

在本教程中,您将学习如何抓取Next.js站点的技巧:
- 什么是Next.js及其受欢迎的原因
- 为什么由于React hydration的工作原理,抓取Next.js网页变得容易
- 如何利用React hydration进行网页抓取
让我们深入了解吧!
什么是Next.js及其工作原理?
Next.js是一个基于React构建的JavaScript框架,用于构建服务器端渲染和静态生成的网站。它通过提供丰富的API和结构化的方法简化了构建服务器端React应用的开发过程。
Next.js近年来变得非常受欢迎,根据Statista的统计,它已经成为第五大最常用的Web库。这是由于其易用性、优异的性能、与React的相似性、详尽的文档和社区支持。难怪许多大公司和初创公司选择Next.js进行Web开发。
在高层次上,Next.js通过在服务器上获取数据并将其传递给React组件来创建预渲染的HTML文档。这个过程通过在服务器上生成HTML内容来增强性能,然后将其发送给客户端以实现更快的初始页面加载。
如何利用React Hydration进行网页抓取
Hydration桥接了服务器端渲染和客户端渲染之间的差距。详细来说,Next.js hydration是指通过Next.js生成的HTML文档被转换为一个完全功能的客户端React应用的过程。
在hydration过程中——浏览器加载服务器返回的HTML页面后——React为页面添加了交互性。具体来说,它在对应于服务器渲染的React组件的DOM节点上附加事件监听器并处理状态。
React需要以下步骤来hydrate预渲染的页面:
- 初始服务器渲染:服务器生成包含页面上使用的React组件的HTML表示的HTML文档。
