

在本分步指南中,您将学习如何使用Python抓取Reddit。
本教程将涵盖:
- Reddit新的API政策
- Reddit API与Reddit抓取的区别
- 使用Selenium抓取Reddit
Reddit新的API政策
在2023年4月,Reddit宣布对其数据API收取新费用,这使得较小的公司无法负担。截至撰写本文时,API费用定为每1000次调用0.24美元。可以想象,即使是适度的使用,这个数字也会迅速增加。考虑到Reddit上大量的用户生成内容和获取这些内容所需的大量调用,这尤其如此。最常用的第三方应用Apollo由于这个原因被迫关闭。
这是否意味着Reddit作为情感分析、用户反馈和趋势数据来源的终结?当然不是!有一种更有效、成本更低且不受公司临时决策影响的解决方案。这个解决方案就是网络抓取。让我们看看为什么吧!
Reddit API与Reddit抓取的区别
Reddit的API是从网站获取数据的官方方法。考虑到平台最近的政策变化和方向,以下是Reddit抓取更好的原因:
- 成本效益:鉴于Reddit的新API费用,抓取Reddit可以是一个更实惠的替代方案。构建一个Python的Reddit抓取器可以让您在不产生与API使用相关的额外费用的情况下收集数据。
- 增强的数据收集:在抓取Reddit时,您可以灵活地定制数据提取代码,以获取仅符合您要求的信息。这种定制有助于您克服API中数据格式、速率限制和使用限制的限制。
- 访问非官方数据:虽然Reddit的API仅提供对精选信息的访问,但抓取可以访问站点上任何公开可访问的数据。
现在您知道为什么抓取比调用API更有效,让我们看看如何在Python中构建一个Reddit抓取器。在进入下一章之前,请考虑探索我们关于使用Python进行网络抓取的深入指南。
使用Selenium抓取Reddit
在本分步教程中,您将学习如何构建一个Reddit网页抓取Python脚本。
步骤1:项目设置
首先确保满足以下先决条件:
- Python 3+:下载安装程序,双击并按照安装说明进行操作。
- 一个Python IDE:PyCharm社区版或带有Python扩展的Visual Studio Code均可。
通过以下命令初始化一个Python项目并创建一个虚拟环境:
mkdir reddit-scraper
cd reddit-scraper
python -m venv env这里创建的reddit-scraper文件夹是您的Python脚本的项目文件夹。
在IDE中打开该目录,创建一个scraper.py文件,并初始化如下:
print('Hello World!')现在,这个脚本只是打印“Hello World!”,但它很快就会包含抓取逻辑。
通过按IDE的运行按钮或启动以下命令来验证程序是否正常工作:
python scraper.py在终端中,您应该会看到:
Hello World!太好了!您现在已经有了一个Python项目来构建您的Reddit抓取器。
步骤2:选择并安装抓取库
正如您可能已经知道的那样,Reddit是一个高度互动的平台。该网站根据用户通过点击和滚动操作与其页面的互动动态加载和呈现新数据。从技术角度来看,这意味着Reddit高度依赖JavaScript。
因此,在Python中抓取Reddit需要一个可以在浏览器中渲染网页的工具。这就是Selenium的作用!此工具允许在Python中抓取动态网站,从而在浏览器中自动执行网页操作。
您可以通过以下命令将Selenium和Webdriver Manager添加到项目的依赖项中:
pip install selenium webdriver-manager安装过程可能需要一些时间,请耐心等待。
webdriver-manager包不是严格必要的,但强烈推荐。它可以避免手动下载、安装和配置Selenium中的web驱动程序。该库将为您处理所有这些工作。
将Selenium集成到scraper.py文件中:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.chrome.options import Options
# enable the headless mode
options = Options()
options.add_argument('--headless=new')
# initialize a web driver to control Chrome
driver = webdriver.Chrome(
service=ChromeService(ChromeDriverManager().install()),
options=options
)
# maxime the controlled browser window
driver.fullscreen_window()
# scraping logic...
# close the browser and free up the Selenium resources
driver.quit()该脚本实例化了一个Chrome的WebDriver对象以编程方式控制一个Chrome窗口。
默认情况下,Selenium在新的GUI窗口中打开浏览器。这对于监视脚本在页面上的操作以进行调试很有用。同时,加载一个带有用户界面的web浏览器需要大量资源。因此,建议配置Chrome以无头模式运行。具体来说,--headless=new选项将指示Chrome在后台启动,没有UI。
干得好!是时候访问目标Reddit页面了!
