
如果你对网页抓取感兴趣,Crawlee 能帮助你。它是一个快速、互动的抓取引擎,被数据科学家、开发者和研究人员用于收集网页数据。Crawlee 易于设置,提供了代理轮换和会话管理等功能。这些功能对于抓取大型或动态网站而不被封 IP 至关重要,确保数据收集的流畅和不中断。
在本教程中,你将学习如何使用 Crawlee 进行网页抓取。你将从一个基本的网页抓取示例开始,逐步掌握会话管理和动态页面抓取等更高级的概念。
如何使用 Crawlee 进行网页抓取
在开始本教程之前,请确保你的电脑上已安装以下先决条件:
- Node.js。
- npm: 通常与 Node.js 一起安装。你可以通过在终端运行
node -v或npm -v来验证安装。 - 一个你喜欢的代码编辑器: 本教程使用Visual Studio Code。
使用 Crawlee 进行基本的网页抓取
当你具备了所有先决条件后,让我们从抓取 Books to Scrape 网站开始学习,它的 HTML 结构非常简单,非常适合学习。
打开你的终端或 Shell,使用以下命令初始化一个 Node.js 项目:
mkdir crawlee-tutorial
cd crawlee-tutorial
npm init -y然后,使用以下命令安装 Crawlee 库:
npm install crawlee为了有效地从任何网站抓取数据,你需要检查想要抓取的网站的 HTML 标签细节。为此,请在浏览器中打开该网站,并通过右键单击网页上的任意位置导航到开发者工具。然后点击检查或检查元素:
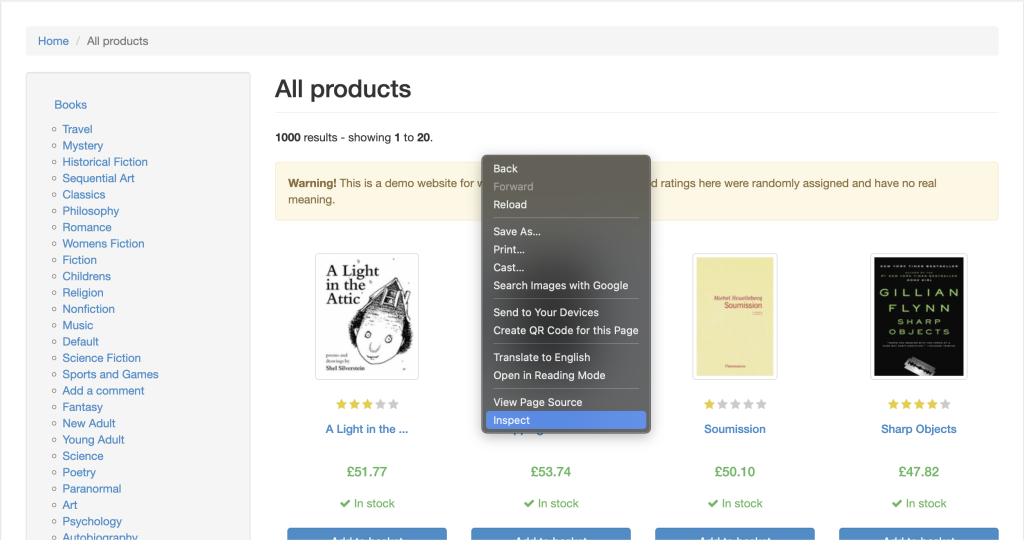
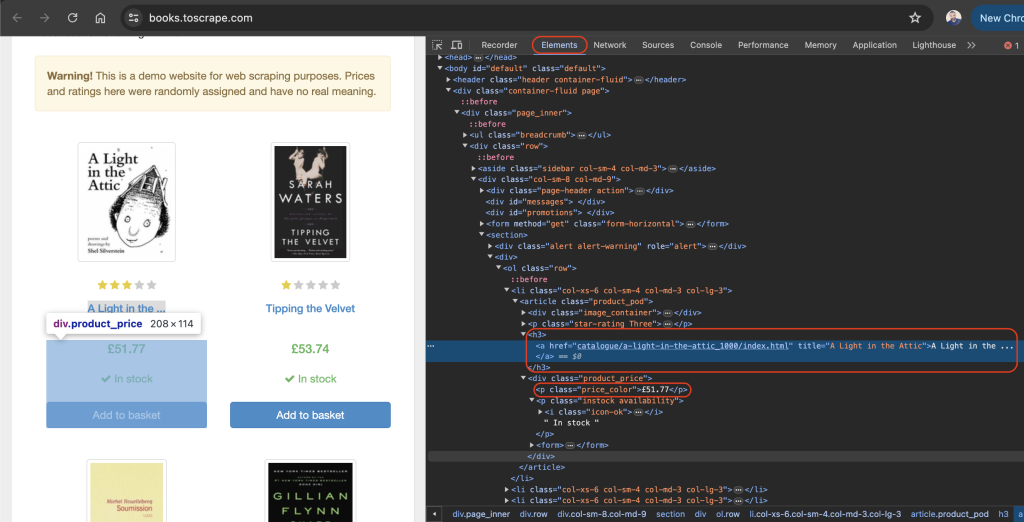
元素标签应该默认处于活动状态,这个标签表示网页的 HTML 布局。在这个例子中,每一本书都被放置在一个带有 product_pod 类的 article HTML 标签中。在每篇文章中,书名包含在 h3 标签中。书的实际标题包含在 h3 元素中的 a 标签的 title 属性中。书的价格位于带有 price_color 类的 p 标签中:
在项目的根目录下,创建一个名为 scrape.js 的文件,并添加以下代码:
const { CheerioCrawler } = require('crawlee');
const crawler = new CheerioCrawler({
async requestHandler({ request, $ }) {
const books = [];
$('article.product_pod').each((index, element) => {
const title = $(element).find('h3 a').attr('title');
const price = $(element).find('.price_color').text();
books.push({ title, price });
});
console.log(books);
},
});
crawler.run(['https://books.toscrape.com/']);在这段代码中,你使用 crawlee 中的 CheerioCrawler 来从 https://books.toscrape.com/ 抓取书名和价格。爬虫获取 HTML 内容,使用类似 jQuery 的语法从 <article class="product_pod"> 元素中提取数据,并将结果打印到控制台。
将前面的代码添加到你的 scrape.js 文件后,可以使用以下命令运行代码:
node scrape.js书名和价格的数组应打印到你的终端中:
…output omitted…
{
title: 'The Boys in the Boat: Nine Americans and Their Epic Quest for Gold at the 1936 Berlin Olympics',
price: '£22.60'
},
{ title: 'The Black Maria', price: '£52.15' },
{
