
在本文中,您将逐步学习如何使用 Google Scholar 的页面数据并使用 Python 进行爬取。在正式开始之前,我们会先了解相关的先决条件以及如何搭建环境。让我们开始吧!
手动爬取 Google Scholar 的替代方案
手动爬取 Google Scholar 可能非常具有挑战性且耗费时间。与其如此,您可以考虑使用 Bright Data 的数据集:
- 数据集市场 (Dataset Marketplace):访问已经预先收集好的、可立即使用的数据。
- 自定义数据集 (Custom Datasets):可以根据您的需求来请求或创建定制化的数据集。
使用 Bright Data 的服务能够节省时间,并确保您获得准确、最新的信息,而无需自己处理复杂的手动爬取流程。现在,让我们继续吧!
先决条件
在开始本教程之前,您需要安装以下内容:
- 最新版本的 Python
- 任意一款您喜欢的代码编辑器,例如 Visual Studio Code
此外,在开始任何爬取项目之前,您都需要确保自己的脚本遵守目标网站的 robots.txt 文件,以避免爬取受限制的区域。本文中的代码仅用于学习目的,使用时请务必保持责任感。
创建 Python 虚拟环境
在设置 Python 虚拟环境之前,先切换到您想要的新项目存放路径,然后创建一个名为 google_scholar_scraper 的新文件夹:
mkdir google_scholar_scraper
cd google_scholar_scraper
创建好 google_scholar_scraper 文件夹后,可以使用以下命令为该项目创建一个虚拟环境:
python -m venv google_scholar_env
在 Linux/Mac 上,使用以下命令激活您的虚拟环境:
source google_scholar_env/bin/activate
如果您使用的是 Windows,则使用以下命令:
.\google_scholar_env\Scripts\activate
安装所需的第三方包
当 venv 激活之后,您需要安装 Beautiful Soup 和 pandas:
pip install beautifulsoup4 pandas
Beautiful Soup 有助于解析 Google Scholar 页面中的 HTML 结构,并提取特定数据元素(如文章、标题、作者等)。pandas 能够将您提取到的数据转换成结构化格式,并将其存储为 CSV 文件。
除了 Beautiful Soup 和 pandas,您还需要安装 Selenium。像 Google Scholar 这样的站点通常会实施一些策略来阻止过度频繁的自动化请求,以避免负载过高。Selenium 可以通过自动化浏览器操作、模拟用户行为来帮助您绕过这些限制。
使用以下命令安装 Selenium:
pip install selenium
请确保您使用的是 Selenium 的最新版本(在撰写本文时为 4.6.0),这样您就不需要手动下载 ChromeDriver 了。
创建 Python 脚本访问 Google Scholar
在成功激活虚拟环境并安装所需库后,您就可以开始爬取 Google Scholar 了。
在 google_scholar_scraper 文件夹内新建一个名为 gscholar_scraper.py 的 Python 文件,并导入所需的库:
from bs4 import BeautifulSoup
import pandas as pd
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
接下来,您将配置 Selenium WebDriver 来控制无头模式(headless)的 Chrome 浏览器(即无需打开浏览器界面)。这样做有助于您在后台进行数据爬取。将以下函数添加到脚本中,用于初始化 Selenium WebDriver:
def init_selenium_driver():
chrome_options = Options()
chrome_options.add_argument("--headless")
chrome_options.add_argument("--no-sandbox")
chrome_options.add_argument("--disable-dev-shm-usage")
driver = webdriver.Chrome(options=chrome_options)
return driver
当您初始化好 WebDriver 后,需要再添加一个函数,该函数利用 Selenium WebDriver 向 Google Scholar 发送搜索请求:
def fetch_search_results(driver, query):
base_url = "https://scholar.google.com/scholar"
params = f"?q={query}"
driver.get(base_url + params)
driver.implicitly_wait(10) # 最长等待 10 秒,以确保页面加载完成
# 返回页面源代码(HTML 内容)
return driver.page_source
在上面的代码中,driver.get(base_url + params) 告知 Selenium WebDriver 前往组合后的 URL。与此同时,driver.implicitly_wait(10) 会在解析前,为页面中所有元素的加载预留最长 10 秒钟的等待时间。
解析 HTML 内容
当您拿到了搜索结果页面的 HTML 内容后,需要一个函数来对其进行解析并提取您需要的信息。
要精准获取文章所对应的 CSS 选择器和元素,您需要手动检查 Google Scholar 页面。可以使用浏览器的开发者工具,寻找标题、作者和摘要对应的唯一类名或 ID(例如 gs_rt 对应标题,如下图所示):
