

本教程将涵盖:
- 为什么抓取 Yelp?
- Yelp 抓取库和工具
- 使用 Beautiful Soup 抓取 Yelp 商家数据
为什么抓取 Yelp?
商业公司抓取 Yelp 有几个原因。这些原因包括:
- 获取全面的商业数据:它提供了关于本地商家的丰富信息,包括评论、评分、联系信息等。
- 了解客户反馈:它以用户评论闻名,提供了大量关于客户意见和体验的见解。
- 进行竞争分析和基准测试:它提供了有关竞争对手表现、优缺点和客户情感的宝贵见解。
虽然有类似的平台,但 Yelp 是数据抓取的首选,因为它具有:
- 广泛的用户基础
- 多样的商业类别
- 良好的声誉
从 Yelp 抓取的数据可用于市场研究、竞争对手分析、情感分析和决策。这些信息还有助于您识别改进的领域、优化您的产品,并保持竞争优势。
Yelp 抓取库和工具
Python 被广泛认为是网页抓取的优秀语言,因为它用户友好,语法简洁,并且拥有大量的库。因此,它是抓取 Yelp 的推荐编程语言。要了解更多,请查看我们的详细指南如何使用 Python 进行网页抓取。
下一步是从众多可用选项中选择合适的抓取库。为了做出明智的决定,您应该首先在网页浏览器中探索该平台。通过检查网页发出的 AJAX 请求,您会发现大多数数据嵌入在从服务器检索到的 HTML 文档中。
这意味着一个简单的 HTTP 客户端加上一个 HTML 解析器就足够完成任务。以下是您应该选择的原因:
- Requests:Python 最流行的 HTTP 客户端库。它简化了发送 HTTP 请求和处理相应响应的过程。
- Beautiful Soup:一个综合的 HTML 和 XML 解析库,广泛用于网页抓取。它提供了强大的方法来浏览和提取 DOM 数据。
感谢 Requests 和 Beautiful Soup,您可以使用 Python 有效地抓取 Yelp。让我们详细了解如何完成这个任务!
使用 Beautiful Soup 抓取 Yelp 商家数据
按照本分步教程,学习如何构建一个 Yelp 抓取器。
步骤 1:Python 项目设置
在开始之前,您需要确保您已经:
- 在您的电脑上安装了 Python 3+:下载安装程序,执行并按照指示操作。
- 选择了一个 Python IDE:带有Python 扩展的 Visual Studio Code 或PyCharm Community Edition都可以。
首先,创建一个 yelp-scraper 文件夹并用虚拟环境初始化它:
mkdir yelp-scraper
cd yelp-scraper
python -m venv env在 Windows 上,运行以下命令来激活环境:
envScriptsactivate.ps1
While on Linux or macOS:
env/bin/activate接下来,在项目文件夹中添加一个 scraper.py 文件,并在其中包含以下行:
print('Hello, World!')这是最简单的 Python 脚本。目前,它只打印“Hello, World!”但很快它将包含抓取 Yelp 的逻辑。
您可以通过以下命令启动抓取器:
python scraper.py它应该在终端中打印:
Hello, World!正如预期的那样。现在,您知道一切正常,请在您的 Python IDE 中打开项目文件夹。
很好,准备写一些 Python 代码吧!
