

如果您是一名卖家或正在进行市场调研,了解某个商品的 ASIN 能帮助您快速找到精准的商品匹配,分析竞争对手的商品列表,并在市场竞争中保持领先。本文将向您展示如何使用简单且有效的方法大规模爬取亚马逊 ASIN。同时,您还将学习到 Bright Data 的解决方案,该方案可以显著加快这一过程。
亚马逊上的 ASIN 是什么?
ASIN 是一个由 10 个字符组成的代码,包含字母和数字(例如,B07PZF3QK9)。亚马逊会为其目录中的每件商品(包括图书、电子产品、服装等)分配该唯一编码。
查找任何商品 ASIN 的方式有两种:
1. 查看商品的 URL —— 在地址栏中 “/dp/” 后面出现的就是 ASIN。
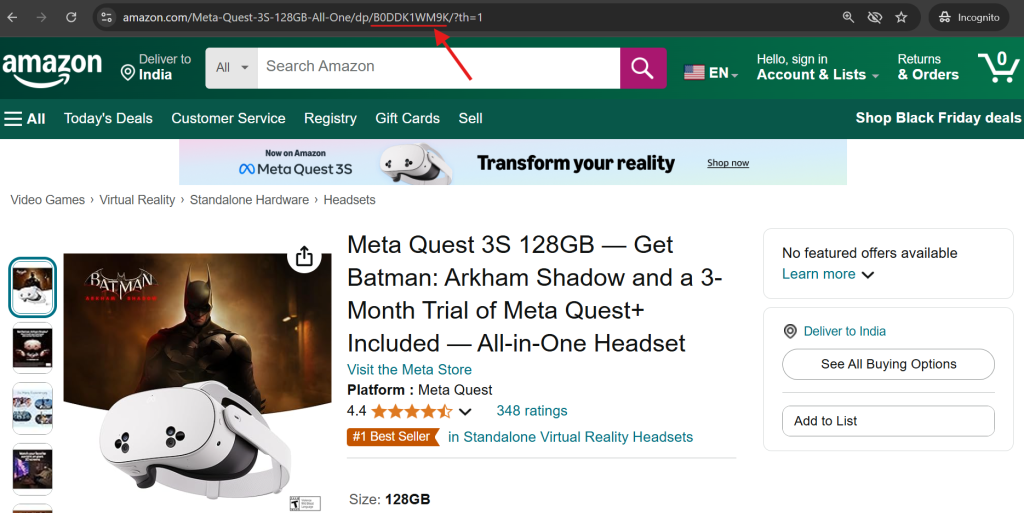
2. 向下滚动至任何亚马逊商品页面上的商品信息部分,在此处也能找到 ASIN。
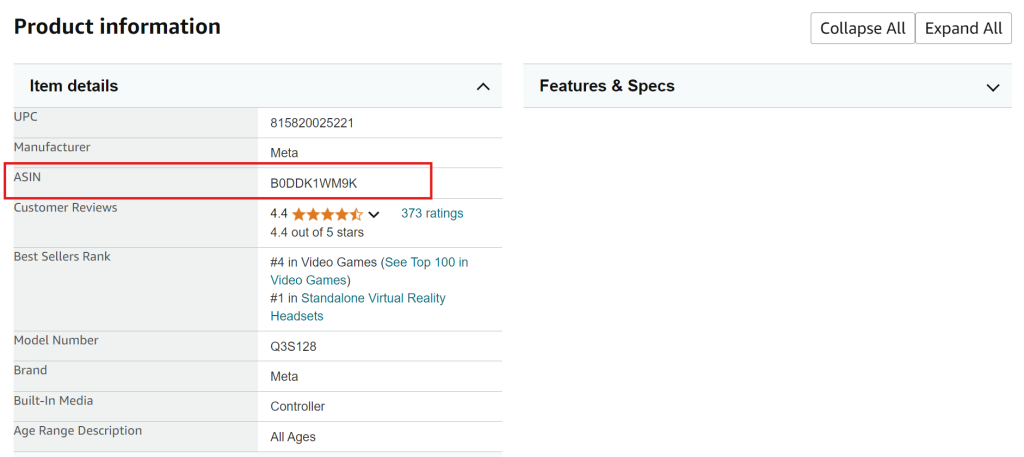
如何从亚马逊提取 ASIN
最初看来,从亚马逊爬取数据似乎很简单,但由于其强大的反爬机制,这项工作实际上相当困难。亚马逊通过以下多种高级方式来防止自动化采集数据:
- CAPTCHA 测试,在检测到可疑行为时出现
- 使用 HTTP 503 错误来阻止对目标页面的访问
- 频繁更改网站布局,导致原有的解析逻辑失效
下图是由亚马逊触发的典型 HTTP 503 错误 截图:

您可以尝试以下脚本来爬取亚马逊 ASIN:
import asyncio import os from curl_cffi import requests from bs4 import BeautifulSoup from tenacity import retry, stop_after_attempt, wait_random class AsinScraper: def __init__(self): self.session = requests.Session() self.asins = set() def create_url(self, keyword: str, page: int) -> str: return f"https://www.amazon.com/s?k={keyword.replace(' ', '+')}&page={page}" @retry(stop=stop_after_attempt(3), wait=wait_random(min=2, max=5)) async def fetch_page(self, url: str) -> str | None: try: print(f"Fetching URL: {url}") response = self.session.get( url, impersonate="chrome120", timeout=30) print(f"HTTP Status Code: {response.status_code}") if response.st\atus_code == 200: # Check for any block indicators in the response if "Sorry" not in response.text: return response.text else: print("Sorry, request blocked!") else: print(f"Unexpected HTTP status code: {response.status_code}") except Exception as e: print(f"Exception occurred