

您将通过本文了解手动收集财经数据,以及使用 Bright Data 财经数据抓取工具 API 自动化这一流程的操作方法。
了解要抓取的内容及其组织方式
财经数据所涵盖的信息往往都较复杂,且种类繁多。在着手抓取前,您需要清楚地知道所需的数据类型。
例如,您可能想要抓取股票价格数据,这涉及到股票的最新价格、当日开盘价和收盘价、当日最高价和最低价以及一段时间内的股价变化趋势。而诸如公司损益表、资产负债表(表明企业资产和负债状况)和现金流量表(追踪资金的进出)等财务信息对于评估股价表现同样重要。此外,财务比率、分析师的评估和报告可为股票买卖决策提供指导,最新资讯和社交媒体情绪分析则有助进一步洞察市场趋势,因此您也需要抓取此类信息。
了解网页数据的组织方式可让您更容易找到并抓取所需内容。
分析法律和道德问题
在抓取网站数据前,您务必要查看相关网站的服务条款。许多网站禁止在未经事先同意或授权的情况下进行抓取。
您还需要遵守 robots.txt 文件规则,该文件指明了您可访问的网站内容。此外,您要确保服务器不会因请求过多而超载,并在请求之间实现延迟。这有助保护网站资源,避免出现任何问题。
使用浏览器开发者工具
您可使用浏览器开发者工具查看网页的 HTML 元素。Chrome、Safari 、Edge 等大多数现代浏览器都内置这些工具。您可通过以下方式打开开发者工具:按快捷键 Ctrl + Shift + I(Windows 操作系统)或 Cmd + Option + I(Mac 操作系统),或右键单击页面并选择“检查”。
打开后,您即可检查相关页面的 HTML 结构并识别特定的数据元素。“元素”选项卡会显示文档对象模型 (DOM) 树,让您可以定位和突出显示网页元素。“网络”选项卡会显示所有的网络请求,便于您查找 API 端点或动态加载的数据。“控制台”选项卡则可让您运行 JavaScript 命令并与网页脚本进行交互。
在本教程中,您将学习如何抓取 APPL 股票 (Yahoo Finance) 的数据 。要查找相关 HTML 标签,请先转到 APPL 股票页面,右键单击页面上的价格并点击“检查”。“元素”选项卡突出显示了包含相关价格的 HTML 元素:
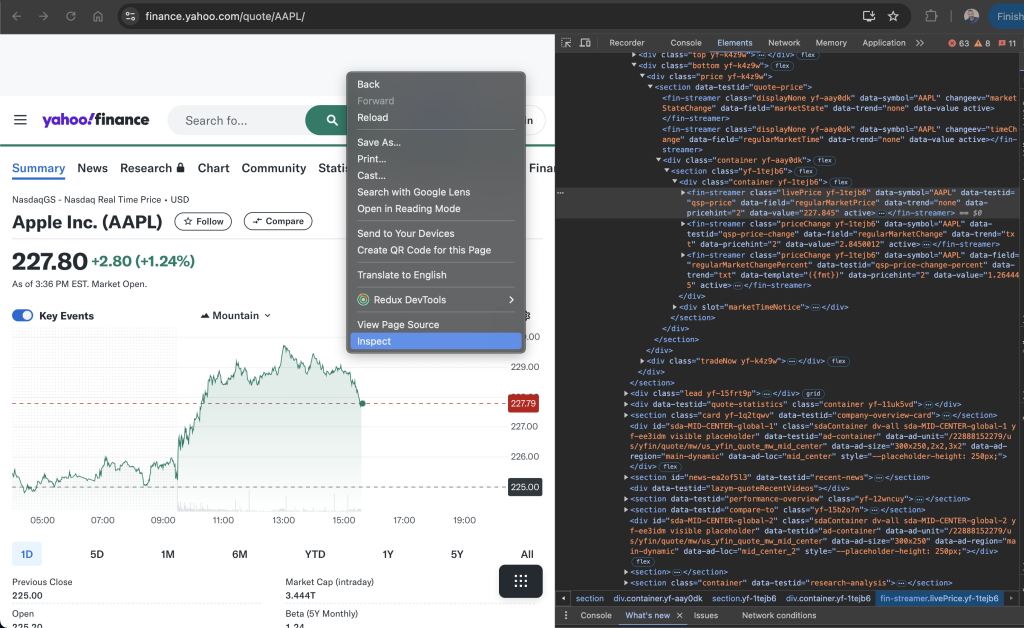
记下标签名称和任何唯一属性,例如 class 或 id,这有助您在抓取工具中定位此元素。
如何设置环境和项目
本教程使用 [Python] (https://www.python.or) 进行网页抓取,因为它简单易用且有可用的库。开始前,请确保您的系统已安装 Python 3.10 或更新版本。
安装 Python 后,请打开终端或 Shell,然后运行下方命令来创建目录和虚拟环境:
mkdir scrape-financial-data
cd scrape-financial-data
python3 -m venv myenv
虚拟环境创建完毕后,您还需要激活它。激活命令因操作系统而异。
如使用 Windows 系统,请运行以下命令:
.\myenv\Scripts\activate
如使用 macOS/Linux 系统,则运行此命令:
source myenv/bin/activate
激活虚拟环境后,使用 pip 安装所需的库:
pip3 install requests beautifulsoup4 lxml
此命令可安装用于处理 HTTP 请求的 Requests 库、用于解析 HTML 内容的 Beautiful Soup 和用于高效解析 XML 和 HTML 的 lxml。
如何手动抓取财经数据
要手动抓取财经数据,请先创建名为 manual_scraping.py 的文件,并添加以下代码以导入所需的库:
import requests
from bs4 import BeautifulSoup
设置要抓取的财经数据 URL。如前所述,本教程使用 Yahoo Finance 网页抓取 Apple 股票 (AAPL) 的数据:
url = 'https://finance.yahoo.com/quote/AAPL?p=AAPL&.tsrc=fin-srch'
