

爬取Zillow,一个在线房地产交易网站,可以为您提供关于房地产市场的宝贵见解,包括市场分析、房地产业趋势以及竞争对手概览。通过爬取Zillow,您可以收集关于房产价格、位置、特点和历史趋势的全面信息,使您能够进行市场分析,了解房地产业的最新趋势,评估竞争对手的策略,并做出符合投资目标的数据驱动决策。
在本教程中,您将学习如何使用Beautiful Soup爬取Zillow的数据。除了学习如何收集有用的数据外,您还将了解Zillow采用的反爬虫技术以及如何使用Bright Data进行帮助。
想跳过爬取直接获取数据?请查看我们的Zillow数据集。
爬取Zillow
无论您是Python新手还是已经有一定经验,本教程将帮助您使用免费的库,如Beautiful Soup或Requests,构建一个网络爬虫。开始吧!
先决条件
在开始之前,建议您对网络爬虫和HTML有基本的了解。您还需要完成以下操作:
- 安装Python:如果您尚未安装Python,请查阅官方文档进行安装。
- 安装Beautiful Soup、Requests、Playwright和pandas库:Beautiful Soup可以通过解析HTML和XML文档轻松提取网页数据。Requests简化了在Python中进行HTTP请求,有助于与Web服务器通信并获取网页内容。pandas是一个功能强大的库,用于操作和分析结构化数据。它提供了有用的数据结构和函数,使清理、转换和分析数据的任务变得更加容易。最后,Python Playwright是一个用于在Python中自动化Web浏览器的库。它允许您与浏览器交互并自动化任务,提供统一的界面、支持无头模式和强大的自动化功能。要下载这些库,请打开您的shell或终端并运行以下命令:
pip3 install beautifulsoup4
pip3 install requests
pip3 install pandas
pip3 install playwright了解Zillow网站结构
在开始爬取Zillow之前,了解其结构非常重要。Zillow的主页上有一个方便的搜索栏,可以搜索房屋、公寓和各种房地产属性。一旦开始搜索,结果会显示在一个页面上,呈现出一系列房产的列表,包括它们的价格、地址和其他相关细节。需要注意的是,这些搜索结果可以根据价格、卧室数量和浴室数量等参数进行排序。
如果您想查看更多的搜索结果,可以使用页面底部的分页按钮。每个页面通常包含四十个列表,允许您访问更多的房产。通过页面左侧的过滤器,您可以根据自己的偏好和要求缩小搜索范围。
要了解网站的HTML结构,您应该按照以下步骤进行:
- 访问Zillow的网站:www.zillow.com。
- 在搜索栏中输入城市或邮政编码并按回车键。
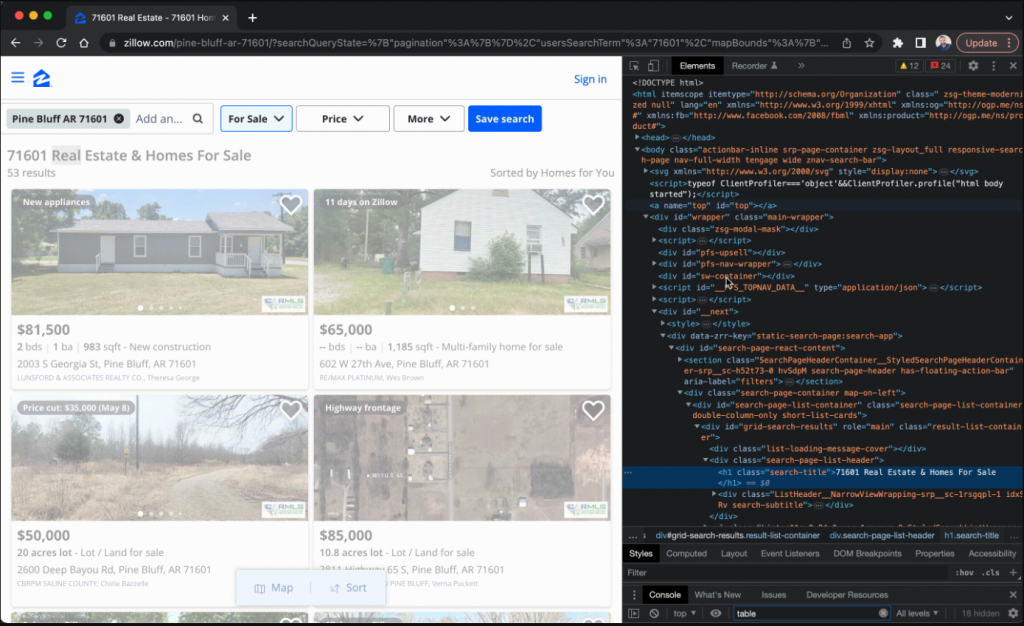
- 右键单击一个房产卡片,然后单击检查以打开浏览器的开发者工具。
- 分析HTML结构以确定包含您要爬取数据的标签和属性。
识别关键数据点
为了有效地从Zillow收集信息,您需要识别您要爬取的确切内容。本指南将向您展示如何提取关于房产的信息,包括以下关键数据点:
- 地址:房产的位置,包括街道地址、城市和州。
- 价格:房产的挂牌价格,提供其当前市场价值的见解。
- Zestimate:Zillow估计的房产市场价值。Zestimate考虑了各种因素,并根据市场趋势和可比房产数据提供大致估值。
- 卧室:房产的卧室数量。
- 浴室:房产的浴室数量。
- 平方英尺:房产的总面积(以平方英尺为单位)。