during fetch: {e}") return None def extract_asins(self, html: str) -> set[str]: soup = BeautifulSoup(html, "lxml") containers = soup.find_all( "div", {"data-component-type": "s-search-result"}) new_asins = set() for container in containers: asin = container.get("data-asin") if asin and asin.strip(): new_asins.add(asin) return new_asins def save_to_csv(self, keyword: str): if not self.asins: print("No ASINs to save") return # Create results directory if it doesn't exist os.makedirs("results", exist_ok=True) # Generate filename csv_path = f"results/amazon_asins_{keyword.replace(' ', '_')}.csv" # Save as CSV with open(csv_path, 'w') as f: f.write("asin\n") for asin in sorted(self.asins): f.write(f"{asin}\n") print(f"ASINs saved to: {csv_path}") async def main(): scraper = AsinScraper() keyword = "laptop" max_pages = 5 for page in range(1, max_pages + 1): print(f"Scraping page {page}...") html = await scraper.fetch_page(scraper.create_url(keyword, page)) if not html: print(f"Failed to fetch page {page}") break new_asins = scraper.extract_asins(html) if new_asins: scraper.asins.update(new_asins) print(f"Found {len(new_asins)} ASINs on page { page}. Total ASINs: {len(scraper.asins)}") else: print("No more ASINs found. Ending scrape.") break # Save results to CSV scraper.save_to_csv(keyword) if __name__ == "__main__": asyncio.run(main())
那么,爬取亚马逊 ASIN 的解决方案是什么?最可靠的方法是结合使用来自最佳代理服务提供商的住宅代理,并正确配置HTTP 头。
使用 Bright Data 代理来爬取亚马逊 ASIN
Bright Data 是一家领先的代理提供商,拥有全球代理网络。它在共享和专用服务器上提供多种类型的代理,适用于各种使用场景。这些服务器可以使用 HTTP、HTTPS 以及 SOCKS 协议进行流量转发。
为什么选择 Bright Data 来爬取亚马逊?
