

在本指南中,您将学习:
- 什么是 CAPTCHA,以及能否绕过它们
- 如何使用 Puppeteer 通过分步教程来绕过 CAPTCHA
- 如果 Puppeteer 的方法不起作用应该怎么办
让我们开始吧!
什么是 CAPTCHA?能绕过它们吗?
CAPTCHA(全称 Completely Automated Public Turing tests to tell Computers and Humans Apart)是一种挑战回应式测试,用于区分人类和自动化程序。为了实现这个目标,CAPTCHA 的设计方式是让人类容易完成,而让软件难以完成。
常见的 CAPTCHA 提供商包括 Google 的reCAPTCHA、hCaptcha和 BotDetect,而常见的 CAPTCHA 类型包括:
- 基于文本:在这些挑战中,用户需要识别字母和数字并输入它们。
- 基于图片:这些测试要求用户在一组图片中识别特定的物体,并选择正确的图片。
- 基于音频:用户需要输入他们听到的字母。
- 拼图挑战:需要用户通过拖动拼图块到正确位置来完成一道简单的拼图。
CAPTCHA 的设计初衷就是让自动化软件和机器人难以绕过。所以,您能做的是将自己的软件与依赖人工操作员或其他算法的 CAPTCHA 解决库或服务集成,以自动化解决这些挑战。
不过,硬编码的 CAPTCHA 并不常见,因为它在网站整体用户体验上会带来负面影响。正因如此,CAPTCHA 更常被用作更广泛防机器人解决方案(比如 Web 应用防火墙,即 WAF)的组成部分:
在这种情况下,系统会在怀疑有机器人活动时动态显示 CAPTCHA。要绕过这些 CAPTCHA,您需要开发一个模拟人类行为的机器人。虽然这可以实现,但需要投入大量精力,尤其是您需要不断更新脚本,以应对越来越新的防机器人检测技术和方法。
好消息是,还有一种更加高效的解决方案来绕过 CAPTCHA:Bright Data 的CAPTCHA Solver!这个随时保持最新的工具无需烦恼即可帮您解决绕过 CAPTCHA 时遇到的所有问题。
轻松绕过任何 CAPTCHA
快速且自动地解决 reCAPTCHA、hCaptcha、px_captcha、SimpleCaptcha、GeeTest CAPTCHA 等。
如何使用 Puppeteer 绕过 CAPTCHA:分步教程
现在是时候创建一个可模拟人类行为的自动化脚本来绕过 CAPTCHA 了。
为此,您可以使用 Puppeteer:这是一个 JavaScript 库,提供了高层次的 API 来控制浏览器,从而模拟人类行为。
让我们开始吧!
步骤 #1:项目初始化
假设您的项目主文件夹命名为bypass_captcha_puppeteer。其目录结构应如下所示:
bypass_captcha_puppeteer/
├── index.js
└── package.json您可以使用以下命令创建:
mkdir bypass_captcha_puppeteer然后,进入该文件夹并运行 npm init 来初始化一个 Node.js 应用:
cd bypass_captcha_puppeteer
npm init -y接下来,在该目录下创建一个 index.js 文件。
如下安装 Puppeteer:
npm install puppeteer步骤 #2:使用 ESM JavaScript 语法
若要在 JavaScript 中使用 ECMAScript Modules 语法,需要在 package.json 文件中添加 "type": "module" 选项。
以下是 package.json 文件的示例:
{
"name": "bypass_captcha_puppeteer",
"version": "1.0.0",
"description": "",
"main": "index.js",
"type": "module",
"scripts": {
"start": "node index.js"
},
"dependencies": {
"puppeteer": "^23.10.4"
}
}步骤 #3:尝试使用 Puppeteer 绕过 CAPTCHA
将以下代码写入 index.js 文件,看看 Puppeteer 是否会被识别为机器人:
import puppeteer from 'puppeteer';
const visitBotAnalyzerPage = async () => {