title: 'Starving Hearts (Triangular Trade Trilogy, #1)',
price: '£13.99'
},
{ title: "Shakespeare's Sonnets", price: '£20.66' },
{ title: 'Set Me Free', price: '£17.46' },
{
title: "Scott Pilgrim's Precious Little Life (Scott Pilgrim #1)",
price: '£52.29'
},
…output omitted…使用 Crawlee 进行代理轮换
代理是你计算机与互联网之间的中间人。使用代理时,它将你的网络请求发送到代理服务器,代理服务器再将请求转发到目标网站。代理服务器将网站的响应发送回来,并隐藏你的 IP 地址,防止你被限速或封 IP。
Crawlee 使代理的实现变得简单,因为它内置了代理处理功能,能够有效地处理重试和错误。Crawlee 还支持一系列代理配置来实现代理轮换。
在接下来的部分中,你将通过首先获得一个有效的代理来设置代理。然后,你将验证你的请求是否通过代理发送。
设置代理
免费代理通常不推荐使用,因为它们可能速度慢且不安全,无法支持敏感的网页任务。相反,考虑使用Bright Data,这是一项安全、稳定且可靠的代理服务。它还提供免费试用,因此你可以在提交前进行测试。
要使用 Bright Data,请点击他们主页上的开始免费试用按钮,并填写所需信息创建一个账户。
账户创建完成后,登录 Bright Data 仪表板,导航到代理与抓取基础设施,并通过选择住宅代理添加一个新的代理:
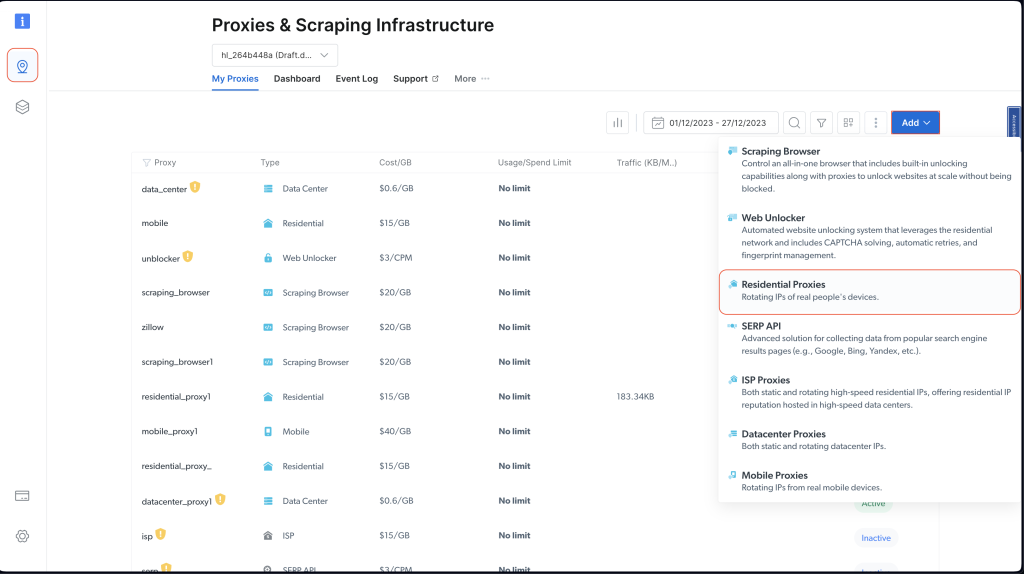
保留默认设置,并通过点击添加来完成住宅代理的创建。
如果系统提示你安装证书,你可以选择继续不安装证书。但是对于生产和实际用例,你应该设置证书,以防你的代理信息被泄露时防止滥用。
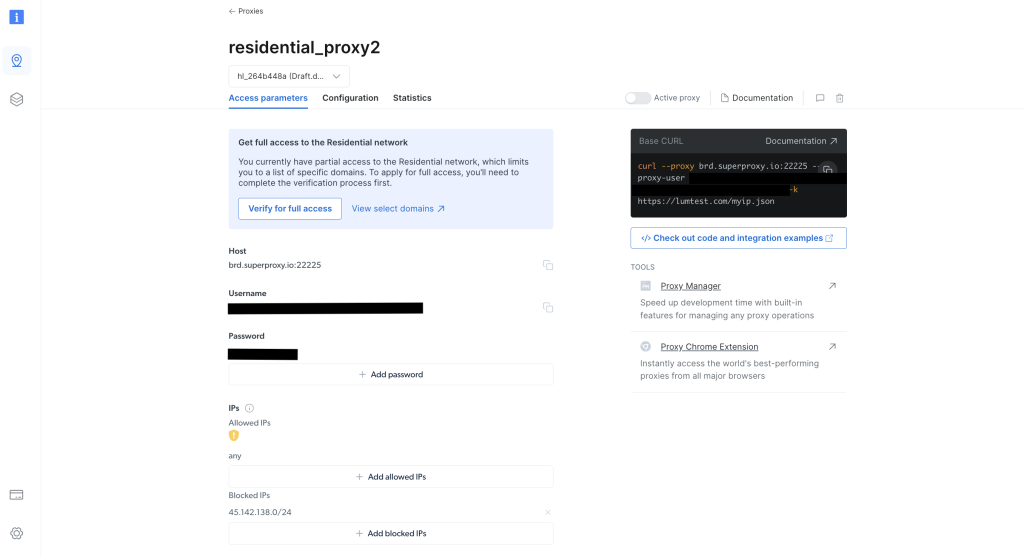
创建完成后,请注意代理凭据,包括主机、端口、用户名和密码。你将在下一步中使用这些信息:
在项目的根目录下,运行以下命令安装axios库:
npm install axios你将使用 axios 库发送 GET 请求到 http://lumtest.com/myip.json,每次运行脚本时,它都会返回你正在使用的代理的详细信息。
接下来,在项目的根目录下,创建一个名为 scrapeWithProxy.js 的文件,并添加以下代码:
const { CheerioCrawler } = require("crawlee");
const { ProxyConfiguration } = require("crawlee");
const axios = require("axios");
const proxyConfiguration = new ProxyConfiguration({
proxyUrls: ["http://USERNAME:PASSWORD@HOST:PORT"],
});
const crawler = new CheerioCrawler({
proxyConfiguration,
async requestHandler({ request, $, response, proxies }) {
// Make a GET request to the proxy information URL
try {
const proxyInfo = await axios.get("http://lumtest.com/myip.json", {
proxy: {
host: "HOST",
port: PORT,
auth: {
username: "USERNAME",
password: "PASSWORD",
},
},
});
console.log("Proxy Information:", proxyInfo.data);
} catch (error) {
console.error("Error fetching proxy information:", error.message);
}
const books = [];