步骤 2:安装抓取库
现在,您需要将执行网页抓取所需的库添加到项目的依赖项中。在激活的虚拟环境中,运行以下命令来安装Beautiful Soup和Requests:
pip install beautifulsoup4 requests清空 scraper.py 文件,然后添加以下行来导入这些包:
import requests
from bs4 import BeautifulSoup
# scraping logic...确保您的 Python IDE 没有报告任何错误。您可能会收到一些未使用导入的警告,但可以忽略它们。您即将使用这些抓取库从 Yelp 提取数据。
步骤 3:识别和下载目标页面
浏览 Yelp 并识别您想要抓取的页面。在本指南中,您将学习如何从纽约评价最高的意大利餐厅列表中检索数据:
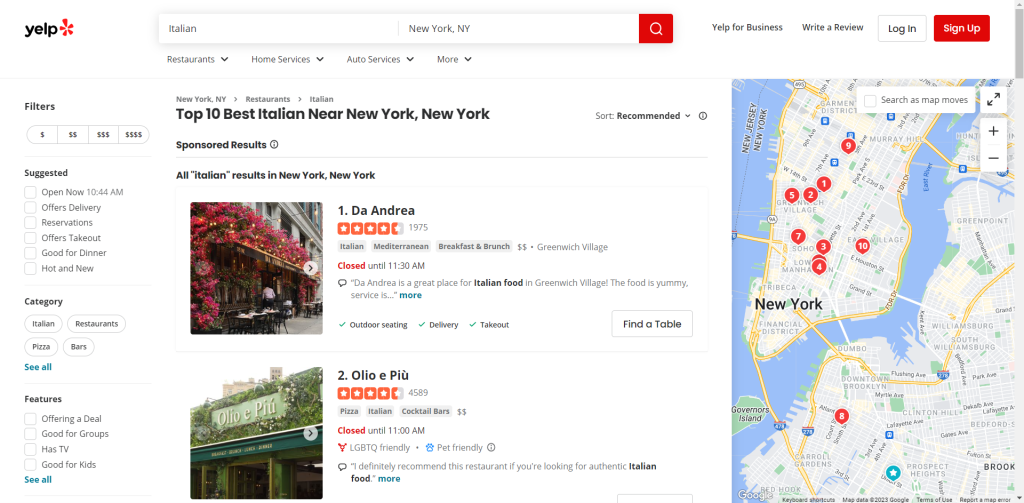
将目标页面的 URL 分配给一个变量:
url = 'https://www.yelp.com/search?find_desc=Italian&find_loc=New+York%2C+NY'
Next, use requests.get() to make an HTTP GET request to that URL:
page = requests.get(url)变量 page 现在将包含服务器生成的响应。
具体来说,page.text 存储了与目标网页关联的 HTML 文档。您可以通过记录它来验证:
print(page.text)这应该打印:
<!DOCTYPE html><html lang="en-US" prefix="og: http://ogp.me/ns#" style="margin: 0;padding: 0; border: 0; font-size: 100%; font: inherit; vertical-align: baseline;"><head><script>document.documentElement.className=document.documentElement.className.replace(no-j/,"js");</script><meta http-equiv="Content-Type" content="text/html; charset=UTF-8" /><meta http-equiv="Content-Language" content="en-US" /><meta name="viewport" content="width=device-width, initial-scale=1, shrink-to-fit=no"><link rel="mask-icon" sizes="any" href="https://s3-media0.fl.yelpcdn.com/assets/srv0/yelp_large_assets/b2bb2fb0ec9c/assets/img/logos/yelp_burst.svg" content="#FF1A1A"><link rel="shortcut icon" href="https://s3-media0.fl.yelpcdn.com/assets/srv0/yelp_large_assets/dcfe403147fc/assets/img/logos/favicon.ico"><script> window.ga=window.ga||function(){(ga.q=ga.q||[]).push(arguments)};ga.l=+new Date;window.ygaPageStartTime=new Date().getTime();</script><script>
<!-- Omitted for brevity... -->完美!让我们学习如何解析它以从中检索数据。
步骤 4:解析 HTML 内容
将从服务器检索到的 HTML 内容传递给BeautifulSoup()构造函数进行解析:
soup = BeautifulSoup(page.text, 'html.parser')该函数需要两个参数:
- 包含 HTML 的字符串。
- Beautiful Soup 将用来解析内容的解析器。
“html.parser”是 Python 内置 HTML 解析器的名称。
BeautifulSoup() 将返回一个可浏览的树结构中的解析内容。特别是,soup 变量提供了用于从 DOM 树中选择元素的有用方法。最流行的是:
- find():返回与传入选择策略匹配的第一个 HTML 元素。
- find_all():返回与输入选择策略匹配的 HTML 元素列表。
- select_one():返回与传入的 CSS 选择器匹配的第一个 HTML 元素。
- select():返回与输入 CSS 选择器匹配的 HTML 元素列表。
太棒了!您很快就会使用它们来提取所需的 Yelp 数据。
步骤 5:熟悉页面
为了制定有效的选择策略,您必须首先熟悉目标网页的结构。在浏览器中打开它并开始探索。
右键单击页面上的 HTML 元素,然后选择“检查”以打开开发工具:

您会立即注意到,该站点依赖于在构建时随机生成的 CSS 类。由于它们可能会在每次部署时更改,因此您不应该基于它们构建 CSS 选择器。这是构建有效抓取器时需要了解的关键信息。
如果深入研究 DOM,您还会看到最重要的元素具有独特的 HTML 属性。因此,您的选择策略应依赖于它们。
继续在开发工具 中检查页面,直到您准备好使用 Python 抓取它!
