

进行网络爬取时,通常需要应对反爬机制,使用类似 Puppeteer 的浏览器自动化工具加载动态内容,通过代理轮换避免 IP 阻断,并解决 CAPTCHA。即便使用了这些策略,想要稳定扩展会话仍然很有挑战性。
本文将教你如何从传统的基于代理的配置转向使用 Bright Data 抓取浏览器 进行动态爬取,更加简化的方案。我们会比较两种方法,包括配置、性能、可扩展性以及复杂度等方面。
注意:本文中的示例仅用作教育用途。在爬取任何数据之前,请务必先阅读目标网站的服务条款,并遵守相关法律法规。
先决条件
在开始本教程之前,请确保你已经具备如下条件:
- 已在本地安装 Node.js 和 npm
- 对 JavaScript 和命令行的基本了解
- 一个文本编辑器或 IDE,如 Visual Studio Code 或 WebStorm,用于编写代码
- 一个免费的 Bright Data 账户,以便使用它们的抓取浏览器
首先,新建一个 Node.js 项目文件夹以存放你的代码。
然后,打开你的终端或 shell,使用以下命令创建新目录:
mkdir scraping-tutorial
cd scraping-tutorial初始化一个新的 Node.js 项目:
npm init -y-y 参数会自动回答 yes 给所有问题,使用默认设置创建一个 package.json 文件。
基于代理的网络爬取
在典型的基于代理的方案中,你可以使用 Puppeteer 这样的浏览器自动化工具来与目标域进行交互,加载动态内容并提取数据。同时,通过集成代理来避免 IP 封锁并保持匿名。
下面让我们使用 Puppeteer 快速创建一个爬虫脚本,通过代理从电商网站爬取数据。
使用 Puppeteer 创建爬虫脚本
首先安装 Puppeteer:
npm install puppeteer然后,在 scraping-tutorial 文件夹中创建一个名为 proxy-scraper.js(文件名可自定)的文件,并添加以下代码:
const puppeteer = require("puppeteer");
(async () => {
// Launch a headless browser
const browser = await puppeteer.launch({
headless: true,
});
const page = await browser.newPage();
const baseUrl = "https://books.toscrape.com/catalogue/page-";
const books = [];
for (let i = 1; i <= 5; i++) { // Loop through the first 5 pages
const url = `${baseUrl}${i}.html`;
console.log(`Navigating to: ${url}`);
// Navigate to the page
await page.goto(url, { waitUntil: "networkidle0" });
// Extract book data from the current page
const pageBooks = await page.evaluate(() => {
let books = [];
document.querySelectorAll(".product_pod").forEach((item) => {
let title = item.querySelector("h3 a")?.getAttribute("title") || "";
let price = item.querySelector(".price_color")?.innerText || "";
books.push({ title, price });
});
return books;
});
books.push(...pageBooks); // Append books from this page to the main list
}
console.log(books); // Print the collected data