设置 URL 后,向该 URL 发送 GET 请求:
headers = {'User-Agent': 'Mozilla/5.0'}
response = requests.get(url, headers=headers)
此代码包含一个 User-Agent 标头,用于模拟浏览器请求,以免被目标网站屏蔽。
验证请求是否成功:
if response.status_code == 200:
print('Successfully retrieved the webpage')
else:
print(f'Failed to retrieve the webpage. Status code: {response.status_code}')
exit()
然后,使用 lxml 解析器解析网页内容:
soup = BeautifulSoup(response.content, 'lxml')
根据相关元素的唯一属性找到它们,然后提取文本内容,并打印提取的数据:
# Extract specific company details
try:
# Extract specific company details
previous_close = soup.find('fin-streamer', {'data-field': 'regularMarketPreviousClose'}).text.strip()
open_price = soup.find('fin-streamer', {'data-field': 'regularMarketOpen'}).text.strip()
day_range = soup.find('fin-streamer', {'data-field': 'regularMarketDayRange'}).text.strip()
week_52_range = soup.find('fin-streamer', {'data-field': 'fiftyTwoWeekRange'}).text.strip()
market_cap = soup.find('fin-streamer', {'data-field': 'marketCap'}).text.strip()
# Extract PE Ratio (TTM)
pe_label = soup.find('span', class_='label', title='PE Ratio (TTM)')
pe_value = pe_label.find_next_sibling('span').find('fin-streamer').text.strip()
# Extract EPS (TTM)
eps_label = soup.find('span', class_='label', title='EPS (TTM)')
eps_value = eps_label.find_next_sibling('span').find('fin-streamer').text.strip()
# Print the scraped details
print("\n### Stock Price ###")
print(f"Open Price: {open_price}")
print(f"Previous Close: {previous_close}")
print(f"Day's Range: {day_range}")
print(f"52 Week Range: {week_52_range}")
print("\n### Company Details ###")
print(f"Market Cap: {market_cap}")
print(f"PE Ratio (TTM): {pe_value}")
print(f"EPS (TTM): {eps_value}")
except AttributeError as e:
print("Error while scraping data. Some fields may not be found.")
