
每种语言都有一套定义如何正确构建有效结构的规则;这被称为语言的语法。当你刚开始学习编程时,遇到语法错误是学习过程的一部分。初学者经常难以理解语法规则,经常遇到拼写错误和符号放错位置的情况。
语法错误是每个人编程旅程中的常见部分,但你越早理解它们发生的原因,就能越快地修复它们。
在本文中,你将了解不同的语法错误在 Python 中是如何出现的,以及如何避免它们。
Python中的语法错误
在任何编程语言中,不遵循语法规则很可能会导致语法错误,你的代码无法运行。
在Python中,Python解释器读取并执行你的Python代码,充当高级Python和计算机理解的低级机器语言之间的翻译者。如果你的代码不遵循Python的语法规则,解释器无法处理代码。
当Python解释器遇到语法错误时,它会停止并显示一条错误消息。该消息包括导致错误的代码行的回溯,以及指向在该行中检测到错误的最早点的指示器。
解释器会尽可能为你提供相关信息,帮助你诊断和修复问题,因此请务必仔细阅读错误消息。
Python中的语法错误都是关于结构的——当一个命令违反了语言的语法规则时就会发生。例如,在英语中,句子必须始终以大写字母开头并以标点符号结尾。类似地,在Python中,语句必须始终以新行结束,代码块(如 if 语句或循环)必须正确缩进。
如果你熟悉 运行时错误,你可能会想知道它们与语法错误有何不同。语法错误会阻止程序运行。运行时错误发生在程序开始运行之后。
探索不同类型的语法错误
因为Python有很多 语法规则,所以也会发生很多语法错误。在本节中,你将了解几种常见的错误及其解决方法。
标点符号的错位、缺失或不匹配
Python使用各种标点符号来理解你的代码结构。你需要确保每个这些标点符号都放置正确,并与相应的标点符号匹配,以避免语法错误。
例如,你应该始终成对使用括号 (())、方括号 ([]) 和大括号 ({} )。这意味着如果你打开了一个,就必须关闭它。
在以下示例中,使用了一个大括号来定义一个对象,但它没有关闭:
# Incorrect
proxies = {
'http': proxy_url,
'https': proxy_url如果你尝试运行它,解释器会抛出一个 SyntaxError:
File "python-syntax-errors.py", line 2
proxies = {
^
SyntaxError: '{' was never closed如前所述,Python解释器通常会提供描述性的错误消息。在这里,你得到了发生错误的文件名、发生错误的行号,以及一个指向代码中检测到错误位置的箭头。它还告诉你 '{' was never closed。
有了这些信息,你可以轻松地推断出你需要关闭大括号来修复问题:
# Correct
proxies = {
'http': proxy_url,
'https': proxy_url
} # Closed a curly bracket另一个经常引起问题的标点符号是引号(’ 或 “)。Python,像许多其他编程语言一样,使用引号来定义字符串。你必须使用相同类型的引号来打开和关闭字符串:
# Incorrect
host = "brd.superproxy.io'混用单引号和双引号会导致语法错误:
File "python-syntax-errors.py", line 2
host = "brd.superproxy.io'
^
SyntaxError: unterminated string literal (detected at line 2)这里,解释器告诉你你没有在第二行终止字符串文本:
# Correct
host = "brd.superproxy.io"你可以使用一对单引号来获得相同的结果。
在某些情况下,你可能需要在字符串中使用单引号和双引号。在这种情况下,你可以使用三重引号,如下所示:
quote = """He said, "It's the best proxy service you can find!", and showed me this provider."""在Python中,逗号用于分隔列表、元组或函数参数中的项目。缺少逗号可能会导致意想不到的结果:
# Incorrect
proxies= [
{"http": "http://123.456.789.1:8080", "https": "https://123.456.789.1:8080"}
{"http": "http://98.765.432.1:3128", "https": "https://98.765.432.1:3128"}
{"http": "http://192.168.1.1:8080", "https": "https://192.168.1.1:8080"}
]运行此代码会导致以下错误消息:
File "python-syntax-errors.py", line 3
{"http": "http://123.456.789.1:8080", "https": "https://123.456.789.1:8080"}
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
SyntaxError: invalid syntax. Perhaps you forgot a comma?虽然错误消息尽可能有用,但它们可能并不总是提出完美的解决方案。此代码缺少四个逗号,但错误消息只指出了第一个实例。要修复此问题,你应该查看错误消息周围的代码,并找到其他可能忘记放置逗号的地方:
# Correct
proxies = [
