

网页抓取 是指自动从网站收集数据的过程,目的包括数据分析或微调 AI 模型。
Python 因其广泛的抓取库而成为网页抓取的热门选择,包括用于解析 XML 和 HTML 文档的 lxml。lxml 通过为快速的 C 库 libxml2 和 libxslt 提供 Python API,扩展了 Python 的功能。它还与 Python 的用于 XML/HTML 树的分层数据结构 ElementTree 集成,这使得 lxml 成为高效、可靠的网页抓取的首选工具。
在本文中,您将学习如何使用 lxml 进行网页抓取。
Bright Data 解决方案是完美的替代方案
在网页抓取方面,使用 Python 和 lxml 是一种强大的方法,但可能耗时且成本高,尤其是在处理复杂网站或大量数据时。Bright Data 提供了高效的替代方案,提供 即用型数据集 和 网页抓取 API。这些解决方案通过提供来自 100 多个域的预收集数据和易于集成的抓取 API,大大减少了数据收集所需的时间和成本。
使用 Bright Data,您可以绕过手动抓取的技术挑战,让您专注于分析数据而非获取数据。无论您需要针对特定需求定制的数据集,还是处理代理管理和 验证码解决 的 API,Bright Data 的工具都为您的所有网页抓取需求提供了精简、经济高效的解决方案。
在 Python 中使用 lxml 进行网页抓取
在网络上,结构化和分层数据可以用两种格式表示——HTML 和 XML:
- XML 是一种基本结构,没有预建的标签和样式。编码人员通过定义自己的标签来创建结构。标签的主要目的是创建不同系统之间可理解的标准数据结构。
- HTML 是一种具有预定义标签的网页标记语言。这些标签带有一些样式属性,例如
font-size用于<h1>标签或display用于<img />标签。HTML 的主要功能是有效地构建网页。
lxml 可处理 HTML 和 XML 文档。
先决条件
在开始使用 lxml 进行网页抓取之前,您需要在机器上安装一些库:
pip install lxml requests cssselect此命令安装以下内容:
解析静态 HTML 内容
可以抓取的网页内容主要有两种类型:静态和动态。静态内容在网页最初加载时嵌入 HTML 文档中,易于抓取。相反,动态内容是持续加载的,或者由 JavaScript 在初始页面加载后触发。抓取动态内容需要在内容在浏览器中可用后再执行抓取功能。
在本文中,您首先抓取专为测试目的而设计的 Books to Scrape 网站,提取书籍的标题和价格,并将这些信息保存为 JSON 文件。
首先,使用浏览器的 开发者工具 来识别相关的 HTML 元素。通过右键单击网页并选择 检查 选项来打开 开发者工具。如果您使用的是 Chrome,可以按 F12 访问此菜单:
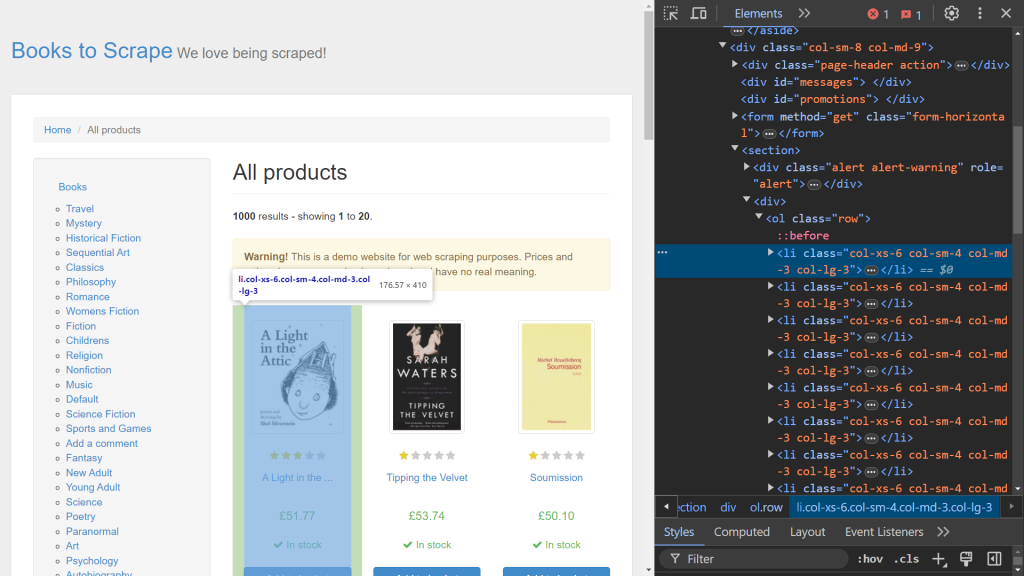
屏幕右侧显示负责呈现页面的代码。要找到处理每本书数据的特定 HTML 元素,使用悬停选择选项(屏幕左上角的箭头)在代码中搜索:
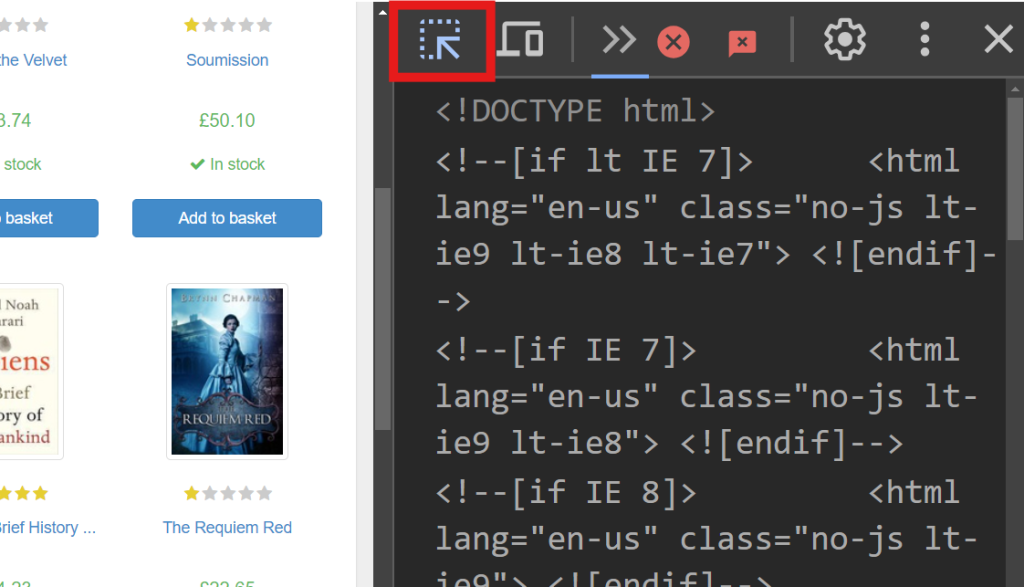
在 开发者工具 中,您应该看到以下代码片段:
<article class="product_pod">
<!-- code omitted -->