print(e)
运行并测试代码
要测试代码,请打开终端或 Shell 并运行以下命令:
python3 manual_scraping.py
输出结果应如下所示:
Successfully retrieved the webpage
### Stock Price ###
Open Price: 225.20
Previous Close: 225.00
Day's Range: 225.18 - 229.74
52 Week Range: 164.08 - 237.49
### Company Details ###
Market Cap: 3.447T
PE Ratio (TTM): 37.50
EPS (TTM): 37.50
应对手动抓取过程中的难题
由于各种原因,手动抓取数据并非易事,例如,您必须处理验证码或 IP 封禁问题,需要采取策略绕过这两大机制。非结构化或混乱的数据可能导致解析错误,而未经授权的抓取行为则可能引发法律问题。此外,频繁的网站更新可能导致抓取工具失效,因此您需要定期维护代码,确保其能持续运行。
要构建和自动化抓取工具,您必须花费大量时间编写并修复代码,而不是专注分析数据。如果您要处理大量的数据,则难度会更大,因为您必须确保数据干净、有序。如果您需要处理不同的网站结构,还必须了解各种网络技术。
也就是说,如果您需要频繁、快速地抓取数据,手动网页抓取并非最佳选择。
如何使用 Bright Data 财经数据抓取工具 API 抓取数据
Bright Data 使用财经数据抓取工具 API 自动提取数据,解决手动抓取难题。它内置代理管理功能,可轮换代理,防止 IP 被封禁。且该 API 以 JSON、CSV 等格式返回结构化数据。它还高度可扩展,可轻松处理大量数据。