try {
// initialize the browser
const browser = await puppeteer.launch();
// open a new browser page
const page = await browser.newPage();
// navigate to the target URL
const url = 'https://bot.sannysoft.com/';
console.log(`Navigating to ${url}...`);
await page.goto(url, { waitUntil: 'networkidle2' });
// save a full-page screenshot
console.log('Taking full-page screenshot...');
await page.screenshot({ path: 'anti-bot-analysis.png', fullPage: true });
console.log('Screenshot taken');
// close the browser
await browser.close();
console.log('Browser closed');
} catch (error) {
console.error('An error occurred:', error);
}
};
// run the script
visitBotAnalyzerPage();此代码的工作原理如下:
- 启动浏览器:
puppeteer.launch()方法将启动一个新的浏览器实例(在默认情况下是无头模式(headless:true),如果未指定则为默认),可以通过设置headless: false使其可见。 - 打开新页面:
browser.newPage()创建一个新的空白浏览器页面,后续可以执行操作。 - 跳转到目标页面:
page.goto()方法会跳转到目标页面,这里是 Intoli.com 测试页面,用来检测请求是否来自机器人。 - 获取并保存截图:
page.screenshot()获取页面截图并保存。 - 关闭浏览器并处理错误:
browser.close()关闭浏览器,同时会拦截潜在的错误。
运行该代码:
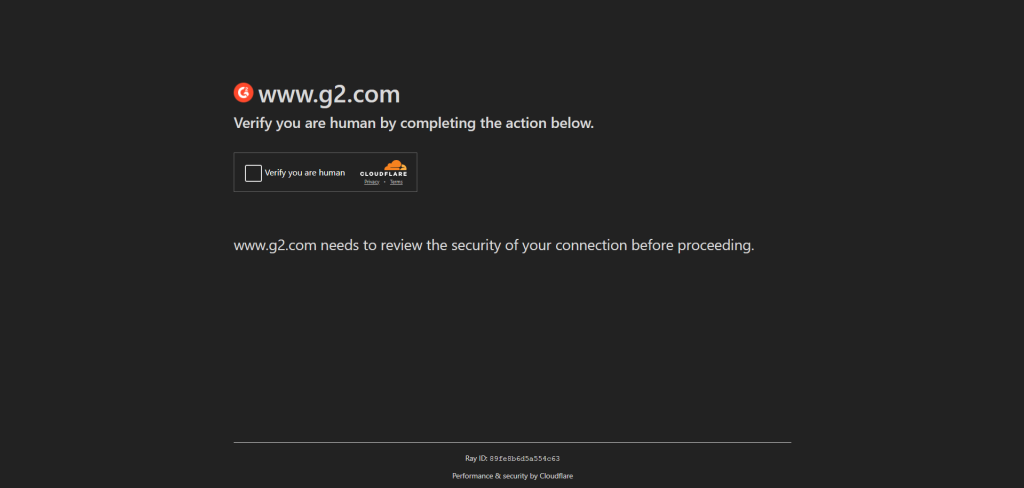
node index.js现在,您可以查看保存的截图。预期结果如下:

如图所示,Puppeteer 没能通过一些测试。因此,当使用 Puppeteer 操作某些页面时,WAF 可能会要求您填写 CAPTCHA。
为了解决这些问题,让我们使用 Puppeteer Stealth!
自动解决 CAPTCHA
Web Unlocker 能自动解决 CAPTCHA,实现无缝访问。
步骤 #4:安装 Stealth 插件
Puppeteer Extra 是对 Puppeteer 的一个轻量级封装,它提供了一些功能,比如可安装 Stealth 插件,通过重写配置让浏览器看起来更加“自然”和“接近人类”,从而防止被检测为机器人。
安装这些库:
npm install puppeteer-extra puppeteer-extra-plugin-stealth然后将 Puppeteer 的导入语句改为从 puppeteer-extra 引入,而不是原本的 puppeteer:
import puppeteer from 'puppeteer-extra';太好了!现在您已准备好使用 Stealth 插件来尝试避免 Puppeteer 中的 CAPTCHA。
步骤 #5:使用 Stealth 插件再次测试
您只需在代码中加入此行:
puppeteer.use(StealthPlugin()).于是,完整的代码如下:
import puppeteer from 'puppeteer-extra';
import StealthPlugin from 'puppeteer-extra-plugin-stealth';
// Add the stealth plugin to Puppeteer
puppeteer.use(StealthPlugin());
const visitBotAnalyzerPage = async () => {
try {
// launch the browser with stealth settings
