

本博客将详细讨论并发与并行,以帮助您为您的应用程序选择最佳的概念。
什么是并发?
简单来说,并发是软件开发中用于同时处理多个任务的概念。然而,理论上它并不是同时运行所有任务,而是通过快速切换任务来管理多个任务,从而创建并行处理的错觉。这一过程也被称为任务交替。
例如,考虑一个需要处理多个用户请求的网络服务器。
- 用户1发送请求到服务器以获取数据。
- 用户2发送请求到服务器以上传文件。
- 用户3发送请求到服务器以获取图像。
如果没有并发,每个用户都必须等待前一个请求完成。
- 步骤1:CPU开始在线程1中处理数据检索请求。
- 步骤2:当线程1等待结果时,CPU开始在线程2中处理文件上传过程。
- 步骤3:当线程2等待文件上传时,CPU开始在线程3中处理图像检索。
- 步骤4:然后,CPU根据资源可用性在这三个线程之间切换,以同时完成所有三个任务。
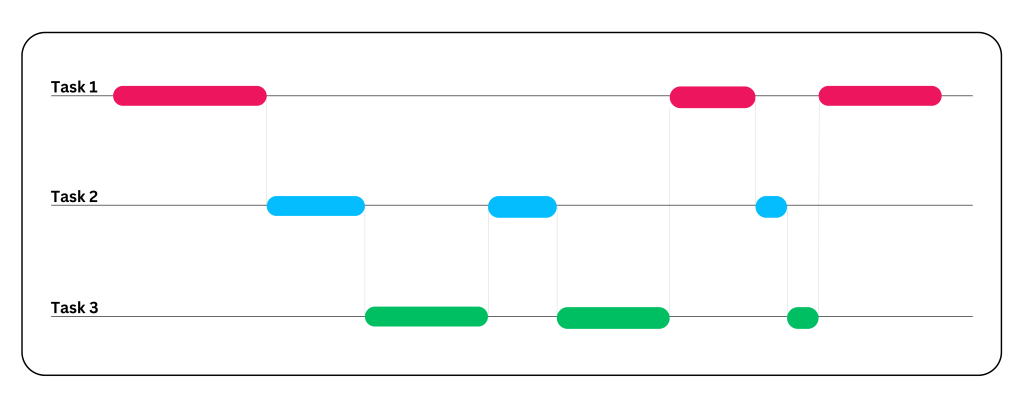
与同步执行方法相比,并发方法更快,非常适用于单核环境,以提高系统的响应时间、资源利用率和系统吞吐能力。然而,并发不仅限于单核,它也可以在多核环境中实现。
并发的用例
- 响应式用户界面。
- 网络服务器。
- 实时系统。
- 网络和I/O操作。
- 后台处理。
不同的并发模型
随着现代应用程序的复杂性和需求的增加,开发人员引入了新的并发模型来解决传统方法的不足。以下是一些关键的并发模型及其用途:
1. 协作多任务
在这种模型中,任务在适当的时间点自愿放弃对调度程序的控制,允许其处理其他任务。这种让出通常发生在任务空闲或等待I/O操作时。由于上下文切换在应用程序代码中管理,这种模型实现起来相对简单。
例子:
- 轻量级嵌入式系统
- 早期版本的Microsoft Windows(Windows 3.x)
- 经典的Mac OS
现实应用:
- 使用协程的应用程序,如Python asyncio和Kotlin协程。
2. 抢占式多任务
操作系统或运行时调度程序根据调度算法强制任务停止并将CPU时间分配给其他任务。这种模型确保所有任务均等分配CPU时间,但需要更复杂的上下文切换。
例子:
现实应用:
- 现代操作系统(Windows、macOS、Linux)
- 网络服务器。
3. 事件驱动并发
在这种模型中,任务被分为小的非阻塞操作,并排入队列。然后,它们从队列中获取任务,执行所需的操作,并移动到下一个任务,保持系统的交互性。
例子:
- Node.js(JavaScript运行时)。
- JavaScript的async/await模式。
- Python的asyncio库。
现实应用:
- 像Node.js这样的网络服务器。
- 实时聊天应用程序。
4. Actor模型
使用actor异步发送和接收消息。每个actor一次处理一条消息,避免共享状态并减少锁的需求。
例子:
- Akka框架(Java/Scala)。
- Erlang编程语言。
- Microsoft Orleans(分布式.NET应用程序)。
现实应用:
- 分布式系统。
- 电信系统。
- 实时数据处理系统。
5. 响应式编程
这种模型允许您创建数据流(observables)并定义如何处理它们(operators)以及如何响应它们(observers)。数据变化或事件发生时,会自动通过流传播到所有订阅的观察者。此方法使得管理异步数据和事件更加容易,提供了一种清晰且声明性的方式来处理复杂的数据流。
例子:
现实应用:
- 实时数据处理管道。
- 交互式用户界面。
- 需要动态和响应式数据处理的应用程序。
什么是并行?