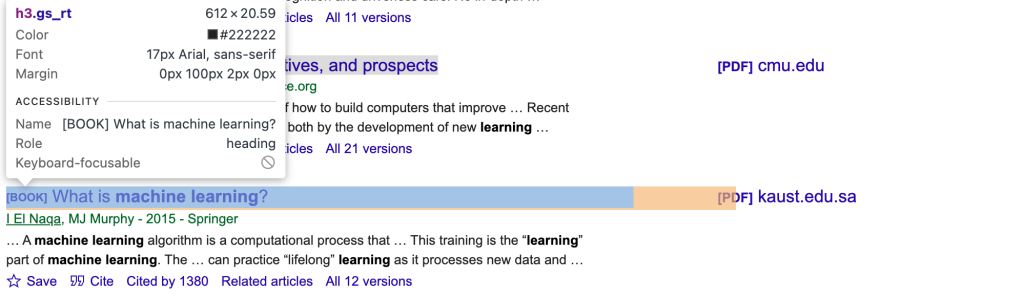
然后,更新脚本:
def parse_results(html):
soup = BeautifulSoup(html, 'html.parser')
articles = []
for item in soup.select('.gs_ri'):
title = item.select_one('.gs_rt').text
authors = item.select_one('.gs_a').text
snippet = item.select_one('.gs_rs').text
articles.append({'title': title, 'authors': authors, 'snippet': snippet})
return articles
此函数利用 BeautifulSoup 在 HTML 结构中进行遍历、找到包含文章信息的元素,并提取每篇文章的标题、作者和摘要,最终组合成一个字典列表。
您会注意到,更新的脚本中包含 .select('.gs_ri'),这会匹配 Google Scholar 页面上每条搜索结果的外层元素。然后,再使用更细分的选择器(.gs_rt、.gs_a 和 .gs_rs)提取各个搜索结果的标题、作者以及摘要信息。
运行脚本
要测试此爬虫脚本,可以在 __main__ 中执行一次 “machine learning” 的搜索:
if __name__ == "__main__":
search_query = "machine learning"
# Initialize the Selenium WebDriver
driver = init_selenium_driver()
try:
html_content = fetch_search_results(driver, search_query)
articles = parse_results(html_content)
df = pd.DataFrame(articles)
print(df.head())
finally:
driver.quit()fetch_search_results 函数会获取搜索结果页面的 HTML 内容,而 parse_results 则会进一步解析这些内容,提取所需的数据。
完整脚本如下所示:
from bs4 import BeautifulSoup
import pandas as pd
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
def init_selenium_driver():
chrome_options = Options()
chrome_options.add_argument("--headless")
chrome_options.add_argument("--no-sandbox")
chrome_options.add_argument("--disable-dev-shm-usage")
driver = webdriver.Chrome(options=chrome_options)
return driver
def fetch_search_results(driver, query):
base_url = "https://scholar.google.com/scholar"
params = f"?q={query}"
# Use Selenium WebDriver to fetch the page
driver.get(base_url + params)
# Wait for the page to load
driver.implicitly_wait(10) # Wait for up to 10 seconds for the page to load
# Return the page source (HTML content)
return driver.page_source
def parse_results(html):
soup = BeautifulSoup(html, 'html.parser')
articles = []
for item in soup.select('.gs_ri'):
title = item.select_one('.gs_rt').text
authors = item.select_one('.gs_a').text
snippet = item.select_one('.gs_rs').text
articles.append({'title': title, 'authors': authors, 'snippet': snippet})
return articles
if __name__ == "__main__":
search_query = "machine learning"
# Initialize the Selenium WebDriver
driver = init_selenium_driver()
try:
html_content = fetch_search_results(driver, search_query)
articles = parse_results(html_content)
df = pd.DataFrame(articles)
print(df.head())
finally:
driver.quit()
运行 python gscholar_scraper.py 来执行脚本,结果输出应类似如下:
% python3 scrape_gscholar.py
title authors snippet
0 [PDF][PDF] Machine learning algorithms-a review B Mahesh - International Journal of Science an... … Here‟sa quick look at some of the commonly u...