- 客户端JavaScript执行:当客户端接收到HTML标记时,它运行包含React代码的JavaScript包。
- 协调:React将服务器返回的HTML与动态生成的虚拟DOM表示进行比较。在官方文档中了解更多。
- Hydration:如果两者相同,React通过添加事件处理程序和处理状态来完成渲染,同时尽可能重用现有的DOM。
要执行此操作,React需要服务器用于生成HTML文档的相同数据。这就是为什么Next.js在生成的页面中添加了一些包含props数据的特殊DOM元素。
在一些Next.js站点上,您可以在带有__NEXT_DATA__ ID的<script>元素中找到这些数据。这个特殊的DOM节点包含JSON格式的数据,React用它来进行hydration,如下所示:
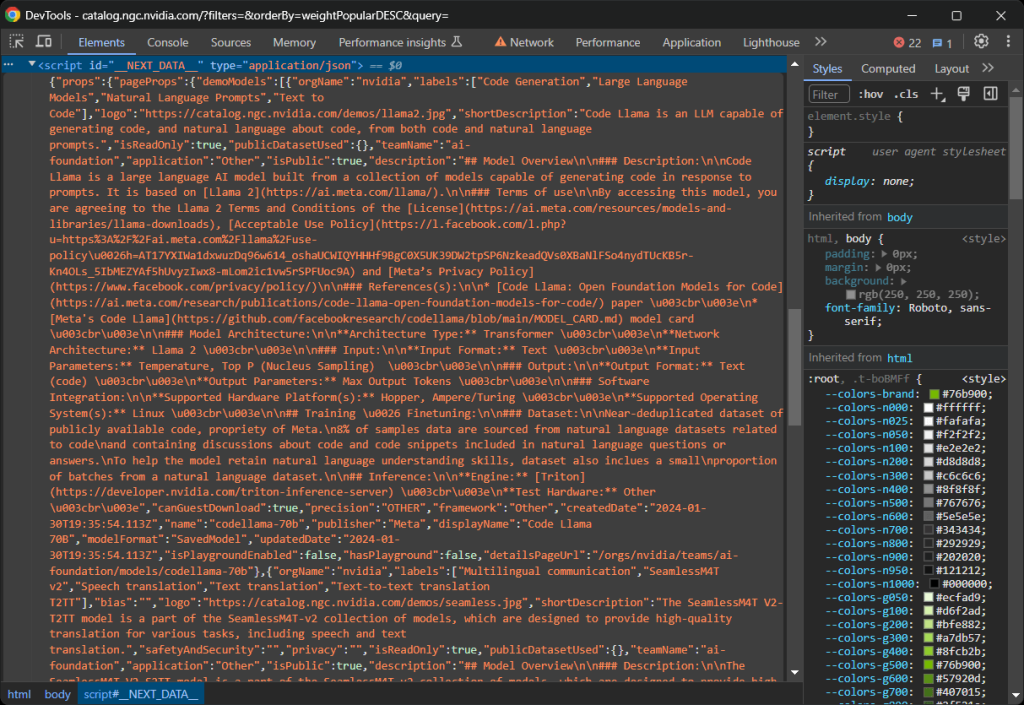
在使用新App Router的最新Next.js站点上,hydration数据存储在多个<script>节点中的self.__next_f.push()函数调用中:
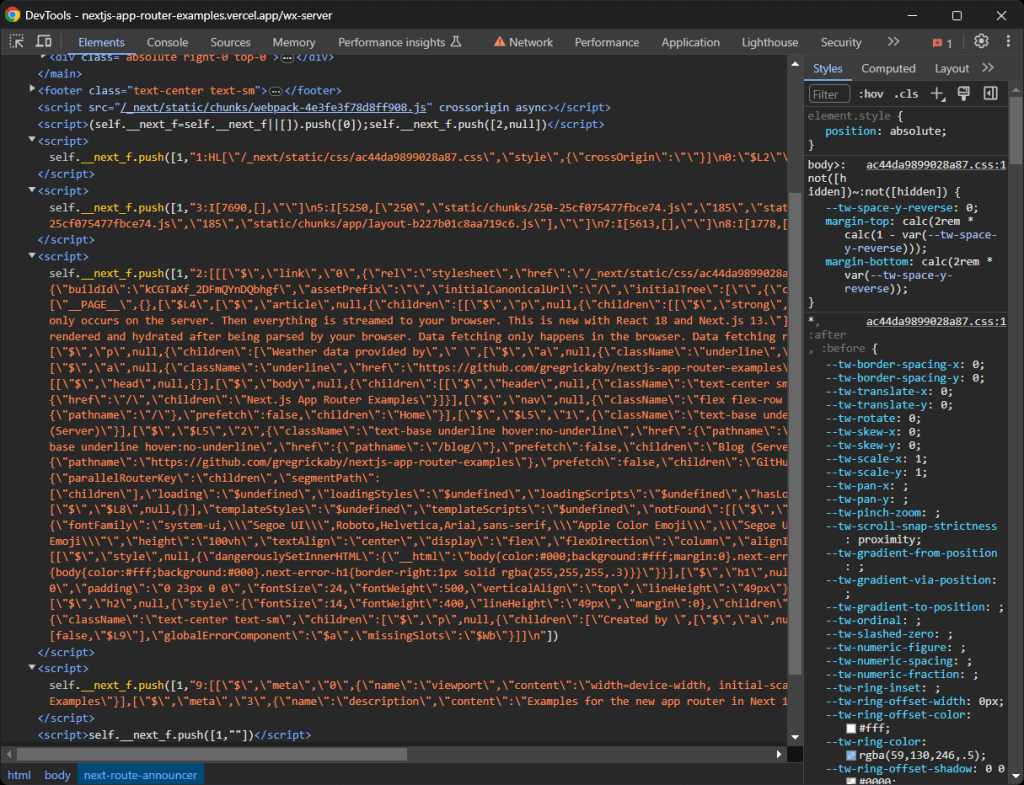
请注意,这些节点可能包含比网站上显示的更多的数据。这是因为这些hydration元素存储了在页面生成过程中从服务器检索并传递给React组件的所有API和数据库数据。然而,并非所有这些对象的属性都会在组件中实际被访问和使用。
现在,无论您是否理解为什么需要这些数据来使React正常工作,关键是通过Next.js生成的网页在特殊的DOM节点中以JSON格式包含了要渲染的数据。正如您所想象的,这对Next.js网页抓取具有重要意义!
