
网页抓取是从网页中提取数据的过程。数据有多种形式,文本抓取一词是特指文本数据的收集。
要做出成功的商业决策,必须拥有大量的相关数据。从竞争对手的网站抓取信息可以让您洞悉其业务逻辑,这有助于您获得竞争优势。在本教程中,您将会了解到如何在Python中实行文本抓取工具,以轻松提取和使用网络数据。
先决条件
在开始本教程之前,需要具备以下先决条件:
- 您的系统已安装最新版本的Python和pip。
- 一个Python虚拟环境。确保在虚拟环境中已安装了所有必需的软件包,包括用于获取网页HTML内容的requests、用于解析并从HTML中提取所需文本或数据的Beautiful Soup,以及用于整理所提取的数据并将其存储为CSV文件等结构化格式的pandas。
如果您正在寻找更多信息来帮助您开始使用Python抓取网页,请查看这篇文章。
了解网站结构
在开始抓取之前,您需要分析目标网站的结构。网站使用HTML构建,HTML是一种标记语言,内容的组织和显示方式由其定义。
每部分的内容(标题、段落或链接等)均包含在HTML标签中。这些标签可帮助您识别要抓取的数据位于何处。例如,在此示例中,您要从模拟网站Quotes to Scrape中抓取引文 。要查看此网站的结构,您需要在浏览器中打开此网站,然后右键单击网页,并选择检查或检查元素以访问开发者工具。此操作会展示该页面的HTML代码:
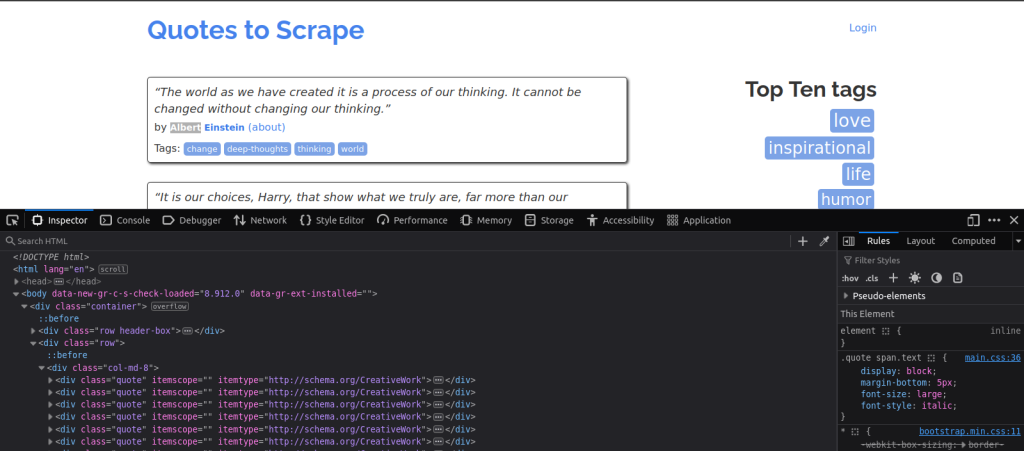
花点时间熟悉一下其结构──查找<div>、<span>、<p>和<a>等标签,因为这些标签通常包含您可能想要提取的文本或链接。另请注意,标签通常包含class属性。其目的是为该HTML元素定义一个特定的类,以便使用CSS对该元素进行样式设置,或使用JavaScript选择该元素。
注意:
class属性在文本抓取中特别有用,因为它可以帮助您针对网页中具有相同样式或结构的特定元素,让您能更轻松地提取所需的确切数据。
在这里,每段引文都包含在一个class为quote的div元素中。如果您对文本和每段引文的作者感兴趣的话,请注意,文本是包含在class为text的div元素中,作者则包含在class为author的一个small元素中:
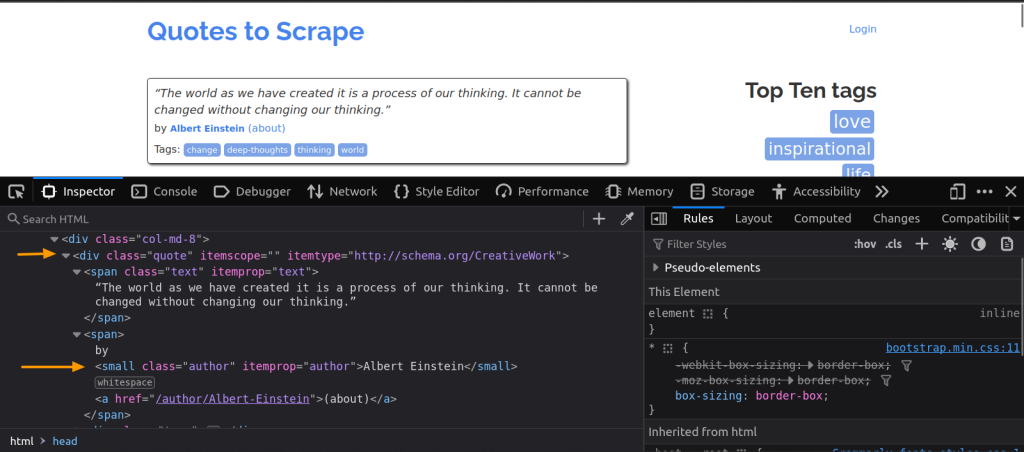
如果您不熟悉HTML的工作原理,请查看这篇HTML网页抓取文章,了解更多信息。
抓取网站文本
了解网站结构后,下一步是编写用于抓取Quotes to Scrape网站的代码。