- 庞大的 IP 网络:可使用覆盖 195 个国家/地区的 72M+ IP
- 精准的地理位置定位:可定向到具体城市、邮编,甚至运营商
- 多种代理类型:可选 住宅、数据中心、移动 或 ISP 代理
- 高可靠性:可实现 99.9% 的成功率,并可选择 100% 正常运行时间
- 灵活的扩展方式:提供 按使用量付费,适合不同规模的企业
在 Bright Data 上配置亚马逊爬取
如果您想使用 Bright Data 代理来爬取亚马逊 ASIN,可按以下步骤进行:
步骤 1:注册 Bright Data
访问 Bright Data 官网并创建账户。若您已有账户,请直接进入下一步。
步骤 2:创建一个新的代理 Zone
登录并进入 Proxy & Scraping Infrastructure 页面,点击 Add 创建一个新的代理 Zone。选择 Residential proxies,因为它们使用真实设备 IP,最适合规避反爬虫限制。
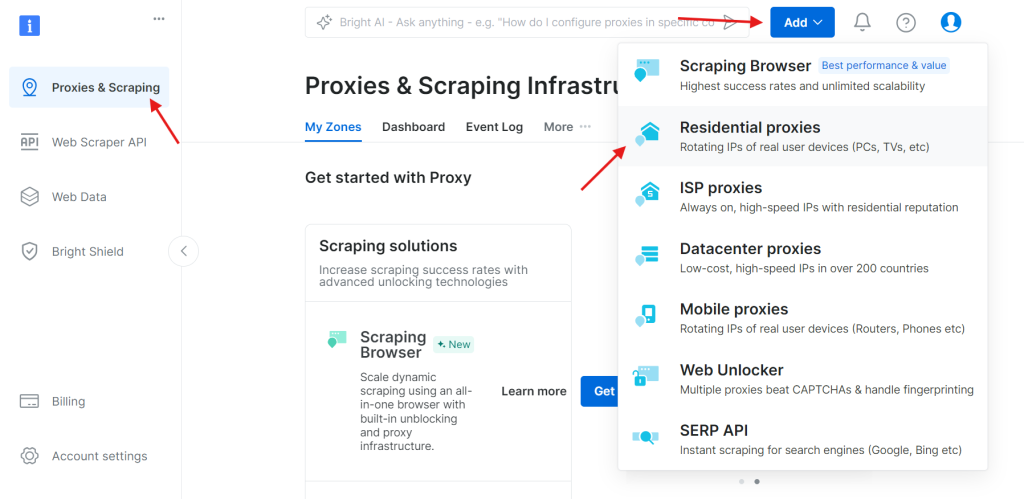
步骤 3:配置代理设置
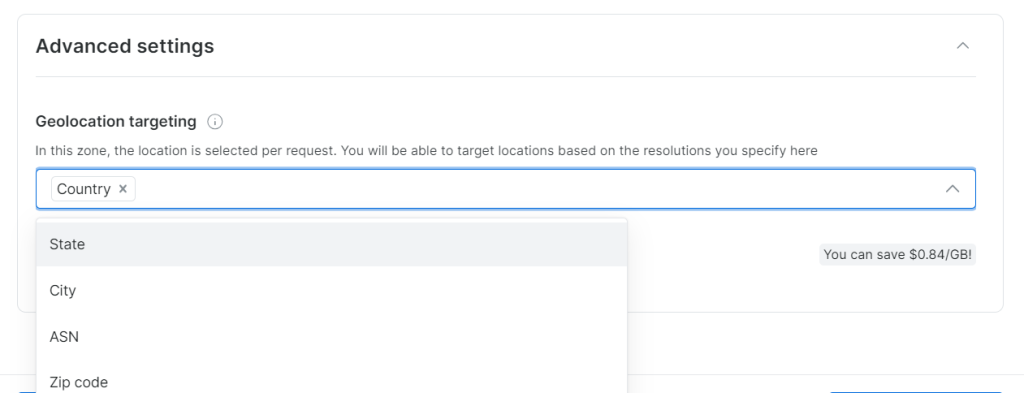
选择要浏览的地区或国家,并为您的 Zone 命名(如 “asin_scraping”)。
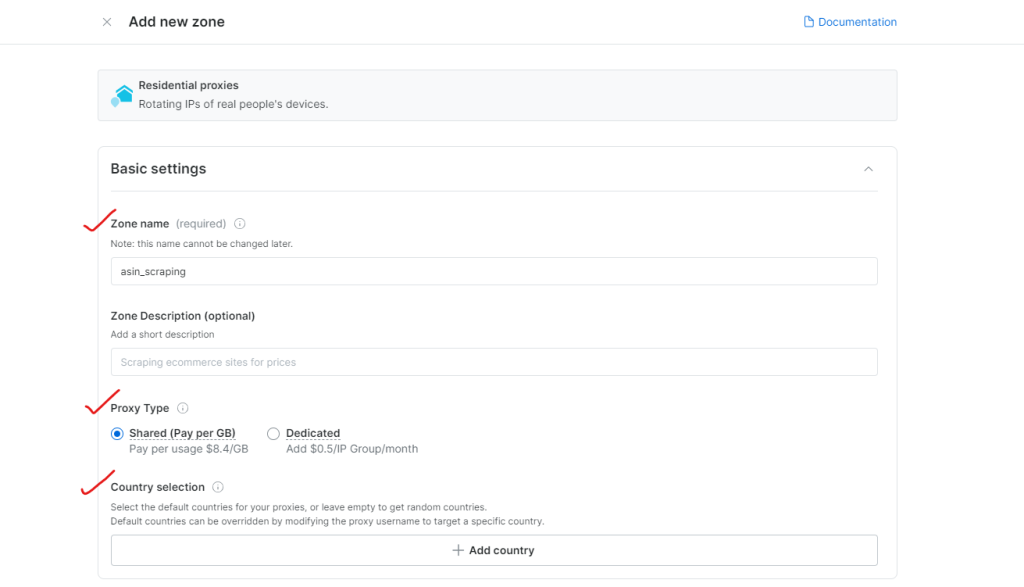
Bright Data 允许精确的地理位置定位,甚至可精确到城市或邮编。
步骤 4:完成 KYC 验证
要完全使用 Bright Data 的住宅代理,您需要完成 KYC 验证流程。
步骤 5:开始使用代理
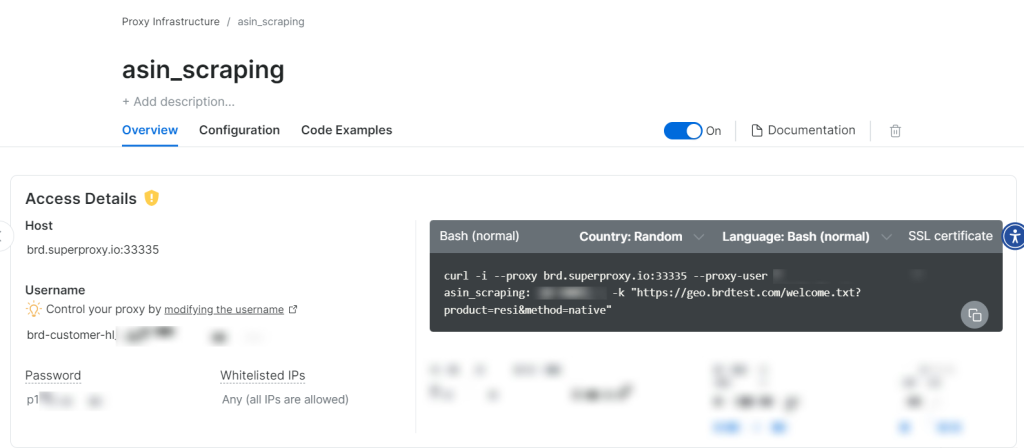
当新建的代理 Zone 创建完成后,您会看到使用该 Zone 所需的相关凭证(主机、端口、用户名、密码),然后便可开始爬取数据。
就是这么简单!
实现爬虫
步骤 1:设置浏览器头
headers = {
"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8",
"accept-language": "en-US,en;q=0.9",
"sec-ch-ua": '"Chromium";v="119", "Not?A_Brand";v="24"',
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": '"Windows"',
"sec-fetch-dest": "document",
"sec-fetch-mode": "navigate",
"sec-fetch-site": "none",
"sec-fetch-user": "?1",