通过Hydration数据抓取Next.js站点
从Next.js构建的页面中提取数据非常简单,您甚至不需要抓取脚本。浏览器的开发者工具就足够了。
现在让我们看看如何利用React hydration在几秒钟内抓取Next.js站点!
从__NEXT_DATA__提取数据
假设您已经确认目标页面是用Next.js构建的(在FAQ中查找如何确认)。
现在,在浏览器中访问该页面,右键单击并选择“检查”以打开开发者工具。转到控制台标签页并运行以下JavaScript代码行以选择所需的<script>元素:
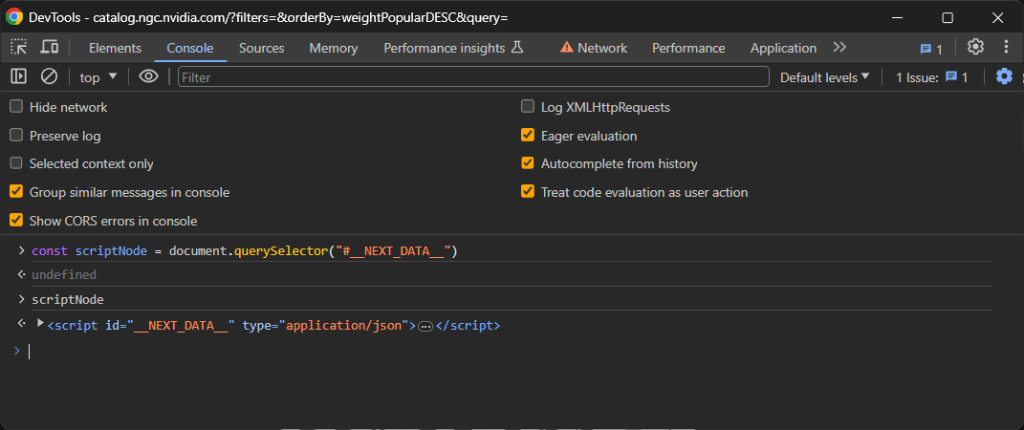
const scriptNode = document.querySelector("#__NEXT_DATA__")这将使用querySelector()函数选择DOM中ID为__NEXT_DATA__的元素并将其分配给scriptNode变量。
如果在控制台中键入scriptNode并按Enter键,您将获得所需的节点:
访问其内部HTML内容并将其解析为JSON内容:
const jsonData = JSON.parse(scriptNode.innerHTML)
瞧!jsonData对象现在将包含React用来渲染页面组件的所有数据:
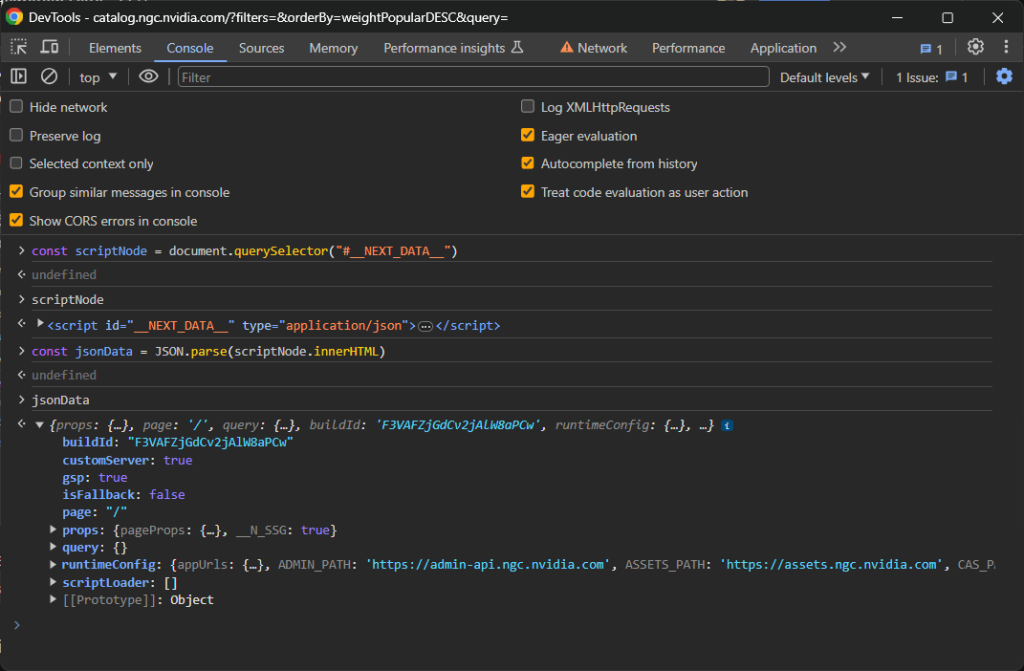