Python是用来进行此任务的热门选择,因其易于使用并具有强大的库,包括requests和BeautifulSoup。您可以使用requests库来获取页面的HTML内容。这是必要的,因为您需要先检索原始数据,然后才能对其进行分析或提取。获得HTML内容后,您可以使用BeautifulSoup将其分解为更易于管理的结构。
首先,为文本抓取脚本创建一个名为text-scraper.py的Python文件。然后,导入BeautifulSoup和requests:
import requests
from bs4 import BeautifulSoup
指定您要抓取的网站的URL,并发送GET请求:
# URL of the quotes website
url = 'https://quotes.toscrape.com/'
# Send a GET request to the URL
response = requests.get(url)
发送GET请求后,您将收到整个网页的HTML。您必须对其进行解析以仅提取所需的数据,在本例中,所需的数据是文本和每段引文的作者。为此,您首先需要创建一个BeautifulSoup对象,以解析HTML:
soup = BeautifulSoup(response.text, 'html.parser')
查找所有包含引文的div元素(这意味着其class为quote):
quotes = soup.find_all('div', class_='quote')
创建一个列表来存储引文:
data = []
然后,从每段引文中提取文本和作者,并将其存储在data列表中:
for quote in quotes:
text = quote.find('span', class_='text').text.strip()
author = quote.find('small', class_='author').text.strip()
data.append({
'Text': text,
'Author': author
})
脚本应该看起来像这样:
import requests
from bs4 import BeautifulSoup
# URL of the quotes website
url = 'http://quotes.toscrape.com/'
# Send a GET request to the URL
response = requests.get(url)
# Create a BeautifulSoup object to parse the HTML
soup = BeautifulSoup(response.text, 'html.parser')
