

在本Excel抓取指南中,您将了解到:
- 什么是VBA。
- 自定义VBA模块是否允许您从网络获取数据。
- 如何在Internet Explorer支持结束后处理Excel中的网页抓取。
- 如何使用Selenium编写VBA代码进行网页抓取。
- Excel中在线数据检索的传统方法。
让我们开始吧!
什么是VBA?
VBA,即应用程序的Visual Basic,是由微软开发的编程语言。其目标是让用户能够在各种Microsoft Office应用程序(包括Excel、Word和Access)中自动执行任务和编写自定义函数。
在Excel中,VBA可用于定义与电子表格单元格中的数据交互的复杂宏。使用VBA,您可以提高生产力,简化工作流程,并扩展Excel的功能超越其内置函数。
是否可以使用VBA在Excel中进行网页抓取?
是的,VBA可以直接在Excel中进行网页抓取。感谢VBA,您可以编写自定义模块来:
- 在浏览器中连接到网页。
- 解析其HTML内容。
- 从中提取数据。
- 将抓取的数据直接写入Excel单元格中。
这就是网页抓取的全部内容。因此,使用VBA进行抓取不仅可能而且高效,因为它直接将数据导入Excel中。在本节中了解更多关于Excel抓取的优缺点!
Excel网页抓取的优缺点
在深入了解如何编写VBA代码进行网页抓取之前,让我们先看看在Excel中使用VBA进行网页抓取的一些优缺点。
👍 优点
- 访问Excel功能:抓取的数据直接导入Excel,使您可以使用Excel强大的数据操作和分析功能。
- 开箱即用:Microsoft Office自带VBA支持。只需在PC上安装Microsoft Office 365,就具备了进行网页抓取所需的一切。
- 一体化自动化:使用VBA网页抓取脚本,您可以自动执行完整的数据收集任务,从数据检索到Excel中的数据表示。
👎 缺点
- 某些功能仅在Windows上可用:用于Active-X控件和COM自动化的VBA包仅在Windows上可用,不适用于Mac版Office。
- VBA显得陈旧:Visual Basic不是最现代的编程语言。如果您从未使用过它,可能会因为其旧的语法和编码方法而觉得难以使用。