"upgrade-insecure-requests": "1",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36",
}步骤 2:配置代理设置
proxy_config = {
"username": "YOUR_USERNAME",
"password": "YOUR_PASSWORD",
"server": "brd.superproxy.io:33335",
}
proxy_url = f"http://{proxy_config['username']}:{proxy_config['password']}@{proxy_config['server']}"步骤 3:发送请求
使用 curl_cffi 库,结合自定义头与代理进行请求:
response = session.get(
url,
headers=headers,
impersonate="chrome120",
proxies={"http": proxy_url, "https": proxy_url},
timeout=30,
verify=False,
)注意: curl_cffi 库是一个优秀的爬虫选择,提供了比标准 requests 更完善的浏览器模拟能力。
步骤 4:运行爬虫
在执行爬虫之前,需要配置目标关键词。示例如下:
keywords = [
"coffee maker",
"office desk",
"cctv camera"
]
max_pages = None # Set to None for all pages完整的代码示例可在 此链接 查看。
脚本执行后,会将结果输出至 CSV 文件,其中包含:
使用 Bright Data Amazon Scraper API 提取 ASIN
虽然使用代理的方式可以成功完成爬虫,但 Bright Data Amazon Scraper API 能提供更高效的方案:
- 无需管理基础设施:无需担心代理、IP 轮换或验证码
- 地理位置抓取:可从任意地理区域进行抓取
- 简单的集成:几分钟内即可在任何编程语言中实现
- 多种数据交付方式:
- 可将数据导出到 Amazon S3、Google Cloud、Azure、Snowflake 或 SFTP
- 以 JSON、NDJSON、CSV 或 .gz 格式获取数据
- 符合 GDPR & CCPA 要求:保障合规的同时进行合法爬取
- 20 次免费 API 调用:可在购买前进行测试
- 7×24 小时支持:随时解答 API 相关的问题或疑虑
设置 Amazon Scraper API
配置该 API 十分简单,只需完成以下几个步骤。
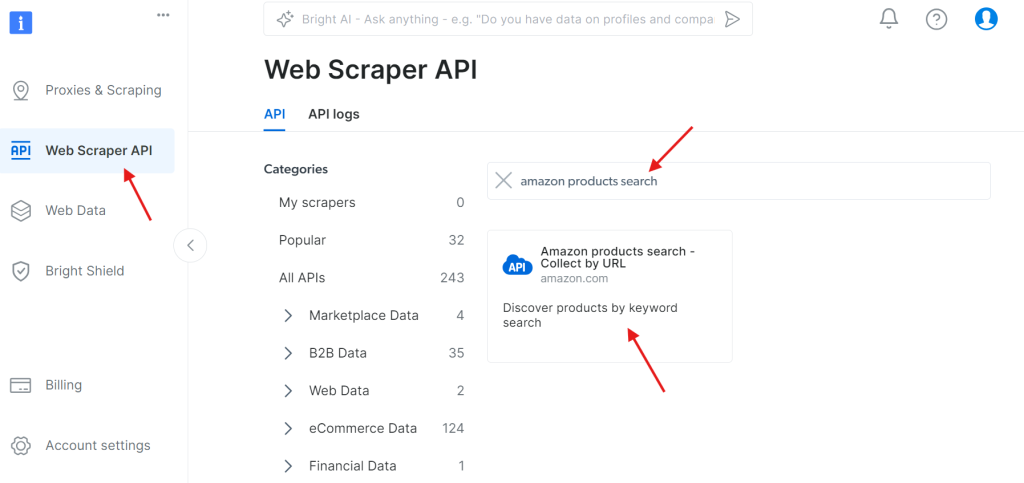