{"http": "http://123.456.789.1:8080", "https": "https://123.456.789.1:8080"},
{"http": "http://98.765.432.1:3128", "https": "https://98.765.432.1:3128"},
{"http": "http://192.168.1.1:8080", "https": "https://192.168.1.1:8080"}
]与逗号相反,冒号用于开始一个新的代码块(如 if 语句或 for 循环):
import requests
from bs4 import BeautifulSoup
# Incorrect
response = requests.get('https://example.com')
if response.status_code == 200
soup = BeautifulSoup(response.content, 'html.parser')
title = soup.title.text
print(title)
)忘记冒号会导致以下语法错误:
if response.status_code == 200
^
SyntaxError: expected ':' 从这个错误消息中,很容易确定缺少了一个冒号,你可以在建议的位置添加它来修复问题:
import requests
from bs4 import BeautifulSoup
# Correct
response = requests.get('https://example.com')
if response.status_code == 200:
soup = BeautifulSoup(response.content, 'html.parser')
title = soup.title.text
print(title)拼写错误、位置错误或缺失的Python关键字
Python关键字是具有特定含义和用途的特殊词,你不能将它们用作变量名。如果你拼写错误、放错位置或忘记使用关键字,解释器会引发错误。
例如,如果你想将 requests 和 pprint 模块导入到你的网页抓取项目中,你可能会不小心拼错了 import 关键字:
# Incorrect
improt requests
import pprint这种拼写错误会导致解释器引发以下 invalid syntax 错误:
File "python-syntax-errors.py", line 2
improt requests
^^^^^^^^
SyntaxError: invalid syntax不幸的是,此错误消息很模糊,因此你需要做一些工作来找出出了什么问题。你可以看到错误消息中的箭头指向 requests;那是解释器首次检测到语法错误的地方。由于拼错模块名不会引发语法错误,唯一的其他可能性是你拼错了 import 关键字。
简单地纠正 import 这个词可以修复错误:
# Correct
import requests
import pprint也有可能弄乱 from ... import ... 语句,如下所示:
import BeautifulSoup from bs4虽然看起来没问题,但运行上述代码会产生错误,因为 from 关键字应该在 import 之前:
File "python-syntax-errors.py", line 2
import BeautifulSoup from bs4
^^^^
SyntaxError: invalid syntax交换 from 和 import 可以修复此问题:
from bs4 import BeautifulSoup遗漏关键字是你在用Python编程时可能会遇到的另一个问题。这种类型的错误比前面提到的错误更微妙,因为在Python中,遗漏关键字可能会引发不同的错误。
如果你忘记在应该返回值的函数中包含 return 关键字,函数不会按预期运行:
def fetch_data():
response = requests.get('https://example.com')
soup = BeautifulSoup(response.content, 'html.parser')
data = soup.find_all('div', class_='data')
# Missing a return statement here
data = fetch_data()这不会抛出语法错误,但函数返回 None 而不是预期的结果。添加 return 关键字可以修复上述代码:
def fetch_data():
response = requests.get('https://example.com')
soup = BeautifulSoup(response.content, 'html.parser')
data = soup.find_all('div', class_='data')
return data
data = fetch_data()如果你在定义函数时忘记了 def 关键字,你会遇到语法错误:
# Missing the `def` keyword
fetch_data():
response = requests.get('https://example.com')
soup = BeautifulSoup(response.content, 'html.parser')
data = soup.find_all('div', class_='data')
return data
data = fetch_data()上述代码引发语法错误,因为解释器期望在函数名之前有一个关键字:
File "python-syntax-errors.py", line 1
fetch_data():
^
SyntaxError: invalid syntax添加 def 关键字可以解决错误:
def fetch_data():
response = requests.get('https://example.com')
soup = BeautifulSoup(response.content, 'html.parser')
data = soup.find_all('div', class_='data')
return data
data = fetch_data()如果你在条件语句中忘记了 if 关键字,解释器会引发错误,因为解释器期望在条件之前有一个关键字:
import requests
from bs4 import BeautifulSoup
response = requests.get('https://example.com')
# Missing the if keyword
response.status_code == 200:
soup = BeautifulSoup(response.content, 'html.parser')
title = soup.title.text
print(title)
File "python-syntax-errors.py", line 6
response.status_code == 200:
^
SyntaxError: invalid syntax你只需包含 if 关键字即可修复此问题:
import requests
from bs4 import BeautifulSoup
response = requests.get('https://example.com')
if response.status_code == 200:
soup = BeautifulSoup(response.content, 'html.parser')
title = soup.title.text
print(title)请注意,这些只是缺少Python关键字的几个示例。缺少关键字可能会引发其他类型的错误,因此要格外小心。
赋值运算符的错误使用
在Python中,= 符号用于 赋值,而 == 用于 比较。混淆这两个符号会导致语法错误:
import requests
from bs4 import BeautifulSoup
# Incorrect
response = requests.get('https://example.com', proxies=proxies)
if response = requests.get('https://example.com/data', proxies=proxies):
soup = BeautifulSoup(response.content, 'html.parser')
data = soup.find_all('div', class_='data')
for item in data:
print(item.text)
else:
print("Failed to retrieve data")在上述代码中,解释器正确地检测到了问题的原因:
File "python-syntax-errors.py", line 5
if response = requests.get('https://example.com/data', proxies=proxies)
^^^^^^在这种情况下,你正试图验证你的响应是否与 request.get() 方法的响应相同。这意味着你需要在 if 语句中将赋值运算符替换为比较运算符:
import requests
from bs4 import BeautifulSoup
# Correct
response = requests.get('https://example.com', proxies=proxies)
# Change in the following line
if response == requests.get('https://example.com/data', proxies=proxies):
soup = BeautifulSoup(response.content, 'html.parser')
data = soup.find_all('div', class_='data')
for item in data:
print(item.text)
else:
print("Failed to retrieve data")缩进错误
Python使用缩进来定义代码块。如果你的代码没有正确缩进,解释器无法区分代码块的内容,会引发 IndentationError:
# Incorrect
async with async_playwright() as playwright:
await run(playwright)如你在上面的代码中所见,在块定义(冒号)之后没有缩进,因此当你运行它时,会得到以下错误消息:
File "python-syntax-errors.py", line 2
await run(playwright)
^
IndentationError: expected an indented block after the with statement on line 1要解决此问题,请遵循Python的语法规则,并正确缩进代码块:
# Correct
async with async_playwright() as playwright:
await run(playwright)变量声明问题
