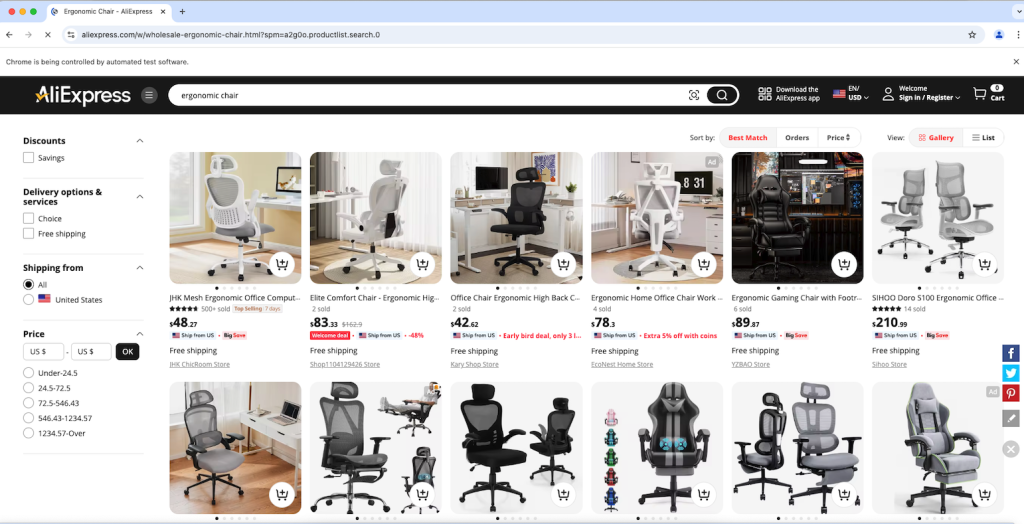
很好!出现“Chrome 正在受到自动测试软件控制”的提示,证明 Selenium 已成功控制了 Chrome。
步骤 #5:选择产品元素
由于 AliExpress 产品页面中包含多个产品卡片,首先需要初始化一个数据结构来存储爬取的数据。这里使用数组(列表)就足够了:
products = []为了在网站布局变动时维持爬虫的适用性,您可以定义一个辅助函数,让选择器在发生变化时有更大的容错空间:
def find_element_smart(parent, by_list):
"""Try multiple selectors until an element is found"""
for by_type, selector in by_list:
try:
element = parent.find_element(by_type, selector)
if element.is_displayed():
return element
except:
continue
return None上述 find_element_smart() 函数会遍历 by_list 中的一系列 (by_type, selector),尝试从指定父级元素 parent 中查找符合条件且可见的元素,一旦找到就返回。如果所有选择器都无法命中,则返回 None。
接下来,检查页面上产品卡片的 HTML 结构,了解如何识别并提取它们所包含的数据:
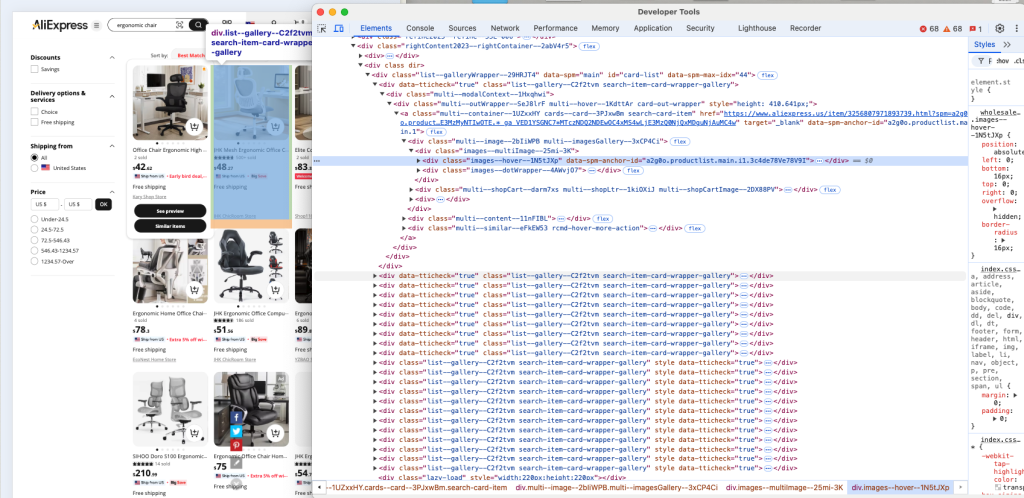
可以看到,每个产品卡片元素都是一个名为 .list--gallery--C2f2tvm 的节点。
要注意的是,由于 list--gallery--C2f2tvm 里包含随机生成的字符串,该类名随时可能变动。因此不宜直接依赖它来选择元素,更好的做法是优先基于结构(例如包含 img 和 a 的 div)或基于页面内容特征来查找。
实现选择产品卡片的逻辑示例:
# Find products using structural patterns first, then fallback to class patterns
product_selectors = [
(By.XPATH, "//div[.//img and .//a[contains(@href, 'item')]]"),
(By.XPATH, "//div[.//img and .//*[contains(text(), '$')]]"),
(By.CSS_SELECTOR, "div[class*='gallery']")
]
# Wait for and get products
wait.until(EC.presence_of_all_elements_located((By.CSS_SELECTOR, "div[class*='gallery']")))
products_found = []
for selector_type, selector in product_selectors:
try:
elements = wait.until(EC.presence_of_all_elements_located((selector_type, selector)))
if elements:
products_found = elements
break
except:
continue以上代码使用选择器策略,通过通用的CSS 选择器检索页面上的元素。
别忘了在您的 Python 脚本里增加如下导入:
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait然后,在初始化 WebDriver 之后、任意页面操作之前,创建一个 WebDriverWait 实例:
wait = WebDriverWait(driver, 20)与其在抓取像速卖通这类动态网站时立即在页面上查找元素,WebDriverWait 会告知抓取器保持耐心,可最多等待指定时长(本例中为 20 秒)来等待元素出现。这非常重要,因为网页加载元素的速度各不相同,如果没有适当的等待,抓取器可能会尝试访问尚未加载的元素,从而导致错误。
您离完整地爬取 AliExpress 又近一步了!
步骤 #6:爬取 AliExpress 产品元素
再次右键检视某个产品元素,以了解它的 HTML 结构:
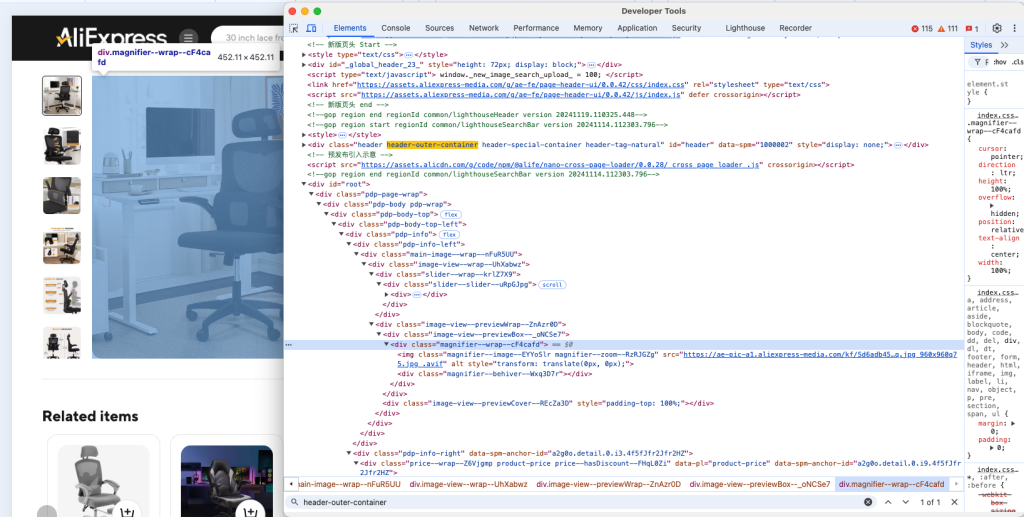
可以看到,您能够抓取该产品的图片、URL、名称或标题、价格以及折扣等数据。