并行是软件开发中用于同时处理多个任务的另一个流行概念。与通过快速切换任务来创建并行处理错觉的并发不同,并行实际上是使用多个CPU核心或处理器同时执行多个任务。它涉及将较大的任务分解为可以并行执行的较小独立子任务。这一过程被称为任务分解。
例如,考虑一个数据处理应用程序,在执行分析和运行模拟后生成报告。如果没有并行,这将作为一个大任务运行,需要很长时间才能完成。但是,如果选择并行处理,它将通过任务分解更快地完成任务。
并行的工作原理如下:
- 步骤1:将主任务分解为独立的子任务。这些子任务应能够在不等待其他任务输入的情况下运行 。然而,如果有任何依赖关系,需要相应地调度它们以确保它们按正确的顺序执行。在这个例子中,我假设子任务之间没有依赖关系。
- 子任务1:执行数据分析。
- 子任务2:生成报告。
- 子任务3:运行模拟。
- 步骤2:将3个子任务分配给3个核心。
- 步骤3:最后,合并每个子任务的结果,以获得原始任务的最终输出。
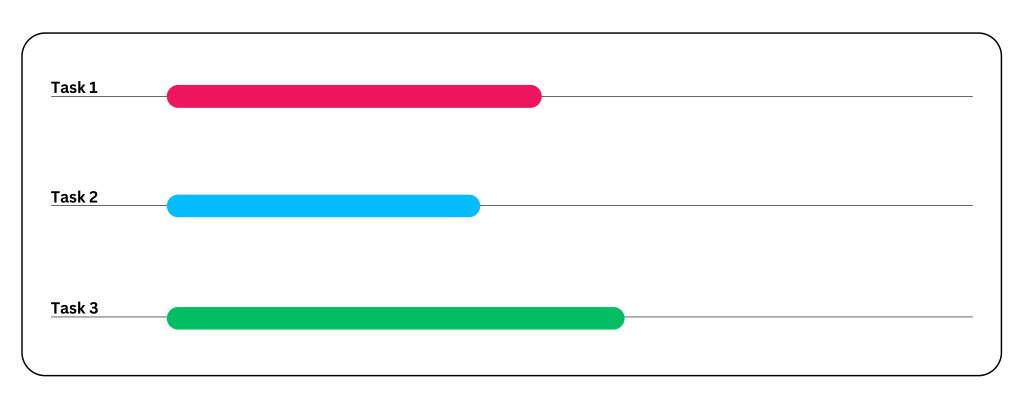
并行的用例
- 科学计算和模拟。
- 数据处理。
- 图像处理。
- 机器学习。
- 风险分析。
不同的并行模型
与并发类似,并行也有多种不同的模型,以有效利用多核处理器和分布式计算资源。以下是一些关键的并行模型及其用途:
1. 数据并行
这种模型将数据分布到多个处理器上,并在每个数据子集上同时执行相同的操作。它对可以轻松分割为独立子任务的任务特别有效。
例子:
- SIMD(单指令多数据)操作。
- 并行数组处理。
- MapReduce框架。
现实应用:
- 图像和信号处理
- 大规模数据分析
- 科学模拟
2. 任务并行
任务并行涉及将整体任务分解为较小的独立任务,并在不同的处理器上同时执行每个任务。每个任务执行不同的操作。
例子:
- Java中的基于线程的并行。
- .NET中的并行任务。
- POSIX线程。
现实应用:
- 处理多个客户端请求的网络服务器。
- 并行算法实现。
- 实时处理系统。
3. 流水线并行
在流水线并行中,任务被分为多个阶段,每个阶段并行处理。数据通过流水线流动,每个阶段同时操作。
例子:
- Unix流水线命令。
- 图像处理流水线。
- ETL(提取、转换、加载)工具中的数据处理流水线。
现实应用:
- 视频和音频处理。
- 实时数据流应用。
- 制造和装配线自动化。
4. Fork/Join模型
这种模型涉及将任务分解为较小的子任务(fork),并行执行它们,然后合并结果(join)。它适用于分治算法。
例子:
- Java中的Fork/Join框架。
- 并行递归算法(例如并行归并排序)。
- Intel线程构建块(TBB)。
现实应用:
- 如排序大数据集等复杂计算任务。
- 递归算法。
- 大规模科学计算。
5. GPU并行
GPU并行利用图形处理单元(GPU)的大量并行处理能力,同时执行数千个线程,使其非常适合高度并行的任务。
例子:
- CUDA(统一计算设备架构)由NVIDIA。
- OpenCL(开放计算语言)。
- TensorFlow用于深度学习。
现实应用:
- 机器学习和深度学习。
- 实时图形渲染。
- 高性能科学计算。
并发与并行
既然您已经了解了并发和并行的工作原理,让我们在几个方面进行比较,看看如何从两者中获得最佳效果。
