

在本教程中,您将学习:
- 什么是 CAPTCHA,以及它们是否可以避免
- 如何在 Selenium 中避免 CAPTCHA
- 如果仍然出现 CAPTCHA 时该怎么办
让我们开始吧!
什么是 CAPTCHA?是否可以避免它们?
CAPTCHA,全称为“完全自动化公共图灵测试以区分计算机和人类”(Completely Automated Public Turing test to tell Computers and Humans Apart),是一种设计用于区分人类用户和机器人的机制。它提供了对于人类来说容易解决但对机器难以解决的挑战。知名的 CAPTCHA 提供商包括谷歌 reCAPTCHA、hCaptcha 和 BotDetect。
常见的 CAPTCHA 类型包括:
- 基于文本的挑战: 用户需要输入一串扭曲的字母和数字。
- 基于图像的挑战: 用户必须在一组图像中识别特定的物体。
- 基于音频的挑战: 用户需要输入他们听到的单词。
- 拼图挑战: 用户需要解决简单的拼图,例如导航迷宫。
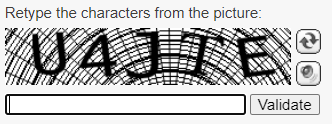
CAPTCHA 通常是特定用户流程的一部分,例如表单提交过程的最后一步:
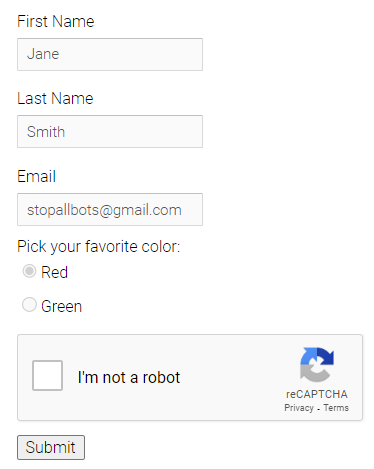
在这些情况下,CAPTCHA 的存在是为了确保机器人无法完成用户流程。为了自动化这些挑战,您可以使用依赖人工操作员实时解决挑战的 CAPTCHA 解决库或服务。然而,由于对用户体验的负面影响,硬编码 CAPTCHA 是不常见的。
更常见的是,CAPTCHA 是全面反机器人解决方案的一部分,例如 WAF(Web 应用程序防火墙):
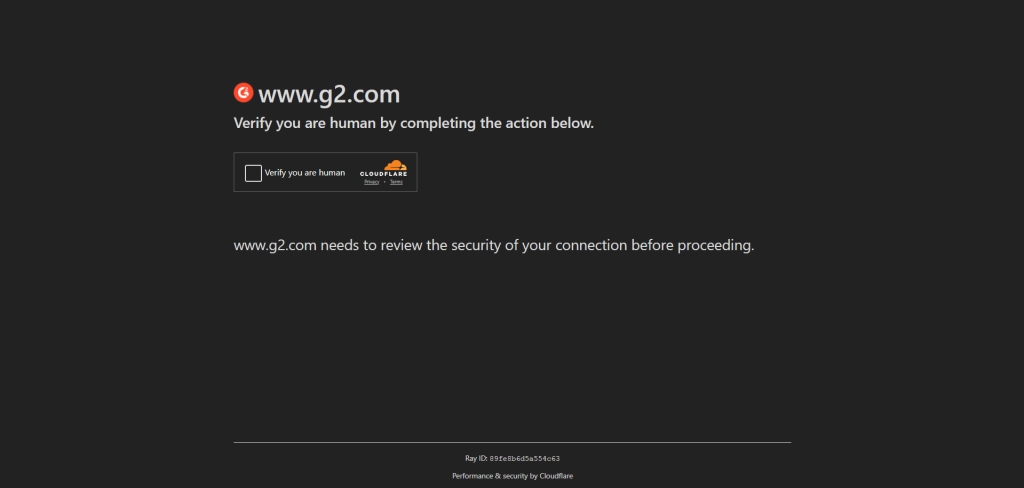
这些系统在怀疑有机器人活动时动态显示 CAPTCHA。在这种情况下,可以通过让机器人模拟真实世界浏览器中的人类行为来绕过 CAPTCHA。尽管如此,这需要不断更新您的脚本以跟上新的机器人检测方法。
避免 CAPTCHA 的更有效解决方案是使用 Bright Data 的CAPTCHA 解决功能等下一代工具。这个云工具始终保持最新,并且可以为您处理多种 CAPTCHA 类型。
Selenium CAPTCHA 处理:逐步教程
正如您刚刚学习的,避免 CAPTCHA 的有效方法是让您的自动化脚本在控制具有真实指纹的浏览器时模拟人类行为。用于该目的的最佳工具之一是Selenium,一个流行的浏览器自动化库。
在本教程部分中,您将学习如何使用 Python 脚本在 Selenium 中避免 CAPTCHA。让我们开始吧!