步骤 6:提取商家数据
目标是从页面上的每张卡片中提取商业信息。为了跟踪这些数据,您需要一个数据结构来存储它:
items = []首先,检查一个卡片的 HTML 元素:

请注意,您可以使用以下命令选择所有这些元素:
html_item_cards = soup.select('[data-testid="serp-ia-card"]')遍历它们,并准备好您的脚本以:
- 从每个元素中提取数据。
- 将其保存在一个 Python 字典 item 中。
- 将其添加到items。
for html_item_card in html_item_cards:
item = {}
# scraping logic...
items.append(item)现在来实现抓取逻辑!
检查图像元素:
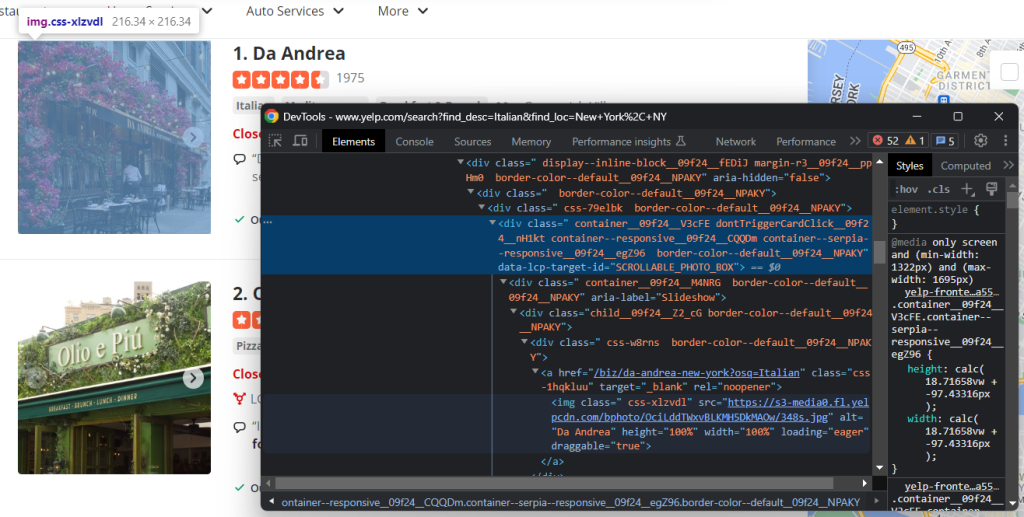
使用以下命令检索商家图像的 URL:
image = html_item_card.select_one('[data-lcp-target-id="SCROLLABLE_PHOTO_BOX"] img').attrs['src']从 select_one() 检索到元素后,可以通过 attrs 成员访问其 HTML 属性。
另一个有用的信息是标题和指向商家详细信息页面的 URL:
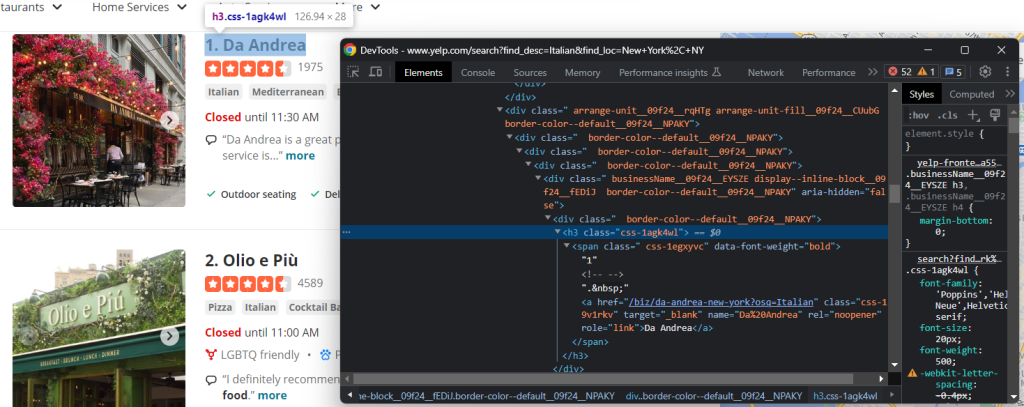
如您所见,您可以从 h3 a 节点中获取这两个数据字段:
name = html_item_card.select_one('h3 a').text
url = 'https://www.yelp.com' + html_item_card.select_one('h3 a').attrs['href']text 属性返回当前元素及其所有子元素内的文本内容。由于某些链接是相对的,您可能需要添加基本 URL 来补全它们。
Yelp 上最重要的数据之一是用户评论评分:
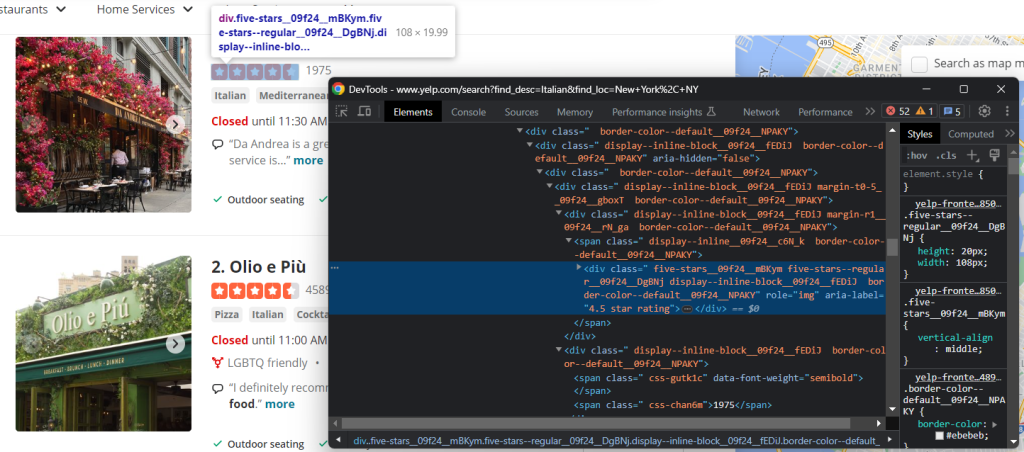
在这种情况下,没有简单的方法来获取它,但您仍然可以通过以下方式实现目标:
html_stars_element = html_item_card.select_one('[class^="five-stars"]')
stars = html_stars_element.attrs['aria-label'].replace(' star rating', '')
reviews = html_stars_element.parent.parent.next_sibling.text请注意使用replace() Python 函数清理字符串,只获取相关数据。
还要检查标签和价格范围元素:
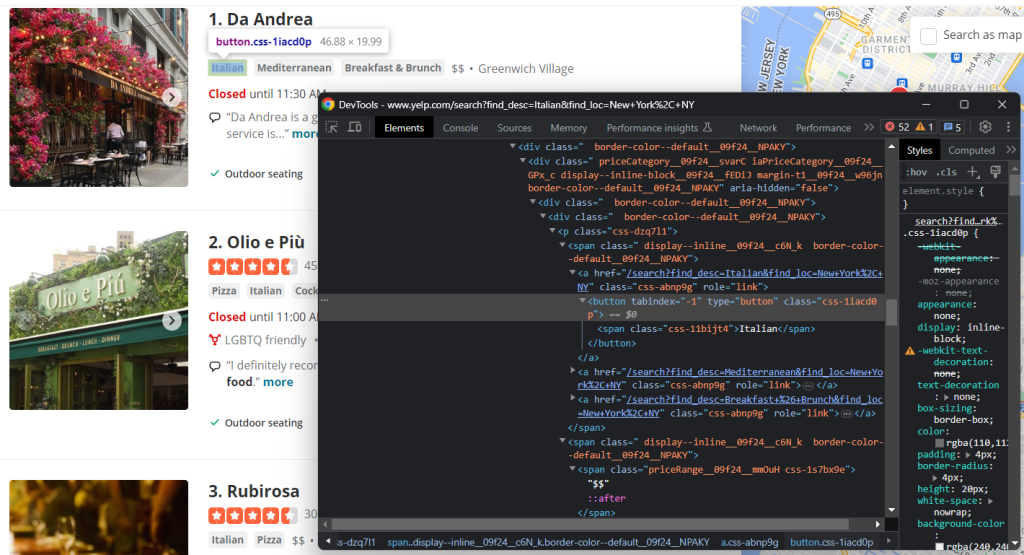
要收集所有标签字符串,您需要选择它们并遍历它们:
tags = []
html_tag_elements = html_item_card.select('[class^="priceCategory"] button')