1. 资源利用
- 并发:在单个核心内运行多个任务,共享任务之间的资源。例如,CPU在空闲或等待期间在任务之间切换。
- 并行:使用多个核心或处理器同时执行任务。
2. 重点
- 并发:重点在于同时管理多个任务。
- 并行:重点在于同时执行多个任务。
3. 任务执行
- 并发:任务以交替的方式执行。CPU的快速上下文切换创建并行执行的错觉。
- 并行:任务以真正并行的方式在不同的处理器或核心上执行。
4. 上下文切换
- 并发:CPU在任务之间切换时频繁发生上下文切换,以给出同时执行的假象。有时,这可能会对性能产生负面影响,如果任务频繁变得空闲。
- 并行:任务在不同核心或处理器上运行时,几乎没有或没有上下文切换。
5. 用例
- 并发:I/O密集型任务,如磁盘I/O、网络通信或用户输入。
- 并行:需要密集处理的CPU密集型任务,如数学计算、数据分析和图像处理。

我们可以同时使用并发和并行吗?
根据上述比较,我们可以发现并发和并行在许多情况下是互补的。但在进入实际示例之前,让我们看看这种组合在多核环境中如何在后台工作。为此,让我们考虑一个执行数据读取、写入和分析的网络服务器。
步骤1:识别任务
首先,您需要识别应用程序中的I/O密集型任务和CPU密集型任务。在这种情况下:
- I/O密集型 – 数据读取和写入。
- CPU密集型 – 数据分析。
步骤2:并发执行
数据读取和写入任务可以在单个核心内的不同线程中执行,因为它们是I/O密集型任务。服务器使用事件循环来管理这些任务,并在线程之间快速切换,交替执行任务。您可以使用像Python asyncio这样的异步编程库来实现这种并发行为。
步骤3:并行执行
多个核心可以分配给CPU密集型任务,以并行处理它们。在这种情况下,可以将数据分析分为多个子任务,并在独立的核心上执行每个子任务。您可以使用像Python concurrent.futures这样的并行执行框架来实现这种行为。
步骤4:同步与协调
有时,不同核心上运行的线程可能会相互依赖。在这种情况下,需要使用像锁和信号量这样的同步机制,以确保数据完整性并避免竞争条件。
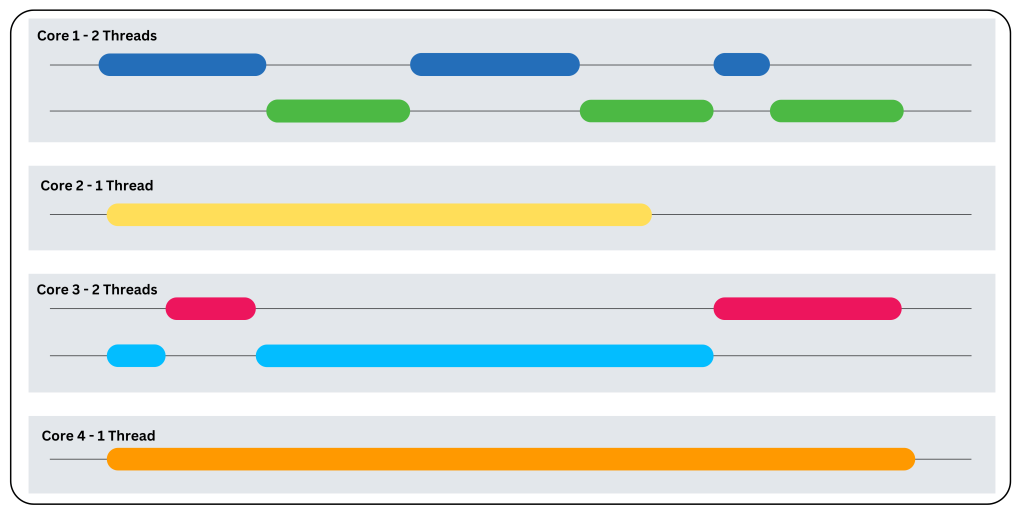
下面的代码片段展示了如何使用Python在同一个应用程序中实现并发和并行:
import asyncio
from concurrent.futures import ProcessPoolExecutor
import os
# Simulate I/O-bound task (data reading)
async def read_data():
await asyncio.sleep(1) # Simulate I/O delay
data = [1, 2, 3, 4, 5] # Dummy data
print("Data read completed")
return data
# Simulate I/O-bound task (data writing)
async def write_data(data):
await asyncio.sleep(1) # Simulate I/O delay
print(f"Data write completed: {data}")
# Simulate CPU-bound task (data analysis)
def analyze_data(data):