- Internet Explorer现已弃用:VBA COM自动化控制网页浏览器是基于Internet Explorer的,而Internet Explorer现已弃用。
最后一个缺点比较重大,因此需要更深入的分析。
如何处理VBA网页抓取中的Internet Explorer弃用问题?
传统的编写VBA代码进行网页抓取的方法依赖于带有InternetExplorer对象的COM自动化接口。这提供了访问网站、解析其HTML内容和从中提取数据所需的一切。问题是Internet Explorer自2022年6月15日起不再受支持。
换句话说,大多数最新版本的Windows甚至不包含Internet Explorer。因此,在VBA脚本中使用InternetExplorer对象会导致错误。由于Edge是Internet Explorer的替代品,您可能会考虑在VBA中使用等效对象。但是,Edge不带有COM自动化接口。因此,您无法像控制Internet Explorer那样以编程方式控制它。
相反,Edge支持通过Web驱动程序进行自动化,您可以通过Selenium等浏览器自动化技术进行控制。因此,当前支持的Excel VBA网页抓取方法是使用VBA的Selenium绑定。这使您可以控制Chrome、Edge或Firefox等浏览器。
在下面的部分中,您将构建一个使用Selenium和Edge的Excel网页抓取脚本。稍后,您还将看到不需要任何第三方依赖项的传统方法代码片段。
如何使用Selenium编写VBA代码进行网页抓取
在本教程部分,您将学习如何使用SeleniumBasic(VBA的Selenium API绑定)在VBA中进行Excel网页抓取。
目标站点将是Scrape This Site国家沙盒,其中包含世界上所有国家的列表:
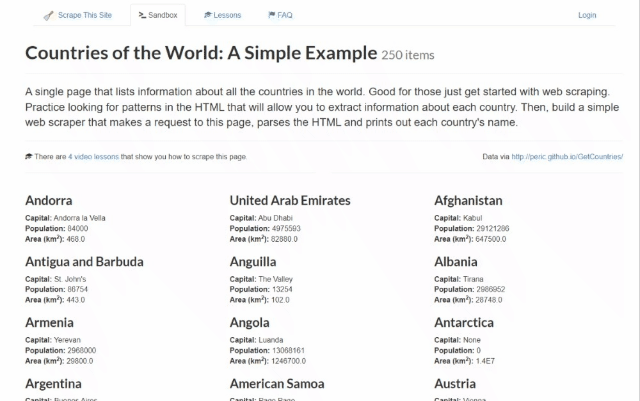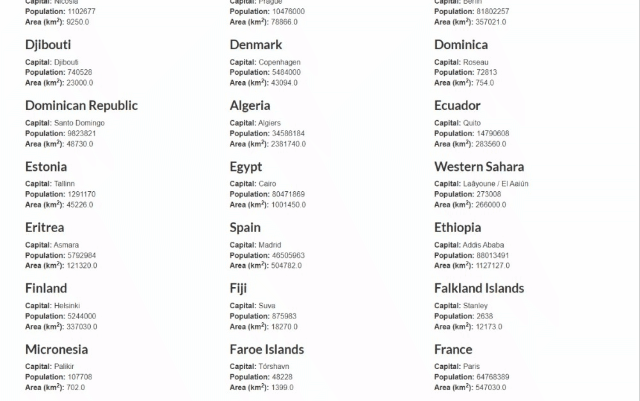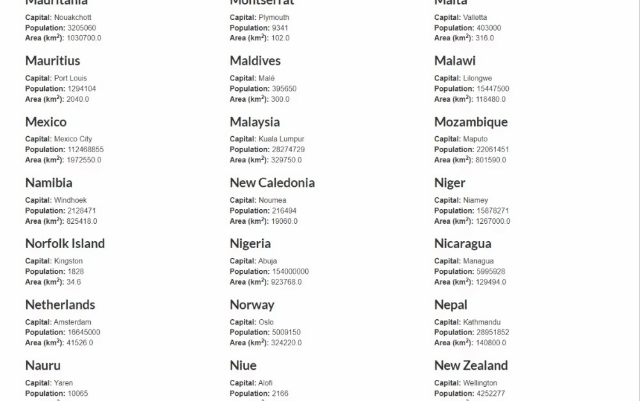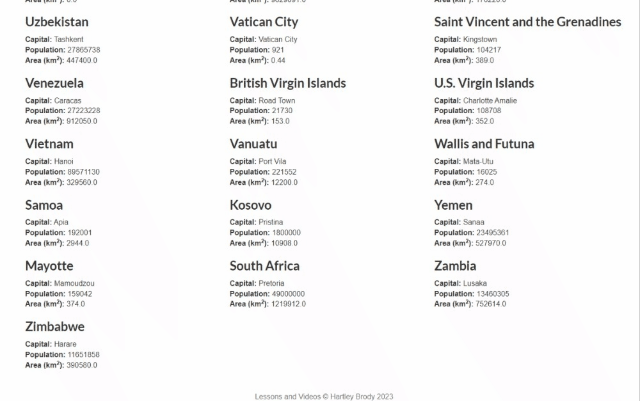
VBA抓取器的目标是自动获取这些数据并将其写入Excel电子表格。
是时候编写一些VBA代码了!
