

简单来说,错误数据是指由于各种原因进入您的数据基础设施的不完整、不准确、不一致、不相关或重复的数据。
阅读完这篇文章后,您将了解:
- 什么是错误数据
- 各种类型的错误数据
- 导致错误数据的原因
- 其后果和预防措施
那么,让我们进一步了解一下:
不同类型的错误数据
几乎在所有领域,从业务分析到 AI模型训练,数据质量和可靠性都是至关重要的。质量差的数据表现为几种不同的形式,每种形式都对数据的可用性和完整性提出了独特的挑战。
不完整数据
不完整数据是指当一个 数据集 缺少一个或多个必要属性、字段或条目,无法进行准确分析时。这些缺失的信息会使整个数据集不可靠,有时甚至无法使用。
不完整数据的常见原因包括有意省略特定数据、未记录的交易、部分数据收集、数据输入错误、数据传输过程中出现的技术问题等。
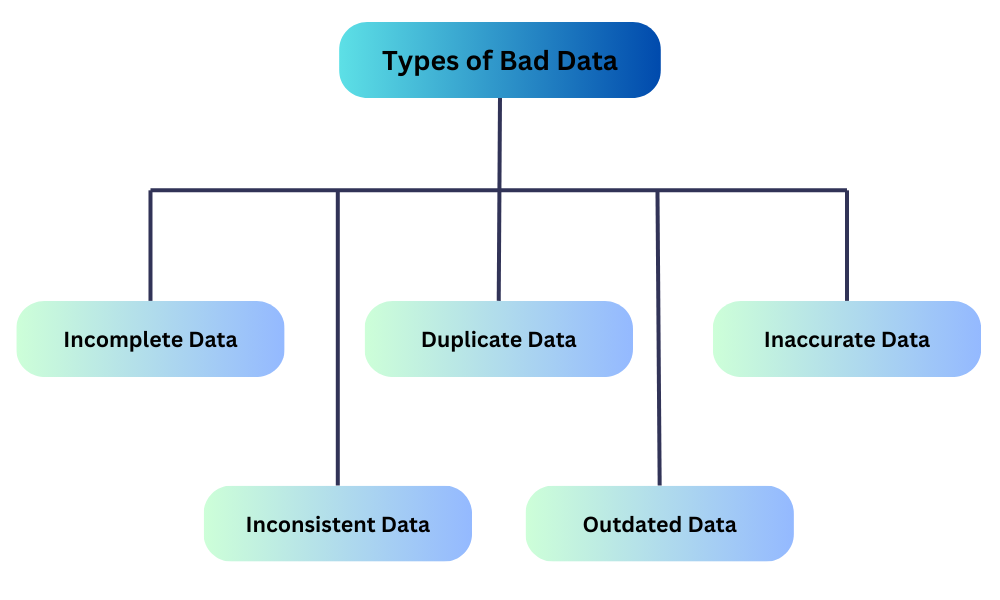
例如,考虑一种情况,一个客户调查缺少联系信息记录。这使得以后无法跟进受访者,如下所示。
另一个例子是,医院数据库中缺少患者的重要信息,如过敏史和既往病史,这可能会导致危及生命的情况。
重复数据
重复数据是指在 数据库中多次记录相同或几乎相同的数据条目。这种冗余会导致误导性的分析和错误的结论,有时还会使合并操作和系统故障变得复杂。包含重复数据的数据集得出的统计数据变得不可靠,并且在决策过程中效率低下。
示例:
- 客户关系管理(CRM)数据库中对同一客户有多个记录,这会扭曲分析后得出的信息,例如不同客户的数量或每个客户的销售量。
- 库存管理系统中同一产品存储在不同SKU编号下,使得库存估算不准确。
不准确数据
不准确数据是指数据集中存在错误或不正确的信息。
由于打字错误或无意的疏忽,代码或数字中的简单错误可能会严重到在高风险领域的决策中造成严重的并发症和损失。数据中存在不准确信息会降低整个数据集的可信度和可靠性。
示例:
- 运输公司数据库中存储了错误的送货地址,可能会将包裹送到错误的地点,甚至是错误的国家,给公司和客户带来巨大的损失和延误。
- 人力资源管理系统(HRMS)中包含错误的员工薪资信息,可能会导致工资差异和潜在的法律问题。
不一致数据
不一致数据是指当不同的人或团队在组织内对同一类型的数据使用不同的单位或格式时,会导致混乱和低效率。这会中断数据之间的一致性和连续性,导致数据处理错误。
示例:
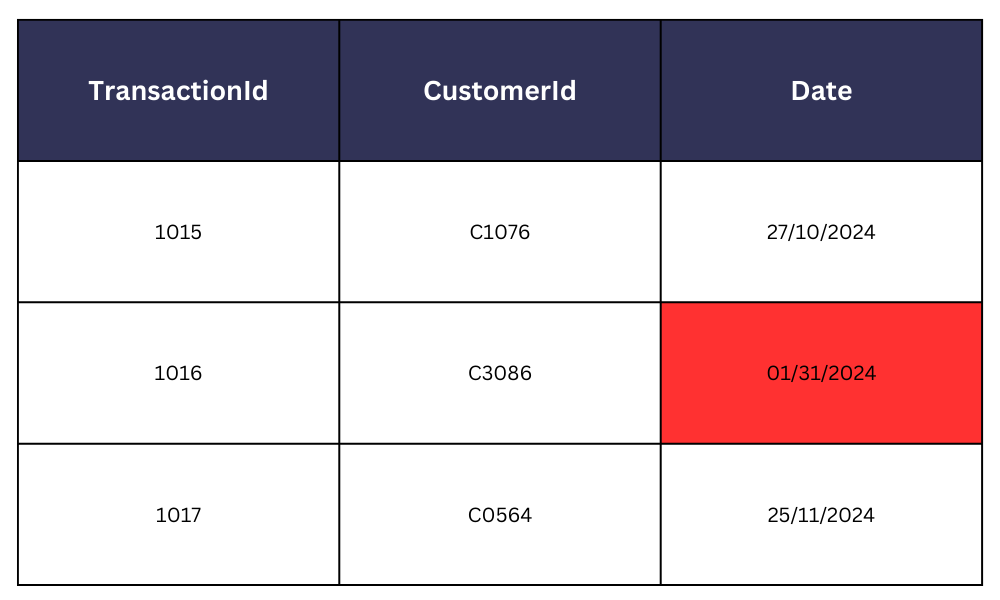
- 在多个数据条目中使用不一致的日期格式(MM/DD/YYYY与DD/MM/YYYY),例如在银行系统中,可能会在数据聚合和分析过程中引发冲突和问题。