1 [BOOK][B] Machine learning E Alpaydin - 2021 - books.google.com MIT presents a concise primer on machine learn...
2 Machine learning: Trends, perspectives, and pr... MI Jordan, TM Mitchell - Science, 2015 - scien... … Machine learning addresses the question of h...
3 [BOOK][B] What is machine learning? I El Naqa, MJ Murphy - 2015 - Springer … A machine learning algorithm is a computatio...
4 [BOOK][B] Machine learning
将搜索关键词设为命令行参数
目前,搜索关键词是硬编码在脚本里的。为了让脚本更加灵活,可以将其作为命令行参数传入,以便无需改动脚本文件就能切换搜索关键词。
首先,导入 sys,以获取传入脚本的命令行参数:
import sys然后,在 __main__ 代码块中进行更新:
if __name__ == "__main__":
if len(sys.argv) != 2:
print("Usage: python gscholar_scraper.py '<search_query>'")
sys.exit(1)
search_query = sys.argv[1]
# Initialize the Selenium WebDriver
driver = init_selenium_driver()
try:
html_content = fetch_search_results(driver, search_query)
articles = parse_results(html_content)
df = pd.DataFrame(articles)
print(df.head())
finally:
driver.quit()您可以在终端中通过如下命令来指定搜索关键词:
python gscholar_scraper.py <search_query>此时,您可以在终端输入各种搜索关键词(例如 “artificial intelligence”、“agent-based modeling” 或 “Affective learning”)。
启用分页功能
通常,Google Scholar 在每页仅展示较少数量(大约 10 条)的搜索结果,这可能不足以满足您的需求。为爬取更多结果,您需要爬取多页搜索结果,这意味着需要在脚本中处理分页。
您可以对 fetch_search_results 函数进行修改,增加一个 start 参数,以控制获取多少页的内容。Google Scholar 的分页系统会以每次增加 10 的方式来显示下一页。
如果您查看某个 Google Scholar 页面链接,例如 https://scholar.google.ca/scholar?start=10&q=machine+learning&hl=en&as_sdt=0,5,其中的 start 参数决定了当前结果的起始位置。start=0 表示第一页;start=10 表示第二页;start=20 表示第三页;以此类推。
让我们对脚本进行更新:
def fetch_search_results(driver, query, start=0):
base_url = "https://scholar.google.com/scholar"
params = f"?q={query}&start={start}"
# Use Selenium WebDriver to fetch the page
driver.get(base_url + params)
# Wait for the page to load
driver.implicitly_wait(10) # Wait for up to 10 seconds for the page to load
# Return the page source (HTML content)
return driver.page_source接下来,创建一个函数来处理多页爬取:
def scrape_multiple_pages(driver, query, num_pages):
all_articles = []
