

在本文中,我们将讨论:
- 揭秘 PhantomJS
- 使用 PhantomJS 进行数据抓取的优缺点
- 逐步 PhantomJS 数据收集指南
- 数据自动化:手动抓取的更简单替代方案
揭秘 PhantomJS
PhantomJS 是一种“无头浏览器”。这意味着它没有图形用户界面(GUI),而是仅运行脚本(使其更精简、更快速,因此更高效)。它可以用来使用 JavaScript (JS) 自动化不同任务,如测试代码或收集数据。
对于初学者,我建议首先使用命令行界面中的“npm”在您的计算机上安装 PhantomJS。您可以通过运行以下命令来完成此操作:
npm install phantomjs -g
现在,您可以使用“phantomjs”命令。
使用 PhantomJS 进行数据抓取的优缺点
PhantomJS 有许多优点,包括它是“无头的”,如上所述,这使得它更快,因为不需要加载图形来测试或检索信息。
PhantomJS 可以高效地用于完成以下任务:
屏幕捕获
PhantomJS 可以帮助自动抓取和保存 PNG、JPEG 甚至 GIF。这一功能使得执行前端用户界面/体验保证变得更加容易。例如,您可以运行命令行:Phantomjs amazon.js,以收集竞争对手产品列表的图片或确保您公司的产品列表显示正确。
页面自动化
这是 PhantomJS 的一个主要优势,因为它帮助开发人员节省了大量时间。通过运行像 Phantomjs userAgent.js 这样的命令行,开发人员可以编写和检查与特定网页相关的 JS 代码。这里的主要时间节省优势是,这个过程可以自动化,并且无需打开浏览器即可完成。
测试
在测试网站时,PhantomJS 具有优势,因为它简化了这一过程,就像其他流行的网络抓取工具如 Selenium一样。无头浏览没有 GUI,这意味着扫描问题的速度更快,错误代码会在命令行级别被发现并传递。
开发人员还将 PhantomJS 集成到不同类型的持续集成(CI)系统中,以在代码上线前进行测试。这有助于开发人员实时修复破损代码,确保项目上线更顺畅。
网络监控 / 数据收集
PhantomJS 还可以用于监控网络流量/活动。许多开发人员将其编程为帮助收集目标数据,如:
- 特定网页的性能
- 代码行的添加/删除
- 股票价格波动数据
- 抓取 Instagram 等网站时的影响力/参与数据
使用 PhantomJS 的一些缺点包括:
- 它可能被恶意方利用进行自动化攻击(主要是由于它不使用用户界面)
- 在全周期/端到端测试和功能测试时,有时可能会显得棘手。
逐步 PhantomJS 数据收集指南
PhantomJS 在 NodeJS 开发人员中非常流行,因此我们将提供一个在 NodeJS 环境中使用它的示例。该示例展示了如何从 URL 获取 HTML 内容。
第一步: 设置 package.json 并安装 npm 包
创建一个项目文件夹,并在其中创建一个文件“package.json”。
{
"name": "phantomjs-example",
"version": "1.0.0",
"title": "PhantomJS Example",
"description": "PhantomJS Example",
"keywords": [
"phantom example"
],
"main": "./index.js",