详细来说,重点关注props中的pageProps字段:
jsonData.props.pageProps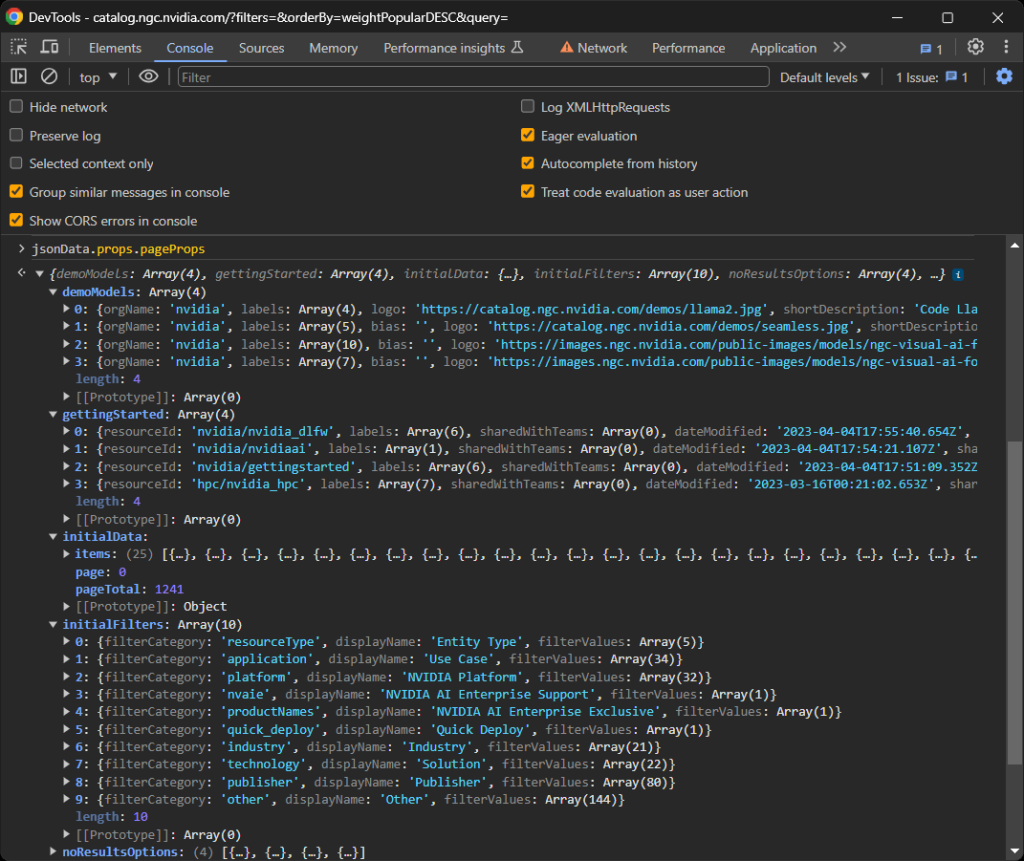
接下来,右键单击该对象并选择“复制对象”选项:
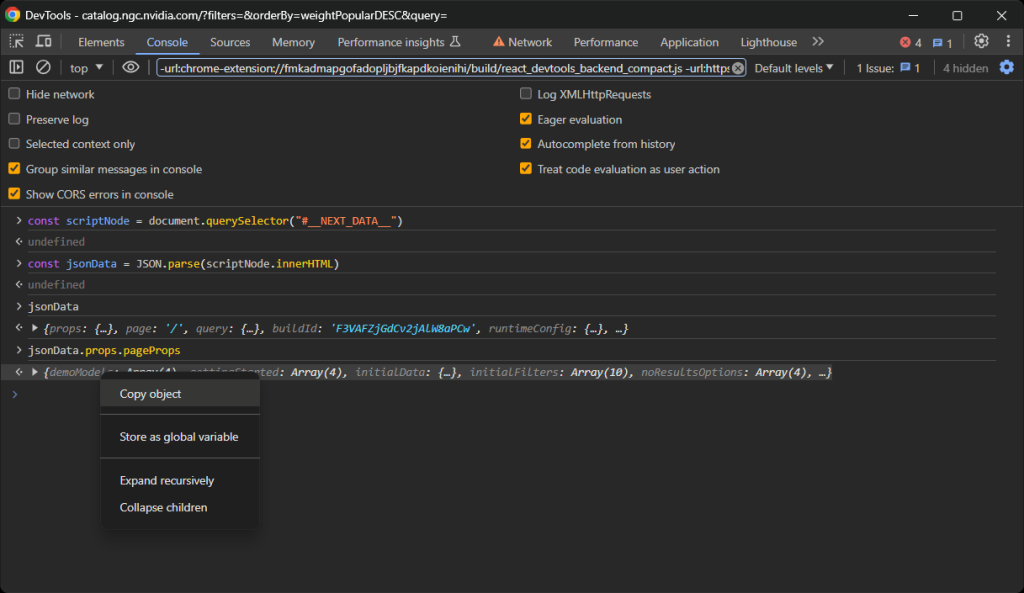
最后,创建一个data.json文件并将所需内容粘贴到其中!
太棒了!您刚刚在不到一分钟的时间内对一个Next.js站点进行了网页抓取。
将所有内容整合在一起,您将获得这个Next.js抓取脚本:
const scriptNode = document.querySelector("#__NEXT_DATA__")
const jsonData = JSON.parse(scriptNode.innerHTML)
jsonData.props.pageProps从self.__next_f.push函数检索数据
Next.js 13引入了App Router。这改变了Next.js将数据传递给React进行hydration的方式。在这种情况下,您需要选择包含self.__next_f.push字符串的所有<script>节点。
再次访问目标页面并进入控制台。运行以下命令以选择<script>节点:
const scriptNodes = document.querySelectorAll("script")querySelectorAll()返回一个NodeList对象。使用Array.from()将其转换为数组,以应用filter()方法并仅获取感兴趣的节点:
const hydrationScriptNodes = Array.from(scriptNodes).filter((e) => e.innerHTML.includes("self.__next_f.push"))现在,hydrationScriptNodes将包含页面上的所有hydration<script>元素:
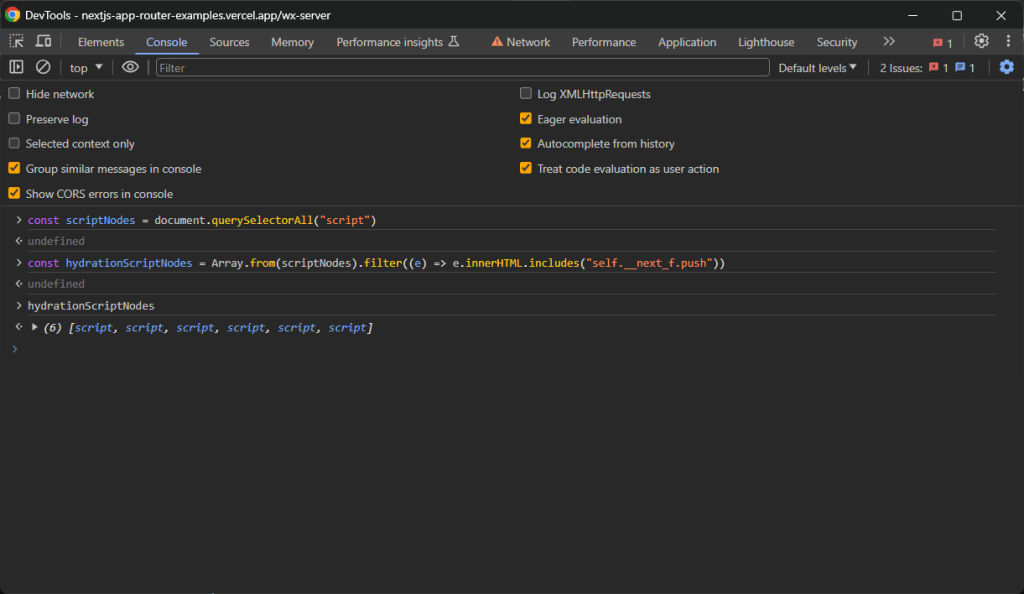
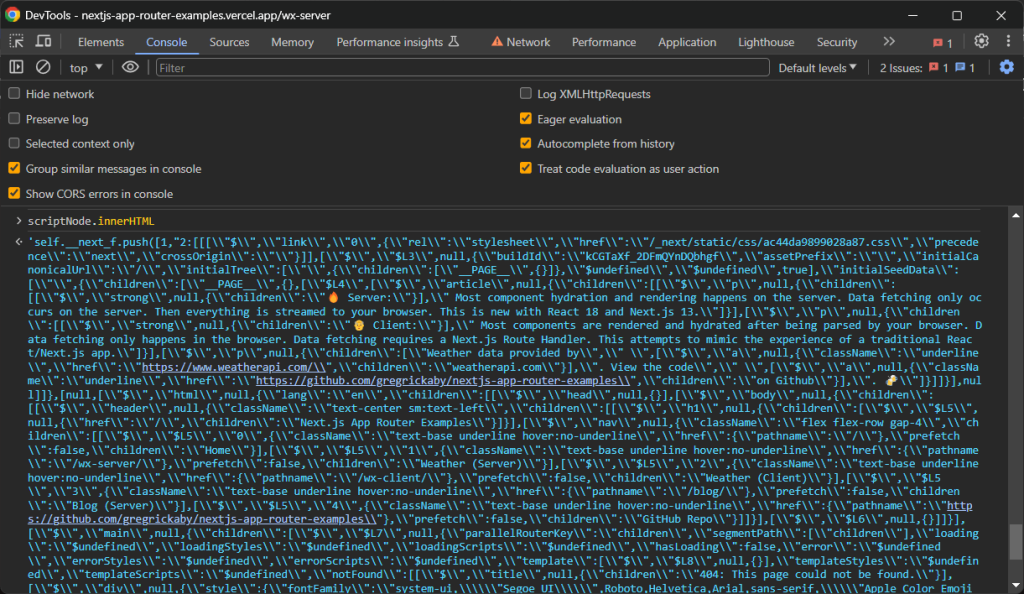
然而,您通常只需要具有initialTree属性的节点。这是所有感兴趣的hydration数据存储的位置:
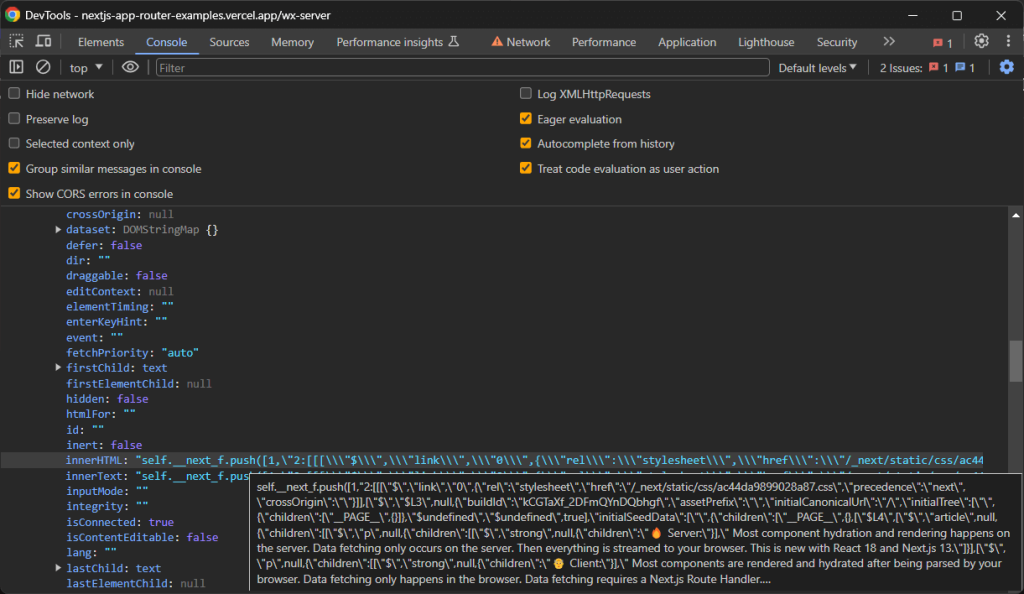
使用以下命令选择它:
const scriptNode = hydrationScriptNodes.find((e) => e.innerHTML.includes("initialTree"))然后,使用以下命令提取感兴趣的数据:
scriptNode.innerHTML请注意,检索到的数据包含感兴趣的信息,但需要额外解析。您可以通过几行额外代码将其转换为更易读的格式。