- 建造年份:房产的建造年份。
- 类型:房产类型,可以包括房屋、公寓、共管公寓或其他相关分类。
Zillow为您提供了广泛的信息,使您能够轻松评估和比较不同的房源,考虑特定社区的价格趋势,评估房产的状况,并识别任何附加设施。此外,通过分析历史和当前的市场数据,您可以了解最新趋势并就购买、出售或投资房地产做出战略决策。
构建爬虫
现在您已经确定了要爬取的内容,是时候构建爬虫了。在这里,您将使用Requests库进行HTTP请求,使用Beautiful Soup解析HTML,并使用Python提取数据。
提取数据
第一步是提取您要查找的数据。创建一个名为scraper.py的新文件,并添加以下代码:
import requests
from bs4 import BeautifulSoup
url = 'https://www.zillow.com/homes/for_sale/San-Francisco_rb/'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'
}
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.content, 'html.parser')
listings = []
for listing in soup.find_all('div', {'class': 'property-card-data'}):
result = {}
result['address'] = listing.find('address', {'data-test': 'property-card-addr'}).get_text().strip()
result['price'] = listing.find('span', {'data-test': 'property-card-price'}).get_text().strip()
details_list = listing.find('ul', {'class': 'dmDolk'})
details = details_list.find_all('li') if details_list else []
result['bedrooms'] = details[0].get_text().strip() if len(details) > 0 else ''
result['bathrooms'] = details[1].get_text().strip() if len(details) > 1 else ''
result['sqft'] = details[2].get_text().strip() if len(details) > 2 else ''
type_div = listing.find('div', {'class': 'gxlfal'})
result['type'] = type_div.get_text().split("-")[1].strip() if type_div else ''
listings.append(result)
print(listings)此代码向Zillow搜索结果页面发送HTTP GET请求,然后使用Beautiful Soup解析HTML。它提取每个房产的数据点,然后打印所有房产信息。
运行爬虫
