

本教程将涵盖以下内容:
- 为什么要从网络上抓取电子商务数据?
- eBay抓取库和工具
- 使用Beautiful Soup抓取eBay产品数据
为什么要从网络上抓取电子商务数据?
从网络上抓取电子商务数据可以让您检索不同情景和活动中有用的信息,包括:
- 价格监控:通过跟踪电商网站,企业可以实时监控产品的价格。这有助于您识别价格波动、发现趋势并相应调整定价策略。如果您是消费者,这能帮助您找到最佳优惠并省钱。
- 竞争对手分析:通过采集有关竞争对手的产品、价格、折扣和促销信息,您可以利用数据,驱动定价策略、产品分类和营销活动等决策。
- 市场研究:电子商务数据提供了有关市场趋势、消费者偏好和需求模式的宝贵洞察。您可以对该信息进行数据分析,以研究新兴趋势并了解客户行为。
- 情绪分析:通过从电子商务网站抓取客户评论,您可以深入了解客户满意度、产品反馈和需要改进的领域。
在抓取电子商务数据时,eBay是最受欢迎的网站之一,有以下三个充分理由:
- 产品范围广
- eBay基于拍卖和竞价系统,让您能够检索比亚马逊等类似平台更多的数据。
- 同一产品有多种价格(拍卖+立即购买!)
通过抓取eBay网页上的数据,您可以访问大量信息来支持您的价格监控、比较或分析策略。
eBay抓取库和工具
由于Python易于使用、语法简单且拥有庞大的库生态系统,因此被认为是最佳网页抓取语言之一。因此,我们选择Python座位抓取eBay的编程语言。想深入了解请参阅指南:使用 Python抓取网页。
现在,您需要从众多抓取库中选择合适的库。要做出正确的决定,请在浏览器中探索eBay。通过检查页面发出的AJAX调用,您会注意到站点上的大部分数据都嵌入在服务器返回的HTML文档中。
这意味着只需要一个简单的HTTP客户端来模拟向服务器发出的请求,并用一个HTML解析器来处理返回的HTML文档即可。因此,我们推荐以下工具:
- Requests:这是Python中最流行的HTTP 客户端库。它简化了发送 HTTP 请求和处理响应的过程,简化了从Web服务器检索页面内容的难度。
- Beautiful Soup:这是一个功能齐全的HTML和XML解析Python库。因为提供了强大的方法来探索DOM并从其元素中提取数据,所以它主要用于抓取网页。
借助Requests和Beautiful Soup,您将能够使用Python抓取目标站点。让我们看看如何操作!
用Beautiful Soup抓取eBay产品数据
按照此分步教程,了解如何构建Python脚本来抓取eBay网页。
第 1 步:开始使用
要抓取价格数据,您需要满足以下先决条件:
- 在您的计算机上安装Python 3+:下载安装程序并运行,按照安装向导完成操作。
- 选择Python IDE:带有Python扩展的Visual Studio Code或PyCharm 社区版,都是不错的选择。
接下来,通过运行以下命令,使用名为ebay-scraper的虚拟环境初始化Python项目:
mkdir ebay-scraper
cd ebay-scraper
python -m venv env进入项目文件夹,并添加一个包含以下代码片段的scraper.py文件:
print('Hello, World!')这是一个仅打印“Hello, World!”的示例脚本。但它很快就会包含抓取eBay的逻辑。
通过执行以下命令来验证它是否有效:
python scraper.py在终端中,您应该会看到:
Hello, World!太棒了,现在您有了一个Python项目!