步骤 #1:创建一个新的 Python 项目
在开始之前,请确保您本地安装了Python 3和Chrome。
如果您已经有一个Selenium 网络抓取或测试脚本,可以跳过前三个步骤。否则,请为您的 Selenium CAPTCHA 绕过演示项目创建一个文件夹并在终端中导航到该文件夹:
mkdir selenium_demo
cd selenium_demo接下来,在其中添加一个新的Python 虚拟环境:
python -m venv venv在您喜欢的 Python IDE 中打开项目文件夹,并创建一个名为script.py的新文件。
太好了!您的项目文件夹现在包含一个 Python 应用程序。
步骤 #2:安装 Selenium
使用以下命令激活Python 虚拟环境:
venvScriptsactivate或者,如果您是 Linux 或 macOS 用户:
source venv/bin/activate然后,通过pip包安装 Selenium,使用以下命令来安装selenium:
pip install selenium安装过程可能需要一段时间,请耐心等待。
太棒了!您可以初始化您的 Selenium 脚本了。
步骤 #3:设置您的 Selenium 脚本
通过将以下行添加到script.py来导入 Selenium:
from selenium import webdriver现在,创建一个ChromeOptions对象以配置 Chrome 在无头模式下启动:
options = webdriver.ChromeOptions()
options.add_argument("--headless")如果您不熟悉此选项,可以在我们的无头浏览器指南中了解更多信息。
使用这些选项初始化一个Chrome WebDriver实例,并最终使用quit()关闭它。当前script.py文件应该如下所示:
from selenium import webdriver
# configure Chrome to start in headless mode
options = webdriver.ChromeOptions()
options.add_argument("--headless")
# start a Chrome instance
driver = webdriver.Chrome(options=options)
# browser automation logic...
# close the browser and release its resources
driver.quit()上述脚本在关闭浏览器之前以无头模式启动一个新的 Chrome 实例。太好了!现在是实现浏览器自动化逻辑的时候了。
步骤 #4:添加浏览器自动化逻辑
为了评估 Selenium CAPTCHA 绕过逻辑,自动化脚本将连接到bot.sannysoft.com并截取屏幕截图。这个特殊的网页在浏览器中运行几个测试以确定用户是人类还是机器人。如果您在自己喜欢的浏览器上访问该页面,您会看到所有测试都通过了。
使用get()方法指示 Chrome 实例访问目标页面:
driver.get("https://bot.sannysoft.com/")然后,您需要截取整个页面的屏幕截图。不幸的是,Selenium 没有直接提供实现该功能的函数。作为一种解决方法,您可以将浏览器窗口设置为<body>节点的宽度和高度,然后截取屏幕截图:
# get the body width and height
full_width = driver.execute_script("return document.body.parentNode.scrollWidth")
full_height = driver.execute_script("return document.body.parentNode.scrollHeight")
# set the browser window to the body width and height
driver.set_window_size(full_width, full_height)
# take a screenshot of the entire page
driver.save_screenshot("screenshot.png")
# restore the original window size
driver.set_window_size(original_size["width"], original_size["height"])上述技巧可以解决问题,并且screenshot.png将包含整个页面的屏幕截图。
将所有内容放在一起,您将拥有以下逻辑:
from selenium import webdriver
# configure Chrome to start in headless mode
options = webdriver.ChromeOptions()
options.add_argument("--headless")
# start a Chrome instance
driver = webdriver.Chrome(options=options)