# Find all quote containers
quotes = soup.find_all('div', class_='quote')
# Extract data from each quote
data = []
for quote in quotes:
text = quote.find('span', class_='text').text.strip()
author = quote.find('small', class_='author').text.strip()
data.append({
'Text': text,
'Author': author
})
print(data)
现在,请在从终端运行脚本:
# For Linux and macOS
python3 text-scraper.py
# For Windows
python text-scraper.py
您应该会看到所提取的引文列表显示出来:
[{'Author': 'Albert Einstein',
'Text': '"The world as we have created it is a process of our thinking. It '
'cannot be changed without changing our thinking."'},
{'Author': 'J.K. Rowling',
'Text': '"It is our choices, Harry, that show what we truly are, far more '
'than our abilities."'},
{'Author': 'Albert Einstein',
'Text': '"There are only two ways to live your life. One is as though '
'nothing is a miracle. The other is as though everything is a '
'miracle."'},
{'Author': 'Jane Austen',
'Text': '"The person, be it gentleman or lady, who has not pleasure in a '
'good novel, must be intolerably stupid."'},
{'Author': 'Marilyn Monroe',
'Text': ""Imperfection is beauty, madness is genius and it's better to be "
'absolutely ridiculous than absolutely boring."'},
{'Author': 'Albert Einstein',
'Text': '"Try not to become a man of success. Rather become a man of '
'value."'},
{'Author': 'André Gide',
'Text': '"It is better to be hated for what you are than to be loved for '
'what you are not."'},
{'Author': 'Thomas A. Edison',
'Text': ""I have not failed. I've just found 10,000 ways that won't work.""},
{'Author': 'Eleanor Roosevelt',
'Text': '"A woman is like a tea bag; you never know how strong it is until '
"it's in hot water.""},
{'Author': 'Steve Martin',
'Text': '"A day without sunshine is like, you know, night."'}]
虽然这种文本抓取看起来颇为简单,但在网络抓取过程中您可能会遇到困难,例如IP被屏蔽(如果网站检测到请求过多),或者CAPTCHA验证码(用于阻止自动访问)。要克服这些困难,您可以使用代理。
使用代理进行匿名抓取
代理可以轮换您的IP地址,使您的请求看起来像来自不同的位置,从而帮助您避开和绕过IP屏蔽和CAPTCHA验证码。要使用代理,您需要配置request.get()方法,使所有请求都通过代理服务器路由。
在这种情况下,您可以采用Bright Data轮换代理,让您可以使用来自超过195个国家/地区的超过7200多万个IP地址。首先,在右上角选择开始免费试用、填写注册表,然后点击创建账户,创建一个免费的Bright Data账户:
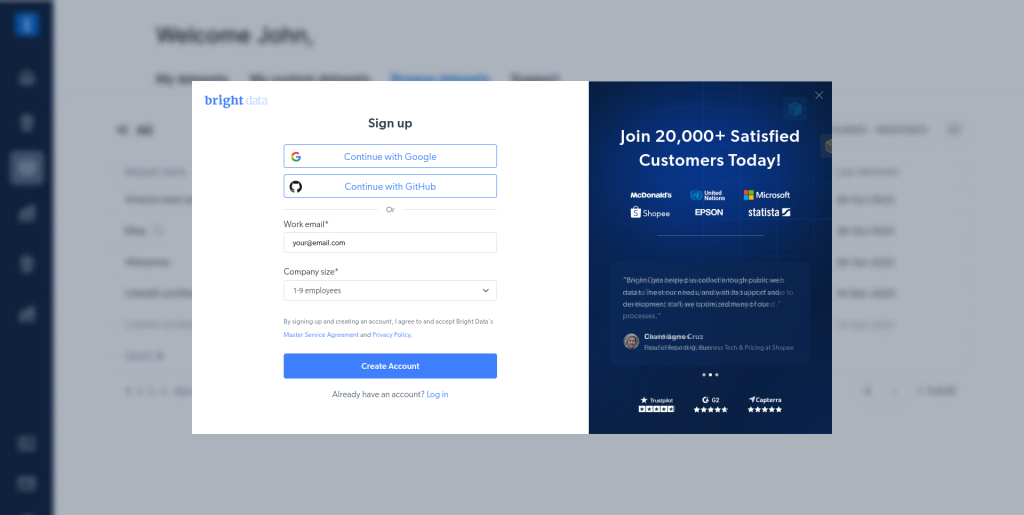
创建基本住宅代理
创建Bright Data账户后,登录账户,然后前往代理和抓取部分。在代理网络部分中,找到住宅代理,然后点击开始:
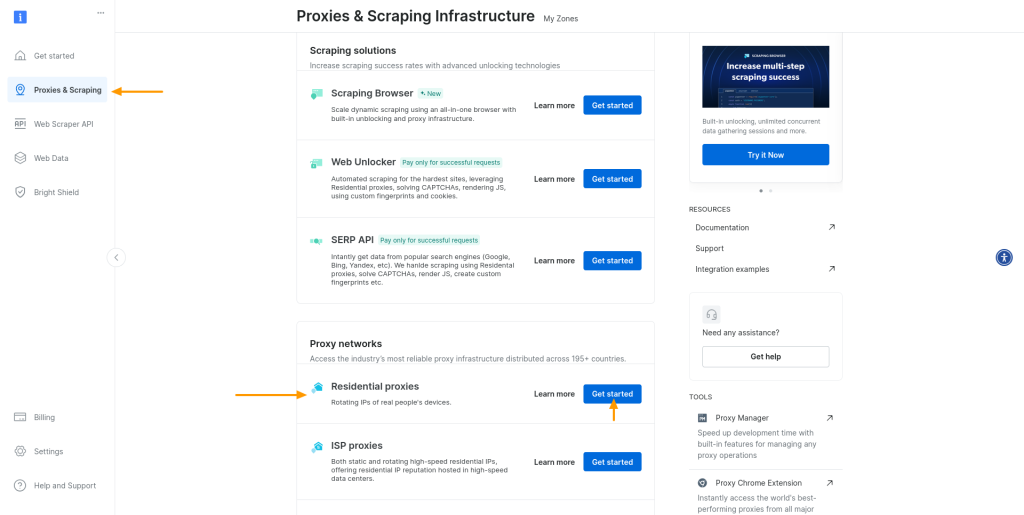
系统会提示您为住宅代理添加新区域。保留所有默认设置,为区域命名,然后点击添加:
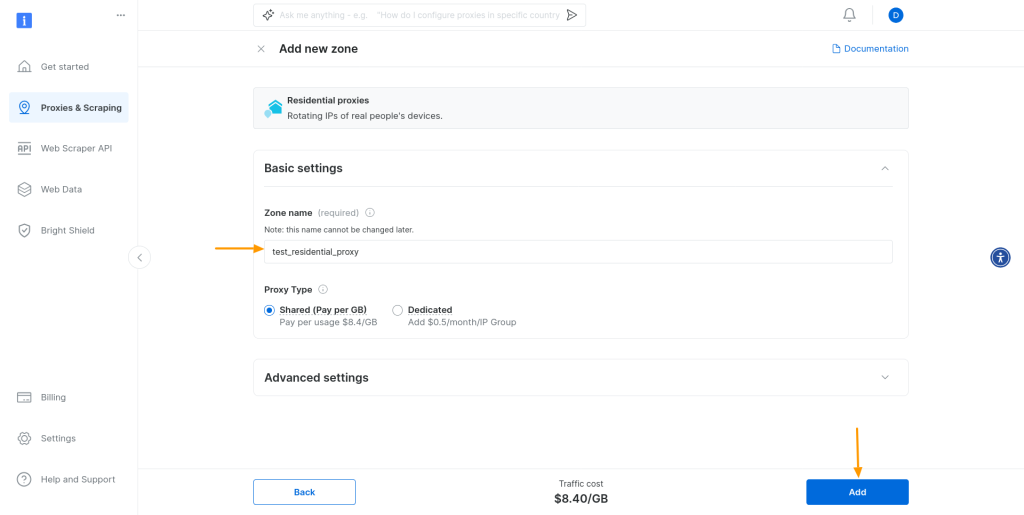
这就是创建新的住宅代理区域所需的全部操作!