第 2 步:安装抓取库
现在可以将执行网页抓取所需的库添加到项目的依赖项中。在项目文件夹中运行以下命令来安装Beautiful Soup和Requests包:
pip install beautifulsoup4 requests在scraper.py中导入这些库,并准备使用它们从eBay提取数据:
import requests
from bs4 import BeautifulSoup
# scraping logic...确保您的Python IDE没有报告任何错误,并且您已准备好抓取页面来监控价格!
第3步:下载目标网页
如果您是eBay用户,您可能留意到产品页面的URL遵循以下格式:
https://www.ebay.com/itm/<ITM_ID>如您所见,这是一个根据商品ID变化的动态URL。
例如,这是eBay产品的URL:
https://www.ebay.com/itm/225605642071?epid=26057553242&hash=item348724e757:g:~ykAAOSw201kD1un&amdata=enc%3AAQAIAAAA4OMICjL%2BH6HBrWqJLiCPpCurGf8qKkO7CuQwOkJClqK%2BT2B5ioN3Z9pwm4r7tGSGG%2FI31uN6k0IJr0SEMEkSYRrz1de9XKIfQhatgKQJzIU6B9GnR6ZYbzcU8AGyKT6iUTEkJWkOicfCYI5N0qWL8gYV2RGT4zr6cCkJQnmuYIjhzFonqwFVdYKYukhWNWVrlcv5g%2BI9kitSz8k%2F8eqAz7IzcdGE44xsEaSU2yz%2BJxneYq0PHoJoVt%2FBujuSnmnO1AXqjGamS3tgNcK5Tqu36QhHRB0tiwUfAMrzLCOe9zTa%7Ctkp%3ABFBMmNDJgZJi在这里,225605642071是该商品的唯一标识符。请注意,访问该页面无需查询参数。您可以删除标识符,eBay仍然会正确加载产品页面。
请不要在脚本中对目标页面进行硬编码,您可以让它从命令行参数中读取商品ID。这样,您就可以从任意产品页面抓取数据。
您可以通过更新scraper.py来实现:
import requests
from bs4 import BeautifulSoup
import sys
# if there are no CLI parameters
if len(sys.argv) <= 1:
print('Item ID argument missing!')
sys.exit(2)
# read the item ID from a CLI argument
item_id = sys.argv[1]
# build the URL of the target product page
url = f'https://www.ebay.com/itm/{item_id}'
# scraping logic...
Assume you want to scrape the product 225605642071. You can launch your scraper with:
python scraper.py 225605642071借助sys,您可以访问命令行参数。sys.argv的第一个元素是脚本名称,scraper.py。要获取商品ID,您需要定位索引为1的元素。
如果您忘记CLI中的商品ID,应用程序会失败并显示以下错误:
Item ID argument missing!如果提供了项目ID,它将读取CLI参数并在格式化字符串f-string中使用参数来生成要抓取产品的目标URL。在这种情况下,URL会包含:
https://www.ebay.com/itm/225605642071现在,您可以使用请求来下载包含以下代码行的网页:
page = requests.get(url)在后台,request.get()对作为参数传递的URL执行HTTP GET请求。页面会存储eBay服务器产生的响应,包括目标页面的HTML内容。
太棒了!现在让我们看看如何从页面检索数据。
第4步:解析HTML文档
page.text包含服务器返回的HTML文档。将文档传递给BeautifulSoup()构造函数进行解析:
soup = BeautifulSoup(page.text, 'html.parser')第二个参数指定了Beautiful Soup使用的解析器。如果您不熟悉,html.parser是Python内置HTML解析器的名称。
现在,soup变量存储了一个树状结构,公开了一些从DOM中选择元素的有用方法。最常用的方法有:
- find():返回与传递的选择器条件匹配的第一个HTML元素。
- find_all():返回与输入选择器策略匹配的HTML元素列表。
- select_one():返回与输入的CSS选择器匹配的HTML元素。
- select() :返回与传递的CSS选择器匹配的HTML元素列表。
使用这些方法,根据标签、ID、CSS类等参数选择HTML元素。然后从属性和文本内容中提取数据。我们来看看如何操作!