前提条件
确保您的机器上安装了最新版本的Microsoft Office 365。本节涉及Windows 11和Office 2024更新。同时,以下步骤在macOS和其他版本的Office中相同或相似。
请注意,桌面版Office是本教程的必需品。免费Microsoft 365网页版不支持VBA脚本。
步骤#1:安装并设置SeleniumBasic
从GitHub仓库的发布页面下载SeleniumBasic安装程序:
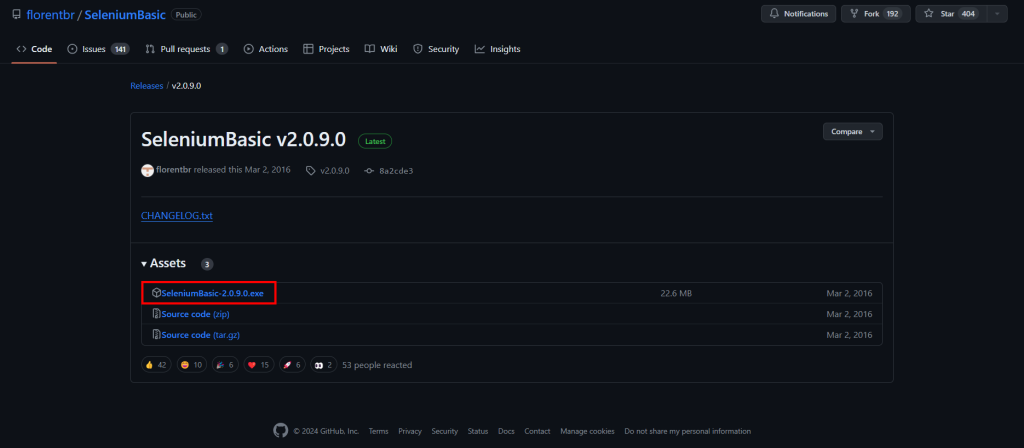
双击.exe安装程序,等待安装过程完成。
与大多数VBA包一样,SeleniumBasic已经多年没有更新。因此,它附带的Web驱动程序不再适用于最近的浏览器。为了解决这个问题,您需要手动覆盖SeleniumBasic安装文件夹中的驱动程序可执行文件。
在这里,您将看到如何覆盖Edge Web驱动程序,但您可以对Chrome和Firefox执行相同的操作。
首先,下载最新稳定版本的Microsoft Edge WebDriver:
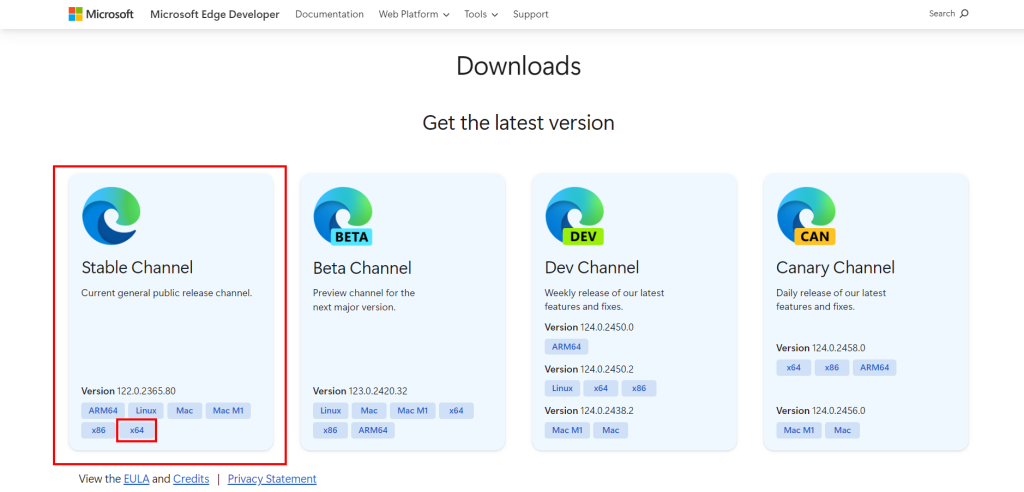
“x64″版本应该是您所需的。
现在应该有一个edgedriver_win64.zip文件。解压它,进入解压后的文件夹,并确保其中包含msedgedriver.exe可执行文件。这就是Edge WebDriver可执行文件。
将其重命名为“edgedriver.exe”,并准备将其放入正确的文件夹中。