要运行爬虫,您需要为其提供一个Zillow搜索结果页面的URL。URL应类似于:https://www.zillow.com/homes/for_sale/{city-or-zip}_rb/,其中{city-or-zip}替换为您要爬取的城市或邮政编码。
例如,如果您想收集旧金山待售房屋的信息,您可以使用以下网址:https://www.zillow.com/homes/for_sale/San-Francisco_rb/。
输入网站URL后,保存scraper.py的更改,并在您的shell或终端中运行以下命令:
python3 scraper.py
…output…
[{'address': '19 Tehama St SUITE 3, San Francisco, CA 94105', 'price': '$1,025,000', 'bedrooms': '1 bd', 'bathrooms': '1 ba', 'sqft': '956 sqft', 'type': 'Condo for sale'}, {'address': '267A Chattanooga St, San Francisco, CA 94114', 'price': '$1,740,000', 'bedrooms': '2 bds', 'bathrooms': '3 ba', 'sqft': '2,114 sqft', 'type': 'Condo for sale'}, {'address': '998 Union St, San Francisco, CA 94133', 'price': '$1,650,000', 'bedrooms': '2 bds', 'bathrooms': '1 ba', 'sqft': '1,181 sqft', 'type': 'Condo for sale'}, {'address': '37-39 Mirabel Ave, San Francisco, CA 94110', 'price': '$2,395,000', 'bedrooms': '7 bds', 'bathrooms': '6 ba', 'sqft': '2,300 sqft', 'type': 'Multi'}, {'address': '304 Yale St, San Francisco, CA 94134', 'price': '$1,399,900', 'bedrooms': '3 bds', 'bathrooms': '4 ba', 'sqft': '1,764 sqft', 'type': 'New construction'}, {'address': '173 Coleridge St, San Francisco, CA 94110', 'price': '$745,000', 'bedrooms': '2 bds', 'bathrooms': '2 ba', 'sqft': '905 sqft', 'type': 'Condo for sale'}, {'address': '289 Sadowa St, San Francisco, CA 94112', 'price': '$698,000', 'bedrooms': '4 bds', 'bathrooms': '2 ba', 'sqft': '1,535 sqft', 'type': 'House for sale'}, {'address': '1739 19th Ave, San Francisco, CA 94122', 'price': '$475,791', 'bedrooms': '2 bds', 'bathrooms': '2 