要使用财经数据抓取工具 API,请先免费注册 Bright Data 账户。然后验证您的电子邮箱地址并完成必要的身份验证步骤。
账户设置完毕后,请登录账户并访问控制面板,获取 API 密钥。
配置财经数据抓取工具 API
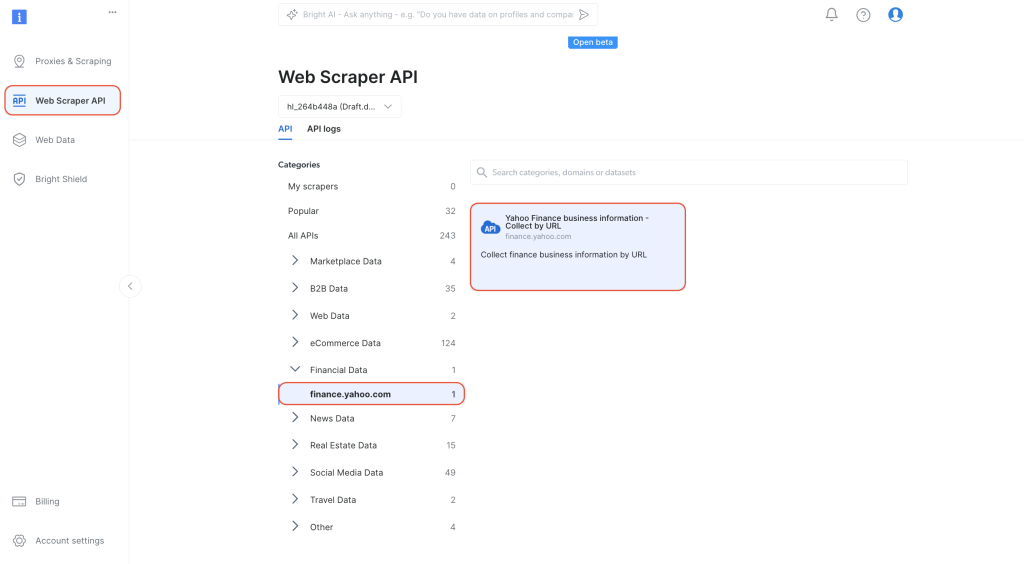
在控制面板中,从左侧导航选项卡进入“网页抓取工具 API” 页面。选择“类别”下的
“财经数据”,然后点击打开 “Yahoo Finance 商业信息 – 通过 URL 采集”:
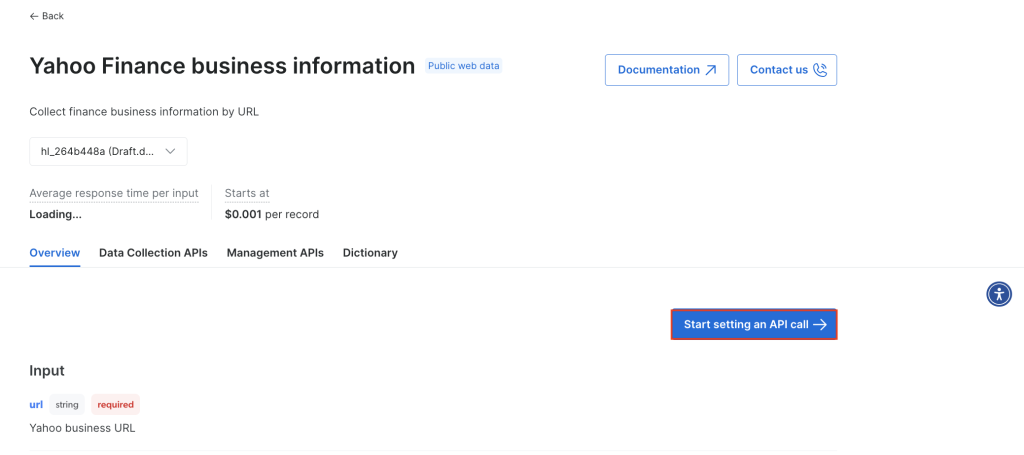
点击开始设置 API 调用:
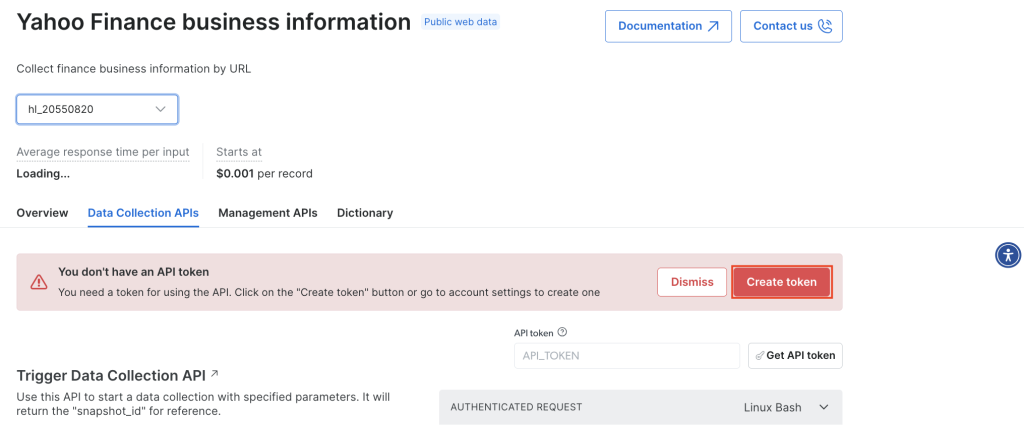
要使用 API,您需要创建一个令牌,以便系统在您调用 Bright Data 抓取工具 API 时进行身份验证。要创建新令牌,请点击“创建令牌”:
然后会打开一个对话框。将权限设置为“管理员”,并将持续时间设置为“无限制”:
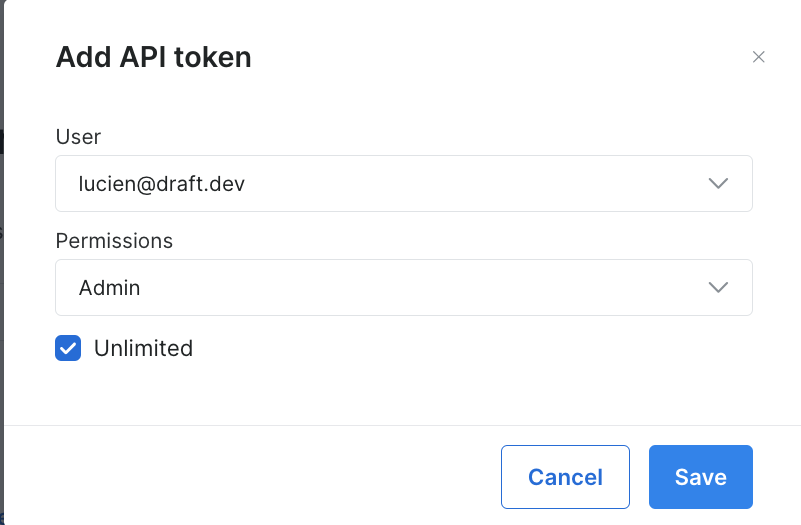
一旦您保存此信息,令牌即创建成功,系统将提示您输入新令牌。请务必将新令牌保存在安全的地方,因为您很快会再次用到它:
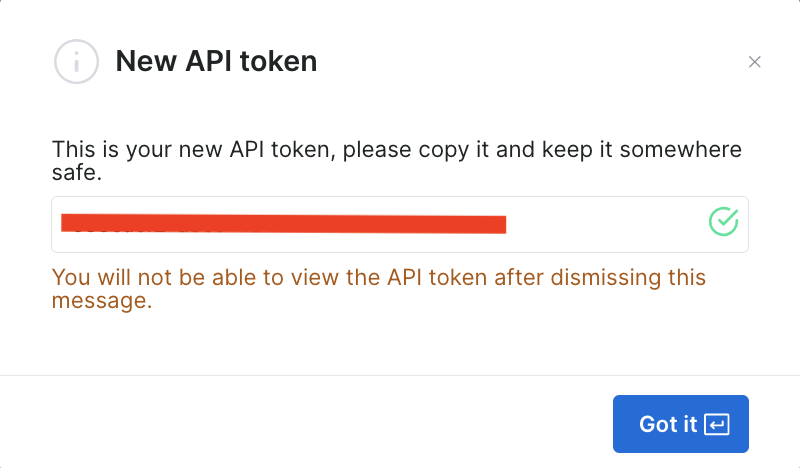
如果您已创建令牌,则可进入 “API 令牌”页面,在“用户设置”中找到该令牌。选择用户设置中的“更多”选项卡,然后点击“复制令牌”。
运行抓取工具以检索财经数据
