在使用Node.js进行网页抓取时,你可能会遇到如互联网审查和代理速度慢等障碍。幸运的是,有一个叫做node unblocker的解决方案可以帮助你。
Unblocker是一个网络代理,可以帮助开发者绕过互联网审查并访问地理限制内容。它是一个开源解决方案,具有快速数据中继、易于定制选项和支持多种协议的优点。通过unblocker,你可以克服互联网限制,从而高效地抓取那些本来无法访问的网站数据。
在本文中,你将了解unblocker的全部内容,包括它在网页抓取项目中的优势。你还将学习如何使用它创建一个可以用来抓取地理限制内容的代理。
使用Node Unblocker的优势
Node Unblocker提供了广泛的优势和功能,使其成为互联网用户寻求不受限制访问网页内容的宝贵工具。除了是一个开源解决方案外,它还有以下其他优点:
- 绕过互联网审查:unblocker的一个关键特性是它充当客户端和目标网站之间的中介。这一特性在网页抓取时特别有价值,能够让你从由于地理限制或审查而无法访问的网站上提取数据。
- 快速高效地中继数据:unblocker在不进行缓冲的情况下将数据传递给客户端。因此,它是可用的最快代理解决方案之一。
- 使用简单:unblocker提供了一个用户友好的界面,适合所有技能水平的用户。如果你想将该解决方案集成到你的项目中,unblocker提供了一个易于实现的API。
- 高度可定制:使用unblocker,开发者可以根据具体的抓取需求自定义代理。例如,你可以配置请求头和响应处理等参数,提供个性化和高效的抓取过程。
- 支持多种协议:unblocker支持多种协议,如HTTP、HTTPS和WebSockets。这种多功能性使得其可以无缝集成到不同的抓取场景中,为开发者提供了与各种数据源交互的灵活性和便利性。
如何开始使用Unblocker
现在你已经了解了unblocker提供的所有好处,是时候开始使用它了。在开始之前,你需要确保你的系统上已经安装了Node.js和npm。你还需要一个网络浏览器来测试项目,并需要一个免费的Render账号来托管解决方案。
完成这些先决条件后,就可以创建网络代理了。为此,创建一个名为node-unblocker-proxy的文件夹,在终端中打开它,并执行以下命令以初始化一个新的Node.js项目:
npm init -y然后执行以下命令安装所需的依赖项:
npm install express unblockerexpress是用于设置网络服务器的网络应用框架。node-unblocker是帮助你创建网络代理的npm包。