await browser.close();
})();该脚本使用 Puppeteer 从 Books to Scrape 网站的前五页抓取书名和价格。它会启动一个无头浏览器,打开新页面,并依次访问每个目录页。
脚本在每一页中,使用 page.evaluate() 内部的 DOM 选择器提取书名和价格,并将数据存入数组。当处理完所有页面后,脚本会在控制台中打印数据,并关闭浏览器。这样就能高效地从分页网站中抓取数据。
使用以下命令测试并运行:
node proxy-scraper.js输出应类似如下:
Navigating to: https://books.toscrape.com/catalogue/page-1.html
Navigating to: https://books.toscrape.com/catalogue/page-2.html
Navigating to: https://books.toscrape.com/catalogue/page-3.html
Navigating to: https://books.toscrape.com/catalogue/page-4.html
Navigating to: https://books.toscrape.com/catalogue/page-5.html
[
{ title: 'A Light in the Attic', price: '£51.77' },
{ title: 'Tipping the Velvet', price: '£53.74' },
{ title: 'Soumission', price: '£50.10' },
{ title: 'Sharp Objects', price: '£47.82' },
{ title: 'Sapiens: A Brief History of Humankind', price: '£54.23' },
{ title: 'The Requiem Red', price: '£22.65' },
…output omitted…
{
title: 'In the Country We Love: My Family Divided',
price: '£22.00'
}
]设置代理
在爬虫配置中,代理常被用来分散请求并使请求难以追踪。常见做法是维护一个代理池并动态轮换。
你可以把代理放在一个数组里,或者存放在单独文件中:
const proxies = [
"proxy1.example.com:port",
"proxy2.example.com:port"
// Add more proxies here
];实现代理轮换逻辑
让我们添加一些逻辑,在每次启动浏览器时,从代理数组中随机选择代理。更新 proxy-scraper.js,内容如下:
const puppeteer = require("puppeteer");
const proxies = [
"proxy1.example.com:port",
"proxy2.example.com:port"
// Add more proxies here
];
(async () => {
// Choose a random proxy
const randomProxy =
proxies[Math.floor(Math.random() * proxies.length)];
// Launch Puppeteer with proxy
const browser = await puppeteer.launch({
headless: true,
args: [
`--proxy-server=http=${randomProxy}`,
"--no-sandbox",
"--disable-setuid-sandbox",
"--ignore-certificate-errors",
],
});
const page = await browser.newPage();
const baseUrl = "https://books.toscrape.com/catalogue/page-";
const books = [];
for (let i = 1; i <= 5; i++) {