print(f"Data analysis started on CPU: {os.getpid()}")
result = [x ** 2 for x in data] # Simulate computation
print(f"Data analysis completed on CPU: {os.getpid()}")
return result
async def handle_request():
# Concurrency: Read data asynchronously
data = await read_data()
# Parallelism: Analyze data in parallel
loop = asyncio.get_event_loop()
with ProcessPoolExecutor() as executor:
analyzed_data = await loop.run_in_executor(executor, analyze_data, data)
# Concurrency: Write data asynchronously
await write_data(analyzed_data)
async def main():
# Simulate handling multiple requests
await asyncio.gather(handle_request(), handle_request())
# Run the server
asyncio.run(main())并发与并行结合的实际示例
现在,让我们讨论一些常见的用例,通过结合并发与并行来实现最佳性能。
1. 金融数据处理
金融数据处理系统的主要任务包括数据收集、处理和分析,同时进行日常操作。
- 使用并发从股票市场等各个资源中获取金融数据,利用异步I/O操作。
- 分析收集的数据以生成报告。这是一个CPU密集型任务,使用并行执行以不影响日常操作的方式进行。
2. 视频处理
视频处理系统的主要任务包括上传、编码/解码和分析视频文件。
- 可以使用并发处理多个视频上传请求,使用异步I/O操作。这允许用户在不等待其他上传完成的情况下上传视频。
- 使用并行处理CPU密集型任务,如编码、解码和分析视频文件。
3. 数据抓取
数据抓取服务的主要任务包括从各个网站获取数据并解析/分析收集的数据以获取见解。
- 数据获取可以通过并发处理。它确保数据收集高效且不会在等待响应时阻塞。
- 使用并行处理跨多个CPU核心处理收集的数据。它通过提供实时报告来改善组织的决策过程。
结论
并发和并行是软件开发中用于提高应用程序性能的两个关键概念。并发允许同时运行多个任务,而并行通过使用多个CPU核心加速数据处理。尽管它们具有不同的功能,但结合它们可以显著提高具有I/O密集型和CPU密集型任务的应用程序的性能。
Bright Data的工具,如网络抓取API、网络抓取功能和抓取浏览器,旨在充分利用这些技术。它们使用异步操作同时从多个来源收集数据,并使用并行处理快速分析和组织数据。因此,选择像Bright Data这样已经在其核心集成了并发和并行的数据提供商,可以节省时间和精力,因为在网络抓取时不需要从头开始实现这些概念。
立即开始您的免费试用吧!