ba', 'sqft': '1,780 sqft', 'type': 'Townhouse for sale'}, {'address': '1725 Quesada Ave, San Francisco, CA 94124', 'price': '$600,000', 'bedrooms': '3 bds', 'bathrooms': '2 ba', 'sqft': '1,011 sqft', 'type': 'Condo for sale'}]请记住,进行网页爬取时应尊重网站的
robots.txt文件和服务条款,过度的爬取可能会导致您的IP被封锁。
保存数据
现在您已经提取了数据,需要将其保存为JSON或CSV文件。将数据保存到文件中可以让您处理它并基于所收集的数据创建分析。
要保存数据,请在scraper.py文件顶部导入pandas和json库:
import pandas as pd
import json然后在文件末尾添加以下代码:
#Write data to Json file
with open('listings.json', 'w') as f:
json.dump(listings, f)
print('Data written to Json file')
#Write data to csv
df = pd.DataFrame(listings)
df.to_csv('listings.csv', index=False)
print('Data written to CSV file')此代码将listings数据(一组字典)写入名为listings.json的JSON文件,使用json.dump()。然后,它从listings数据创建一个pandas DataFrame,并使用to_csv()方法将其写入名为listings.csv的CSV文件。代码会打印消息,指示数据已成功写入JSON和CSV文件。
接下来,在您的shell或终端中运行代码:
python3 scraper.py
…output…
[{'address': '19 Tehama St SUITE 3, San Francisco, CA 94105', 'price': '$1,025,000', 'bedrooms': '1 bd', 'bathrooms': '1 ba', 'sqft': '956 sqft', 'type': 'Condo for sale'}, {'address': '267A Chattanooga St, San Francisco, CA 94114', 'price': '$1,740,000', 'bedrooms': '2 bds', 'bathrooms': '3 ba', 'sqft': '2,114 sqft', 'type': 'Condo for sale'}, {'address': '998 Union St, San Francisco, CA 94133', 'price': '$1,650,000', 'bedrooms': '2 bds', 'bathrooms': '1 ba', 'sqft': '1,181 sqft', 'type': 'Condo for sale'}, {'address': '37-39 Mirabel Ave, San Francisco, CA 94110', 'price': '$2,395,000', 'bedrooms': '7 bds', 'bathrooms': '6 