在 Yahoo Finance 商业信息页面, 将您的 API 令牌添加至 “API 令牌”字段,然后添加目标网站的股票 URL,即 https://finance.yahoo.com/quote/AAPL/。复制右侧“已验证请求”部分中的请求:
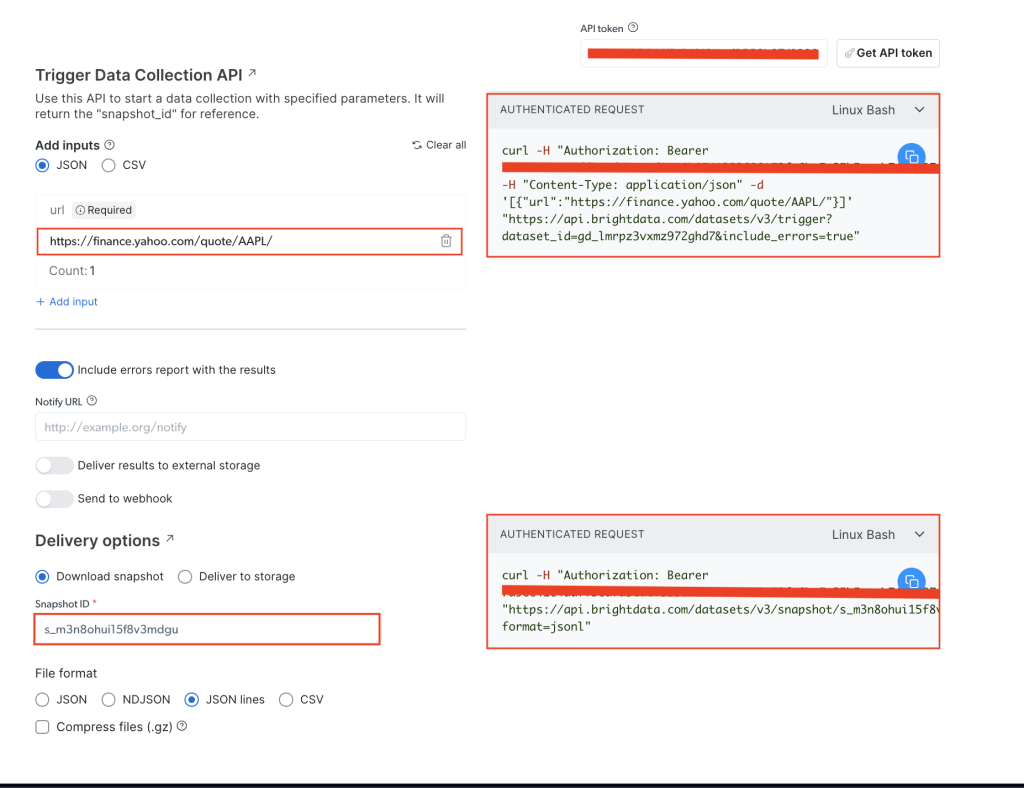
打开终端或 Shell,使用 curl 运行 API 调用。具体命令应如下所示:
curl -H "Authorization: Bearer YOUR_TOKEN" -H "Content-Type: application/json" -d '[{"url":"https://finance.yahoo.com/quote/AAPL/"}]' "https://api.brightdata.com/datasets/v3/trigger?dataset_id=YOUR_DATA_SET_ID&include_errors=true"
运行该命令后,您会收到 snapper_id 作为响应:
{"snapshot_id":"s_m3n8ohui15f8v3mdgu"}
复制 snapper_id 并在终端或 Shell 运行以下 API 调用:
curl -H "Authorization: Bearer YOUR_TOKEN" "https://api.brightdata.com/datasets/v3/snapshot/YOUR_SNAP_SHOT_ID?format=jsonl"
务必要将
YOUR_TOKEN和YOUR_SNAP_SHOT_ID替换为您的凭据。
运行此代码后,您应会获得输出结果(即抓取的数据)。相关数据应类似此 JSON 文件。
如果您收到响应,提示快照尚未准备妥当,请等待十秒后重试。