- 同一零售连锁店的两家门店在输入库存数据时使用不同的计量单位(箱数与单件数),会在补货和分发时造成混乱。
过时数据
简单来说,过时数据是指不再当前、相关和适用的记录。特别是在快速变化的领域,过时数据非常常见,随着变化的快速发生,来自十年前、一年前甚至一个月前的数据可能会变得不再有用,甚至具有误导性。
示例:
- 一个人可能会随着时间的推移发展出新的过敏症。医院根据过时的过敏信息给患者开药,可能会危及患者的安全。
- 房地产中介列出来自过时数据源的房产信息,可能会浪费时间和精力在已经售出或不再可用的房产上。这是不高效的,会损害公司的声誉。
此外,不合规、不相关、非结构化和偏见数据也是会损害您的数据生态系统数据质量的错误数据类型。了解这些各种错误数据类型对于了解其根本原因及其对业务的威胁并制定减轻影响的策略至关重要。
导致错误数据的原因
现在您已经清楚了解了错误数据的类型。了解其原因同样重要,这样您可以采取主动措施防止这种情况在您的数据集中发生。
导致错误数据的一些原因包括:
- 数据输入过程中的人为错误:毫无疑问,这是导致错误数据最常见的原因,特别是不完整、不准确和重复数据。培训不足、缺乏细节关注、对数据输入过程的误解以及大多数无意的错误,如打字错误,最终会导致数据集不可靠,并在分析过程中带来巨大复杂性。
- 糟糕的数据输入实践和标准:建立一套健全的标准是构建坚实且结构良好的实践的关键。例如,如果您允许一个字段(如国家)输入自由文本,用户可能会为同一个国家输入不同的名称(例如:USA、United States、U.S.A.),导致对同一值的响应种类繁多且低效。这种不一致和混乱是由于没有适当设定标准造成的。
- 迁移问题:错误数据并不总是手动输入的结果。它还可能是从 一个数据库迁移到另一个数据库的结果。这种问题会导致记录和字段的不对齐、数据丢失甚至数据损坏,可能需要长时间的审查和修复。
- 数据退化:从客户偏好到市场趋势的每一个小变化都会更新 公司数据。如果数据库未能不断更新以匹配这些变化,它将变成过时数据,导致数据衰减或数据退化。过时数据在决策和分析中没有实际用途,使用时会造成误导信息。
- 合并来自多个来源的数据:低效地将来自多个来源的数据合并或错误的数据集成会导致不准确和不一致的数据。当合并的数据源的格式、标准和质量水平不一致时,就会发生这种情况。

错误数据的影响
如果您处理的数据集中有错误数据,您将使最终分析面临风险。事实上,错误数据会对依赖数据的业务和领域产生长期和毁灭性的影响,例如:
- 糟糕的数据质量会增加根据误导信息做出错误决策和投资的风险,从而损害您的业务。
- 错误数据会造成大量财务成本,包括浪费资源和损失收入。弥补错误数据留下的影响可能需要大量资金和时间。