// Loop through the first 5 pages
const url = `${baseUrl}${i}.html`;
console.log(`Navigating to: ${url}`);
// Navigate to the page
await page.goto(url, { waitUntil: "networkidle0" });
// Extract book data from the current page
const pageBooks = await page.evaluate(() => {
let books = [];
document.querySelectorAll(".product_pod").forEach((item) => {
let title = item.querySelector("h3 a")?.getAttribute("title") || "";
let price = item.querySelector(".price_color")?.innerText || "";
books.push({ title, price });
});
return books;
});
books.push(...pageBooks); // Append books from this page to the main list
}
console.log(`Using proxy: ${randomProxy}`);
console.log(books); // Print the collected data
await browser.close();
})();注意:除了手动轮换代理,你也可以使用类似 luminati-proxy 这样的库来自动化该过程。
在这段代码中,从 proxies 列表中随机选择一个代理,通过 --proxy-server=${randomProxy} 参数应用到 Puppeteer。为避免被识别,还可以额外设置随机的用户代理字符串。随后重复爬取逻辑,并记录所使用的代理。
再次运行代码时,输出和之前类似,并会打印使用到的代理:
Navigating to: https://books.toscrape.com/catalogue/page-1.html
Navigating to: https://books.toscrape.com/catalogue/page-2.html
Navigating to: https://books.toscrape.com/catalogue/page-3.html
Navigating to: https://books.toscrape.com/catalogue/page-4.html
Navigating to: https://books.toscrape.com/catalogue/page-5.html
Using proxy: 115.147.63.59:8081
…output omitted…基于代理爬取的挑战
虽然使用基于代理的方法适用于很多场景,但你可能会遇到如下难题:
- 频繁被封:如果目标网站反爬措施严格,代理可能被封锁。
- 性能开销:代理轮换和请求重试会减慢数据采集流程。
- 可扩展性复杂:为了获取最佳性能和可用性,需要管理和轮换规模庞大的代理池,包括负载均衡、避免过度使用、冷却周期,以及实时处理失效。并发请求数增多时,这个问题会愈发明显,还需要持续监控并更换被拉黑或性能不佳的 IP。
- 浏览器维护:浏览器的维护相当复杂且消耗资源,需要不断更新和管理其指纹(cookies、headers 以及其他识别信息)来模拟真实用户行为,从而规避高级反爬措施。
- 云端浏览器开销:云端浏览器的资源需求较高,且基础设施管理更复杂,导致运营成本上升。若要保证扩展时性能稳定,则更是复杂。
使用 Bright Data 抓取浏览器进行动态爬取
为了解决上述难题,你可以使用 Bright Data 抓取浏览器这样的“一站式”API 方案。它能简化你的操作,无需手动代理轮换和繁琐的浏览器配置,并在数据获取的成功率上更具优势。
注册并设置 Bright Data 账户
首先,登录你的 Bright Data 账户,进入 Proxies & Scraping,向下滚动至抓取浏览器并点击 Get Started:
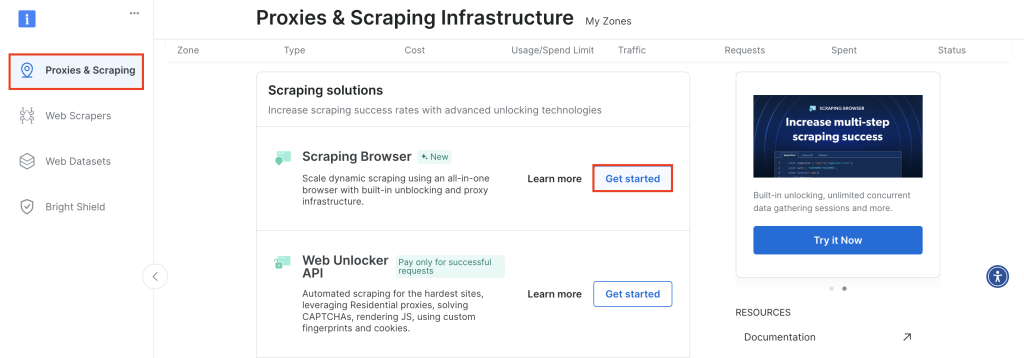
保持默认配置并点击 Add 即可创建一个新的抓取浏览器实例:
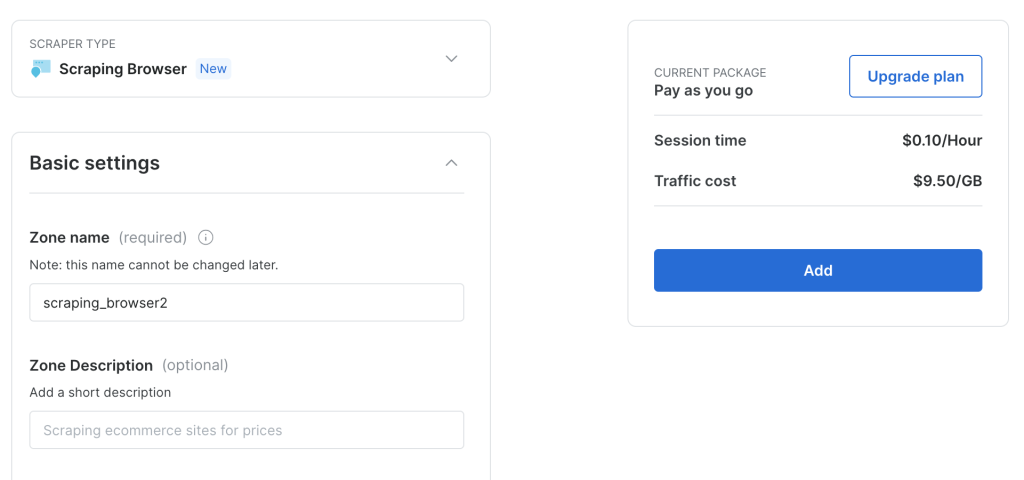
创建完抓取浏览器实例后,记下 Puppeteer 的 URL,后面会用到:
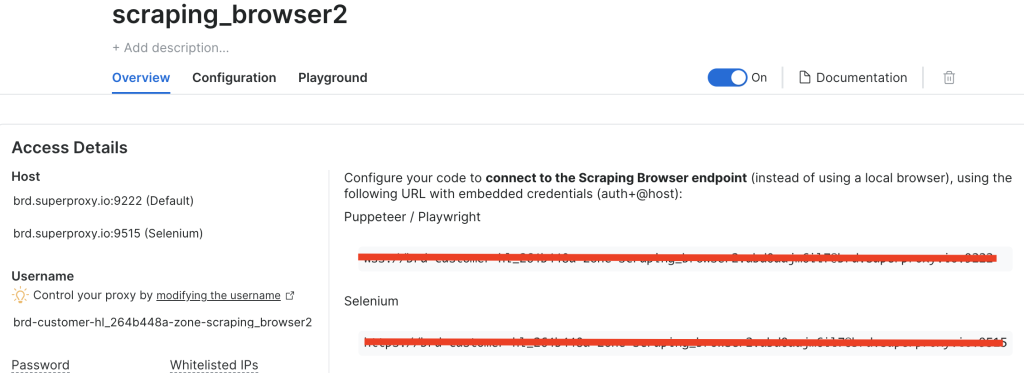
修改代码以使用 Bright Data 抓取浏览器
现在,让我们调整代码,让它不再使用代理轮换,而是直接连接到 Bright Data 抓取浏览器的端点。
新建一个名为 brightdata-scraper.js 的文件,添加如下代码:
const puppeteer = require("puppeteer");
(async () => {
// Choose a random proxy
const SBR_WS_ENDPOINT ="YOUR_BRIGHT_DATA_WS_ENDPOINT"
// Launch Puppeteer with proxy
const browser = await puppeteer.connect({
browserWSEndpoint: SBR_WS_ENDPOINT,
});
const page = await browser.newPage();
const baseUrl = "https://books.toscrape.com/catalogue/page-";
const books = [];
for (let i = 1; i <= 5; i++) {
// Loop through the first 5 pages
const url = `${baseUrl}${i}.html`;
console.log(`Navigating to: ${url}`);
// Navigate to the page
await page.goto(url, { waitUntil: "networkidle0" });
// Extract book data from the current page
const pageBooks = await page.evaluate(() => {
let books = [];
document.querySelectorAll(".product_pod").forEach((item) => {
let title = item.querySelector("h3 a")?.getAttribute("title") || "";
let price = item.querySelector(".price_color")?.innerText || "";
books.push({ title, price });
});
return books;
});
books.push(...pageBooks); // Append books from this page to the main list
}
console.log(books); // Print the collected data
await browser.close();
})();请将 YOUR_BRIGHT_DATA_WS_ENDPOINT 替换为你在上一步中拿到的 URL。
该脚本与前文几乎相同,区别就在于不需要依赖多个代理,而是直接连接到 Bright Data 提供的端点。
运行以下命令:
node brightdata-scraper.js输出结果和之前相同,但现在你不再需要手动代理轮换或配置用户代理。Bright Data 抓取浏览器会自动处理代理轮换、绕过 CAPTCHA 等工作,确保数据采集不中断。
将代码暴露为 Express 接口
如果想把 Bright Data 抓取浏览器融入更大型的应用中,你可以考虑将其封装成 Express 接口。
先安装 Express:
npm install express创建一个名为 server.js 的文件,并添加如下代码:
const express = require("express");