<h3><a href="catalogue/a-light-in-the-attic_1000/index.html" title="A Light in the Attic">A Light in the ...</a></h3>
<div class="product_price">
<p class="price_color">£51.77</p>
<!-- code omitted -->
</div>
</article>在此片段中,每本书都包含在一个带有类 product_pod 的 <article> 标签内。您将针对该元素提取数据。创建一个名为 static_scrape.py 的新文件,并输入以下代码:
import requests
from lxml import html
import json
URL = "https://books.toscrape.com/"
content = requests.get(URL).text此代码导入了必要的库,并定义了一个 URL 变量。它使用 requests.get() 通过向指定的 URL 发送 GET 请求来获取网页的静态 HTML 内容。然后,使用响应的 text 属性检索 HTML 代码。
获得 HTML 内容后,下一步是使用 lxml 进行解析并提取必要的数据。lxml 提供了两种提取方法:XPath 和 CSS 选择器。在此示例中,您使用 XPath 来检索书名,使用 CSS 选择器来获取书籍价格。
在脚本中追加以下代码:
parsed = html.fromstring(content)
all_books = parsed.xpath('//article[@class="product_pod"]')
books = []此代码使用 html.fromstring(content) 初始化 parsed 变量,将 HTML 内容解析为分层树结构。all_books 变量使用 XPath 选择器从网页中检索所有带有类 product_pod 的 <article> 标签。此语法特定于 XPath 表达式。
接下来,向脚本添加以下内容,迭代 all_books 中的每本书并从中提取数据:
for book in all_books:
book_title = book.xpath('.//h3/a/@title')
price = book.cssselect("p.price_color")[0].text_content()
books.append({"title": book_title, "price": price})book_title 变量使用 XPath 选择器定义,从 <h3> 标签内的 <a> 标签中检索 title 属性。XPath 表达式开头的点(.)指定从 <article> 标签开始搜索,而不是默认起点。下一行使用 cssselect 方法从带有类 price_color 的 <p> 标签中提取价格。由于 cssselect 返回一个列表,通过索引([0])访问第一个元素,¨C32C 方法检索元素内的文本。然后,每个提取的标题和价格对都作为字典附加到 ¨C33C 列表中,可以轻松地存储在 JSON 文件中。
现在您已经完成了网页抓取过程,是时候将这些数据保存在本地了。打开脚本文件,输入以下代码:
with open("books.json", "w", encoding="utf-8") as file:
json.dump(books ,file)在此代码中,创建了一个名为 books.json 的新文件。该文件使用 json.dump 方法填充,该方法将 books 列表作为源,file 对象作为目标。
您可以通过打开终端并运行以下命令来测试此脚本:
python static_scrape.py此命令将在您的目录中生成一个新文件,输出如下:
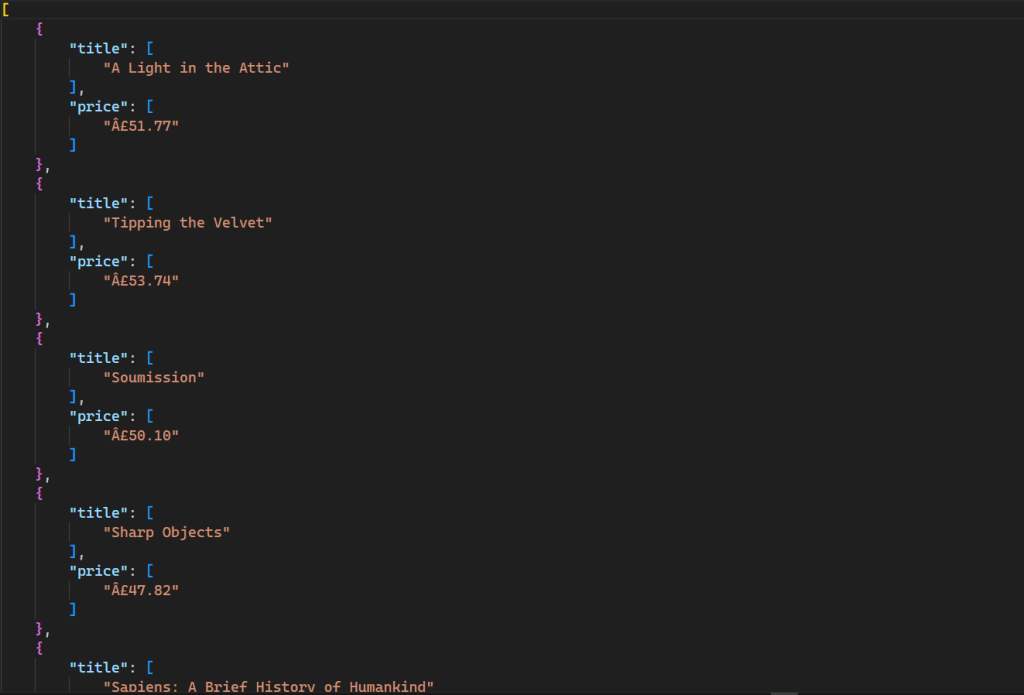
此脚本的所有代码都可在 GitHub 上找到。
解析动态 HTML 内容
抓取动态网页内容比抓取静态内容更为棘手,因为 JavaScript 会持续渲染数据而不是一次全部渲染。为了帮助抓取动态内容,您可以使用名为 Selenium 的浏览器自动化工具,它允许您创建和运行浏览器实例并以编程方式控制它。
要安装 Selenium,请打开终端并运行以下命令:
pip install seleniumYouTube 是一个使用 JavaScript 渲染内容的绝佳示例。当您访问任何频道时,最初只加载有限数量的视频,随着您向下滚动会出现更多视频。这里,您将通过模拟键盘按键来滚动页面,从 freeCodeCamp.org 的 YouTube 频道 抓取前一百个视频的数据。
首先,检查网页的 HTML 代码。当您打开 开发者工具 时,您会看到以下内容:
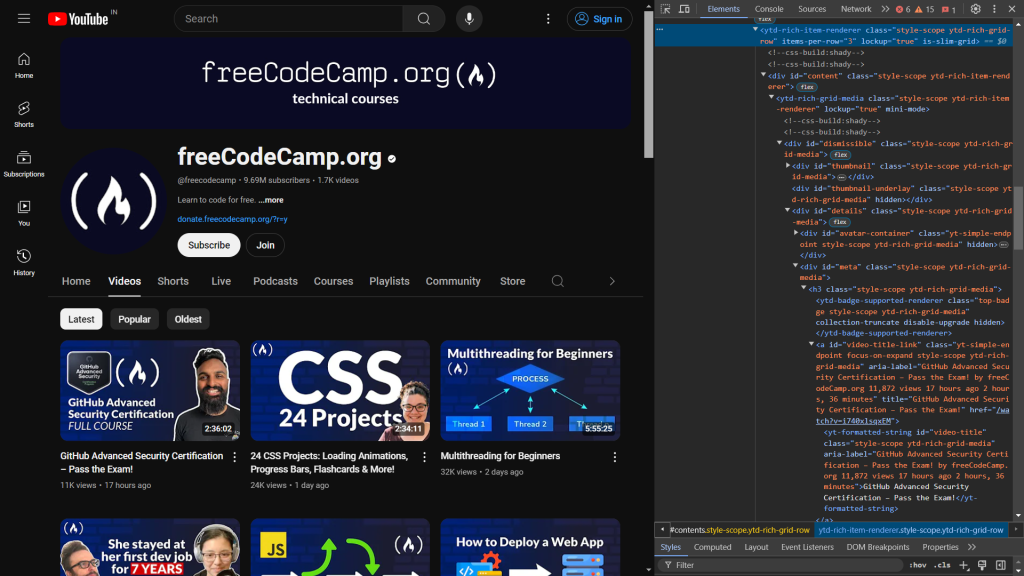
以下代码标识了显示视频标题和链接的元素:
<a id="video-title-link" class="yt-simple-endpoint focus-on-expand style-scope ytd-rich-grid-media" href="/watch?v=i740xlsqxEM">
<yt-formatted-string id="video-title" class="style-scope ytd-rich-grid-media">GitHub Advanced Security Certification – Pass the Exam!
</yt-formatted-string></a>视频标题位于 ID 为 video-title 的 yt-formatted-string 标签内,视频链接位于 ID 为 video-title-link 的 a 标签的 href 属性中。
确定要抓取的内容后,创建一个名为 dynamic_scrape.py 的新文件,并添加以下代码,导入脚本所需的所有模块:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from lxml import html
from time import sleep
import json首先,您从 selenium 中导入 webdriver,它创建一个您可以以编程方式控制的浏览器实例。接下来的行导入 By 和 Keys,用于在网页上选择元素并对其执行按键操作。sleep 函数用于暂停程序执行,等待 JavaScript 在页面上渲染内容。
准备好所有导入后,您可以为所选浏览器定义驱动程序实例。本教程使用 Chrome,但 Selenium 也支持 Edge、Firefox 和 Safari。