Python中的变量名必须以字母或下划线开头,并且只能包含字母、数字和下划线。此外,Python区分大小写,因此 myvariable、myVariable 和 MYVARIABLE 都是不同的变量。
你的变量名绝不能以字母或下划线以外的任何东西开头。以下变量名以 1 开头,不符合Python的语法规则:
# Incorrect
1st_port = 22225当你运行上述代码时,解释器会引发一个 SyntaxError:
File "python-syntax-errors.py", line 2
1st_port = 1
^
SyntaxError: invalid decimal literal要修复此问题,你必须以字母或下划线开始变量名。以下任何选项都可以:
# Correct
first_port = 22225
port_no_1 = 22225函数定义和调用错误
在定义函数时,你必须使用 def 关键字,后跟函数名、括号和冒号。在调用函数时,你必须使用其名称后跟括号。忘记其中任何一个元素都会引发语法错误:
import requests
from bs4 import BeautifulSoup
# Incorrect
def fetch_data
response = requests.get('https://example.com')
soup = BeautifulSoup(response.content, 'html.parser')
data = soup.find_all('div', class_='data')
return data
# Incorrect
data = fetch_data这里缺少三个元素,每个元素都会导致单独的语法错误。要修复这些错误,你需要在函数名 fetch_data 之后添加括号和冒号。你还需要在代码块的最后一行的函数调用之后添加括号,如下所示:
import requests
from bs4 import BeautifulSoup
# Corrected
def fetch_data():
response = requests.get('https://example.com')
soup = BeautifulSoup(response.content, 'html.parser')
data = soup.find_all('div', class_='data')
return data
# Corrected
data = fetch_data()请注意,在函数定义中缺少括号和冒号总是会导致语法错误。然而,解释器并不总是能检测到你在调用函数时是否忘记了括号(fetch_data())。在这种情况下,它不一定会抛出异常,这可能会导致意外的行为。
帮助你避免语法错误的最佳实践
编写无错误的代码是随着实践而来的技能。理解并实施以下最佳实践可以帮助你避免常见的语法错误。
主动策略
处理语法错误的最佳方法是尽量预防它们。
在开始项目之前,你应该熟悉你正在编码的语言的最常见语法规则。
使用具有语法高亮和缩进检查的代码编辑器
一个好的代码编辑器在避免语法错误方面是一个很好的伙伴。大多数现代代码编辑器都提供诸如语法高亮和缩进检查等功能,可以帮助你在运行代码之前发现错误。
例如,在以下插图中,if response.status_code == 200 行的末尾有一个红色标记,提示可能存在错误,因为缺少冒号:
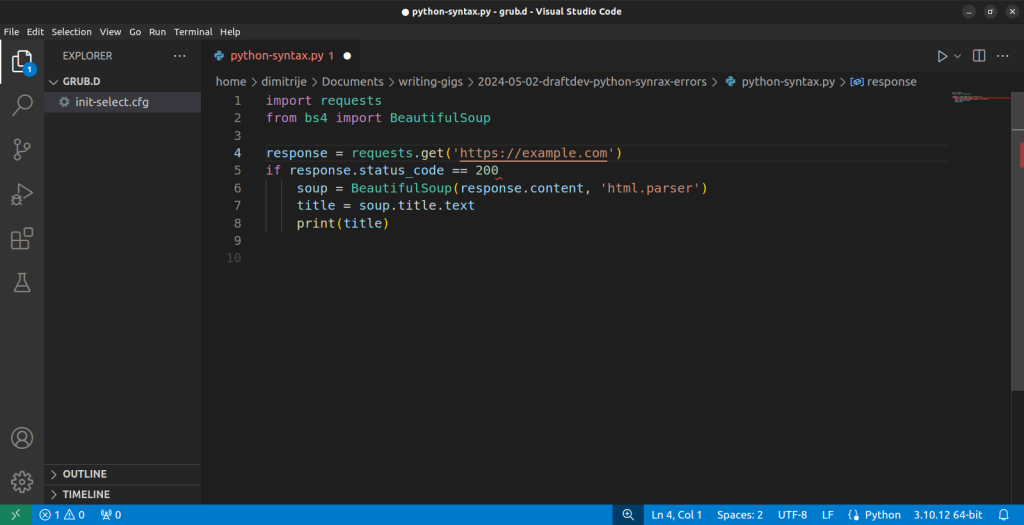
遵循一致的编码风格指南
与大多数事情一样,一致性是编写干净、无错误代码的关键。努力遵循一致的编码风格。这使你的代码更易于阅读和理解,从而更容易发现和修复错误。
在Python中,PEP 8 风格指南被广泛接受为编码风格的标准。它提供了关于变量命名、缩进和空白使用等方面的指南。
在小的、定义明确的函数中编写代码
将你的代码分解为小的、定义明确的函数可以使其更易于管理和调试。
每个函数都应有一个明确的目的。如果一个函数做了太多事情,它可能会变得难以理解和调试。例如,看看以下的 scrape_and_analyze() 函数:
import requests
from bs4 import BeautifulSoup
from textblob import TextBlob
def scrape_and_analyze():
url = "https://example.com/articles"
response = requests.get(url)
soup = BeautifulSoup(response.content, "html.parser")
titles = soup.find_all("h2", class_="article-title")
sentiments = []
for title in titles:
title_text = title.get_text()
blob = TextBlob(title_text)
sentiment = blob.sentiment.polarity
sentiments.append(sentiment)
return sentiments
print(scrape_and_analyze())在此示例中,将此函数分解为多个更小的函数,每个执行更小、更易于管理的代码部分,会使代码更具可读性:
import requests
from bs4 import BeautifulSoup
from textblob import TextBlob
def scrape_titles(url):
"""Scrape article titles from a given URL."""