for html_tag_element in html_tag_elements:
tag = html_tag_element.text
tags.append(tag)相反,检索可选的价格范围指示要容易得多:
price_range_html = html_item_card.select_one('[class^="priceRange"]')
# since the price range info is optional
if price_range_html is not None:
price_range = price_range_html.text最后,您还应该抓取餐厅提供的服务:

再次,您需要遍历每个节点:
services = []
html_service_elements = html_item_card.select('[data-testid="services-actions-component"] p[class^="tagText"]')
for html_service_element in html_service_elements:
service = html_service_element.text
services.append(service)做得好!您刚刚实现了抓取逻辑。
将抓取到的数据变量添加到字典中:
item['name'] = name
item['image'] = image
item['url'] = url
item['stars'] = stars
item['reviews'] = reviews
item['tags'] = tags
item['price_range'] = price_range
item['services'] = services使用 print(item) 确保数据提取过程按预期工作。在第一个卡片上,您将得到:
{'name': 'Olio e Più', 'image': 'https://s3-media0.fl.yelpcdn.com/bphoto/CUpPgz_Q4QBHxxxxDJJTTA/348s.jpg', 'url': 'https://www.yelp.com/biz/olio-e-pi%C3%B9-new-york-7?osq=Italian', 'stars': '4.5', 'reviews': '4588', 'tags': ['Pizza', 'Italian', 'Cocktail Bars'], 'price_range': '$$', 'services': ['Outdoor seating', 'Delivery', 'Takeout']}太棒了!您离目标更近了!
步骤 7:实现爬取逻辑
不要忘记,商家是以分页列表呈现给用户的。您刚刚看到了如何抓取单个页面,但如果您想获取所有数据怎么办?为此,您需要将网页爬取集成到 Yelp 数据抓取器中。
首先,在脚本顶部定义一些支持数据结构:
visited_pages = []