要为浏览器定义驱动程序实例,在脚本中添加以下代码:
URL = "https://www.youtube.com/@freecodecamp/videos"
videos = []
driver = webdriver.Chrome()
driver.get(URL)
sleep(3)与前面的脚本类似,您声明了一个包含要抓取的网页 URL 的 URL 变量,以及一个存储所有数据的 videos 变量。接下来,声明了一个 driver 变量(即 Chrome 实例),您将在与浏览器交互时使用。get() 函数打开浏览器实例并向指定的 URL 发送请求。之后,您调用 sleep 函数,等待三秒钟再访问网页上的任何元素,以确保所有 HTML 代码都已在浏览器中加载。
如前所述,YouTube 使用 JavaScript 在您滚动到页面底部时加载更多视频。要从一百个视频中抓取数据,您必须在打开浏览器后以编程方式滚动到页面底部。您可以通过将以下代码添加到脚本中来实现:
parent = driver.find_element(By.TAG_NAME, 'html')
for i in range(4):
parent.send_keys(Keys.END)
sleep(3)在此代码中,使用 find_element 函数选择 <html> 标签。它返回第一个匹配给定条件的元素,在本例中是 html 标签。send_keys 方法模拟按下 END 键以滚动到页面底部,触发加载更多视频。此操作在 for 循环内重复四次,以确保加载足够多的视频。sleep 函数在每次滚动后暂停三秒钟,允许视频在再次滚动之前加载。
现在您拥有了开始抓取过程所需的所有数据,是时候使用 lxml 和 cssselect 选择您要提取的元素:
html_data = html.fromstring(driver.page_source)
videos_html = html_data.cssselect("a#video-title-link")
for video in videos_html:
title = video.text_content()
link = "https://www.youtube.com" + video.get("href")
videos.append( {"title": title, "link": link} )在此代码中,您将驱动程序的 page_source 属性中的 HTML 内容传递给 fromstring 方法,它构建了 HTML 的分层树。然后,您使用 CSS 选择器选择所有 ID 为 video-title-link 的 <a> 标签,其中 # 符号表示使用标签的 ID 进行选择。此选择返回满足给定条件的元素列表。然后,代码迭代每个元素以提取标题和链接。text_content 方法检索内部文本(视频标题),而 get 方法获取 href 属性值(视频链接)。最后,数据存储在名为 videos 的列表中。
至此,您已完成抓取过程。下一步是将这些抓取的数据存储在您的系统中。要存储数据,请在脚本中追加以下代码:
with open('videos.json', 'w') as file:
json.dump(videos, file)