response = requests.get(url)
soup = BeautifulSoup(response.content, "html.parser")
titles = soup.find_all("h2", class_="article-title")
return [title.get_text() for title in titles]
def analyze_sentiment(text):
"""Analyze sentiment of a given text."""
blob = TextBlob(text)
return blob.sentiment.polarity
def analyze_titles_sentiment(titles):
"""Analyze sentiment of a list of titles."""
return [analyze_sentiment(title) for title in titles]
def scrape_and_analyze(url):
"""Scrape titles from a website and analyze their sentiment."""
titles = scrape_titles(url)
sentiments = analyze_titles_sentiment(titles)
return sentiments
url = "https://example.com/articles"
print(scrape_and_analyze(url))应对策略
无论你多么努力地防止错误,总会有一些错误会溜过来。以下策略着重于处理这些错误。
仔细阅读错误消息
如前所述,Python通常会给你一个错误消息,其中包含有关错误性质和位置的信息。
仔细阅读这些错误消息可以为你提供有关出了什么问题以及如何修复它的宝贵线索。
策略性地使用打印语句
使用 print() 语句是在你需要跟踪执行流程或检查特定点的变量值时,快速且有效地调试小型项目或简单问题的方法。它对于快速开发以及当你对问题所在有良好理解时特别有用。
打印调试可以减少干扰并更快地实现,使其成为快速修复和简单错误的首选方法。然而,请始终注意,它仅供临时使用,确保不要在生产代码中使用它,因为向最终用户打印数据可能导致严重的数据泄露和性能问题。
当你遇到更复杂的问题、有更大的代码库,或者需要更深入地检查程序的状态(例如跨多个函数调用或迭代的变量状态)时,使用调试器更合适。调试器允许你设置断点、逐行执行代码,并在任何时候检查应用程序的状态,提供更受控和全面的调试环境。
利用在线资源和社区
如果你被一个特别棘手的错误困住了,不要犹豫寻求帮助。有许多在线资源(Python文档和 Real Python)和社区(r/Python 和 r/LearnPython 子版块、Stack Overflow和 Python论坛),你可以在其中找到问题的答案和解决方案。
结论
在本文中,你已经探索了Python语法错误的世界。你了解了几种类型的语法错误,包括它们可能发生的地方以及如何识别和修复它们。
你还学习了一些主动和被动的策略,帮助你预防语法错误或在它们发生时修复它们。
Bright Data 是领先的网络爬取工具提供商。无论你需要可靠的代理、自动化数据收集、现成的数据集,还是 自动化的网络爬取任务,Bright Data都提供了可以使你的网络爬取项目更高效和富有成效的解决方案。
立即注册,找到适合你需求的产品,并开始免费试用吧!
支持支付宝等多种支付方式