在尝试爬取每个产品之前,可以先确认它是否在可视区域可见:
wait.until(EC.visibility_of(product))然后,使用模式化的方式去获取产品的具体信息,而不是直接依赖特定类名:
# Get image - look for product images by source patterns
img_element = find_element_smart(product, [
(By.XPATH, ".//img[contains(@src, 'item') or contains(@src, 'product')]"),
(By.CSS_SELECTOR, "img[src*='item']"),
(By.CSS_SELECTOR, "img[class*='image']")
])
# Get URL - look for product links
url_element = find_element_smart(product, [
(By.CSS_SELECTOR, "a[href*='item']"),
(By.XPATH, ".//a[contains(@href, 'product')]")
])
# Get title - look for longest text element first
price_element = find_element_smart(product, [
(By.CSS_SELECTOR, "*[class*='price-sale']"),
(By.CSS_SELECTOR, "*[class*='price']"),
(By.XPATH, ".//*[contains(@class, 'price')]")
])
# Get price - look for currency symbols/patterns
price_element = find_element_smart(product, [
(By.XPATH, ".//*[contains(text(), '$') or contains(text(), 'US') or contains(text(), 'GHS')]"),
(By.XPATH, ".//*[contains(@class, 'price')]")
])
# Try to get discount if available
discount_element = find_element_smart(product, [
(By.XPATH, ".//*[contains(text(), '%') or contains(text(), 'OFF')]"),
(By.CSS_SELECTOR, "[class*='discount']")
])find_element() 会返回第一个匹配指定 CSS 选择器的元素,然后您可以通过 text 获取其文本内容。
将获取到的数据存入列表 products 中,并将其封装为字典:
products.append({
"image_url": img_element.get_attribute("src"),
"product_url": url_element.get_attribute("href"),
"product_title": title_element.text.strip(),
"product_price": price_element.text.strip(),
"product_discount": discount_element.text.strip() if discount_element else "N/A"
})现在,数据提取逻辑已经完成并可以投入实际使用了。
步骤 #7:将爬取结果导出为 CSV
目前,提取到的数据都存在了 products 列表中。为了便于分享和查看,最好将其输出到更易读的格式,例如 CSV 文件。以下是创建并写入 CSV 文件的示例:
# Write data to CSV
csv_file_name = "aliexpress_products.csv"
with open(csv_file_name, mode="w", newline="", encoding="utf-8") as csv_file:
fieldnames = ["image_url", "product_url", "product_title", "product_price", "product_discount"]
writer = csv.DictWriter(csv_file, fieldnames=fieldnames)