const puppeteer = require("puppeteer");
const app = express();
const PORT = 3000;
// Needed to parse JSON bodies:
app.use(express.json());
// Your Bright Data Scraping Browser WebSocket endpoint
const SBR_WS_ENDPOINT =
"wss://brd-customer-hl_264b448a-zone-scraping_browser2:[email protected]:9222";
/**
* POST /scrape
* Body example:
* {
* "baseUrl": "https://books.toscrape.com/catalogue/page-"
* }
*/
app.post("/scrape", async (req, res) => {
const { baseUrl } = req.body;
if (!baseUrl) {
return res.status(400).json({
success: false,
error: 'Missing "baseUrl" in request body.',
});
}
try {
// Connect to the existing Bright Data (Luminati) Scraping Browser
const browser = await puppeteer.connect({
browserWSEndpoint: SBR_WS_ENDPOINT,
});
const page = await browser.newPage();
const books = [];
// Example scraping 5 pages of the base URL
for (let i = 1; i <= 5; i++) {
const url = `${baseUrl}${i}.html`;
console.log(`Navigating to: ${url}`);
await page.goto(url, { waitUntil: "networkidle0" });
const pageBooks = await page.evaluate(() => {
const data = [];
document.querySelectorAll(".product_pod").forEach((item) => {
const title = item.querySelector("h3 a")?.getAttribute("title") || "";
const price = item.querySelector(".price_color")?.innerText || "";
data.push({ title, price });
});
return data;
});
books.push(...pageBooks);
}
// Close the browser connection
await browser.close();
// Return JSON with the scraped data
return res.json({
success: true,
books,
});
} catch (error) {
console.error("Scraping error:", error);
return res.status(500).json({
success: false,
error: error.message,
});
}
});
// Start the Express server
app.listen(PORT, () => {
console.log(`Server is listening on http://localhost:${PORT}`);
});上述代码中,你初始化了一个 Express 应用,接受 JSON 负载,并定义了一个 POST /scrape 路由。客户端需要在请求体中传入 baseUrl,随后代码将目标 URL 转发给 Bright Data 抓取浏览器端点。