# connect to the target page
driver.get("https://bot.sannysoft.com/")
# get the current window size
original_size = driver.get_window_size()
# get the body width and height
full_width = driver.execute_script("return document.body.parentNode.scrollWidth")
full_height = driver.execute_script("return document.body.parentNode.scrollHeight")
# set the browser window to the body width and height
driver.set_window_size(full_width, full_height)
# take a screenshot of the entire page
driver.save_screenshot("screenshot.png")
# restore the original window size
driver.set_window_size(original_size["width"], original_size["height"])
# close the browser and release its resources
driver.quit()使用以下命令启动上述script.py文件:
python script.py脚本将在无头模式下启动一个 Chromium 实例,连接到所需页面,截取屏幕截图,并关闭浏览器。在脚本执行结束时,项目根文件夹中将出现一个screenshot.png文件。打开它,您将看到:
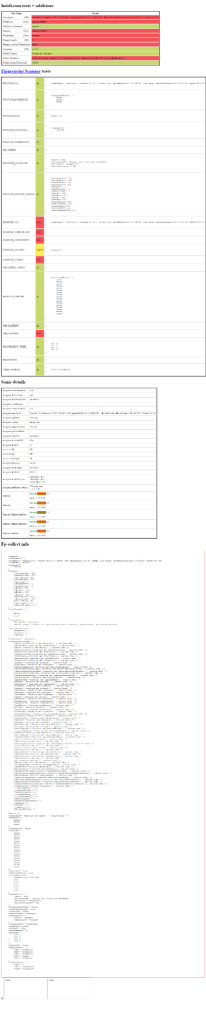
从红色框中可以看出,通过原始 Selenium 控制的无头模式的 Chrome 未通过各种测试。这意味着您的脚本很可能被检测为机器人。其结果是,当您与之交互时,受反机器人技术保护的网站可能会显示 CAPTCHA。在 Selenium 中避免 CAPTCHA 的解决方案?Stealth 插件!
步骤 #5:安装 Selenium Stealth 插件
Selenium Stealth是一个 Python 包,旨在使 Selenium 控制的 Chrome/Chromium 实例更难被检测为机器人。该项目的目标是配置浏览器以绕过几乎所有已知的机器人检测策略。
具体来说,Selenium Stealth 修改浏览器属性,以防止任何泄漏暴露浏览器为自动化。如果您熟悉反机器人绕过解决方案,此包可以被视为Puppeteer Stealth的重新实现。
通过pip包安装 Selenium Stealth,使用以下命令来安装selenium-stealth:
pip install selenium-stealth然后,添加此行到script.py文件以导入库:
from selenium_stealth import stealth做好准备!剩下的就是配置隐形设置。
步骤 #6:配置隐形设置以避免 CAPTCHA
要注册 Selenium Stealth 并配置 Chrome WebDriver 以避免 CAPTCHA,按以下方式调用stealth()函数:
stealth(
driver,
user_agent="Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36",
languages=["en-US", "en"],
vendor="Google Inc.",
platform="Win32",
webgl_vendor="Intel Inc.",
renderer="Intel Iris OpenGL Engine",
fix_hairline=True,
)您可以根据需要配置函数参数,但请记住,上述值足以绕过大多数反机器人措施。
做得好!由 Selenium 控制的浏览器现在将显示为人类用户使用的真实浏览器。
步骤 #7:重复机器人检测测试
以下是最终的script.js文件:
from selenium import webdriver
from selenium_stealth import stealth
# configure Chrome to start in headless mode
options = webdriver.ChromeOptions()
options.add_argument("--headless")
# start a Chrome instance
driver = webdriver.Chrome(options=options)
# configure the WebDriver to avoid bot detection
# with Selenium Stealth
stealth(
driver,