步骤3:连接到Reddit
在这里,您将看到如何从r/Technology子Reddit中提取数据。请记住,其他任何子Reddit也可以。
具体来说,假设您想抓取一周内热门帖子的页面。目标页面的URL如下:
https://www.reddit.com/r/technology/top/?t=week将该字符串存储在一个Python变量中:
url = 'https://www.reddit.com/r/technology/top/?t=week'然后,使用Selenium访问该页面:
driver.get(url)get()函数指示受控浏览器连接到由URL参数标识的页面。
这是您目前的Reddit网页抓取器的样子:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.chrome.options import Options
# enable the headless mode
options = Options()
options.add_argument('--headless=new')
# initialize a web driver to control Chrome
driver = webdriver.Chrome(
service=ChromeService(ChromeDriverManager().install()),
options=options
)
# maxime the controlled browser window
driver.fullscreen_window()
# the URL of the target page to scrape
url = 'https://www.reddit.com/r/technology/top/?t=week'
# connect to the target URL in Selenium
driver.get(url)
# scraping logic...
# close the browser and free up the Selenium resources
driver.quit()测试您的脚本。它将在短暂的时间内打开浏览器窗口,然后由于quit()指令而关闭:
看看“Chrome正在受自动化测试软件控制。”消息。很好!这确保了Selenium在Chrome上正常运行。