for i in range(num_pages):
start = i * 10 # each page contains 10 results
html_content = fetch_search_results(driver, query, start=start)
articles = parse_results(html_content)
all_articles.extend(articles)
return all_articles此函数会根据指定的 num_pages 进行循环,每一页都会解析其 HTML 内容,并将所有文章信息汇总到一个列表中。
别忘了在主脚本中使用新的函数:
if __name__ == "__main__":
if len(sys.argv) < 2 or len(sys.argv) > 3:
print("Usage: python gscholar_scraper.py '<search_query>' [<num_pages>]")
sys.exit(1)
search_query = sys.argv[1]
num_pages = int(sys.argv[2]) if len(sys.argv) == 3 else 1
# Initialize the Selenium WebDriver
driver = init_selenium_driver()
try:
all_articles = scrape_multiple_pages(driver, search_query, num_pages)
df = pd.DataFrame(all_articles)
df.to_csv('results.csv', index=False)
finally:
driver.quit()脚本中新增了 df.to_csv('results.csv', index=False),这样可以把所有结果都存入 CSV 文件,而不只是打印到终端上。
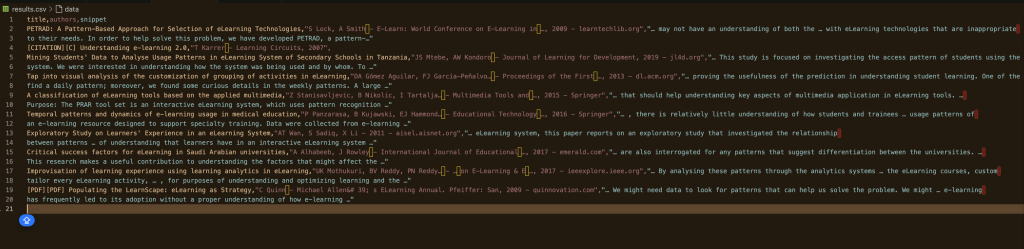
现在,运行脚本并指定要爬取的页数:
python gscholar_scraper.py "understanding elearning patterns" 2输出应该类似如下:
如何避免 IP 被封禁
大多数网站都会设置反爬虫机制,用来检测自动化请求的行为模式,以防止频繁爬取。如果网站检测到可疑活动,您的 IP 可能会被封禁。
例如,在编写本脚本时,就出现过返回的页面数据为空的情况:
Empty DataFrame
Columns: []
Index: []如果出现这种情况,说明您的 IP 可能已经被封禁。此时,您需要想办法规避这种情况,避免 IP 被识别和封锁。以下是在爬虫中常用的一些规避策略:
使用代理
代理服务 可以帮助您将请求分散到多个 IP 地址上,从而降低被封禁的风险。当您通过代理来转发请求时,代理服务器会直接将请求发送到目标网站;也就是说,网站只会看到代理服务器的 IP,而非您本机的 IP。如果想了解如何在项目中集成代理,可以查看相关教程。
轮换 IP
另一种防止 IP 被封禁的方法是编写脚本来在一定量请求后自动切换 IP。您可以手动实现,也可以使用自动进行 IP 轮换的代理服务。这样做的好处是让网站难以判断出这些请求都来自同一用户。
使用虚拟专用网络 (VPN)
VPN 可以通过将您的网络流量路由到其他地区的服务器来隐藏您的真实 IP 地址。您可以选择在不同国家或地区的 VPN 服务器间进行切换,以模拟不同区域的访问流量。同时,这也能使网站更难基于 IP 追踪并封禁您的活动。
总结
在本文中,我们探讨了如何使用 Python 从 Google Scholar 爬取数据。我们先搭建了一个虚拟环境,并安装了诸如 Beautiful Soup、pandas、Selenium 等必需包,然后编写脚本获取并解析搜索结果;接着,还实现了分页以爬取更多页面的内容,并讨论了避免 IP 被封禁的方法,包括使用代理、轮换 IP 和 VPN 等。
然而,手动爬取往往会面临 IP 封禁及脚本持续维护等诸多挑战。想要更省心地获取数据,您可以考虑使用 Bright Data 的解决方案。我们的 住宅代理网络 能提供高度匿名性和稳定性,帮助您顺利完成爬取任务。此外,网络抓取API 会自动处理 IP 轮换以及 验证码 (CAPTCHA) 的问题,为您节省大量时间和精力。对于想要即拿即用的数据,也可以探索我们提供的各种可定制数据集。
让您的数据采集更上一层楼——注册 Bright Data 免费试用,体验高效可靠的爬取解决方案吧!