步骤 1:访问 API
进入 Web Scraper API 界面,在可用 API 中搜索 “amazon products search”:
点击 “Start setting an API call”:
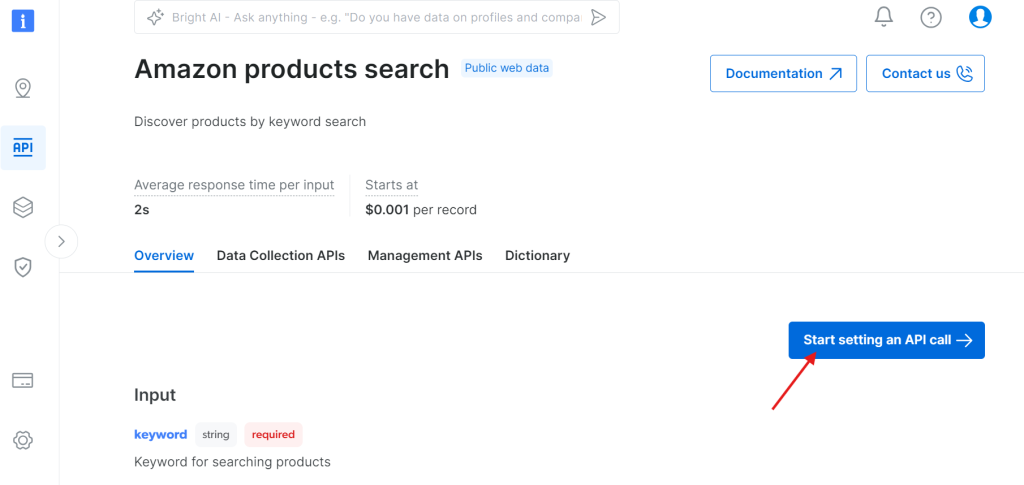
步骤 2:获取 API Token
点击 “Get API token”:
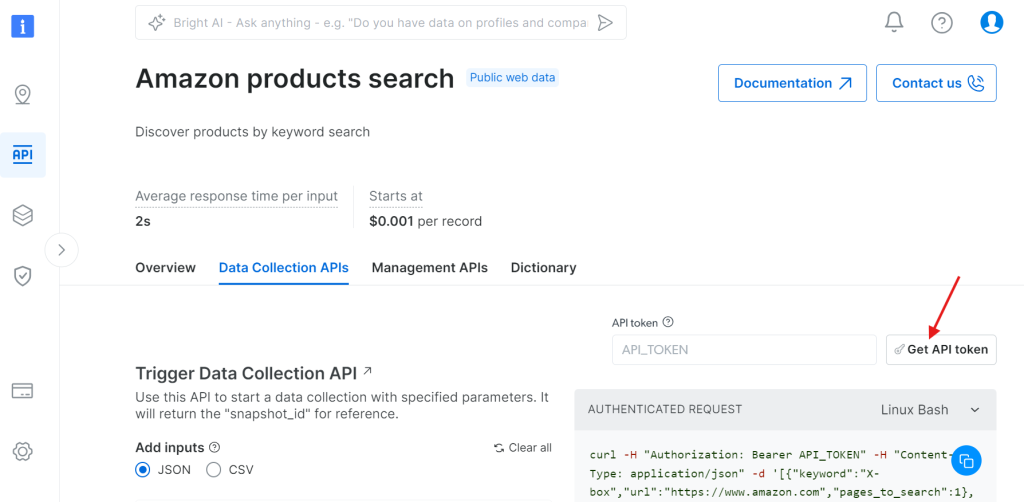
选择 “Add token”:
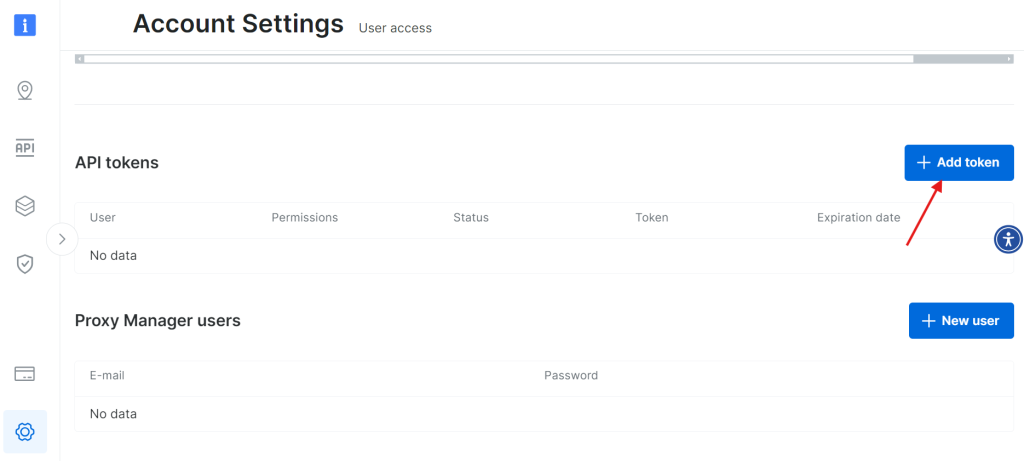
妥善保存新创建的 API token:
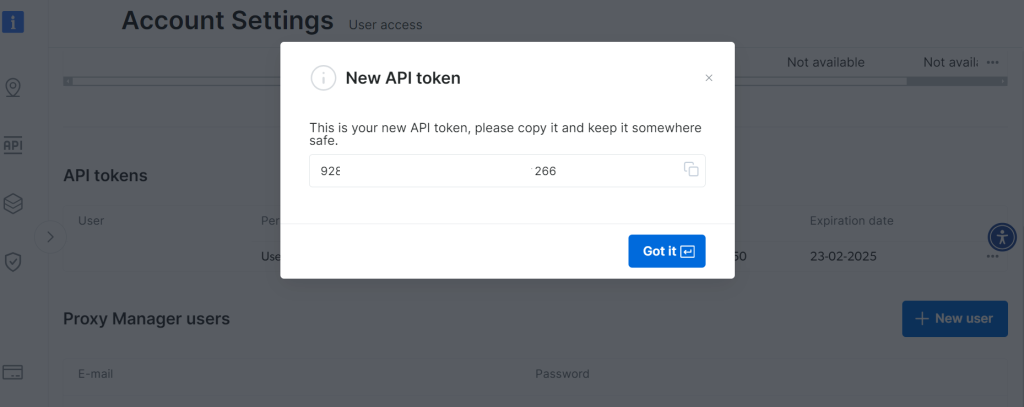
步骤 3:配置数据采集
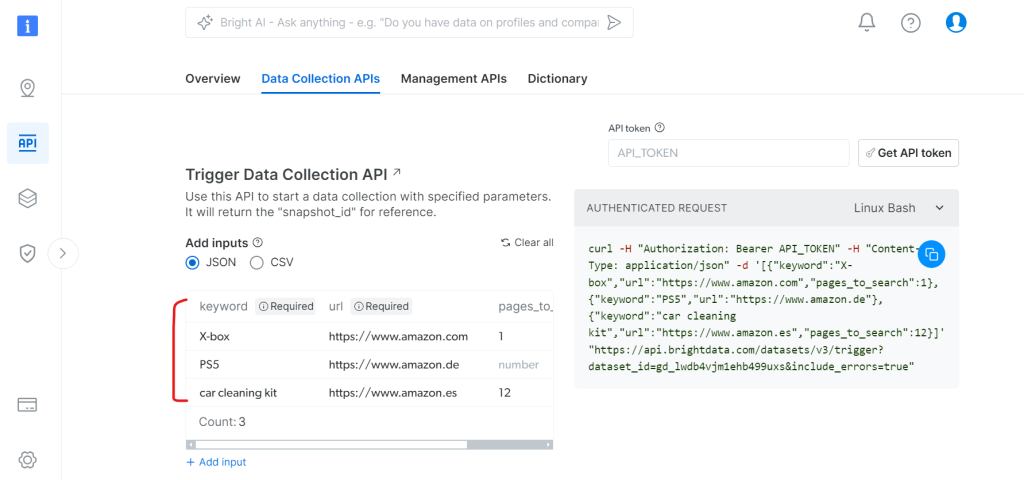
在 Data Collection APIs 标签下:
- 指定想要搜索的关键词
- 设置目标亚马逊域名
- 定义需要抓取的页面数
- 可选的其他过滤器
在 Python 中使用该 API
下面是一个使用 Python 调用 API 进行数据采集并获取结果的示例:
import json
import requests
import time
from typing import Dict, List, Optional, Union, Tuple
from datetime import datetime, timedelta
import logging
from requests.adapters import HTTPAdapter
from urllib3.util.retry import Retry
from enum import Enum
class SnapshotStatus(Enum):
SUCCESS = "success"
PROCESSING = "processing"
FAILED = "failed"
TIMEOUT = "timeout"
class BrightDataAmazonScraper:
def __init__(self, api_token: str, dataset_id: str):
self.api_token = api_token
self.dataset_id = dataset_id
self.base_url = "https://api.brightdata.com/datasets/v3"
self.headers = {
"Authorization": f"Bearer {api_token}",
"Content-Type": "application/json",