$("article.product_pod").each((index, element) => {
const title = $(element).find("h3 a").attr("title");
const price = $(element).find(".price_color").text();
books.push({ title, price });
});
console.log(books);
},
});
crawler.run(["https://books.toscrape.com/"]);注意:确保用你的凭据替换
HOST、PORT、USERNAME和PASSWORD。
在这段代码中,你使用 crawlee 中的 CheerioCrawler 来通过指定的代理抓取 https://books.toscrape.com/ 的信息。你通过 ProxyConfiguration 配置代理;然后,通过发送 GET 请求到 http://lumtest.com/myip.json 来获取并记录代理详情。最后,你使用 Cheerio 类似 jQuery 的语法提取书名和价格,并将抓取的数据记录到控制台中。
现在你可以运行并测试代码,以确保代理工作正常:
node scrapeWithProxy.js你将看到类似之前的结果,但这次你的请求是通过 Bright Data 代理发送的。你还应该在控制台中看到记录的代理详情:
Proxy Information: {
country: 'US',
asn: { asnum: 21928, org_name: 'T-MOBILE-AS21928' },
geo: {
city: 'El Paso',
region: 'TX',
region_name: 'Texas',
postal_code: '79925',
latitude: 31.7899,
longitude: -106.3658,
tz: 'America/Denver',
lum_city: 'elpaso',
lum_region: 'tx'
}
}
[
{ title: 'A Light in the Attic', price: '£51.77' },
{ title: 'Tipping the Velvet', price: '£53.74' },
{ title: 'Soumission', price: '£50.10' },
{ title: 'Sharp Objects', price: '£47.82' },
{ title: 'Sapiens: A Brief History of Humankind', price: '£54.23' },
{ title: 'The Requiem Red', price: '£22.65' },
…output omitted..如果你再次运行 node scrapingWithBrightData.js 脚本,你应该会看到 Bright Data 代理服务器使用了不同的 IP 地址位置。这验证了 Bright Data 在你每次运行抓取脚本时轮换位置和 IP。这种轮换对于绕过目标网站的封锁或 IP 禁令非常重要。
注意:在
proxyConfiguration中,你可以传递不同的代理 IP,但由于 Bright Data 会为你处理这个问题,你不需要指定 IP。
使用 Crawlee 进行会话管理
会话有助于在多个请求之间保持状态,这对于使用 cookie 或登录会话的网站非常有用。
要管理会话,在项目的根目录下创建一个名为 scrapeWithSessions.js 的文件,并添加以下代码:
const { CheerioCrawler, SessionPool } = require("crawlee");
(async () => {
// Open a session pool
const sessionPool = await SessionPool.open();
// Ensure there is a session in the pool
let session = await sessionPool.getSession();
if (!session) {