步骤4:检查目标页面
在编写代码之前,您需要探索目标页面,以了解它提供了哪些信息以及如何获取这些信息。特别是,您必须确定哪些HTML元素包含感兴趣的数据,并制定适当的选择策略。
为了模拟Selenium操作的条件,即“原始”浏览器会话,请以隐身模式打开Reddit页面。在页面的任意部分右键单击并选择“检查”以打开Chrome开发者工具:
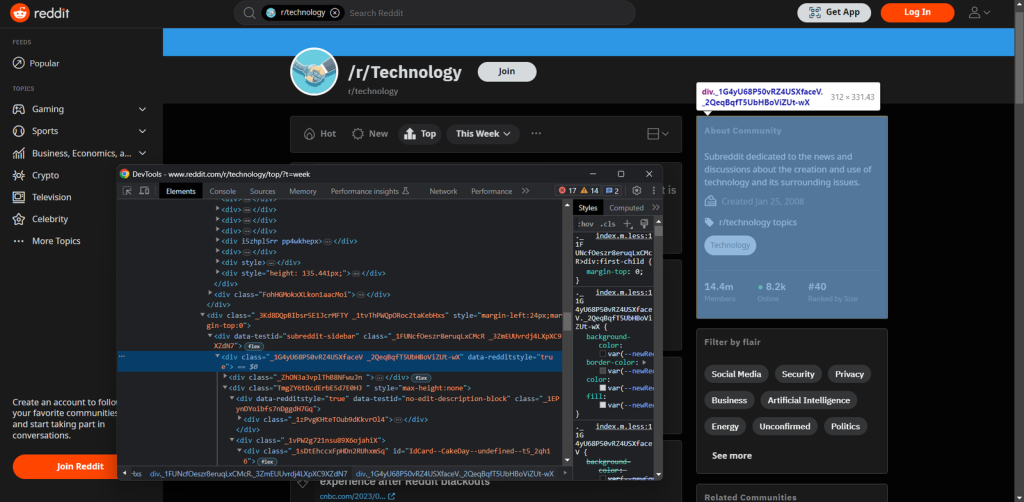
此工具帮助您了解页面的DOM结构。正如您所看到的,该网站依赖于在构建时似乎随机生成的CSS类。换句话说,您不应该基于这些类来制定选择策略。
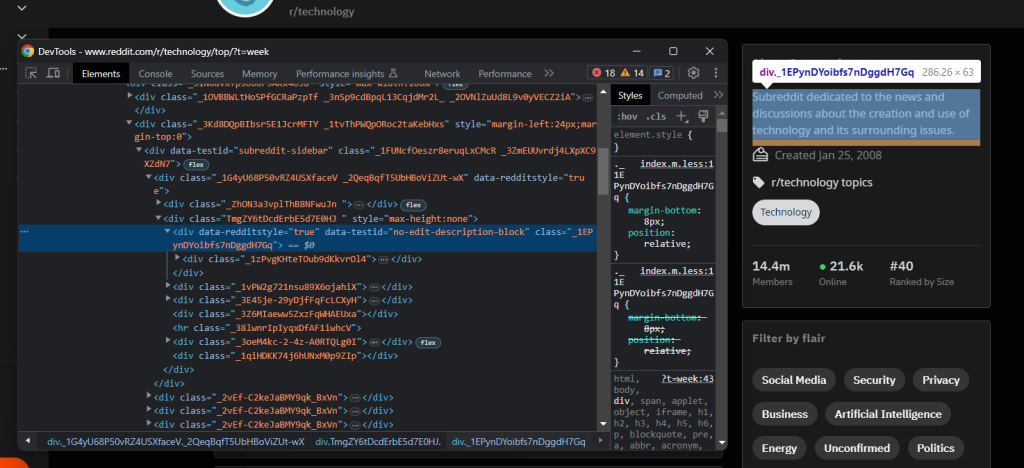
幸运的是,网站上最重要的元素具有特殊的HTML属性。例如,子Reddit描述节点具有以下属性:
data-testid="no-edit-description-block"这对于构建有效的HTML元素选择逻辑非常有用。
继续在开发者工具中分析该站点,并熟悉其DOM,直到您准备好在Python中抓取Reddit。
步骤5:抓取子Reddit的主要信息
首先,创建一个Python字典来存储抓取的数据:
subreddit = {}然后,请注意,您可以从页面顶部的<h1>元素中获取子Reddit的名称:
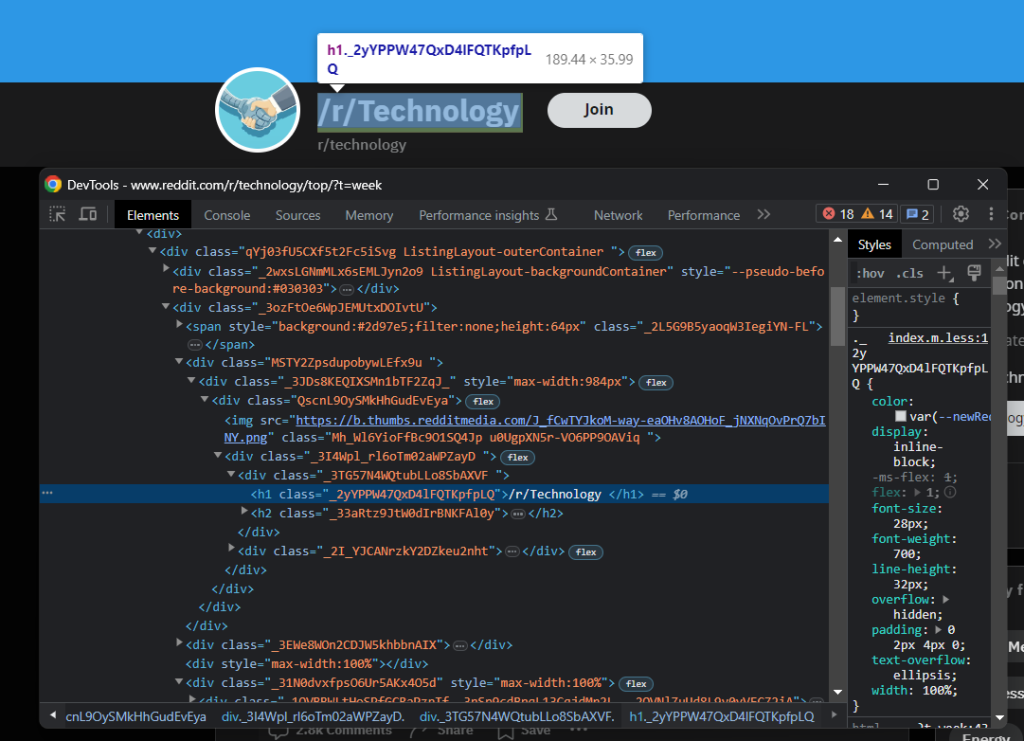
如下检索它:
name = driver \
.find_element(By.TAG_NAME, 'h1') \
.text正如您已经注意到的那样,一些关于子Reddit的最有趣的一般信息位于右侧的侧栏中:
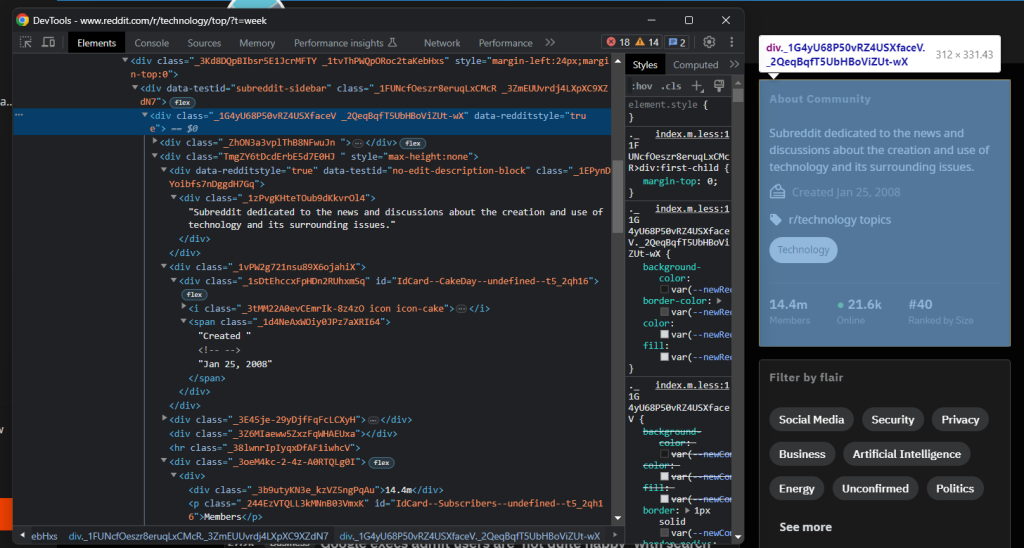
您可以通过以下方式获取文本描述、创建日期和成员数:
description = driver \
.find_element(By.CSS_SELECTOR, '[data-testid="no-edit-description-block"]') \
.get_attribute('innerText')
creation_date = driver \
.find_element(By.CSS_SELECTOR, '.icon-cake') \