运行你的 Express 服务:
node server.js测试该接口,可以使用 Postman 这样的工具(或任意其他 REST 客户端),也可以使用 curl 在终端或 shell 中请求:
curl -X POST http://localhost/scrape
-H 'Content-Type: application/json'
-d '{"baseUrl": "https://books.toscrape.com/catalogue/page-"}'输出应类似如下:
{"success":true,"books":[{"title":"A Light in the Attic","price":"£51.77"},{"title":"Tipping the Velvet","price":"£53.74"},{"title":"Soumission","price":"£50.10"},{"title":"Sharp Objects","price":"£47.82"},{"title":"Sapiens: A Brief History of Humankind","price":"£54.23"},{"title":"The Requiem Red","price":"£22.65"},{"title":"The Dirty Little Secrets of Getting Your Dream Job","price":"£33.34"},{"title":"The Coming Woman: A Novel Based on the Life of the Infamous Feminist, Victoria Woodhull","price":"£17.93"},
… output omitted…
{"title":"Judo: Seven Steps to Black Belt (an Introductory Guide for Beginners)","price":"£53.90"},{"title":"Join","price":"£35.67"},{"title":"In the Country We Love: My Family Divided","price":"£22.00"}]}下图对比了手动(代理轮换)和 Bright Data 抓取浏览器这两种方式:
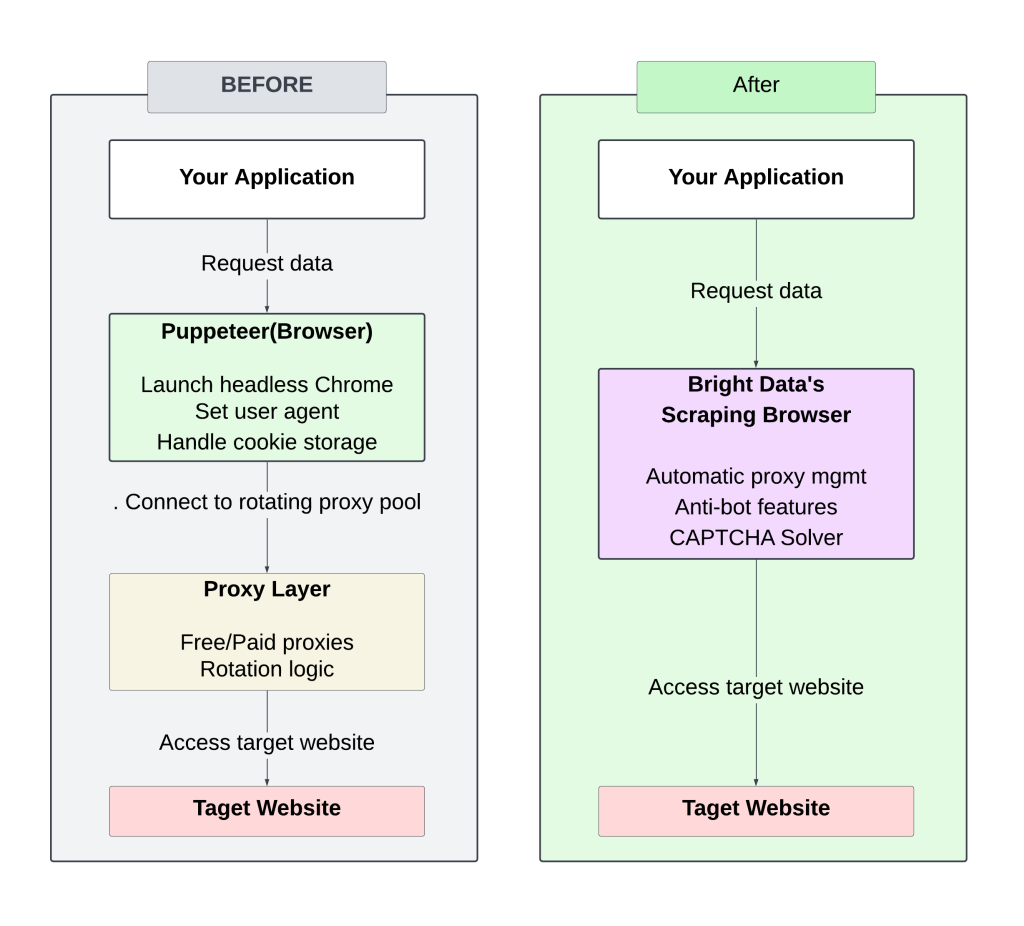
使用手动轮换代理的方案,需要持续投入精力进行监控和调整,容易出现频繁封禁且难以扩展。
使用 Bright Data 抓取浏览器则可以免去管理代理和请求头的麻烦,通过优化后的基础设施获得更快的响应时间。它自带反爬策略,可提升成功率,减少被封或被标记的风险。
本文所有示例代码都可在此 GitHub 仓库中获取。
计算 ROI
从手动代理的爬取模式转向 Bright Data 抓取浏览器,能显著降低开发时间与成本。
传统方案
假设每天需要爬取新闻网站:
- 初期开发:约 50 小时(时薪 100 美元,总计 5,000 美元)
- 持续维护:每月约 10 小时(1,000 美元),用于更新代码、管理基础设施、扩展和代理维护
- 代理/IP 成本:每月约 250 美元(根据实际需求浮动)
月度成本总计:约 1,250 美元
Bright Data 抓取浏览器方案
- 开发时间:5–10 小时(约 1,000 美元)
- 维护:每月约 2–4 小时(200 美元)
- 无需额外的代理或基础设施管理
- Bright Data 服务费用:
- 流量使用:8.40 美元/GB(例如每月 30GB = 252 美元)
月度成本总计:约 450 美元
通过自动化代理管理并借助 Bright Data 抓取浏览器的可扩展能力,不仅能降低初期开发成本,也能减少后续维护支出,让大规模数据采集更加高效经济。
总结
从传统的代理轮换配置迁移到 Bright Data 抓取浏览器,可以免去繁琐的代理轮换和手动防爬配置。
除了获取 HTML 之外,Bright Data 还提供更多工具来简化数据采集流程:
这些方案可让你的爬虫流程更简单、工作量更低,并提升可扩展性。
支持支付宝等多种支付方式