session = await sessionPool.createSession();
}
const crawler = new CheerioCrawler({
useSessionPool: true, // Enable session pool
async requestHandler({ request, $, response, session }) {
// Log the session information
console.log(`Using session: ${session.id}`);
// Extract book data and log it (for demonstration)
const books = [];
$("article.product_pod").each((index, element) => {
const title = $(element).find("h3 a").attr("title");
const price = $(element).find(".price_color").text();
books.push({ title, price });
});
console.log(books);
},
});
// First run
await crawler.run(["https://books.toscrape.com/"]);
console.log("First run completed.");
// Second run
await crawler.run(["https://books.toscrape.com/"]);
console.log("Second run completed.");
})();在这里,你使用 crawlee 中的 CheerioCrawler 和 SessionPool 来抓取 https://books.toscrape.com/ 的数据。你初始化一个会话池,然后配置爬虫使用这个会话。requestHandler 函数记录会话信息,并使用 Cheerio 类似 jQuery 的选择器提取书名和价格。代码进行两次连续抓取,并记录每次运行的会话 ID。
运行并测试代码,以验证使用了不同的会话:
node scrapeWithSessions.js你应该会看到类似之前的结果,但这次你还应该看到每次运行的会话 ID:
Using session: session_GmKuZ2TnVX
[
{ title: 'A Light in the Attic', price: '£51.77' },
{ title: 'Tipping the Velvet', price: '£53.74' },
…output omitted…
Using session: session_lNRxE89hXu
[
{ title: 'A Light in the Attic', price: '£51.77' },
{ title: 'Tipping the Velvet', price: '£53.74' },
…output omitted…如果你再次运行代码,你应该会看到使用了不同的会话 ID。
使用 Crawlee 处理动态内容
如果你在处理动态网站(即由 JavaScript 填充内容的网站),网页抓取可能会非常具有挑战性,因为你需要渲染 JavaScript 才能访问数据。为了处理这些情况,Crawlee 集成了Puppeteer,这是一种无头浏览器,可以渲染 JavaScript 并像人类一样与目标网站进行交互。
为了演示此功能,让我们从这个 YouTube 页面抓取内容。如往常一样,在抓取任何内容之前,请确保你已经审查了该页面的规则和服务条款。
在审查了服务条款后,在项目的根目录下创建一个名为 scrapeDynamicContent.js 的文件,并添加以下代码:
const { PuppeteerCrawler } = require("crawlee");
async function scrapeYouTube() {
const crawler = new PuppeteerCrawler({
async requestHandler({ page, request, enqueueLinks, log }) {