这次,Next.js抓取脚本是:
const scriptNodes = document.querySelectorAll("script")
const hydrationScriptNodes = Array.from(scriptNodes).filter((e) => e.innerHTML.includes("self.__next_f.push"))
const scriptNode = hydrationScriptNodes.find((e) => e.innerHTML.includes("initialTree"))
scriptNode.innerHTML恭喜!抓取Next.js站点从未如此简单!
这种Next.js抓取方法的局限性
虽然这种基于React hydration数据的抓取方法快速有效,但它也存在一些局限性。这些局限性包括:
- 数据部分:Next.js添加的特殊
<script>节点仅包含服务器检索并传递给React组件的hydration数据。这可能不是页面上包含的全部数据。因为React组件可以有硬编码的值或通过AJAX动态检索其他数据。在这种情况下,您需要使用浏览器自动化工具进行网页抓取。 - 需要额外解析:
self.__next_f.push涉及专有格式的数据,正确解析这些数据可能并不总是容易的。 - 需要手动操作:除非您将上述脚本翻译为JavaScript、Python或类似语言中的抓取脚本并集成数据导出的逻辑,否则您必须手动将数据导出到文本文件中。了解更多请参阅我们的使用JavaScript和Node.js进行网页抓取指南。
结论
在本文中,您了解了什么是Next.js,为什么它是世界上最广泛使用的技术之一,以及如何从中抓取数据。特别是,您认识到它依赖于React hydration及其影响。因此,服务器返回的HTML页面已经包含了您所需的所有数据(甚至是JSON格式!)。这使得抓取Next.js站点变得非常容易。
真正的问题是:被反机器人技术阻止。这些系统可以检测并阻止您的自动抓取脚本。幸运的是,Bright Data为您提供了几种有效的解决方案:
- Web Scraper IDE:一个云IDE,用于构建能够自动绕过和避免任何阻止的网页抓取工具。
- Web Scraper API:轻松访问结构化的网页数据,具有99.99%的正常运行时间和无限的可扩展性。
- Scraping Browser:一个基于云的可控浏览器,提供JavaScript渲染功能,同时为您处理CAPTCHA、浏览器指纹、自动重试等。它与最流行的自动化浏览器库(如Playwright和Puppeteer)集成。
- Web Unlocker:一个解锁API,能够无缝返回任何页面的原始HTML,绕过任何反抓取措施。
不想处理网页抓取但仍然对在线数据感兴趣?探索Bright Data的现成数据集!