第 5 步:检查产品页面
如果您想构建有效的数据抓取策略,必须首先熟悉目标网页的结构。打开浏览器并访问一些eBay产品页面。
您会首先注意到,根据产品类别不同,页面包含不同的信息。在电子产品中,您可以查看技术规格。

当您访问服装产品时,您会看到有库存的尺寸和颜色。
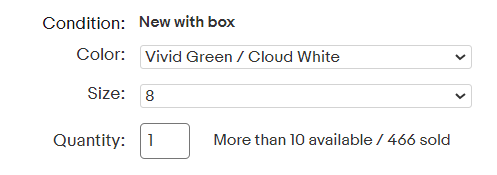
不同品类的网页结构不一致,这加大了抓取数据的难度。但是,每个页面都会有一些信息字段,例如产品和运费。
您还需要熟悉浏览器的开发者工具。右键单击包含您感兴趣的数据的HTML元素,然后选择“检查”。会打开以下窗口:
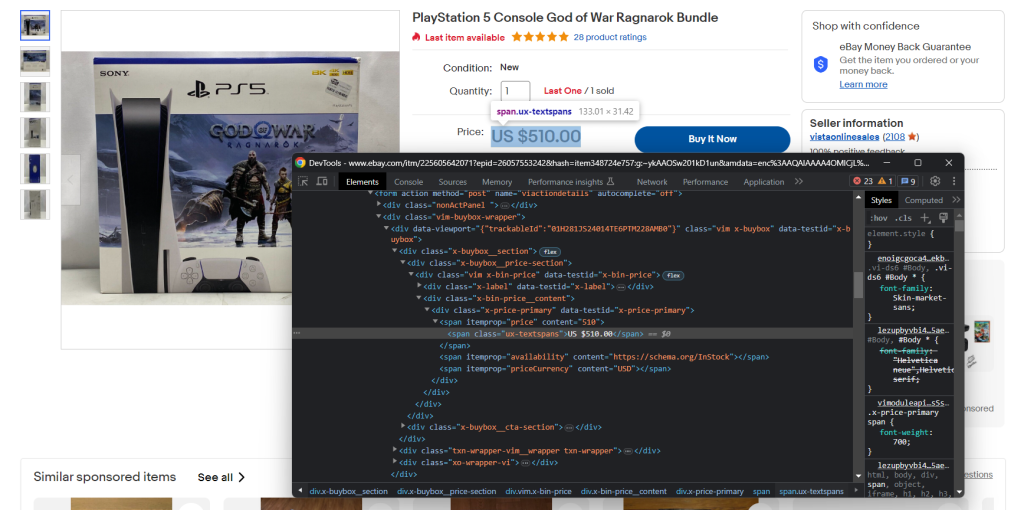
在这里,您可以探索页面的DOM结构并了解如何定义有效的选择器策略。
这里需要您花点时间,使用开发工具检查产品页面。
第 6 步:提取价格数据
首先,您需要一个数据结构来存储要抓取的数据。请使用以下命令初始化Python 字典:
item = {}您在上一步可能已经注意到了,价格数据位于以下部分:
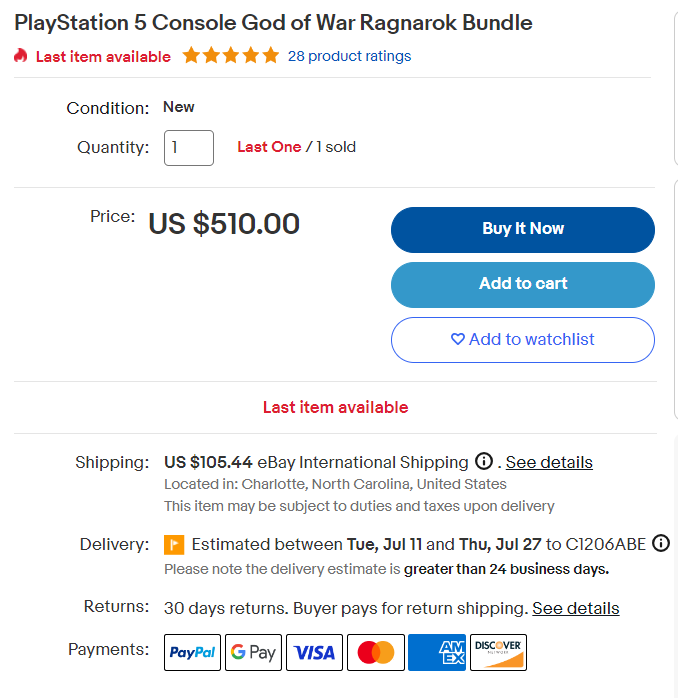
检查HTML价格元素:
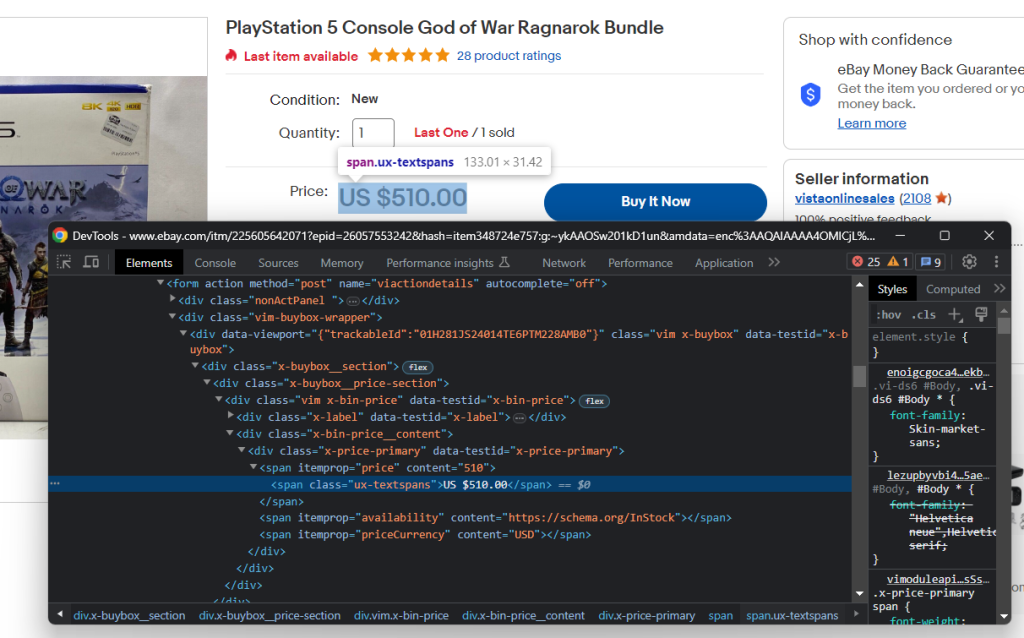
您可以使用以下CSS选择器获取产品价格:
.x-price-primary span[itemprop="price"]
And the currency with:
.x-price-primary span[itemprop="priceCurrency"]
Apply those selectors in Beautiful Soup and retrieve the desired data with:
price_html_element = soup.select_one('.x-price-primary span[itemprop="price"]')
price = price_html_element['content']
currency_html_element = soup.select_one('.x-price-primary span[itemprop="priceCurrency"]')
currency = currency_html_element['content']此代码片段选择了价格和货币HTML元素,然后采集了其内容属性中包含的字符串。