writer.writeheader()
for product in products:
writer.writerow(product)这段代码将生成一个 CSV 文件,每个产品对应一行,产品图片、URL、标题、价格以及折扣信息等分别占据不同的列。当您打开最终生成的 aliexpress_products.csv 文件时,就能看到所有从 AliExpress 抓取下来的产品数据。
最后,在 Python 标准库中引入 csv 包:
import csv步骤 #8:整合所有代码
以下是将所有示例代码整合后的完整脚本:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import csv
def find_element_smart(parent, by_list):
"""Try multiple selectors until an element is found"""
for by_type, selector in by_list:
try:
element = parent.find_element(by_type, selector)
if element.is_displayed():
return element
except:
continue
return None
# Initialize driver
driver = webdriver.Chrome()
wait = WebDriverWait(driver, 20)
# Target URL
url = "https://www.aliexpress.com/w/wholesale-ergonomic-chair.html?spm=a2g0o.productlist.search.0"
driver.get(url)
# Wait for initial products to load
wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, "div[class*='gallery']")))
# Where to store the scraped data
products = []
# Find products using patterns first, then fallback to class patterns
product_selectors = [
(By.XPATH, "//div[.//img and .//a[contains(@href, 'item')]]"),
(By.XPATH, "//div[.//img and .//*[contains(text(), '$')]]"),
(By.CSS_SELECTOR, "div[class*='gallery']")
]
# Wait for and get products
wait.until(EC.presence_of_all_elements_located((By.CSS_SELECTOR, "div[class*='gallery']")))
products_found = []
for selector_type, selector in product_selectors:
try:
elements = wait.until(EC.presence_of_all_elements_located((selector_type, selector)))
if elements:
products_found = elements
break
except:
continue
# Iterate over the product found and scrape data from them
for product in products_found:
# Wait for product to be visible and interactable
wait.until(EC.visibility_of(product))
# Get image - look for product images by source patterns
img_element = find_element_smart(product, [
(By.XPATH, ".//img[contains(@src, 'item') or contains(@src, 'product')]"),
(By.CSS_SELECTOR, "img[src*='item']"),
(By.CSS_SELECTOR, "img[class*='image']")