编写创建代理的脚本
设置所有依赖项后,是时候实现网络代理脚本了。
在项目根文件夹中创建一个index.js文件,并将以下代码粘贴到其中:
// import required dependencies
const express = require("express");
const Unblocker = require("unblocker");
// create an express app instance
const app = express();
// create a new Unblocker instance
const unblocker = new Unblocker({ prefix: "/proxy/" });
// set the port
const port = 3000;
// add the unblocker middleware to the Express application
app.use(unblocker);
// listen on specified port
app.listen(port).on("upgrade", unblocker.onUpgrade);
console.log(`proxy running on http://localhost:${port}/proxy/`);在这段代码中,你导入了所需的依赖项,并创建了一个Express应用实例。此外,你创建了一个新的Unblocker实例,允许进行广泛的配置选项。在这里,你只设置了prefix选项,指定了代理URL应以哪个路径开头。
因为unblocker导出了一个与Express兼容的API,将其集成到Express应用中非常简单。你只需调用Express应用实例的use()方法并传递Unblocker实例。然后使用listen()方法启动Express应用。.on("upgrade", unblocker.onUpgrade)确保WebSocket连接由unblocker正确处理。
本地测试代理
要在本地测试代理实现,在终端中执行以下命令:
node index.js如果你希望查看通过代理发出的每个请求的详细信息,也可以使用命令
DEBUG=unblocker:* node index.js。
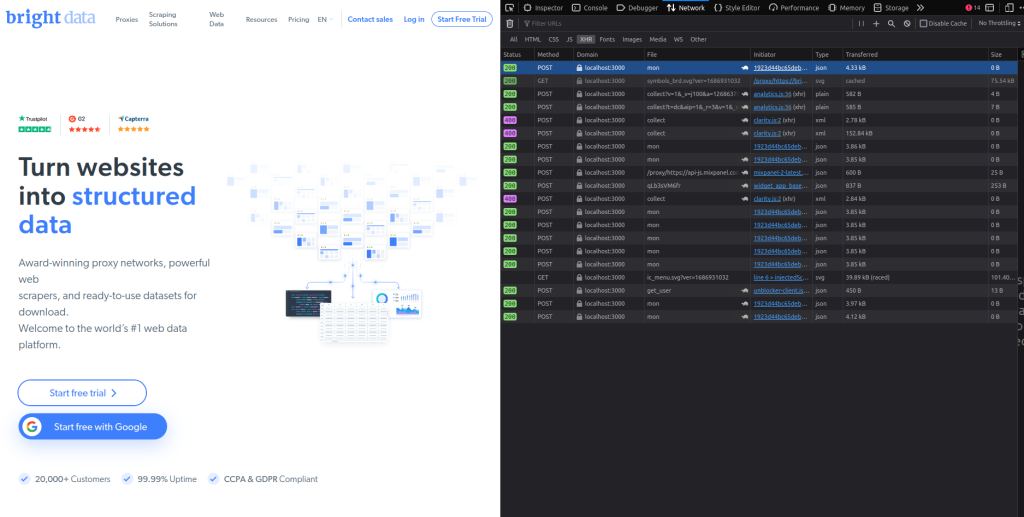
接下来,取任何URL并在其前面加上localhost/proxy/(例如localhost/proxy/https://brightdata.com/),然后在网络浏览器中打开它。