.find_element(By.XPATH, "following-sibling::*[1]") \
.get_attribute('innerText') \
.replace('Created ', '')
members = driver \
.find_element(By.CSS_SELECTOR, '[id^="IdCard--Subscribers"]') \
.find_element(By.XPATH, "preceding-sibling::*[1]") \
.get_attribute('innerText')在这种情况下,您不能使用text属性,因为文本字符串包含在嵌套节点中。如果使用.text,将获得一个空字符串。相反,您需要调用get_attribute()方法来读取innerText属性,该属性返回节点及其子节点的渲染文本内容。
如果查看创建日期元素,您会注意到没有简单的方法来选择它。因为它是蛋糕图标之后的节点,先用.icon-cake选择图标,然后使用following-sibling::*[1]XPath表达式来获取下一个兄弟节点。通过调用Python的replace()方法来清理收集的文本,删除“Created ”字符串。
当涉及到订阅者成员计数器元素时,情况类似。主要区别在于,您需要访问前面的兄弟节点。
不要忘记将抓取的数据添加到subreddit字典中:
subreddit['name'] = name
subreddit['description'] = description
subreddit['creation_date'] = creation_date
subreddit['members'] = members用print(subreddit)打印subreddit,您将看到:
{'name': '/r/Technology', 'description': 'Subreddit dedicated to the news and discussions about the creation and use of technology and its surrounding issues.', 'creation_date': 'Jan 25, 2008', 'members': '14.4m'}完美!您刚刚在Python中执行了网络抓取!