要使用代理,您需要您的凭据(即用户名、密码和主机)。要查找这些凭据,请再次前往代理和抓取部分,然后选择您刚刚创建的代理区域:
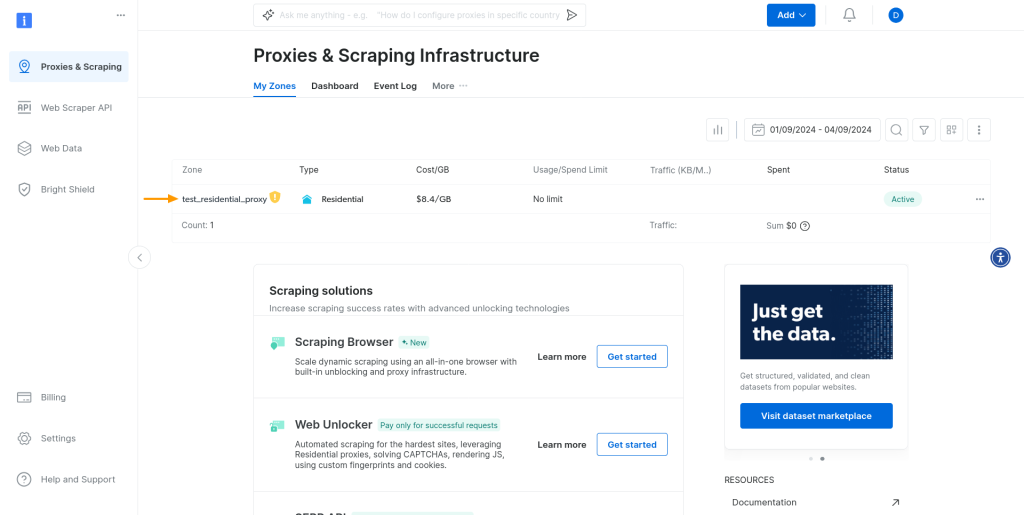
点击代理区域后,就会看到区域控制面板。在授权部分中,您会看到您的凭据:
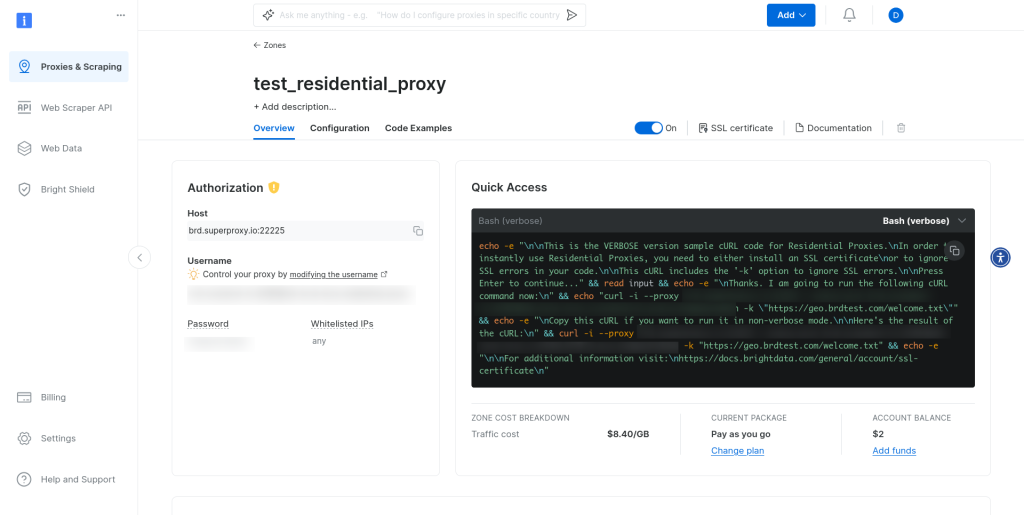
更新抓取脚本
现在您有了代理凭据,可以进行代理配置了。首先,将您的凭据存储为变量:
host = 'brd.superproxy.io'
port = 22225
username = 'brd-customer-<customer_id>-zone-<zone_name>'
password = '<zone_password>'
然后,用存储的凭据组成代理URL:
proxy_url = f'http://{username}:{password}@{host}:{port}'
为HTTP和HTTPS请求创建代理配置:
proxies = {
'http': proxy_url,
'https': proxy_url
}
并将代理配置添加到现有的requests.get()调用中:
response = requests.get(url, proxies=proxies)
此时,脚本应如下所示:
import requests
from bs4 import BeautifulSoup
# BrightData credentials
host = 'brd.superproxy.io'
port = 22225
username = 'brd-customer-<customer_id>-zone-<zone_name>'
password = '<zone_password>'
# Compose a proxy URL
proxy_url = f'http://{username}:{password}@{host}:{port}'
# Create a proxy configuration
proxies = {
'http': proxy_url,
'https': proxy_url
}
# URL of the quotes website
url = 'http://quotes.toscrape.com/'
# Send a GET request to the URL via the specified proxy
response = requests.get(url, proxies=proxies)
# Create a BeautifulSoup object to parse the HTML
soup = BeautifulSoup(response.text, 'html.parser')
# Find all quote containers
quotes = soup.find_all('div', class_='quote')
# Extract data from each quote
data = []
for quote in quotes:
text = quote.find('span', class_='text').text.strip()
author = quote.find('small', class_='author').text.strip()
data.append({
'Text': text,
'Author': author
})
print(data)
运行并测试脚本
运行此脚本会得到与无代理脚本相同的结果。不同之处在于,您正在抓取的网站现在会以为您是从其他地方发送请求,所以您的实际位置是保密的。让我们编写一个新的简单脚本,以说明这一点。
导入必要的库,并在脚本中将url设置为“http://lumtest.com/myip.json”:
import requests
from bs4 import BeautifulSoup
url = "http://lumtest.com/myip.json"
在未配置代理的情况下向url发送GET请求,并为响应创建BeautifulSoup对象:
# Send a GET request to the URL
response = requests.get(url)
# Create a BeautifulSoup object to parse the HTML
soup = BeautifulSoup(response.text, 'html.parser')
最后,显示soup:
print(soup)
运行这个脚本。然后,您将获得响应,内有关于您的IP地址和位置的信息。
要进行比较,请将GET请求配置为使用Bright Data代理,其他一切则保持不变:
# BrightData credentials
host = 'brd.superproxy.io'
port = 22225
username = 'brd-customer-hl_459f8bd4-zone-test_residential_proxy'
password = '8sdgouh1dq5h'
proxy_url = f'http://{username}:{password}@{host}:{port}'
proxies = {
'http': proxy_url,
'https': proxy_url
}
# Send a GET request to the URL
response = requests.get(url, proxies=proxies)
当您运行更新后的脚本时,所获得的响应中的IP地址会不同;这不是您的实际IP,而是您设置的代理的IP地址。基本上,您是将自己的IP地址隐藏在其中一个代理服务器后面。
存储数据
成功从网站抓取数据后,下一步是将其存储为易于访问和分析的结构化格式。CSV是常用于这方面的热门格式,因为很多数据分析工具和编程语言均支持CSV。
要将抓取的数据保存为CSV文件,首先要导入pandas库(位于抓取脚本的顶部),因为它有将数据转换为CSV格式的方法:
import pandas as pd
然后,用您收集的数据创建一个pandas DataFrame对象:
df = pd.DataFrame(data)
最后,将DataFrame转换为CSV文件,并为其命名(例如quotes.csv):
df.to_csv('quotes.csv', index=False)
进行这些更改后,运行脚本。然后,您就能获得存储在CSV文件中的抓取数据。
在这个简单的例子中,您可以对引文做的事情并不多。但是,您有各种方法可以分析所抓取的数据,以提取信息,使用的方法取决于数据。
您可以先使用pandasdescribe()函数探索描述性的统计数据。此函数提供数值数据的快速概览,包括平均值、中位数和标准偏差。您可以使用Matplotlib或seaborn创建直方图、散点图或条形图,将数据可视化,让您能运用视觉识别模式或趋势。对于文本数据,可以考虑使用自然语言处理技术(例如词频分析或情绪分析)来了解评论或留言中的共同主题或整体情绪。
要获得更深入的见解,可在数据集中查找不同变量之间的相关性。例如,您可以研究书籍评分与评论长度之间的关系,或者分析不同类型或作者之间的评分差异。使用pandasgroupby()函数将数据汇总,并比较各类别的指标。
别忘了考虑数据的背景,以及您想找到答案的问题。例如,如果您在分析书评,您可以研究哪些因素对高评分的影响最大,或者找出热门类型在一段时间内的趋势。在数据收集过程中,对自己的发现要保持批判态度,并考虑可能存在的偏差。
结论
在本教程中,您学会了如何使用Python抓取文本、探讨了使用代理的好处,并了解到Bright Data轮换代理可以如何帮助您避开IP屏蔽和保持匿名。
虽然开发自己的抓取解决方案好处很多,但通常会带来一些难题,例如维护代码、应对CAPTCHA验证码和遵守网站政策等。在这些方面,Bright Data scraping API可以为您提供帮助。Bright Data具有CAPTCHA验证码自动破解、IP轮换和强大的数据解析等功能,能简化抓取过程,让您可以专注于数据分析,不用为基础设施管理而分心。
请注册以免费试用Bright Data,了解Bright Data可以如何强化您的网页抓取项目,为您的业务需求提供可靠、可扩展和高效的数据收集解决方案。