}
# Setup logging with custom format
logging.basicConfig(
level=logging.INFO,
format='%(message)s' # Simplified format to show only messages
)
self.logger = logging.getLogger(__name__)
# Setup session with retry strategy
self.session = self._create_session()
# Track progress
self.last_progress_update = 0
def _create_session(self) -> requests.Session:
"""Create a session with retry strategy"""
session = requests.Session()
retry_strategy = Retry(
total=3,
backoff_factor=0.5,
status_forcelist=[500, 502, 503, 504]
)
adapter = HTTPAdapter(max_retries=retry_strategy)
session.mount("https://", adapter)
session.mount("http://", adapter)
return session
def trigger_collection(self, datasets: List[Dict]) -> Optional[str]:
"""Trigger data collection for specified datasets"""
trigger_url = f"{self.base_url}/trigger?dataset_id={self.dataset_id}"
try:
response = self.session.post(
trigger_url,
headers=self.headers,
json=datasets
)
response.raise_for_status()
snapshot_id = response.json().get("snapshot_id")
if snapshot_id:
self.logger.info("Initializing Amazon data collection...")
return snapshot_id
else:
self.logger.error("Unable to initialize data collection.")
return None
except requests.exceptions.RequestException as e:
self.logger.error(f"Collection initialization failed: {str(e)}")
return None
def check_snapshot_status(self, snapshot_id: str) -> Tuple[SnapshotStatus, Optional[Dict]]:
"""Check the current status of a snapshot"""
snapshot_url = f"{self.base_url}/snapshot/{snapshot_id}?format=json"
try:
response = self.session.get(snapshot_url, headers=self.headers)
if response.status_code == 200:
return SnapshotStatus.SUCCESS, response.json()
elif response.status_code == 202:
return SnapshotStatus.PROCESSING, None
else:
return SnapshotStatus.FAILED, None
except requests.exceptions.RequestException:
return SnapshotStatus.FAILED, None
def wait_for_snapshot_data(
self,
snapshot_id: str,
timeout: Optional[int] = None,
check_interval: int = 10,
max_interval: int = 300,
callback=None
) -> Optional[Dict]:
"""Wait for snapshot data with minimal console output"""
start_time = datetime.now()
current_interval = check_interval
attempts = 0
progress_shown = False
while True:
attempts += 1
if timeout is not None:
elapsed_time = (datetime.now() - start_time).total_seconds()
if elapsed_time >= timeout:
self.logger.error("Data collection exceeded time limit.")