您会看到 Bright Data 财经数据抓取工具 API 为您提取了所需的各种数据,无需您分析 HTML 结构或定位特定标签。它检索了整个网页的数据,包括 earning_estimate、earning_history、growth_estinates 等其他字段的数据。
本教程中的所有代码都可在此 GitHub 存储库中找到。
使用 Bright Data API 的好处
Bright Data 财经数据抓取工具 API 无需编写或管理抓取代码,简化了抓取流程。该 API 还可管理代理轮换并遵守网站服务条款,从而确保了合规性,让您可以放心收集数据,无屏蔽或违反规则之忧。
Bright Data 财经数据抓取工具 API 只需少量编码即可提供可靠的结构化数据。它能为您处理页面导航和 HTML 解析,简化了流程。该 API 还可扩展,让您可以顺畅收集大量的股票数据和其他财经指标的数据,无需对代码进行重大修改。而且 Bright Data 会在网站更改其结构后及时更新抓取工具,将维护需求降到最低,您可持续顺利地收集数据,无需额外操作。
结语
对于从事财经分析、算法交易和市场研究的开发人员和数据团队来说,收集财经数据是一项至关重要的任务。在本文中,您学习了使用 Python 和 Bright Data 财经数据抓取工具 API 手动抓取财经数据的方法。手动抓取数据虽然可控,但应对反抓取措施、开展维护工作并非易事,且难以扩展。
Bright Data 财经数据抓取工具 API 通过管理代理轮换、 验证码解算等复杂任务来简化数据采集流程。除 API 外,Bright Data 还提供数据集、住宅代理和抓取浏览器,提升了网页抓取项目的效率。您可注册账户以免费试用,探索 Bright Data 提供的各项功能。