ba', 'sqft': '2,300 sqft', 'type': 'Multi'}, {'address': '304 Yale St, San Francisco, CA 94134', 'price': '$1,399,900', 'bedrooms': '3 bds', 'bathrooms': '4 ba', 'sqft': '1,764 sqft', 'type': 'New construction'}, {'address': '173 Coleridge St, San Francisco, CA 94110', 'price': '$745,000', 'bedrooms': '2 bds', 'bathrooms': '2 ba', 'sqft': '905 sqft', 'type': 'Condo for sale'}, {'address': '289 Sadowa St, San Francisco, CA 94112', 'price': '$698,000', 'bedrooms': '4 bds', 'bathrooms': '2 ba', 'sqft': '1,535 sqft', 'type': 'House for sale'}, {'address': '1739 19th Ave, San Francisco, CA 94122', 'price': '$475,791', 'bedrooms': '2 bds', 'bathrooms': '2 ba', 'sqft': '1,780 sqft', 'type': 'Townhouse for sale'}, {'address': '1725 Quesada Ave, San Francisco, CA 94124', 'price': '$600,000', 'bedrooms': '3 bds', 'bathrooms': '2 ba', 'sqft': '1,011 sqft', 'type': 'Condo for sale'}]
Data written to Json file
Data written to CSV file如果一切正常,您应该会在项目目录中找到两个新文件:一个名为listings.csv的文件和一个名为listings.json的文件。这两个文件的内容应类似于这些GitHub仓库文件:listings.csv和listings.json。
如果您多次运行代码,您会注意到成功率较低(大约50%)。这是因为当Zillow检测到自动化爬取时,可能会返回一个CAPTCHA页面而不是实际内容。要提高爬取网站如Zillow的成功率,您需要使用可以帮助您在不同IP之间切换并绕过CAPTCHA的工具。
Zillow采用的反爬虫技术
为了阻止未经许可的数据获取,Zillow采用了一系列不同的方法来防止其网站被自动化爬取(即爬虫)。这些方法包括使用CAPTCHAs、封锁IP地址以及设置蜜罐陷阱。
CAPTCHA是一种用于区分用户是人类还是计算机程序的测试。它通常对人类来说容易解决,但对程序来说很难,可以减慢或阻止数据爬取。</p
>
另一种防止爬虫的方法是封锁IP地址。IP地址类似于计算机的家庭地址。如果一台计算机发送的请求过多(通常发生在数据爬取中),Zillow可以封锁该IP地址以阻止更多请求。这些封锁可以是短期的也可以是长期的,取决于情况的严重程度。
Zillow还使用蜜罐陷阱。这些陷阱是一些只有程序才能看到的数据或链接。如果一个程序与蜜罐陷阱互动,Zillow就知道它是一个机器人,并可以封锁它。