"scripts": {
"inst": "rm -rf node_modules && rm package-lock.json && npm install",
"dev": "nodemon index.js"
},
"dependencies": {
"phantom": "^6.3.0"
}
}然后在终端运行此命令:$ npm install。它将在您的本地项目文件夹“node_modules”中安装 Phantom。
第二步:创建 Phantom JS 脚本
创建 JS 脚本并将其命名为“index.js”
const phantom = require('phantom');
const main = async () => {
const instance = await phantom.create();
const page = await instance.createPage();
await page.on('onResourceRequested', function(requestData) {
console.info('Requesting', requestData.url);
});
const url = 'https://example.com/';
console.log('URL::', url);
const status = await page.open(url);
console.log('STATUS::', status);
const content = await page.property('content');
console.log('CONTENT::', content);
await instance.exit();
};
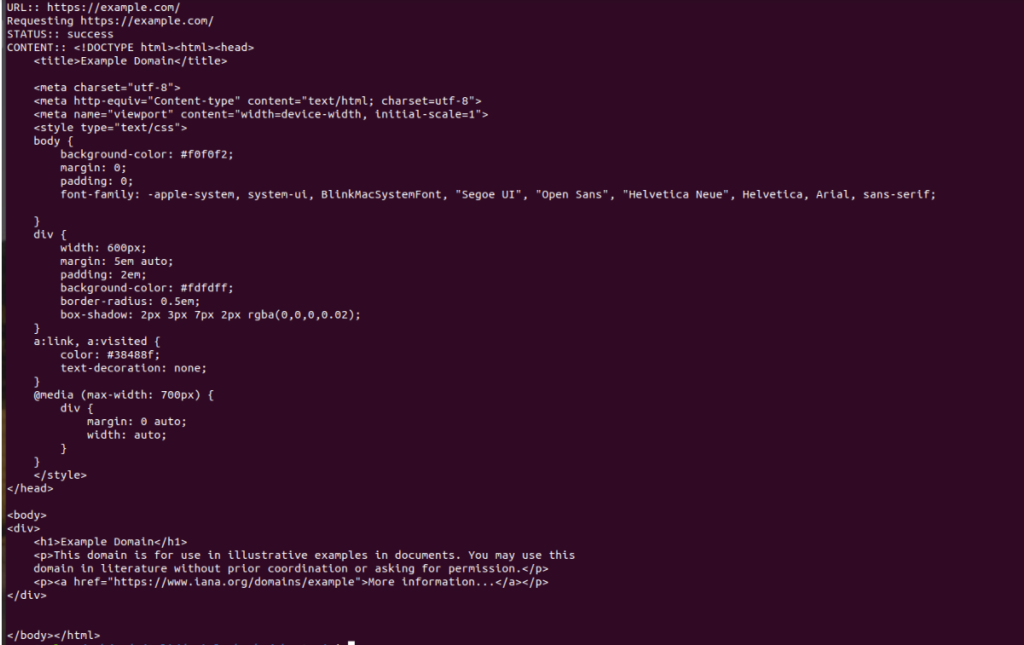
main().catch(console.log);第三步:运行 JS 脚本
要启动脚本,请在终端运行:$ node index.js。结果将是 HTML 内容。
数据自动化:手动抓取的更简单替代方案
当涉及到大规模数据抓取时,一些公司可能更喜欢使用 PhantomJS 的替代方案。
这些替代方案包括:
- 代理:使用代理进行网络抓取的好处在于,它们使用户能够大规模收集数据,提交无限数量的并发请求。代理还可以帮助解决目标站点的限制,如速率限制或地理位置基于的封锁。在这种情况下,企业可以利用国家/城市特定的移动和住宅 IP/设备来路由数据请求,使他们能够检索更准确的用户数据(例如竞争对手的定价、广告活动和 Google 搜索结果)。
- 现成的数据集:数据集基本上是已经收集的信息包,可以立即交付给算法/团队使用。它们通常包含来自目标站点的信息,并从相关网站(例如,多个供应商和各种电子商务市场中的产品信息)丰富信息。数据集还可以定期刷新,以确保所有数据点都是最新的。这里的主要优势是,在数据收集上不需要投入时间/资源,这意味着可以花更多时间在数据分析和为客户创造价值上。
- 完全自动化的 Web 抓取 API:Web 抓取 API是一种易于使用的、零代码、零基础设施的可定制数据收集解决方案。它使公司 能够毫不费力地收集结构化网络数据,而无需进行软件或硬件开发和维护的麻烦。
请与 Bright Data 的数据专家联系,了解哪种产品最适合您的网络抓取需求。