const { url } = request;
await page.goto(url, { waitUntil: "networkidle2" });
// Scraping first 10 comments
const comments = await page.evaluate(() => {
return Array.from(document.querySelectorAll("#comments #content-text"))
.slice(0, 10)
.map((el) => el.innerText);
});
log.info(`Comments: ${comments.join("n")}`);
},
launchContext: {
launchOptions: {
headless: true,
},
},
});
// Add the URL of the YouTube video you want to scrape
await crawler.run(["https://www.youtube.com/watch?v=wZ6cST5pexo"]);
}
scrapeYouTube();然后使用以下命令运行代码:
node scrapeDynamicContent.js在这段代码中,你使用 Crawlee 库中的 PuppeteerCrawler 来抓取 YouTube 视频评论。首先初始化一个爬虫,该爬虫导航到特定的 YouTube 视频 URL 并等待页面完全加载。页面加载后,代码评估页面内容,选择具有指定 CSS 选择器 #comments #content-text 的元素,提取前十条评论。然后将评论记录到控制台中。
你的输出应包括与所选视频相关的前十条评论:
INFO PuppeteerCrawler: Starting the crawler.
INFO PuppeteerCrawler: Comments: Who are you rooting for?? US Marines or Ex Cons
Bro Mateo is a beast, no lifting straps, close stance.
ex convict doing the pushups is a monster.
I love how quick this video was, without nonsense talk and long intros or outros
"They Both have combat experience" is wicked
That military guy doing that deadlift is really no joke.. ...
One lives to fight and the other fights to live.
Finally something that would test the real outcome on which narrative is true on movies
I like the comradery between all of them. Especially on the Bench Press ... Both team members quickly helped out on the spotting to protect from injury. Well done.
I like this style, no youtube funny business. Just straight to the lifts
…output omitted…你可以在GitHub 上找到本教程中使用的所有代码。
结论
在本文中,你学习了如何使用 Crawlee 进行网页抓取,并了解了它如何帮助提高你网页抓取项目的效率和可靠性。
记住,在抓取数据时,始终要遵守目标网站的robots.txt 文件和服务条款。
准备好通过专业级的数据、工具和代理来提升你的网页抓取项目了吗?探索 Bright Data 综合的网页抓取平台,提供现成的数据集和高级代理服务,以简化你的数据收集工作。
立即注册并开始你的免费试用!