打开您应该在以下位置找到的SeleniumBasic安装文件夹:
C:UsersAppDataLocalSeleniumBasic
将edgedriver.exe放入该文件夹,覆盖现有的Edge WebDriver可执行文件。
太好了!SeleniumBasic现在能够在Excel中控制最新版本的Edge。
步骤#2:启动Excel
打开Windows开始菜单,键入“Excel”,然后单击“Excel”应用程序。选择“空白工作簿”选项以创建新电子表格:
在本节结束时,这将包含抓取的数据。
步骤#3:启用开发者选项卡
如果您查看顶部的选项卡栏,您将看不到任何创建VBA脚本的选项。这是因为您必须首先在Excel配置中启用它。
为此,请单击左上角的“文件”:
然后,如下选择“选项”:
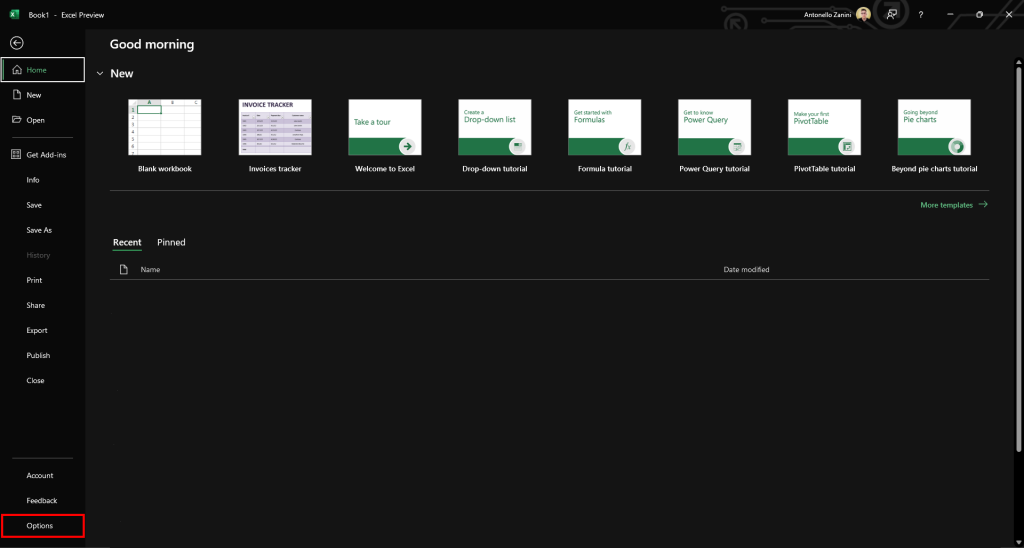
在“选项”弹出窗口中,进入“自定义功能区”选项卡,并在“主选项卡”部分勾选“开发者”选项:
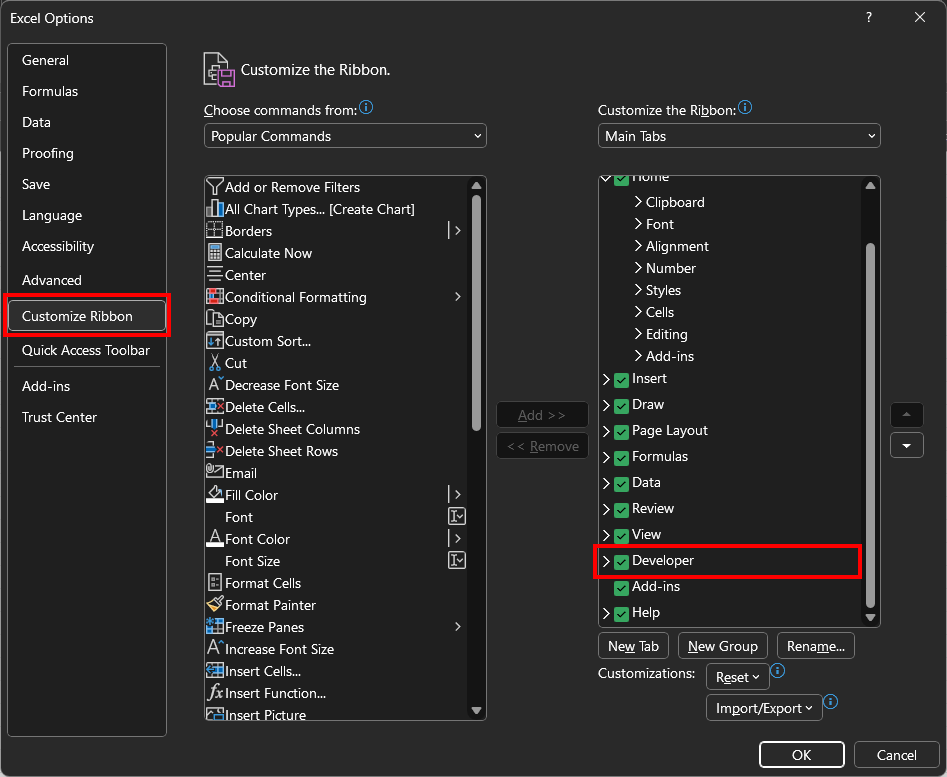
按“确定”,一个新的“开发者”选项卡将出现:
步骤#4:初始化VBA网页抓取模块
单击“开发者”选项卡并按“Visual Basic”按钮:
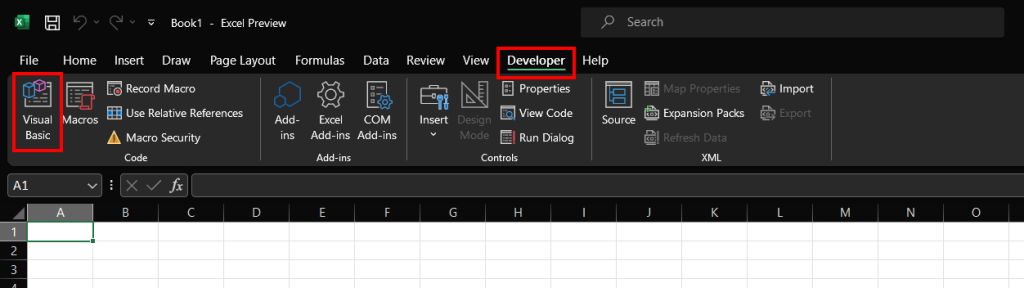
这将打开以下窗口:
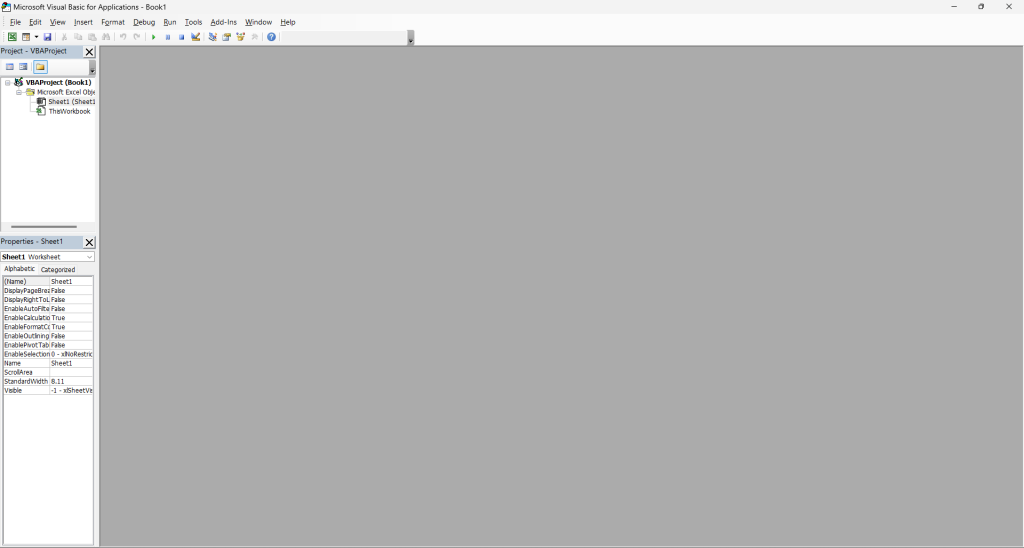
在这里,点击顶部菜单中的“插入”,然后选择“模块”以初始化您的VBA抓取模块:
这就是您现在应该看到的内容:
“Book1 – Module1(代码)”内部窗口是您应该编写网页抓取VBA代码的地方。
步骤#5:导入Seleniumbasic
在顶部菜单中,单击“工具”,然后选择“引用…”
在弹出窗口中,找到“Selenium类型库”并勾选它:
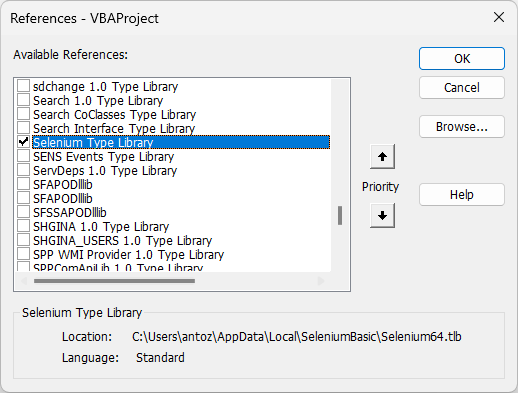
单击“确定”按钮,您现在可以在Excel中使用Selenium进行网页抓取。
步骤#6:自动化Edge打开目标站点
将以下代码粘贴到VBA模块窗口中:
Sub scrape_countries()
' initialize a Selenium WebDriver instance
Dim driver As New WebDriver
' open a new Edge window
driver.Start "Edge"
' navigate to the target page
driver.Get "https://www.scrapethissite.com/pages/simple/"
' wait 10 seconds before shutting down the application
Application.Wait Now + TimeValue("00:00:10")
' close the current driver window
driver.Quit
End Sub这将初始化一个Selenium实例,并使用它来指示Edge访问目标页面。通过单击运行按钮测试代码:
这将打开以下Edge窗口:
请注意“Microsoft Edge正在被自动测试软件控制。”消息,这表明Selenium正在按预期操作Edge。
如果您不希望Edge显示,可以通过以下行启用无头模式:
driver.SetCapability "ms:edgeOptions", "{""args"":[""--headless""]}"步骤#7:检查页面的HTML代码
网页抓取涉及选择页面上的HTML元素并从中收集数据。CSS选择器是选择HTML节点的最流行方法之一。如果您是Web开发人员,您应该已经熟悉它们。否则,请浏览官方文档。
要定义有效的CSS选择器,您首先需要熟悉目标页面的HTML。因此,在浏览器中打开Scrape This Site国家沙盒,右键单击国家元素,然后选择“检查”选项:
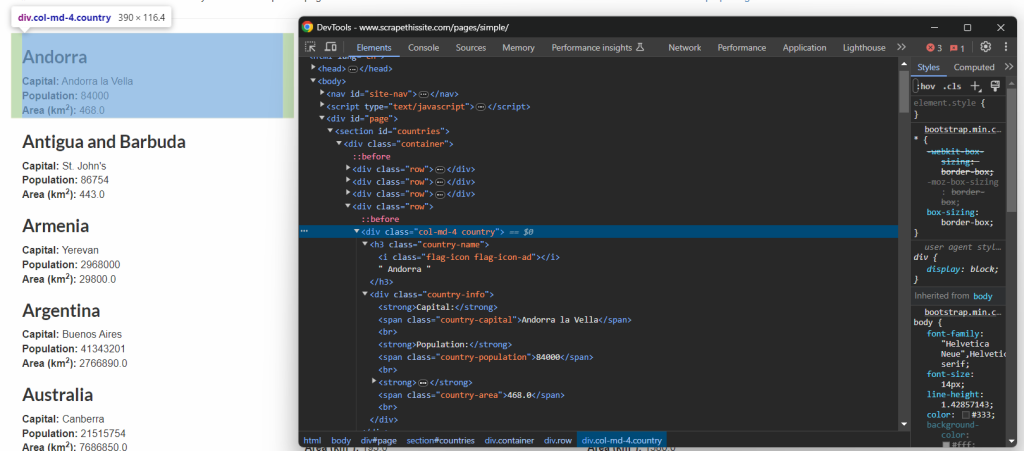
在这里,您可以看到每个国家HTML元素是一个<div>,您可以使用以下CSS选择器进行选择:
.country给定一个.country HTML节点,您应该选择:
- .country-name元素中的国家名称。
- .country-capital元素中的首都名称。
- .country-population元素中的人口信息。
- .country-area元素中的国家占地面积(单位:平方公里)。
这些就是选择所需HTML节点并从中提取数据的所有CSS选择器。请参阅下一步中的使用方法!