步骤6:抓取子Reddit帖子
由于一个子Reddit显示了多个帖子,您现在需要一个数组来存储收集的数据:
posts = []检查一个帖子HTML元素:
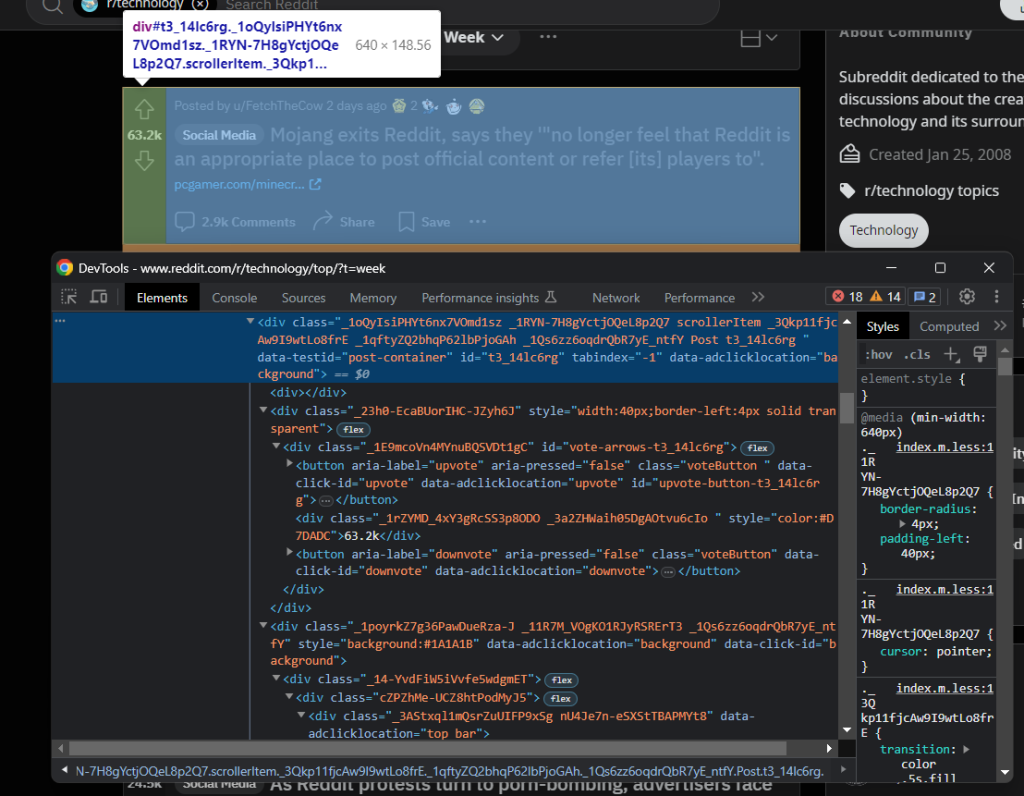
在这里您可以注意到,可以使用[data-testid="post-container"]CSS选择器选择所有这些元素:
post_html_elements = driver \
.find_elements(By.CSS_SELECTOR, '[data-testid="post-container"]')遍历它们。对于每个元素,创建一个帖子字典来记录单个帖子的数据信息:
for post_html_element in post_html_elements:
post = {}
# scraping logic...检查点赞元素:
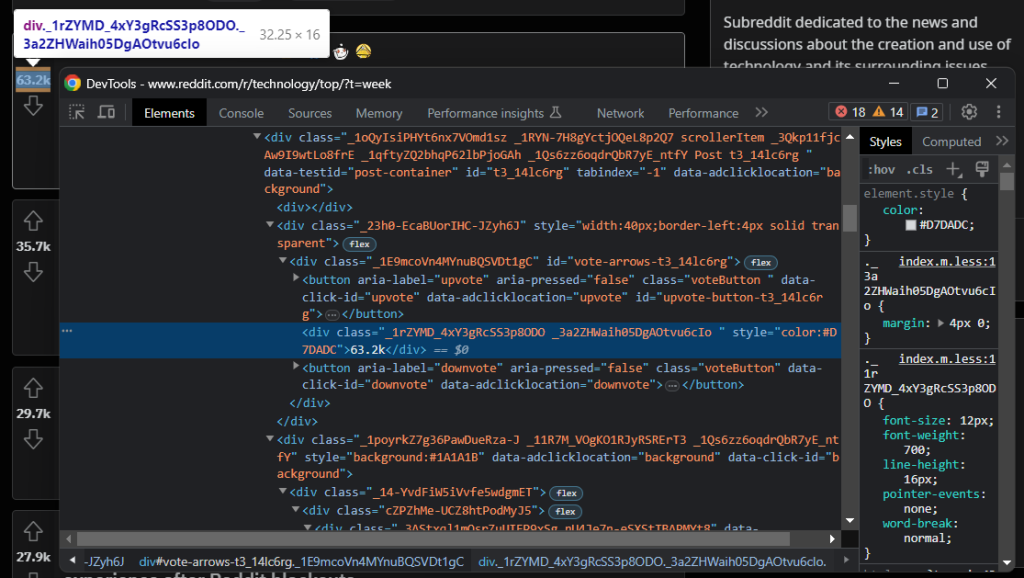
您可以在for循环中通过以下方式检索该信息:
upvotes = post_html_element \
.find_element(By.CSS_SELECTOR, '[data-click-id="upvote"]') \
.find_element(By.XPATH, "following-sibling::*[1]") \
.get_attribute('innerText')同样,最好获取容易选择的点赞按钮,然后指向下一个兄弟节点以获取目标信息。
检查帖子的作者和标题元素:
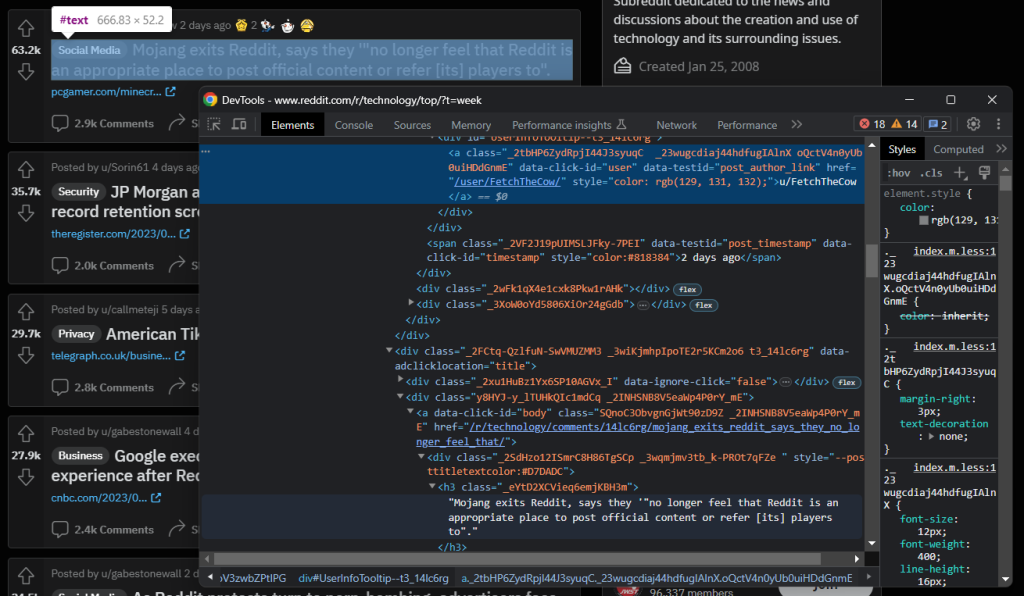
获取这些数据要容易得多:
author = post_html_element \
.find_element(By.CSS_SELECTOR, '[data-testid="post_author_link"]') \
.text
title = post_html_element \
.find_element(By.TAG_NAME, 'h3') \
.text然后,您可以收集评论数和外部链接:
try:
outbound_link = post_html_element \
.find_element(By.CSS_SELECTOR, '[data-testid="outbound-link"]') \
.get_attribute('href')
except NoSuchElementException:
outbound_link = None
comments = post_html_element \
.find_element(By.CSS_SELECTOR, '[data-click-id="comments"]') \
.get_attribute('innerText') \
.replace(' Comments', '')由于外部链接元素是可选的,因此需要用try块包装选择逻辑。
将这些数据添加到post中,并仅在title存在时将其附加到posts数组中。此额外检查可防止Reddit放置的特殊广告帖子被抓取:
# 使用检索到的数据填充字典
post['upvotes'] = upvotes
post['title'] = title
post['outbound_link'] = outbound_link
post['comments'] = comments
# to avoid adding ad posts
# to the list of scraped posts
if title:
posts.append(post)最后,将posts添加到subreddit字典中:
subreddit['posts'] = posts太棒了!您现在拥有所有所需的Reddit数据了!
步骤7:将抓取的数据导出为JSON
收集的数据现在存储在Python字典中。这不是与其他团队共享它的最佳格式。为了解决这个问题,您应该将其导出为JSON:
import json
# ...
with open('subreddit.json', 'w') as file:
json.dump(video, file)从Python标准库中导入json,使用open()创建一个subreddit.json文件,并用json.dump()填充它。查看我们的指南,了解有关如何在Python中解析JSON的更多信息。
太棒了!您从动态HTML页面中的原始数据开始,现在已经有了半结构化的JSON数据。您现在可以查看整个Reddit抓取器了。
步骤8:整合所有内容
这是完整的scraper.py脚本:
from selenium import webdriver
from selenium.common import NoSuchElementException
from selenium.webdriver.chrome.service import Service as ChromeService
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
import json
# enable the headless mode
options = Options()
options.add_argument('--headless=new')
# initialize a web driver to control Chrome
driver = webdriver.Chrome(
service=ChromeService(ChromeDriverManager().install()),
options=options
)
# maxime the controlled browser window
driver.fullscreen_window()
# the URL of the target page to scrape
url = 'https://www.reddit.com/r/technology/top/?t=week'
# connect to the target URL in Selenium
driver.get(url)
# initialize the dictionary that will contain
# the subreddit scraped data
subreddit = {}
# subreddit scraping logic
name = driver \
.find_element(By.TAG_NAME, 'h1') \
.text
description = driver \
.find_element(By.CSS_SELECTOR, '[data-testid="no-edit-description-block"]') \
.get_attribute('innerText')
creation_date = driver \
.find_element(By.CSS_SELECTOR, '.icon-cake') \
.find_element(By.XPATH, "following-sibling::*[1]") \
.get_attribute('innerText') \
.replace('Created ', '')
members = driver \
.find_element(By.CSS_SELECTOR, '[id^="IdCard--Subscribers"]') \
.find_element(By.XPATH, "preceding-sibling::*[1]") \
.get_attribute('innerText')
# add the scraped data to the dictionary
subreddit['name'] = name