请记住,上文抓取的价格数据只是您购买所需商品时需要支付的部分价格,总价还包括运费。
检查运输元素:
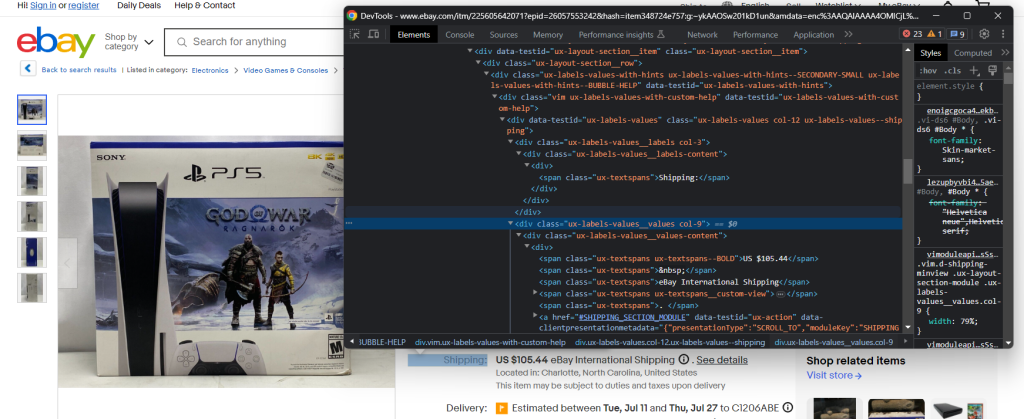
由于缺少容易获得元素的CSS选择器,这次要提取数据有些困难。您需要迭代每个.ux-labels-values__labels div。当前元素包含“ Shipping :”字符串时,您可以访问DOM中的下一个兄弟元素,并从.ux-textspans–BOLD中提取价格:
label_html_elements = soup.select('.ux-labels-values__labels')
for label_html_element in label_html_elements:
if 'Shipping:' in label_html_element.text:
shipping_price_html_element = label_html_element.next_sibling.select_one('.ux-textspans--BOLD')
# if there is a shipping price HTML element
if shipping_price_html_element is not None:
# extract the float number of the price from
# the text content
shipping_price = re.findall("d+[.,]d+", shipping_price_html_element.text)[0]
break运费元素按照以下格式呈现所需数据:
US $105.44要提取价格,您可以使用带re.findall()方法的正则表达式。记得在脚本的导入部分添加以下行:
import re
Add the collected data to the item dictionary:
item['price'] = price
item['shipping_price'] = shipping_price
item['currency'] = currency
Print it with:
print(item)
And you will get:
{'price': '499.99', 'shipping_price': '72.58', 'currency': 'USD'}在Python中实现价格跟踪流程,做到上述步骤就够了。不过eBay产品页面上还有很多其他有用的信息。所以,如何提取信息也值得了解!
第7步:检索商品详细信息
如果您查看“关于此商品”选项卡,您会发现其中包含许多有趣的数据:
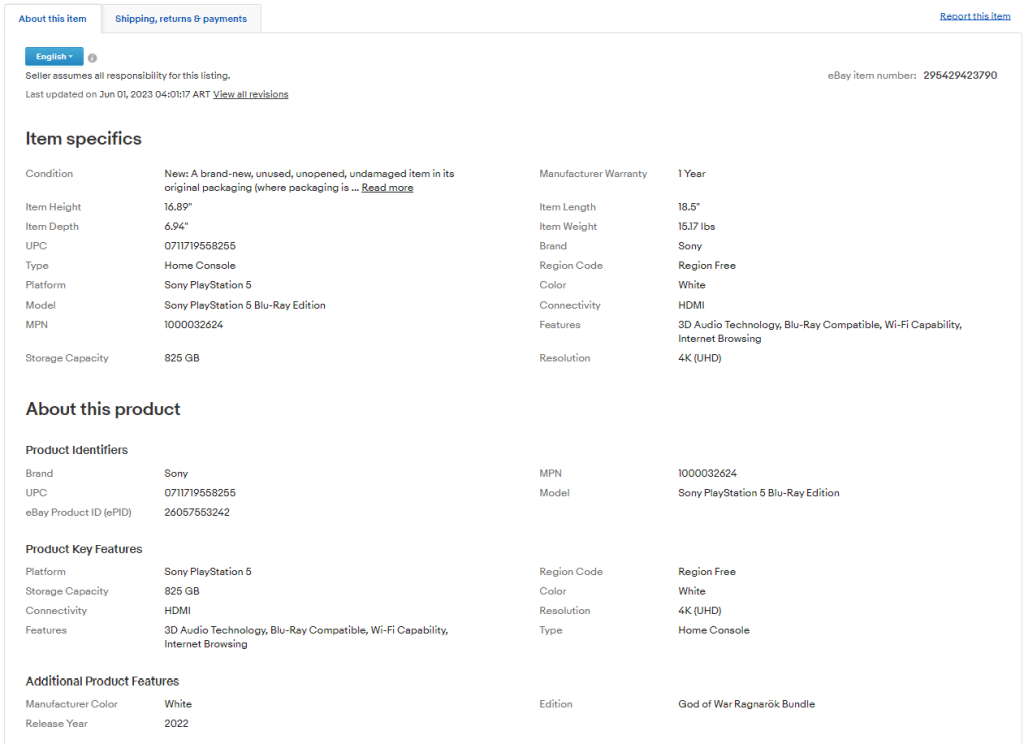
商品内部的部分和字段会因产品而异,因此需要您找到一种智能的方法来获取信息。
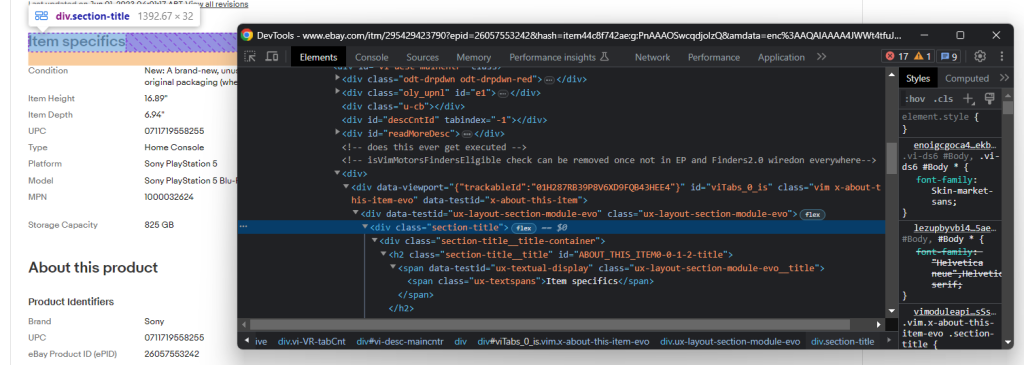
具体来说,最重要的部分是“商品详情”和“关于产品”。这两种信息存在于大多数产品中。您可以通过以下方式选择并检查其中之一:.section-title
选择一个部分后,探索其DOM结构:
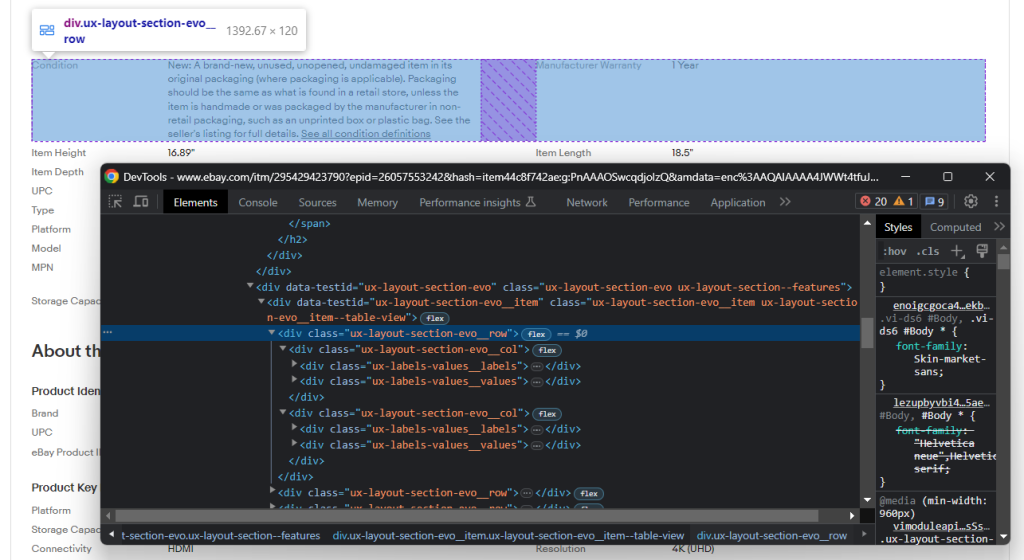
请注意,DOM结构包含多个行,每行都有一些.ux-layout-section-evo__col元素,共包含两个元素:
- .ux-labels-values__labels:属性名称。
- .ux-labels-values__values:属性值。
到这一步,您已经准备好以编程方式抓取所有详细部分信息:
section_title_elements = soup.select('.section-title')
for section_title_element in section_title_elements:
if 'Item specifics' in section_title_element.text or 'About this product' in section_title_element.text:
# get the parent element containing the entire section
section_element = section_title_element.parent
for section_col in section_element.select('.ux-layout-section-evo__col'):
print(section_col.text)
col_label = section_col.select_one('.ux-labels-values__labels')