user_agent="Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36",
languages=["en-US", "en"],
vendor="Google Inc.",
platform="Win32",
webgl_vendor="Intel Inc.",
renderer="Intel Iris OpenGL Engine",
fix_hairline=True,
)
# connect to the target page
driver.get("https://bot.sannysoft.com/")
# get the current window size
original_size = driver.get_window_size()
# get the body width and height
full_width = driver.execute_script("return document.body.parentNode.scrollWidth")
full_height = driver.execute_script("return document.body.parentNode.scrollHeight")
# set the browser window to the body width and height
driver.set_window_size(full_width, full_height)
# take a screenshot of the entire page
driver.save_screenshot("screenshot.png")
# restore the original window size
driver.set_window_size(original_size["width"], original_size["height"])
# close the browser and release its resources
driver.quit()再次执行绕过 CAPTCHA 的 Selenium Python 脚本:
python script.py查看screenshot.png,您会注意到所有的机器人检测测试都已通过:
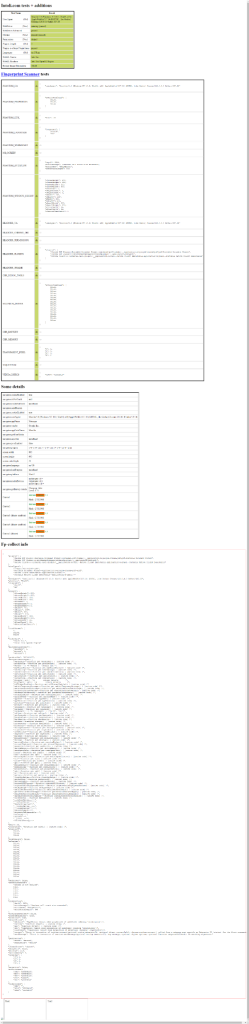
太好了!您现在知道了在 Selenium 中避免反机器人 CAPTCHA 的技巧。
如果上述绕过 CAPTCHA 的 Selenium 解决方案不起作用怎么办
不幸的是,浏览器设置并不是反机器人解决方案关注的唯一方面。IP 声誉是另一个关键方面,您不能仅仅通过使用免费库更换 IP 为更可靠的 IP。这需要Selenium 代理集成!
换句话说,即使您以最佳方式配置浏览器,CAPTCHA 也可能仍然会出现。对于仅需要单击一次的简单 CAPTCHA,您可以尝试使用像selenium-recaptcha-solver或selenium-recptcha这样的包。然而,这些库仅适用于 reCAPTCHA v2,并且不再维护。
上一章中方法及这些包的主要问题是它们仅对付基础 CAPTCHA 有效。在处理更复杂的反机器人系统(如 Cloudflare)时,您需要更强大的解决方案。
寻找真正的 Selenium CAPTCHA 解决方案?尝试 Bright Data 的网页抓取解决方案!
这些解决方案具有卓越的解锁功能,并提供专用的 CAPTCHA 解决功能,以自动处理 reCAPTCHA、hCaptcha、px_captcha、SimpleCaptcha、GeeTest CAPTCHA、FunCaptcha、Cloudflare Turnstile、AWS WAF Captcha、KeyCAPTCHA 等众多 CAPTCHA。
将 Bright Data 的 CAPTCHA Solver 集成到您的脚本中很简单,因为它可以与任何 HTTP 客户端或浏览器自动化工具(包括 Selenium)一起使用。
了解更多关于如何使用 Bright Data 的 CAPTCHA Solver的信息,并查看文档以获取所有配置详情。
结论
在本文中,您了解了为什么 CAPTCHA 对自动化软件是一个挑战,以及如何在 Selenium 中解决它们。感谢 Selenium Stealth 库,您可以覆盖 Chrome 的默认配置以限制机器人检测。然而,这种方法并不是一个最终的解决方案。
无论您的 Selenium CAPTCHA 绕过逻辑多么复杂,先进的机器人检测工具仍然能够阻止您。真正的解决方案是通过一个可以返回任何网页的无 CAPTCHA HTML 的解锁 API 连接到目标网站。
这个 API 不是梦。它存在并被称为Web Unlocker,它是一个抓取 API,通过代理集成自动旋转您的出口 IP,并为您处理浏览器指纹、自动重试和 CAPTCHA 解决。处理 CAPTCHA 从未如此简单!
立即注册并开始您的免费试用。



技术写作
 5.5 years experience
5.5 years experience
Antonello是一名软件工程师,但他更喜欢称自己为技术传教士。通过写作传播知识是他的使命。