])
# Get URL - look for product links
url_element = find_element_smart(product, [
(By.CSS_SELECTOR, "a[href*='item']"),
(By.XPATH, ".//a[contains(@href, 'product')]")
])
# Get title - look for longest text element first
title_element = find_element_smart(product, [
(By.XPATH, ".//div[string-length(text()) > 20]"),
(By.XPATH, ".//*[contains(@class, 'title')]"),
(By.CSS_SELECTOR, "[class*='name']")
])
# Get price
price_element = find_element_smart(product, [
(By.CSS_SELECTOR, "*[class*='price-sale']"),
(By.CSS_SELECTOR, "*[class*='price']"),
(By.XPATH, ".//*[contains(@class, 'price')]")
])
if all([img_element, url_element, title_element, price_element]):
# Get discount if available
discount_element = find_element_smart(product, [
(By.XPATH, ".//*[contains(text(), '%') or contains(text(), 'OFF')]"),
(By.CSS_SELECTOR, "[class*='discount']")
])
products.append({
"image_url": img_element.get_attribute("src"),
"product_url": url_element.get_attribute("href"),
"product_title": title_element.text.strip(),
"product_price": price_element.text.strip(),
"product_discount": discount_element.text.strip() if discount_element else "N/A"
})
# Save results
csv_file_name = "aliexpress_products.csv"
with open(csv_file_name, mode="w", newline="", encoding="utf-8") as csv_file:
writer = csv.DictWriter(csv_file, fieldnames=["image_url", "product_url", "product_title", "product_price", "product_discount"])
writer.writeheader()
writer.writerows(products)
driver.quit()现在,用以下命令启动脚本:
python scraper.py脚本应能成功运行,并在 aliexpress_products.csv 中生成提取结果,如下所示:
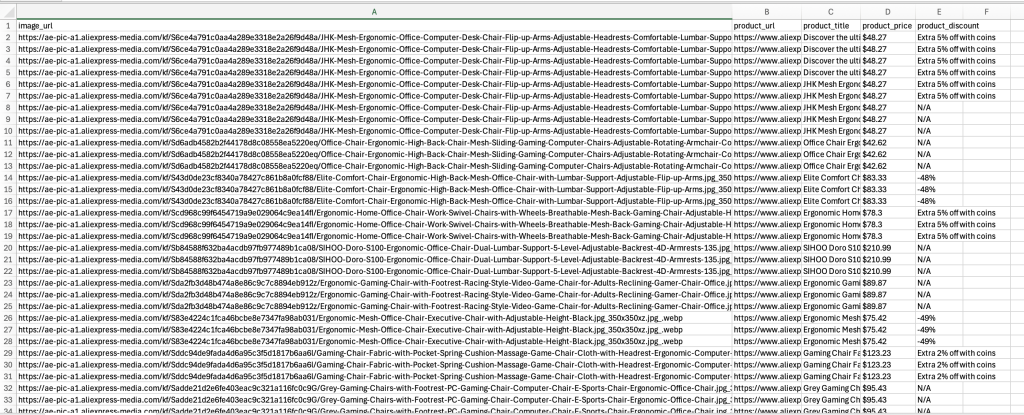
在完成可运行的爬虫脚本后,您可以进一步执行多种操作,比如定期自动化执行、或进行优化,以确保爬虫持续稳定地获取有价值的数据。
结论
通过本指南,您了解了什么是 AliExpress 爬虫,以及它可以提取的数据类型,并学会了如何编写一个简洁的 Python 爬虫来获取 AliExpress 产品信息。
但爬取 AliExpress 仍面临挑战:该平台实施了严格的反爬措施,并且由于分页和动态加载等特性,增加了抓取难度。要打造一个强大的 AliExpress 爬虫并不容易。
我们提供的 AliExpress Scraper API 为此提供了专门的解决方案,可以帮助您轻松绕过这些障碍。通过简洁的 API 调用,您就能在降低被封禁风险的同时快速获取所需数据。需要更快拿到数据?
想使用我们的 Scraper APIs 或 浏览我们的数据集?只需注册一个 Bright Data 账户,开启免费试用即可体验!