- 错误数据的积累甚至会导致业务失败,因为它增加了返工的需求,导致错失机会,并整体上降低了生产力。
- 因此,企业的可信度和可靠性下降,严重损害客户满意度和保留率。公司端的不准确和不完整数据导致糟糕的客户服务和不一致的沟通。
此外,错误数据可能会导致关键错误,加速为法律或危及生命的并发症,尤其是在金融和医疗领域。
例如,在2020年COVID-19大流行期间,英格兰公共卫生部 (PHE)发生了一次重大数据管理错误,导致15,841例COVID-19病例未报告,原因是错误数据。问题出在PHE使用的Excel电子表格版本过时,无法容纳超过65,000行,而实际可以容纳超过一百万行。第三方公司分析拭子测试提供的一些记录丢失,导致数据不完整。由于这一技术错误,错过了大约50,000个有感染风险的密切接触者。
此外,2018年三星的“胖手指”错误导致股票价格在一天内下跌约11%,损失了近3亿美元的市值。原因是三星证券的一名员工在公司股票所有权计划中输入了2.8亿“股”(价值1050亿美元)而不是2.8亿“韩元”,导致了这一错误。
因此,不应轻视错误数据的后果,必须采取适当的预防措施来消除风险。
预防错误数据
没有哪个数据集是完美的。您的数据必然会有错误。预防错误数据的第一步是承认这一现实,以便实施必要的预防策略来确保数据质量。
一些预防错误数据的步骤包括:
- 实施强大的数据治理是建立组织内责任和标准的关键步骤。它可以帮助您制定清晰的政策和程序,管理、访问和维护数据,从而最大限度地减少错误数据的风险。
- 定期进行数据审计,以在出现问题之前发现不一致和过时的数据。
- 通过在整个组织中设置标准、数据验证规则和标准格式和模板来规范数据输入过程,以减少人为错误。
- 知识渊博的员工在处理和管理数据时犯错最少。因此,定期培训和更新会话是必要的,以保持员工对标准过程的了解。
- 定期备份数据,以防止意外事件中的数据丢失。
- 使用专为数据验证设计的高级工具,以确保数据的一致性和完整性。这些工具可以确认数据的准确性和完整性,检测和纠正潜在错误。
总结
本文探讨了什么是错误数据,您可能遇到的不同类型的错误数据及其原因。此外,还重点介绍了错误数据对依赖数据的组织的重大负面影响,从财务损失到业务失败。了解这些因素是预防错误数据的第一步。
尽管有多种预防策略来确保数据质量,但使用专门为此目的设计的可靠工具一定会减轻您的负担。
考虑使用数据抓取工具,让您自动构建可靠且干净的数据集。这将减少您的工作量,为您提供干净且直接可用的数据。一个可以实现这一目标的工具是 Bright Data的Web Scraper API。不想处理抓取?立即注册并下载我们的免费数据集样本!