你应该会看到Bright Data主页。快速检查你的浏览器的网络标签,你会看到所有请求都通过代理(你可以通过查看域名列来看到这一点):
将代理部署到Render
现在你已经测试了代理,是时候部署它了。在此之前,请打开项目根文件夹中的package.json文件,并使用以下内容修改scripts键值对:
"scripts": {
"start": "node index"
}这样可以在将Express网络服务器托管到Render时提供启动命令。
要部署网络代理,首先上传代理代码到GitHub仓库。然后登录你的Render账号:
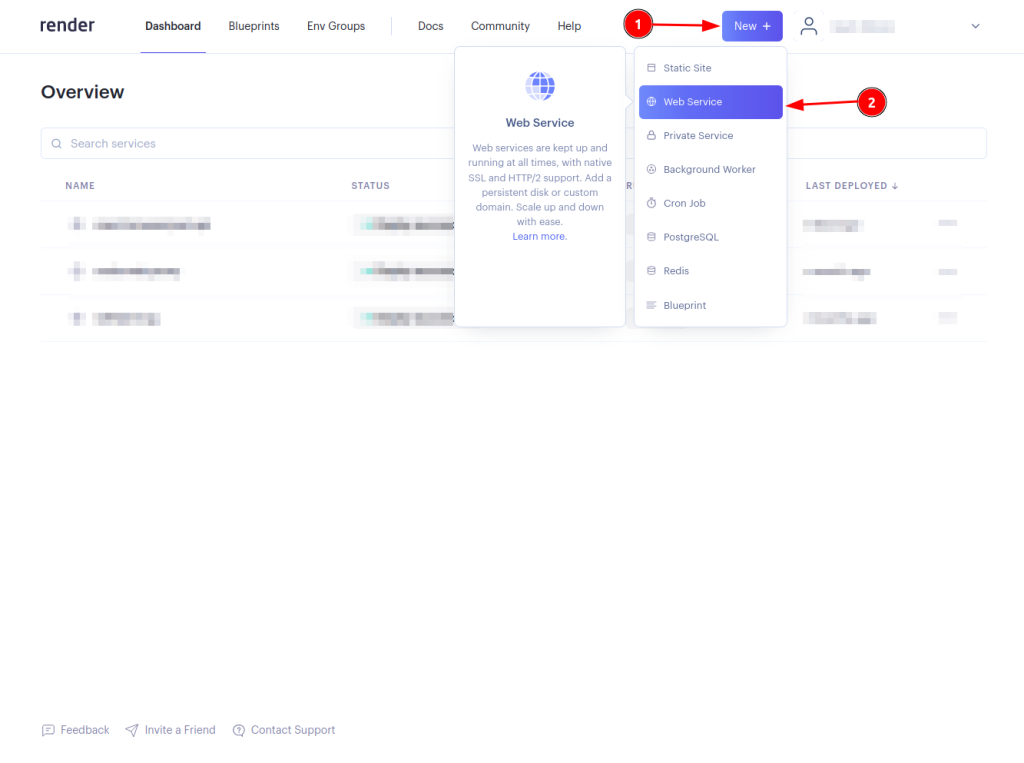
点击New +按钮并选择Web Service:
通过选择Connect按钮连接你的网络代理仓库。如果你尚未配置Render访问特定的GitHub仓库,可能需要配置你的账户以便Render可以访问仓库:
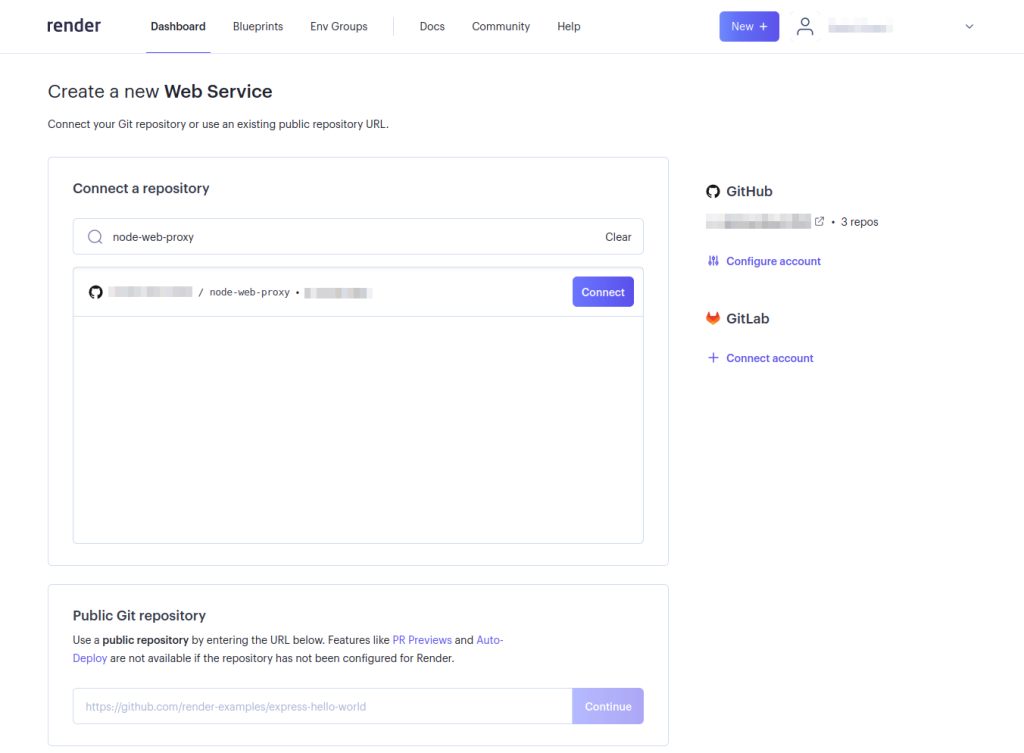
填写所需的网络服务详细信息,然后在页面底部选择Create Web Service:
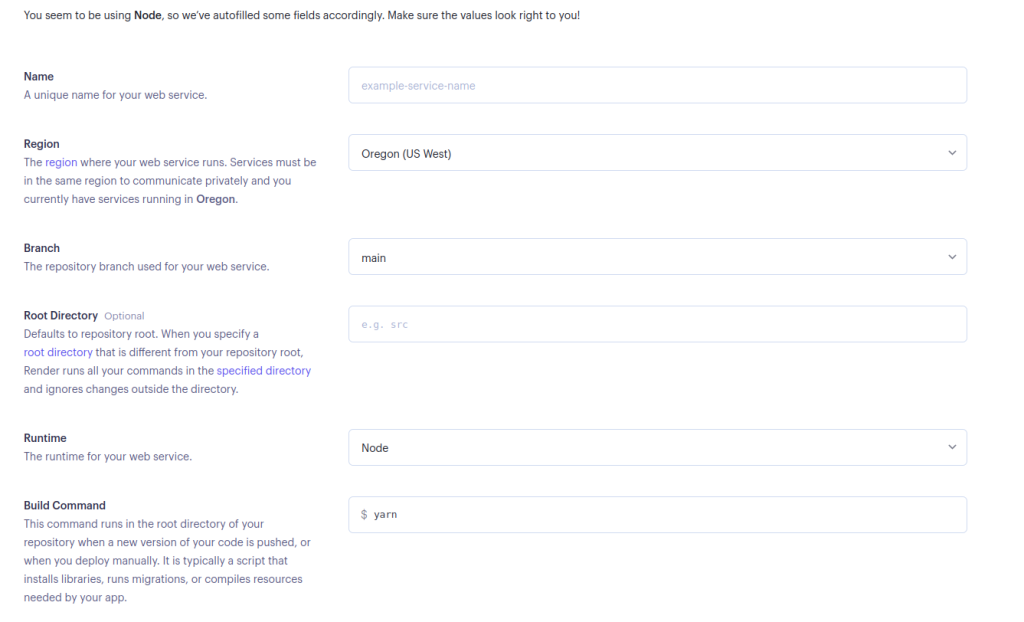
如果你更喜欢使用Yarn,可以将启动命令保持原样,或者如果你想使用npm,可以将其改为
npm run start。
在成功部署网络代理后,是时候测试它了。取任何URL并在其前面加上部署的<DEPLOYED-APP-URL>/proxy/(例如https://node-web-proxy-gvn6.onrender.com/proxy/https://brightdata.com/),然后在网络浏览器中打开它。
检查你的浏览器的网络标签,你应该会看到所有请求都通过已部署的代理:
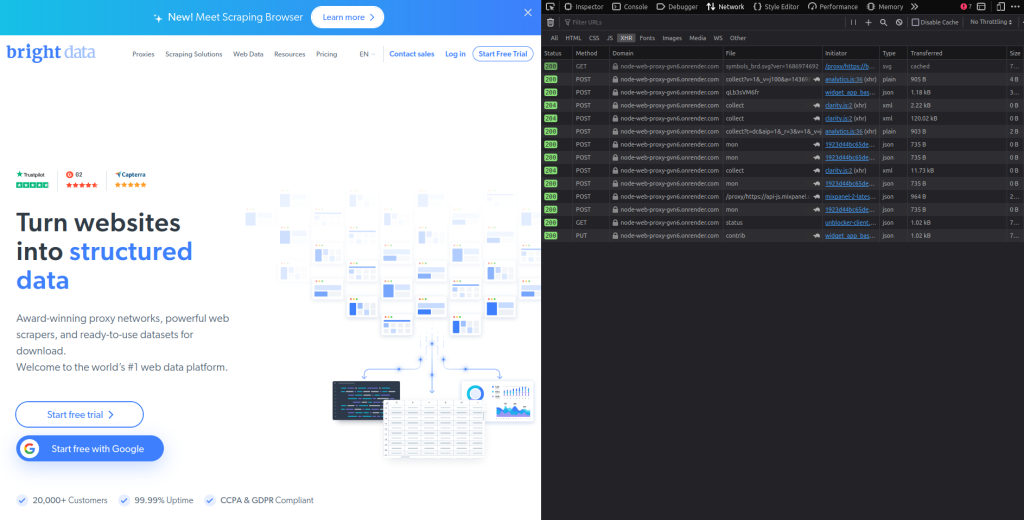
使用代理进行抓取请求
一旦你确认所有请求都通过已部署的代理,是时候进行抓取请求了。在本教程中,你将使用Puppeteer库,但任何其他测试库,如Cheerio或Nightmare,都可以使用。
如果你还没有安装Puppeteer,请立即运行npm i puppeteer进行安装。然后在项目根文件夹中创建一个scrape.js文件,并添加以下代码:
// import puppeteer
const puppeteer = require("puppeteer");
const scrapeData = async () => {