所有这些方法使得从Zillow爬取数据变得困难、耗时,有时甚至是不可能的。任何想要从Zillow爬取数据的人不仅需要了解这些方法,还需要理解与数据爬取相关的法律和道德问题。请记住,Zillow可能会改变其使用这些方法的方式,并且可能不会通知公众。
更好的选择:使用Bright Data爬取Zillow
Bright Data提供了一种更好的选择,通过绕过Zillow采用的反爬虫技术来爬取Zillow的数据。Bright Data的爬取浏览器允许您在Bright Data的网络上运行Puppeteer脚本,这提供了数百万个IP地址的访问,并防止被Zillow的反爬虫技术检测到。
使用Bright Data的爬取浏览器爬取Zillow
要使用Bright Data的爬取浏览器爬取Zillow,请按照以下步骤操作:
1. 创建Bright Data账户
如果您还没有Bright Data账户,请访问Bright Data的网站,点击开始免费试用,并按照提示操作。
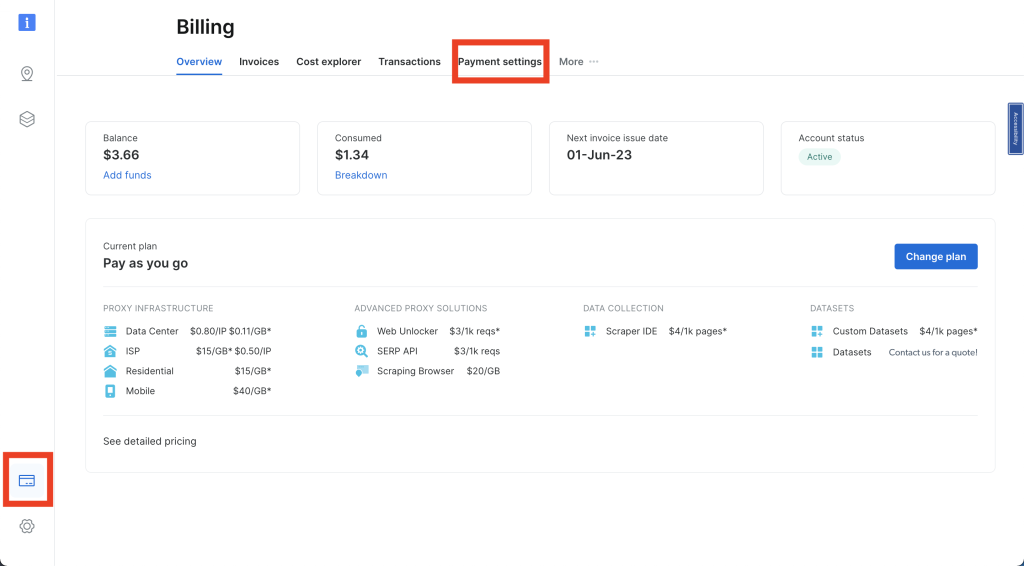
登录到您的Bright Data账户后,点击导航栏左下角的信用卡图标进入账单,根据您的首选方式添加支付方式;否则,您将无法激活您的账户:
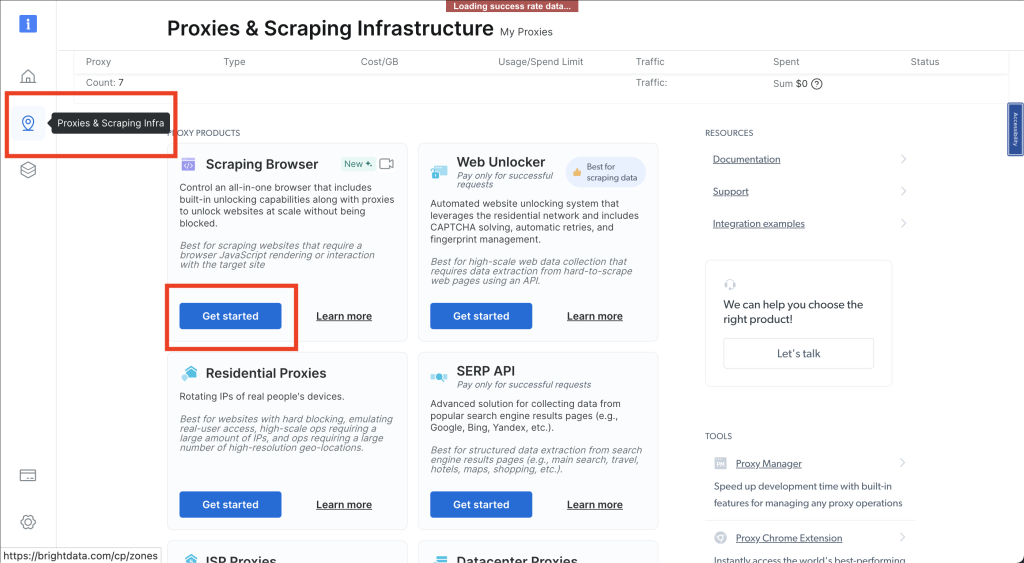
接下来,点击图钉图标,打开代理和爬取基础设施页面;然后选择爬取浏览器 > 开始使用:
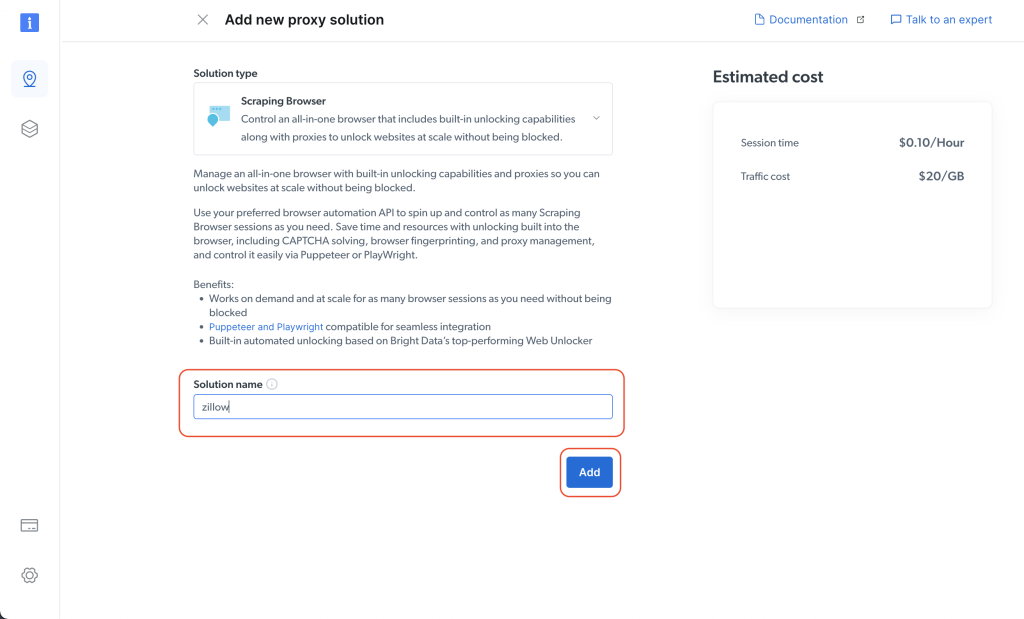
接下来,指定您的解决方案名称;然后点击添加按钮:
然后点击访问参数,记下您的用户名、主机和密码,因为它们将在稍后的教程中需要:
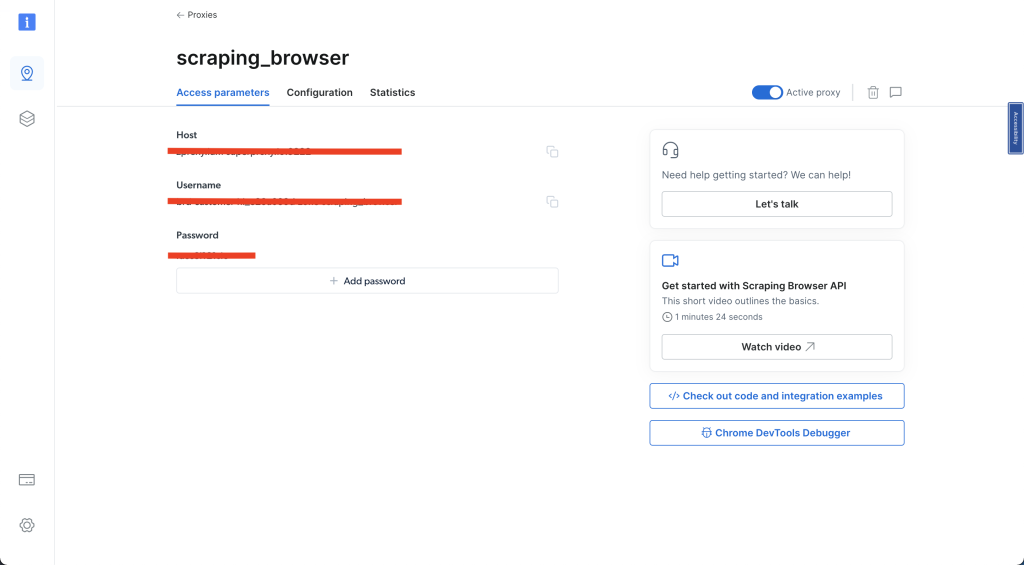
完成上述步骤后,您就可以继续了。
2. 编写爬虫
创建一个名为scraper-brightdata.py的新文件,并添加以下代码:
import asyncio
from playwright.async_api import async_playwright
import json
import pandas as pd
username='YOUR_BRIGHTDATA_USERNAME'
password='YOUR_BRIGHTDATA_PASSWORD'
auth=f'{username}:{password}'
host = 'YOUR_BRIGHTDATA_HOST'
browser_url = f'wss://{auth}@{host}'
async def main():
async with async_playwright() as pw:
print('Connecting to a remote browser...')
browser = await pw.chromium.connect_over_cdp(browser_url)
print('Connected. Opening new page...')
page = await browser.new_page()
print('Navigating to Zillow...')
await page.goto('https://www.zillow.com/homes/for_sale/San-Francisco_rb/', timeout=3600000)
print('Scraping data...')
