

本文将讨论:
- 什么是结构化数据
- 什么是非结构化数据
- 什么是半结构化数据
- 关键区别:结构化数据与非结构化数据
- 通过示例展示每种数据类型
- 如何收集结构化/非结构化数据
什么是结构化数据
结构化数据集或“结构化数据”是网络数据的“最干净”形式。这意味着没有多余的文件副本或数据点,没有损坏的数据。结构化数据集已经被转换或收集为相同的格式(例如 JSON、CSV、HTML 或 Microsoft Excel)。这意味着这些信息可以很容易地存储在数据库和数据湖中,并通过系统和算法进行分析,从而获得高价值的见解。
结构化数据的主要优势
许多公司更喜欢使用结构化数据,原因如下:
原因一:收集和使用所需资源较少
当公司寻求收集和利用数据时,他们更喜欢结构化数据,因为它需要的时间、技术专家和精力显著减少。结构化数据不包含任何:
- 重复/不完整的数据点
- 损坏的文件
- 格式不正确或标签错误的数据集
实际上,这意味着企业可以将精力集中在核心业务发展上,而不是数据收集本身。
原因二:查询和分析速度快
延续原因一,由于结构化数据不需要进一步处理,从“收集到获取适用见解”的时间减少。这意味着利用结构化数据的公司可以为客户提供不仅是信息上的优势,还有时间上的优势,超越竞争对手。
结构化数据的主要劣势
以下是公司在使用结构化数据时可能遇到的一些问题:
原因一:灵活性和适应性有限
与生活中的许多事物一样,结构化数据的一个最大优势(即格式化)也是其阿喀琉斯之踵。举例来说,想象一个公司为其分析师收集股票走势数据,以 Microsoft Excel 格式存储。但在将这些数据输入其股票表现预测算法时,需要 JSON 格式的数据。这导致灵活性不足,有时会影响快速/同步进展。
原因二:存储选项有限
存储有时可能会很复杂,特别是在处理数据仓库时。原因是这些通常有“固定模式”,需求的变化可能导致企业在数据/仓库兼容性上浪费时间和人力。
什么是非结构化数据
非结构化数据可以被概念化为未经加工的钻石或原油。非结构化数据可能包含各种格式的信息,在给定的数据集中重复出现的条目,或包含损坏的文件。这些数据需要经过耗时的“清理”/“格式化”过程才能保存、分析,并提供给团队或算法。
非结构化数据的主要优势
某些公司可能更喜欢非结构化数据,原因如下:
原因一:启动收集任务更快
非结构化数据收集任务可以更快地设置和运行,因为需要遵守的技术收集参数较少。
原因二:格式多样性
由于非结构化数据可能以多种格式出现,可以根据需要定义,增加了灵活性和可用性。
非结构化数据的主要劣势
使用非结构化数据的劣势包括:
原因一:定制系统
需要处理非结构化数据的公司将需要支付或开发定制工具。这是一个巨大的预算和时间限制。
原因二:人力
除了专业工具外,结构化数据还需要数据科学家、IT 和 DevOps 人员。这可能由一个专业团队负责收集、清理和结构化数据,企业才能进入分析阶段。
关键区别:结构化数据与非结构化数据
网络抓取指南将教你,这两种数据类型的关键区别主要在于数据的包装方式以及谁能使用这些数据。以下是一些主要区别:
- 结构化数据集有一种格式,而非结构化数据有多种格式。
- 结构化数据通常保存在数据仓库中,而非结构化数据通常保存在数据湖中。
- 即使没有技术背景的人也可以使用结构化数据,而非结构化数据需要数据专家清理/处理后才能具有更广泛的实用性。
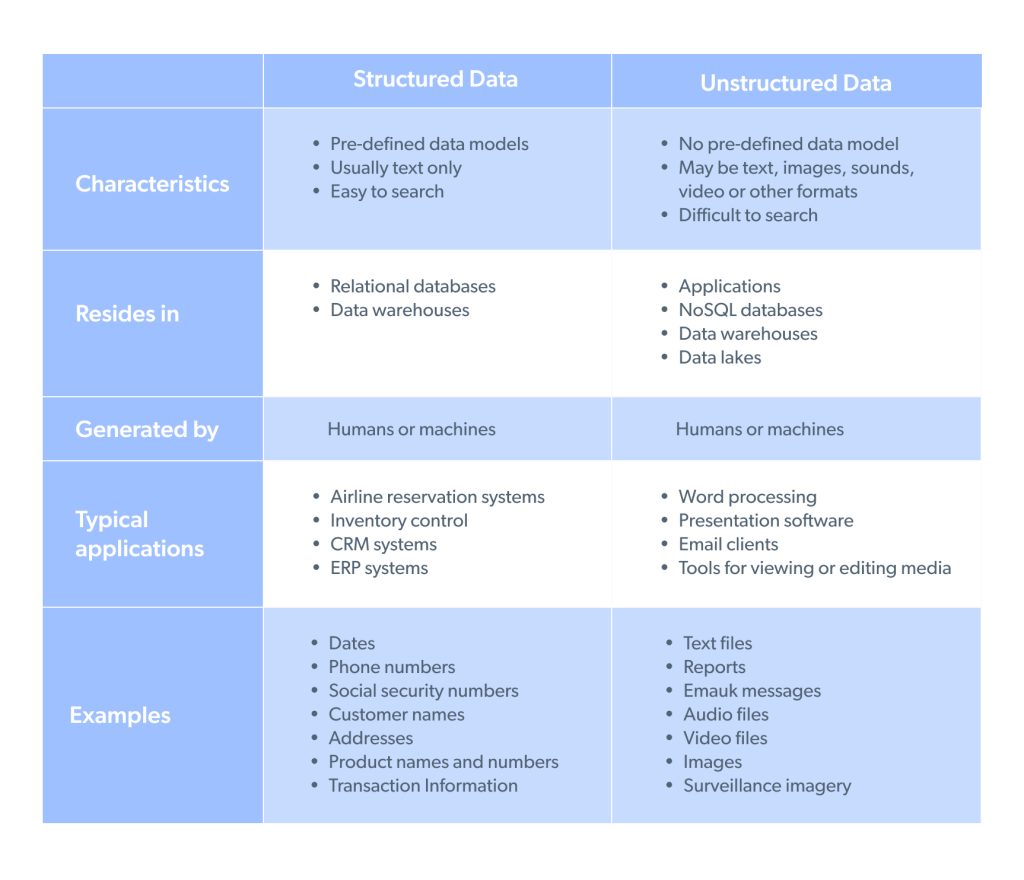
通过示例展示每种数据类型
非结构化数据示例
非结构化数据的一个好例子是从社交媒体网站、电子商务网站的评论/星级评分和在线论坛讨论中收集的开源网络数据。
它通常以 HTML 或纯文本形式出现,机器难以处理。这是因为算法或数据模型需要对信息进行分类才能进行分析。而要实现这一点,它们需要字段、标签或属性,而纯文本文件很少具备这些。
因此,数据科学家需要使用自然语言处理(NLP)等技术或手动标记元数据来进行进一步处理。
结构化数据示例
结构化数据更加“直截了当”,可以有多种形式。一些好例子包括:
- 地理位置数据
- 公司活动日期
- 企业名称
- 股票信息(交易量、证券价格变化等)
你可以看到,这些都是机器学习(ML)可以轻松分类的项目,特别是如果有逻辑的数字模式可供遵循。
什么是半结构化数据
半结构化数据是“结构化”和“非结构化”数据的混合体。例如,一个数据集中可能包含重复的数据点,另一方面,它可能包含某些元数据(例如,“文件最后修改日期”),这可以帮助系统对信息进行排序。
半结构化数据的示例可能包括:
- CSV、XML 和 JSON 文档
- NoSQL 数据库
- 电子数据交换(EDI)
例如,如果我们关注某个电子商务品牌的 XML 文档,它可能包含:
- 解释企业用例的纯文本
- 库存信息
- 交易数据
在这个例子中,纯文本部分将被视为“非结构化”,而库存数据和交易数据将被视为“结构化”部分。
如何收集结构化/非结构化数据
企业可以通过多种方式获取目标数据点,无论是瞄准结构化还是非结构化信息。拥有专门数据团队的企业可能会选择使用Selenium 和 Puppeteer。公司也可以选择购买抓取代理或简单地选择购买代理。
选择 Selenium/Puppeteer 路线的专业人士需要定义目标数据 和 URL,编写定制代码以执行数据提取,然后在数据能够正确分析之前对其进行格式化。
想要将数据收集和结构化的负担转移给第三方的公司可以选择以下两种方式之一:
选项一:自动数据收集
公司正在使用网络抓取 API以自动清理、匹配、合成、处理和结构化目标数据。
对于像网络抓取 API 这样的自动化工具,过程如下:
- 选择目标网站。
- 选择首选的收集频率和数据格式。
- 将数据传送到您选择的目的地(Webhook、电子邮件、Amazon S3、Google Cloud、Microsoft Azure、SFTP 或 API)。
选项二:现成的数据集
数据集正成为一种越来越受欢迎的工具。原因是企业不再希望参与数据收集过程。他们更希望成为“客户”——就像他们被提供电力一样,但对自己发电不感兴趣。数据集可以在几分钟内按最终用户需要的格式订购,根据需要提供。