driver.close()在这里,您创建了一个 videos.json 文件,并使用 json.dump 方法将视频列表序列化为 JSON 格式并写入文件对象。最后,您调用驱动程序对象的 close 方法,以安全地关闭和销毁浏览器实例。
现在,您可以通过打开终端并运行以下命令来测试您的脚本:
python dynamic_scrape.py运行脚本后,您的目录中将创建一个名为 videos.json 的新文件:
此脚本的所有代码也可在 GitHub 上找到。
使用带有 Bright Data 代理的 lxml
虽然网页抓取是一种从各种来源自动收集数据的好技术,但这个过程并非没有挑战。您必须处理网站实施的反抓取工具、速率限制、地域封锁和缺乏匿名性。代理服务器 可以通过充当掩盖用户 IP 地址的中介来帮助解决这些问题,允许抓取器绕过限制并在不被发现的情况下访问目标数据。Bright Data 是 可靠代理服务 的首选。
以下示例突出显示了使用 Bright Data 代理的简便性。它涉及对 script_scrape.py 文件进行一些更改,以抓取 Books to Scrape 网站。
首先,您需要通过注册免费试用来从 Bright Data 获取代理,该试用提供价值 5 美元的代理资源。创建 Bright Data 帐户后,您将看到以下仪表板:

导航到 我的区域 选项并创建一个新的 住宅代理 区域。创建新区域会显示您的代理用户名、密码和主机名,您在下一步中需要这些信息。
打开 static_scrape.py 文件,在 URL 变量下方添加以下代码:
URL = "https://books.toscrape.com/"
# new
username = ""
password = ""
hostname = ""
proxies = {
"http": f"https://{username}:{password}@{hostname}",
"https": f"https://{username}:{password}@{hostname}",
}
content = requests.get(URL, proxies=proxies).text用您的代理凭据替换 username、password 和 hostname 占位符。此代码指示 requests 库使用指定的代理。脚本的其余部分保持不变。
通过运行以下命令测试您的脚本:
python static_scrape.py运行此脚本后,您将看到与前一个示例类似的输出。
您可以在 GitHub 上查看整个脚本。
结论
lxml 是从 HTML 文档中提取数据的强大且易于使用的工具。lxml 针对速度进行了优化,并支持 XPath 和 CSS 选择器,允许高效解析大型 XML 和 HTML 文档。
在本教程中,您了解了有关使用 lxml 进行网页抓取以及抓取动态和静态内容的所有信息。您还了解了使用 Bright Data 代理服务器如何帮助您绕过网站对抓取器施加的限制。
Bright Data 是您所有网页抓取项目的一站式解决方案。它提供了代理、抓取浏览器和 reCAPTCHA 等功能,使用户能够有效地解决网页抓取挑战。Bright Data 还提供了一个 深入的博客,其中包含与网页抓取相关的教程和最佳实践。
有兴趣开始吗?立即注册并免费测试我们的产品!