listings = []
properties = await page.query_selector_all('div.property-card-data')
for property in properties:
result = {}
address = await property.query_selector('address[data-test="property-card-addr"]')
result['address'] = await address.inner_text() if address else ''
price = await property.query_selector('span[data-test="property-card-price"]')
result['price'] = await price.inner_text() if price else ''
details = await property.query_selector_all('ul.dmDolk > li')
result['bedrooms'] = await details[0].inner_text() if len(details) >= 1 else ''
result['bathrooms'] = await details[1].inner_text() if len(details) >= 2 else ''
result['sqft'] = await details[2].inner_text() if len(details) >= 3 else ''
type_div = await property.query_selector('div.gxlfal')
result['type'] = (await type_div.inner_text()).split("-")[1].strip() if type_div else ''
listings.append(result)
await browser.close()
return listings
# Run the asynchronous function
listings = asyncio.run(main())
# Print the listings
for listing in listings:
print(listing)
# Write data to Json file
with open('listings-brightdata.json', 'w') as f:
json.dump(listings, f)
print('Data written to Json file')
# Write data to csv
df = pd.DataFrame(listings)
df.to_csv('listings-brightdata.csv', index=False)
print('Data written to CSV file')确保将YOUR_BRIGHTDATA_USERNAME、YOUR_BRIGHTDATA_PASSWORD和YOUR_BRIGHTDATA_HOST替换为您的实际Bright Data账户凭据。
3. 运行爬虫
保存对 scraper-brightdata.py的更改,并在您的shell或终端中运行代码:
python3 scraper-brightdata.py
…output…
Connecting to a remote browser...
Connected. Opening new page...
Navigating to Zillow...
Scraping data...
{'address': '1438 Green St UNIT 2B, San Francisco, CA 94109', 'price': '$995,000', 'bedrooms': '1 bd', 'bathrooms': '1 ba', 'sqft': '974 sqft', 'type': 'Condo for sale'}
{'address': '815 Tennessee St UNIT 504, San Francisco, CA 94107', 'price': '$1,195,000', 'bedrooms': '2 bds', 'bathrooms': '2 ba', 'sqft': '-- sqft', 'type': ''}
{'address': '455 27th Ave, San Francisco, CA 94121', 'price': '$1,375,000', 'bedrooms': '2 bds', 'bathrooms': '1 ba', 'sqft': '1,040 sqft', 'type': 'House for sale'}