subreddit['description'] = description
subreddit['creation_date'] = creation_date
subreddit['members'] = members
# to store the post scraped data
posts = []
# retrieve the list of post HTML elements
post_html_elements = driver \
.find_elements(By.CSS_SELECTOR, '[data-testid="post-container"]')
for post_html_element in post_html_elements:
# to store the data scraped from the
# post HTML element
post = {}
# subreddit post scraping logic
upvotes = post_html_element \
.find_element(By.CSS_SELECTOR, '[data-click-id="upvote"]') \
.find_element(By.XPATH, "following-sibling::*[1]") \
.get_attribute('innerText')
author = post_html_element \
.find_element(By.CSS_SELECTOR, '[data-testid="post_author_link"]') \
.text
title = post_html_element \
.find_element(By.TAG_NAME, 'h3') \
.text
try:
outbound_link = post_html_element \
.find_element(By.CSS_SELECTOR, '[data-testid="outbound-link"]') \
.get_attribute('href')
except NoSuchElementException:
outbound_link = None
comments = post_html_element \
.find_element(By.CSS_SELECTOR, '[data-click-id="comments"]') \
.get_attribute('innerText') \
.replace(' Comments', '')
# populate the dictionary with the retrieved data
post['upvotes'] = upvotes
post['title'] = title
post['outbound_link'] = outbound_link
post['comments'] = comments
# to avoid adding ad posts
# to the list of scraped posts
if title:
posts.append(post)
subreddit['posts'] = posts
# close the browser and free up the Selenium resources
driver.quit()
# export the scraped data to a JSON file
with open('subreddit.json', 'w', encoding='utf-8') as file:
json.dump(subreddit, file, indent=4, ensure_ascii=False)太棒了!您可以使用略多于100行代码构建一个Python的Reddit网页抓取器!
启动脚本,subreddit.json文件将出现在项目根文件夹中:
{