// launch the browser
const browser = await puppeteer.launch({
headless: false,
});
// open a new page and navigate to the defined URL
const page = await browser.newPage();
await page.goto("<DEPLOYED-APP-URL>/proxy/https://brightdata.com/blog");
// get the content of the webpage
const data = await page.evaluate(() => {
// variable to hold all the posts data
let blogData = [];
// extract all elements with the specified class
const posts = document.querySelectorAll(".post_item");
// loop through the posts object, extract required data and push it to the blogData array
for (const post of posts) {
const title = post.querySelector("h5").textContent;
const link = post.href;
const author = post
.querySelector(".author_box")
.querySelector(".author_box__details")
.querySelector("div").textContent;
const article = { title, link, author };
blogData.push(article);
}
return blogData;
});
// log the data to the console
console.log(data);
// close the browser instance
await browser.close();
};
// call the scrapeData function
scrapeData();请记得将
<DEPLOYED-APP-URL>替换为你在Render上部署的应用URL。
此代码片段设置了Puppeteer并从Bright Data博客中抓取博客文章数据。Bright Data网站上的所有博客文章卡片都有一个类名.post_item。它获取所有帖子,遍历posts对象,提取每个帖子的标题、链接和作者,将这些数据推入blogData数组,最后将所有信息记录到控制台。
如何选择最 适合你的Node Unblocker代理?
在将代理与Node Unblocker集成时,关键是要根据项目的需求和你预期的具体挑战来定制选择。以下是选择代理时需要考虑的几个关键方面:
- 性能和可靠性:选择一个以快速连接速度和高可用性著称的代理,以确保无缝的数据访问和网页抓取效率。
- 地理灵活性:选择提供广泛地理位置范围的代理。这一特性对于绕过区域限制和访问本地化内容至关重要。
- IP轮换:为了减少被网站封锁的风险,选择一个提供轮换IP地址的代理服务。此功能有助于通过在每次请求时呈现新的IP来保持访问。
- 安全协议:确保代理服务包括如SSL加密等强大的安全措施,以保护你的数据完整性和隐私,特别是如果你处理敏感信息时。
- 可扩展性:考虑代理服务是否可以扩展以满足日益增长的需求,因为你的抓取需求可能会增加。资源扩展的灵活性对于支持更大或更复杂的抓取任务至关重要。
- 支持和文档:全面的支持和详细的文档可以大大简化集成过程,特别是在使用Node Unblocker配置复杂的设置时。
通过仔细评估这些因素,你可以选择一个不仅适合你当前需求的代理服务,还能适应未来的增长和抓取活动的变化。
结论
Node Unblocker为在Node.js中进行网页抓取提供了一个强大的解决方案,使开发者能够绕过互联网审查并访问地理限制内容。它的用户友好界面、广泛的定制选项和多种协议支持,使其成为高效抓取网站数据的宝贵工具。在本指南中,你了解了unblocker、它在网页抓取项目中的优势以及如何使用它。
在当今以数据为驱动的世界中,网页抓取已成为收集有价值洞察和信息的不可或缺的工具。然而,网页抓取也面临许多挑战,如IP封锁、速率限制和地理限制,这些都可能阻碍数据收集工作并影响获取关键数据。
Bright Data提供了一个全面的平台来解决这些挑战。通过庞大的住宅、ISP、数据中心和移动IP网络,Bright Data允许用户通过世界各地的多种IP地址路由他们的抓取请求。这不仅确保了匿名性,还提供了访问地理限制内容的能力,并克服了可能阻碍数据收集工作的障碍。
不确定需要哪种Bright Data代理?立即注册并与我们的数据专家交谈,找到最适合你需求的解决方案。