{'address': '19 Tehama St SUITE 3, San Francisco, CA 94105', 'price': '$1,025,000', 'bedrooms': '1 bd', 'bathrooms': '1 ba', 'sqft': '956 sqft', 'type': 'Condo for sale'}
{'address': '267A Chattanooga St, San Francisco, CA 94114', 'price': '$1,740,000', 'bedrooms': '2 bds', 'bathrooms': '3 ba', 'sqft': '2,114 sqft', 'type': 'Condo for sale'}
{'address': '998 Union St, San Francisco, CA 94133', 'price': '$1,650,000', 'bedrooms': '2 bds', 'bathrooms': '1 ba', 'sqft': '1,181 sqft', 'type': 'Condo for sale'}
{'address': '37-39 Mirabel Ave, San Francisco, CA 94110', 'price': '$2,395,000', 'bedrooms': '7 bds', 'bathrooms': '6 ba', 'sqft': '2,300 sqft', 'type': 'Multi'}
{'address': '304 Yale St, San Francisco, CA 94134', 'price': '$1,399,900', 'bedrooms': '3 bds', 'bathrooms': '4 ba', 'sqft': '1,764 sqft', 'type': 'New construction'}
{'address': '173 Coleridge St, San Francisco, CA 94110', 'price': '$745,000', 'bedrooms': '2 bds', 'bathrooms': '2 ba', 'sqft': '905 sqft', 'type': 'Condo for sale'}
Data written to Json file
Data written to CSV file此代码连接到Bright Data爬取浏览器,导航到Zillow搜索结果页面,并提取数据。接下来,代码打印结果,然后将listings数据(一组字典)写入名为listings-brightdata.json的JSON文件,使用json.dump()。然后,它从listings数据创建一个pandas DataFrame,并使用to_csv()方法将其写入名为listings-brightdata.csv的CSV文件。代码会打印消息,指示数据已成功写入JSON和CSV文件。
如果一切正常,您应该会找到两个文件:一个listings-brightdata.csv文件和一个listings-brightdata.json文件。这些文件应类似于listings-brightdata.json和listings-brightdata.csv。
如果您多次运行代码,发现文件中没有保存任何数据,这意味着您的IP已被Zillow封锁或浏览器在完成之前关闭。如果浏览器在爬取完成之前关闭,您需要将timeout更改为更大的值,这在前面的代码中与await page.goto('https://www.zillow.com/homes/for_sale/San-Francisco_rb/', timeout=3600000)相关。
如果您的IP被Zillow封锁,您需要更改您的区域,幸运的是,Bright Data为您提供了多个区域的访问权限。
要在不同区域之间切换,请点击图钉图标进入代理和爬取基础设施页面,然后选择爬取浏览器并点击访问参数。接下来,点击</> 查看代码和集成示例:
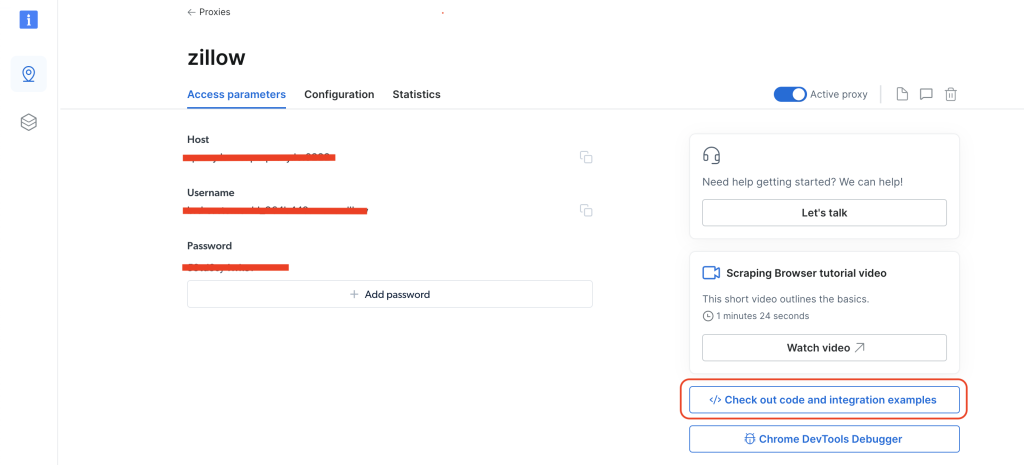
选择Python作为语言,在右侧导航中,有一个国家下拉列表。选择您想要的国家,您的区域将同时更新。您应看到auth变量在Python示例代码中发生变化。您需要从auth变量中获取与该区域相关的用户名。主要是,auth变量包含用户名和密码,格式如下username:password:
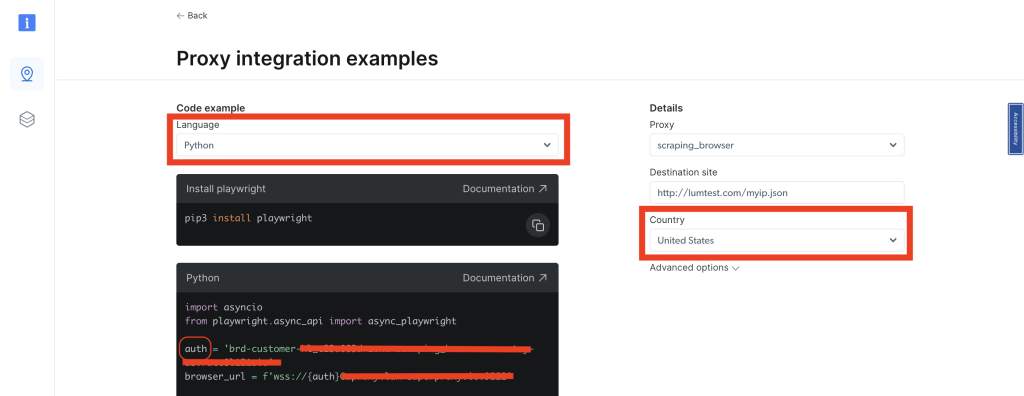
每次更改国家时,您会为该特定国家/区域获得不同的用户。根据您获取的用户名和所选国家,将用户放入您的代码中并再次运行。
结论
在本教程中,您学习了如何使用Beautiful Soup爬取Zillow的数据。您还了解了Zillow采用的反爬虫技术以及如何绕过这些技术。为了解决这些问题,介绍了Bright Data的爬取浏览器,帮助您超越Zillow的反爬虫机制,轻松提取所需的数据。