const browser = await puppeteer.launch();
console.log('Launching browser in stealth mode...');
// open a new page
const page = await browser.newPage();
// navigate to the target page
const url = 'https://bot.sannysoft.com/';
console.log(`Navigating to ${url}...`);
await page.goto(url, { waitUntil: 'networkidle2' });
// save the screenshot of the entire page
console.log('Taking full-page screenshot...');
await page.screenshot({ path: 'anti-bot-analysis.png', fullPage: true });
console.log(`Screenshot taken`);
// close the browser
await browser.close();
console.log('Browser closed. Script completed successfully');
} catch (error) {
console.error('Error occurred:', error);
}
};
// run the script
visitBotAnalyzerPage();再次运行:
node index.js预期结果如下:
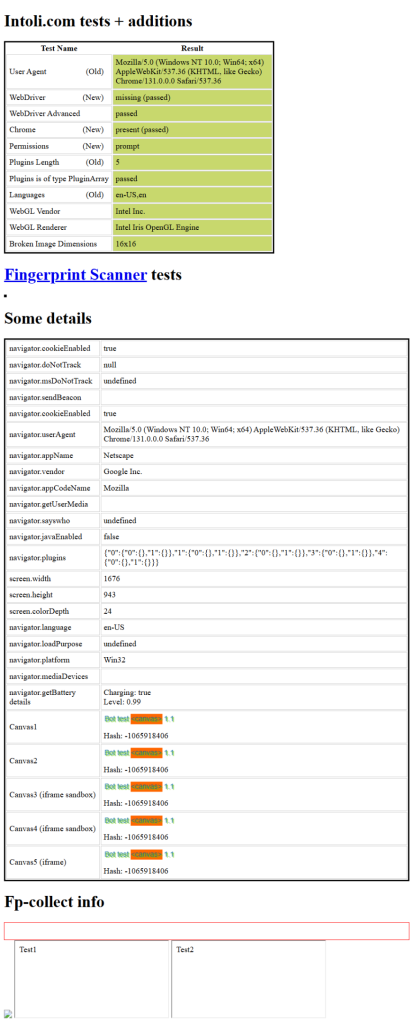
太好了!脚本现在通过了反机器人测试,这意味着在使用 Puppeteer 时,您更不容易被要求填写 CAPTCHA。
如果前面使用 Puppeteer 绕过 CAPTCHA 的方法无效该怎么办
遗憾的是,Puppeteer Extra 并非总是万能的。原因在于,浏览器设置并不是反机器人系统用来阻止自动化软件的唯一方式。
例如,User-Agent 也是反机器人系统判断行为的一个重要因素。为解决此问题,您可以使用 puppeteer-extra-plugin-anonymize-ua 库,它可以让 User-Agent 更加匿名化。
不过,上述基于插件的方法只能对付较为基础的反机器人措施;当面对更复杂的服务(例如 Cloudflare)时,还需要更强大的方法。
那么……您在寻找真正的 Playwright CAPTCHA 解决方案吗?试试 Bright Data 的网页抓取解决方案吧!
它们提供了更高级的解锁能力,并且配备专门的 CAPTCHA 解题功能,可以自动处理 reCAPTCHA、hCaptcha、px_captcha、SimpleCaptcha、GeeTest CAPTCHA、FunCaptcha、Cloudflare Turnstile、AWS WAF Captcha、KeyCAPTCHA 等各种测试。
将 Bright Data 的 CAPTCHA Solver 集成到您的脚本十分方便,因为它可以与任何 HTTP 客户端或浏览器自动化工具兼容。
了解更多有关 如何使用 Bright Data 的 CAPTCHA Solver的信息,并查阅文档获取完整的集成和配置细节。
轻松解决 CAPTCHA
Web Unlocker 处理 CAPTCHA、反机器人检测和 IP 轮换,让您可以专注于抓取。
结论
在本文中,您了解了为什么用 Puppeteer 绕过 CAPTCHA 具有挑战性,以及如何使用 Stealth 插件来修改浏览器默认配置,从而绕过自动化检测。
问题在于,这种方法仅适用于简单场景。对于高级的反机器人检测系统,它们仍然可能识别出您是机器人并进行拦截。
因此,当需要绕过 CAPTCHA 时,真正的解决方案是在一个专门的解锁 API 的帮助下连接到目标页面,从而无缝返回没有 CAPTCHA 的网页 HTML。这种方案已经存在,名为 Web Unlocker。它的目标是通过代理集成自动轮换出口 IP、处理浏览器指纹、自动重试以及自动解决 CAPTCHA 来帮助您实现。
立即注册,了解哪种 Bright Data 的抓取产品最适合您的需求。
从免费试用开始吧!