col_value = section_col.select_one('.ux-labels-values__values')
# if both elements are present
if col_label is not None and col_value is not None:
item[col_label.text] = col_value.text此代码遍历每个HTML详细字段元素,并将与每个产品属性关联的键-值对添加到item字典中(存储商品信息)。
在for循环结束时,item将包含以下内容:
{'price': '499.99', 'shipping_price': '72.58', 'currency': 'USD', 'Condition': "New: A brand-new, unused, unopened, undamaged item in its original packaging (where packaging is applicable). Packaging should be the same as what is found in a retail store, unless the item is handmade or was packaged by the manufacturer in non-retail packaging, such as an unprinted box or plastic bag. See the seller's listing for full details. See all condition definitionsopens in a new window or tab ", 'Manufacturer Warranty': '1 Year', 'Item Height': '16.89"', 'Item Length': '18.5"', 'Item Depth': '6.94"', 'Item Weight': '15.17 lbs', 'UPC': '0711719558255', 'Brand': 'Sony', 'Type': 'Home Console', 'Region Code': 'Region Free', 'Platform': 'Sony PlayStation 5', 'Color': 'White', 'Model': 'Sony PlayStation 5 Blu-Ray Edition', 'Connectivity': 'HDMI', 'MPN': '1000032624', 'Features': '3D Audio Technology, Blu-Ray Compatible, Wi-Fi Capability, Internet Browsing', 'Storage Capacity': '825 GB', 'Resolution': '4K (UHD)', 'eBay Product ID (ePID)': '26057553242', 'Manufacturer Color': 'White', 'Edition': 'God of War Ragnarök Bundle', 'Release Year': '2022'}非常好!您已经成功完成数据检索!
第 8 步:将抓取的数据导出为JSON
抓取的数据目前存储在Python字典中。为了使其更易于共享和阅读,您可以将其导出为JSON格式,以下是操作步骤:
import json
# scraping logic...
with open('product_info.json', 'w') as file:
json.dump(item, file)首先,您需要使用open()初始化一个名为Product_info.json文件。然后,您可以使用json.dump()将item字典的JSON表示格式写入输出文件。请参阅此文,了解更多关于如何在Python中解析数据并将其序列化为JSON的内容。
json 包来自 Python 标准库,因此您甚至不需要安装额外的依赖项来实现目标。
太棒了!您从网页中的原始数据开始,现在得到了半结构化的JSON数据。现在我们来看看整个eBay爬虫的完整代码。
第 9 步:将所有内容组合在一起
以下是完整的scraper.py脚本:
import requests
from bs4 import BeautifulSoup
import sys
import re
import json
# if there are no CLI parameters
if len(sys.argv) <= 1:
print('Item ID argument missing!')