步骤#8:编写VBA网页抓取逻辑
使用driver公开的FindElementsByCss()方法应用.country CSS选择器并选择页面上的所有国家HTML节点:
Dim countryHTMLElements As WebElements
Set countryHTMLElements = driver.FindElementsByCss(".country")
Then, define an integer counter to keep track of the current Excel row to write data in:
Dim currentRow As Integer
currentRow = 1接下来,迭代国家HTML节点,从中提取所需数据,并使用Cells()函数将其写入Excel单元格:
For Each countryHTMLElement In countryHTMLElements
' where to store the scraped data
Dim name, capital, population, area As String
' data retrieval logic
name = countryHTMLElement.FindElementByCss(".country-name").Text
capital = countryHTMLElement.FindElementByCss(".country-capital").Text
population = countryHTMLElement.FindElementByCss(".country-population").Text
area = countryHTMLElement.FindElementByCss(".country-area").Text
' write the scraped data in Excel cells
Cells(currentRow, 1).Value = name
Cells(currentRow, 2).Value = capital
Cells(currentRow, 3).Value = population
Cells(currentRow, 4).Value = area
' increment the row counter
currentRow = currentRow + 1
Next countryHTMLElement太棒了!您已经准备好查看最终的Excel网页抓取代码。
步骤#9:整合所有内容
您的VBA网页抓取模块现在应该包含:
Sub scrape_countries()
' initialize a Selenium WebDriver instance
Dim driver As New WebDriver
' enable the "headless" mode
driver.SetCapability "ms:edgeOptions", "{""args"":[""--headless""]}"
' open a new Edge window
driver.Start "Edge"
' navigate to the target page
driver.Get "https://www.scrapethissite.com/pages/simple/"
' select all country HTML nodes on the page
Dim countryHTMLElements As WebElements
Set countryHTMLElements = driver.FindElementsByCss(".country")
' counter to the current row
Dim currentRow As Integer
currentRow = 1
' iterate over each country HTML node and
' apply the Excel scraping logic
For Each countryHTMLElement In countryHTMLElements
' where to store the scraped data
Dim name, capital, population, area As String
' data retrieval logic
name = countryHTMLElement.FindElementByCss(".country-name").Text
capital = countryHTMLElement.FindElementByCss(".country-capital").Text
population = countryHTMLElement.FindElementByCss(".country-population").Text
area = countryHTMLElement.FindElementByCss(".country-area").Text
' write the scraped data in Excel cells
Cells(currentRow, 1).Value = name
Cells(currentRow, 2).Value = capital
Cells(currentRow, 3).Value = population
Cells(currentRow, 4).Value = area
' increment the row counter
currentRow = currentRow + 1
Next countryHTMLElement
' close the current driver window
driver.Quit
End Sub运行它并等待模块执行完成。在VBA脚本结束时,Excel电子表格将包含:
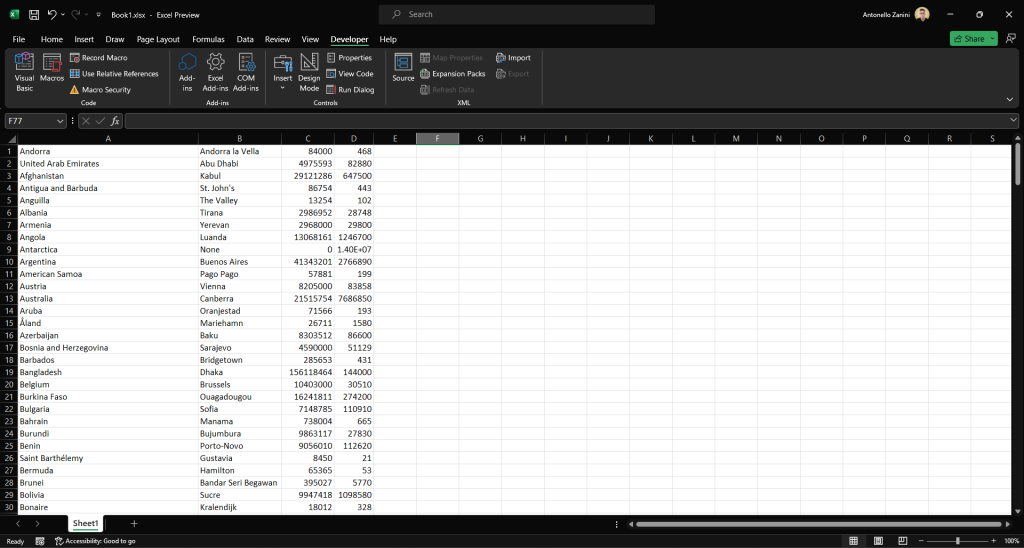
该文件包含与目标站点相同的数据,但采用半结构化格式。由于Excel提供的功能,分析和过滤这些数据现在将变得更加容易。
就是这样!在不到100行的VBA代码中,您刚刚在Excel中进行了网页抓取!