return None
status, data = self.check_snapshot_status(snapshot_id)
if status == SnapshotStatus.SUCCESS:
self.logger.info(
"Amazon data collection completed successfully!")
return data
elif status == SnapshotStatus.FAILED:
self.logger.error("Data collection encountered an error.")
return None
elif status == SnapshotStatus.PROCESSING:
# Show progress indicator only every 30 seconds
current_time = time.time()
if not progress_shown:
self.logger.info("Collecting data from Amazon...")
progress_shown = True
elif current_time - self.last_progress_update >= 30:
self.logger.info("Data collection in progress...")
self.last_progress_update = current_time
if callback:
callback(attempts, (datetime.now() -
start_time).total_seconds())
time.sleep(current_interval)
current_interval = min(current_interval * 1.5, max_interval)
def store_data(self, data: Dict, filename: str = "amazon_data.json") -> None:
"""Store collected data to a JSON file"""
if data:
try:
with open(filename, "w", encoding='utf-8') as file:
json.dump(data, file, indent=4, ensure_ascii=False)
self.logger.info(f"Data saved successfully to {filename}")
except IOError as e:
self.logger.error(f"Error saving data: {str(e)}")
else:
self.logger.warning("No data available to save.")
def progress_callback(attempts: int, elapsed_time: float):
"""Minimal callback function - can be customized based on needs"""
pass # Silent by default
def main():
# Configuration
API_TOKEN = "YOUR_API_TOKEN"
DATASET_ID = "gd_lwdb4vjm1ehb499uxs"
# Initialize scraper
scraper = BrightDataAmazonScraper(API_TOKEN, DATASET_ID)
# Define search parameters
datasets = [
{"keyword": "X-box", "url": "https://www.amazon.com", "pages_to_search": 1},
{"keyword": "PS5", "url": "https://www.amazon.de"},
{"keyword": "car cleaning kit",
"url": "https://www.amazon.es", "pages_to_search": 4},
]
# Execute scraping process
snapshot_id = scraper.trigger_collection(datasets)
if snapshot_id:
data = scraper.wait_for_snapshot_data(
snapshot_id,
timeout=None,
check_interval=10,
max_interval=300,
callback=progress_callback
)
if data:
scraper.store_data(data)
print("\nScraping process completed successfully!\n")
if __name__ == "__main__":
main()运行上述脚本时,请务必将以下值替换为您的实际信息:
API_TOKEN替换为您在 Bright Data 上生成的实际 token。- 在
datasets列表中修改为您需要爬取的产品或关键词。
以下是从 API 获取到的数据示例 JSON 结构:
{
asin: "B0CJ3XWXP8",
url: "https://www.amazon.com/Xbox-X-Console-Renewed/dp/B0CJ3XWXP8/ref=sr_1_1",
name: "Xbox Series X Console (Renewed) Xbox Series X Console (Renewed)Sep 15, 2023",
sponsored: "false",
initial_price: 449.99,
final_price: 449.99,
currency: "USD",
sold: 2000,
rating: 4.1,
num_ratings: 1529,
variations: null,
badge: null,
business_type: null,
brand: null,
delivery: ["FREE delivery Sun, Dec 1", "Or fastest delivery Fri, Nov 29"],
keyword: "X-box",
image: "https://m.media-amazon.com/images/I/51ojzJk77qL._AC_UY218_.jpg",
domain: "https://www.amazon.com/",
bought_past_month: 2000,
page_number: 1,
rank_on_page: 1,
timestamp: "2024-11-26T05:15:24.590Z",
input: {
keyword: "X-box",
url: "https://www.amazon.com",
pages_to_search: 1
}
}您可点击 此示例 JSON 文件 下载并查看完整输出。
结论
本文讨论了使用 Python 搜集亚马逊 ASIN 的流程,以及在此过程中会遇到的一些挑战,例如 CAPTCHA 验证和频率限制等问题。如果想要反馈更高的效率并避免常见的障碍,可以使用 Bright Data 提供的代理服务或 Amazon Scraper API。若您不想花时间搭建自己的爬虫架构,Bright Data 还提供了现成的 亚马逊数据集,可让您即刻使用。
立即注册并开始您的免费试用吧!