常见问题
是否可以隐藏或删除Next.js中的__NEXT_DATA__?
不,您不能删除或隐藏它。如果您决定从DOM中删除_NEXT_DATA_ <script>元素,React将无法进行hydration。由于该脚本中的数据是React正常工作的必要条件,您不能删除它而不期望某些功能失效或性能下降。阅读GitHub讨论。
是否可以从DOM中删除self.__next_f.push调用?
不,您不能删除Next.js添加的<script>节点中的self.__next_f.push调用。这些DOM元素是由服务器添加的,以使客户端React应用能够进行hydration并按预期功能运行。有关详细信息,请查看GitHub讨论。
如何判断一个站点是用Next.js构建的?
有几种方法可以判断一个站点是否用Next.js构建。首先,查看默认由某些版本的Next.js设置的X-Powered-By头:
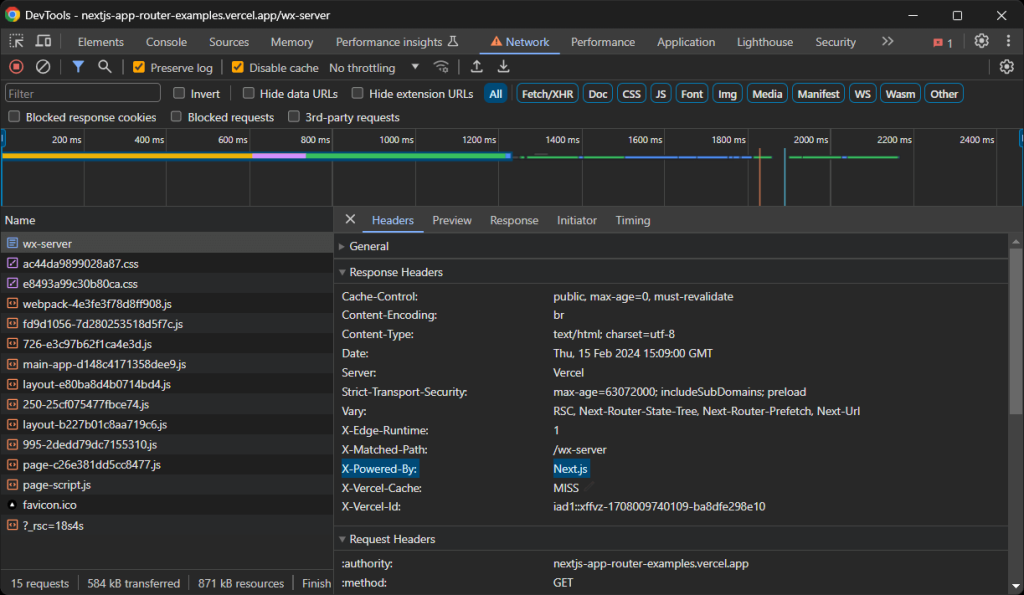
否则,检查DOM是否包含<script id="__NEXT_DATA__" ... >节点或一些<script>self.__next_f.push(...)</script>节点。
Next.js是唯一依赖React hydration的技术吗?
不,Next.js不是唯一依赖React hydration的技术。其他服务器端渲染(SSR)生成器,如Gatsby,也利用React hydration将服务器渲染的HTML转换为客户端上的交互式React应用。这一过程是SSR与React的常见方法,并不限于Next.js。