了解更多关于Excel中网页抓取的工作原理。
使用Internet Explorer进行VBA网页抓取的传统方法
如果您使用的是旧版本的Windows,您可以使用Internet Explorer在VBA中进行网页抓取。
您只需启用“Microsoft HTML对象库”和“Microsoft Internet Controls”引用:
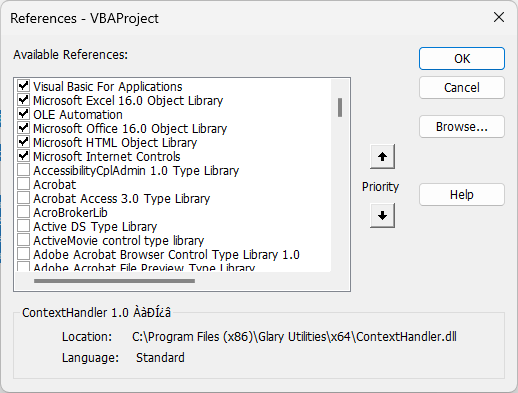
请注意,这两个包内置于Excel中,因此这次您无需安装额外的库。
然后,您可以使用以下VBA代码进行网页抓取,达到与之前相同的结果:
Sub scrape_countries()
' start Internet Explorer
Dim browser As InternetExplorer
Set browser = New InternetExplorer
' enable the "headless" mode
browser.Visible = False
'visit the target page
browser.navigate "https://www.scrapethissite.com/pages/simple/"
' wait for the browser to load the page
Do: DoEvents: Loop Until browser.readyState = 4
' get the current page
Dim page As HTMLDocument
Set page = browser.document
' retrieve all country HTML nodes on the page
Dim countryHTMLNodes As Object
Set countryHTMLElements = page.getElementsByClassName("country")
' counter to the current row
Dim currentRow As Integer
currentRow = 1
' iterate over each country HTML node and
' apply the Excel scraping logic
For Each countryHTMLElement In countryHTMLElements
' where to store the scraped data
Dim name, capital, population, area As String
' data retrieval logic
name = countryHTMLElement.getElementsByClassName("country-name")(0).innerText
capital = countryHTMLElement.getElementsByClassName("country-capital")(0).innerText
population = countryHTMLElement.getElementsByClassName("country-population")(0).innerText
area = countryHTMLElement.getElementsByClassName("country-area")(0).innerText
' write the scraped data in Excel cells
Cells(currentRow, 1).Value = name
Cells(currentRow, 2).Value = capital
Cells(currentRow, 3).Value = population
Cells(currentRow, 4).Value = area
' increment the row counter
currentRow = currentRow + 1
Next countryHTMLElement
' close the current Internext Explorer window
browser.Quit
End Sub运行此VBA模块,您将获得与之前相同的结果。太棒了!您刚刚使用Internet Explorer在Excel中进行了网页抓取。
总结
在本指南中,您了解了什么是VBA以及为什么它允许您在Excel中进行网页抓取。问题在于VBA浏览器自动化库依赖于不再受支持的Internet Explorer。在这里,您探索了使用Selenium在Excel中自动化数据检索的等效方法。还看到了适用于旧版Windows的传统方法。
同时,请记住,从互联网提取数据时需要考虑许多挑战。特别是大多数网站采用防抓取和反机器人解决方案,可以检测并阻止您的VBA网页抓取脚本。使用我们的抓取浏览器解决方案避免所有这些问题。此下一代浏览器与Selenium集成,并可以自动为您处理验证码解决、浏览器指纹、自动重试等问题!
不想处理网页抓取但对Excel数据感兴趣?探索我们现成的数据集。不确定选择哪种数据解决方案?今天就联系我们!



技术写作
 5.5 years experience
5.5 years experience
Antonello是一名软件工程师,但他更喜欢称自己为技术传教士。通过写作传播知识是他的使命。