"name": "/r/Technology",
"description": "Subreddit dedicated to the news and discussions about the creation and use of technology and its surrounding issues.",
"creation_date": "Jan 25, 2008",
"members": "14.4m",
"posts": [
{
"upvotes": "63.2k",
"title": "Mojang exits Reddit, says they '\"no longer feel that Reddit is an appropriate place to post official content or refer [its] players to\".",
"outbound_link": "https://www.pcgamer.com/minecrafts-devs-exit-its-7-million-strong-subreddit-after-reddits-ham-fisted-crackdown-on-protest/",
"comments": "2.9k"
},
{
"upvotes": "35.7k",
"title": "JP Morgan accidentally deletes evidence in multi-million record retention screwup",
"outbound_link": "https://www.theregister.com/2023/06/26/jp_morgan_fined_for_deleting/",
"comments": "2.0k"
},
# omitted for brevity ...
{
"upvotes": "3.6k",
"title": "Facebook content moderators in Kenya call the work 'torture.' Their lawsuit may ripple worldwide",
"outbound_link": "https://techxplore.com/news/2023-06-facebook-content-moderators-kenya-torture.html",
"comments": "188"
},
{
"upvotes": "3.6k",
"title": "Reddit is telling protesting mods their communities ‘will not’ stay private",
"outbound_link": "https://www.theverge.com/2023/6/28/23777195/reddit-protesting-moderators-communities-subreddits-private-reopen",
"comments": "713"
}
]
}恭喜!您刚刚学会了如何在Python中抓取Reddit!
结论
抓取Reddit是一种获取数据的更好方式,特别是在新政策之后。在本分步教程中,您学习了如何构建一个Python抓取器来获取子Reddit数据。如本文所示,这仅需要几行代码。
与此同时,就像他们一夜之间改变了API政策一样,Reddit可能很快会实施严格的反抓取措施。从中提取数据将变得很困难,但有一个解决方案!Bright Data的抓取浏览器是一种工具,可以像Selenium一样渲染JavaScript,同时自动处理指纹、CAPTCHA和反抓取。
如果这不是您的菜,我们构建了一个Reddit抓取器来满足您的需求。借助这一可靠且易于使用的解决方案,您可以无忧地获取所有Reddit数据。
不想处理Reddit网页抓取但对子Reddit数据感兴趣?购买Reddit数据集。