sys.exit(2)
# read the item ID from a CLI argument
item_id = sys.argv[1]
# build the URL of the target product page
url = f'https://www.ebay.com/itm/{item_id}'
# download the target page
page = requests.get(url)
# parse the HTML document returned by the server
soup = BeautifulSoup(page.text, 'html.parser')
# initialize the object that will contain
# the scraped data
item = {}
# price scraping logic
price_html_element = soup.select_one('.x-price-primary span[itemprop="price"]')
price = price_html_element['content']
currency_html_element = soup.select_one('.x-price-primary span[itemprop="priceCurrency"]')
currency = currency_html_element['content']
shipping_price = None
label_html_elements = soup.select('.ux-labels-values__labels')
for label_html_element in label_html_elements:
if 'Shipping:' in label_html_element.text:
shipping_price_html_element = label_html_element.next_sibling.select_one('.ux-textspans--BOLD')
# if there is not a shipping price HTML element
if shipping_price_html_element is not None:
# extract the float number of the price from
# the text content
shipping_price = re.findall("d+[.,]d+", shipping_price_html_element.text)[0]
break
item['price'] = price
item['shipping_price'] = shipping_price
item['currency'] = currency
# product detail scraping logic
section_title_elements = soup.select('.section-title')
for section_title_element in section_title_elements:
if 'Item specifics' in section_title_element.text or 'About this product' in section_title_element.text:
# get the parent element containing the entire section
section_element = section_title_element.parent
for section_col in section_element.select('.ux-layout-section-evo__col'):
print(section_col.text)
col_label = section_col.select_one('.ux-labels-values__labels')
col_value = section_col.select_one('.ux-labels-values__values')
# if both elements are present
if col_label is not None and col_value is not None:
item[col_label.text] = col_value.text
# export the scraped data to a JSON file
with open('product_info.json', 'w') as file:
json.dump(item, file, indent=4)只需不到 70 行代码,您就可以构建一个监控eBay产品数据的网络爬虫。
例如,针对ID 225605642071标识的商品启动爬虫:
python scraper.py 225605642071抓取过程结束时,项目的根文件夹中会出现如下的product_info.json文件:
{
"price": "499.99",
"shipping_price": "72.58",
"currency": "USD",
"Condition": "New: A brand-new, unused, unopened, undamaged item in its original packaging (where packaging is applicable). Packaging should be the same as what is found in a retail store, unless the item is handmade or was packaged by the manufacturer in non-retail packaging, such as an unprinted box or plastic bag. See the seller's listing for full details",
"Manufacturer Warranty": "1 Year",
"Item Height": "16.89"",
"Item Length": "18.5"",
"Item Depth": "6.94"",
"Item Weight": "15.17 lbs",
"UPC": "0711719558255",
"Brand": "Sony",
"Type": "Home Console",
"Region Code": "Region Free",
"Platform": "Sony PlayStation 5",
"Color": "White",
"Model": "Sony PlayStation 5 Blu-Ray Edition",
"Connectivity": "HDMI",
"MPN": "1000032624",
"Features": "3D Audio Technology, Blu-Ray Compatible, Wi-Fi Capability, Internet Browsing",
"Storage Capacity": "825 GB",
"Resolution": "4K (UHD)",
"eBay Product ID (ePID)": "26057553242",
"Manufacturer Color": "White",
"Edition": "God of War Ragnarok Bundle",
"Release Year": "2022"
}恭喜!您已经学会了如何使用Python抓取eBay页面!
结论
在本指南中,您了解了为什么eBay是跟踪产品价格的最佳抓取目标以及如何抓取eBay。具体而言,您了解了如何根据分步教程构建可检索项目数据的Python爬虫。正如本文所示,这并不复杂,只需几行代码即可完成。
同时,您也了解了eBay多变的页面结构。因此,此处构建的爬虫可能仅适用于某一种产品。此外,eBay的用户界面经常变化,这迫使您必须不断维护脚本。好在您可以使用我们的eBay爬虫来避免这种情况!
如果您想批量抓取过程并从其他电子商务平台提取价格,请记住,许多平台严重依赖JavaScript。因此,在应对此类网站时,基于HTML解析器的传统方法无法奏效。您需要一个工具来渲染 JavaScript,自动处理指纹识别、CAPTCHA验证码和自动重试。我们最新的亮数据浏览器解决方案正是为此而生!
如果您不想自己抓取eBay网页,但又对商品数据感兴趣,可以选择购买eBay数据集。



技术写作
 5.5 years experience
5.5 years experience
Antonello是一名软件工程师,但他更喜欢称自己为技术传教士。通过写作传播知识是他的使命。