pages_to_scrape = ['https://www.yelp.com/search?find_desc=Italian&find_loc=New+York%2C+NY']visited_pages 将包含抓取过的页面 URL,而 pages_to_scrape 则包含要访问的下一个页面。创建一个 while 循环,当没有更多页面可抓取或达到特定迭代次数时终止:
visited_pages will contain the URLs of the pages scraped, while pages_to_scrape the next ones to visit.
Create a while loop that terminates when there are no longer pages to scrape or after a specific number of iterations:
limit = 5 # in production, you can remove it
i = 0
while len(pages_to_scrape) != 0 and i < limit:
# extract the first page from the array
url = pages_to_scrape.pop(0)
# mark it as "visited"
visited_pages.append(url)
# download and parse the page
page = requests.get(url)
soup = BeautifulSoup(page.text, 'html.parser')
# scraping logic...
# crawling logic...
# increment the page counter
i += 1每次迭代将处理从列表中删除一个页面、抓取它、发现新页面并将它们添加到队列中。limit 只是防止抓取器无限运行。
剩下的就是实现爬取逻辑。检查 HTML 分页元素:
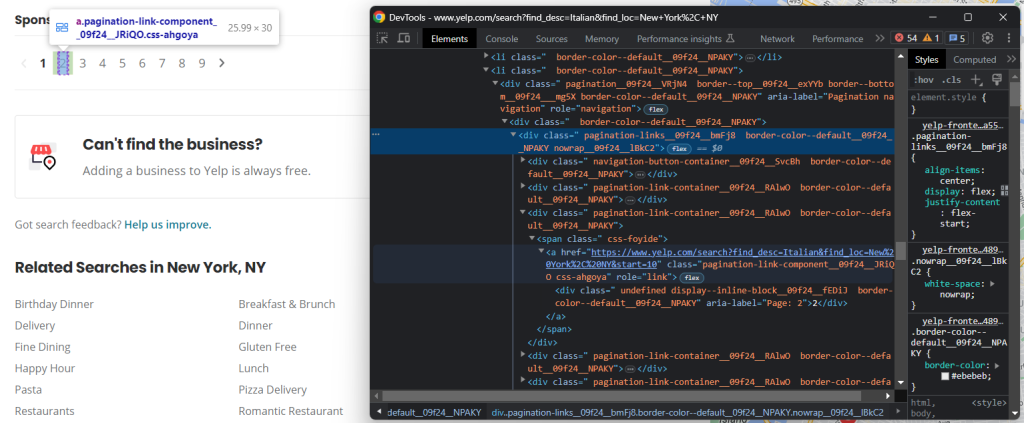
这包括几个链接。收集它们并将新发现的链接添加到 pages_to_visit 中:
pagination_link_elements = soup.select('[class^="pagination-links"] a')
for pagination_link_element in pagination_link_elements:
pagination_url = pagination_link_element.attrs['href']
# if the discovered URL is new
if pagination_url not in visited_pages and pagination_url not in pages_to_scrape:
pages_to_scrape.append(pagination_url)太好了!现在您的抓取器将自动遍历所有分页页面。
步骤 8:将抓取数据导出为 CSV
最后一步是使收集到的数据更易于共享和阅读。最好的方法是将其导出为人类可读的格式,例如 CSV:
import csv
# ...
# initialize the .csv output file
with open('restaurants.csv', 'w', newline='', encoding='utf-8') as csv_file:
writer = csv.DictWriter(csv_file, fieldnames=headers, quoting=csv.QUOTE_ALL)
writer.writeheader()
# populate the CSV file
for item in items:
# transform array fields from "['element1', 'element2', ...]"
# to "element1; element2; ..."
csv_item = {}
for key, value in item.items():
if isinstance(value, list):
csv_item[key] = '; '.join(str(e) for e in value)
else:
csv_item[key] = value
# add a new record
writer.writerow(csv_item)使用open()创建一个 restaurants.csv 文件。然后,使用DictWriter和一些自定义逻辑来填充它。由于 csv 包来自 Python 标准库,不需要安装额外的依赖项。
太好了!您从网页中的原始数据开始,现在拥有半结构化的 CSV 数据。是时候查看整个 Yelp Python 抓取器了。
步骤 9:将所有内容放在一起
以下是完整的 scraper.py 脚本:
import requests
from bs4 import BeautifulSoup
import csv
# support data structures to implement the
# crawling logic
visited_pages = []
pages_to_scrape = ['https://www.yelp.com/search?find_desc=Italian&find_loc=New+York%2C+NY']
# to store the scraped data
items = []
# to avoid overwhelming Yelp's servers with requests
limit = 5
i = 0
# until all pagination pages have been visited
# or the page limit is hit
while len(pages_to_scrape) != 0 and i < limit:
# extract the first page from the array
url = pages_to_scrape.pop(0)
# mark it as "visited"
visited_pages.append(url)
# download and parse the page
page = requests.get(url)
soup = BeautifulSoup(page.text, 'html.parser')
# select all item card
html_item_cards = soup.select('[data-testid="serp-ia-card"]')
for html_item_card in html_item_cards:
# scraping logic
item = {}
image = html_item_card.select_one('[data-lcp-target-id="SCROLLABLE_PHOTO_BOX"] img').attrs['src']
name = html_item_card.select_one('h3 a').text
url = 'https://www.yelp.com' + html_item_card.select_one('h3 a').attrs['href']
html_stars_element = html_item_card.select_one('[class^="five-stars"]')
stars = html_stars_element.attrs['aria-label'].replace(' star rating', '')
reviews = html_stars_element.parent.parent.next_sibling.text
tags = []
html_tag_elements = html_item_card.select('[class^="priceCategory"] button')
for html_tag_element in html_tag_elements:
tag = html_tag_element.text
tags.append(tag)
price_range_html = html_item_card.select_one('[class^="priceRange"]')
# this HTML element is optional
if price_range_html is not None:
price_range = price_range_html.text
services = []
html_service_elements = html_item_card.select('[data-testid="services-actions-component"] p[class^="tagText"]')
for html_service_element in html_service_elements:
service = html_service_element.text
services.append(service)
# add the scraped data to the object
# and then the object to the array
item['name'] = name
item['image'] = image
item['url'] = url
item['stars'] = stars
item['reviews'] = reviews
item['tags'] = tags
item['price_range'] = price_range
item['services'] = services
items.append(item)
# discover new pagination pages and add them to the queue
pagination_link_elements = soup.select('[class^="pagination-links"] a')
for pagination_link_element in pagination_link_elements:
pagination_url = pagination_link_element.attrs['href']
# if the discovered URL is new
if pagination_url not in visited_pages and pagination_url not in pages_to_scrape:
pages_to_scrape.append(pagination_url)
# increment the page counter
i += 1
# extract the keys from the first object in the array
# to use them as headers of the CSV
headers = items[0].keys()
# initialize the .csv output file
with open('restaurants.csv', 'w', newline='', encoding='utf-8') as csv_file:
writer = csv.DictWriter(csv_file, fieldnames=headers, quoting=csv.QUOTE_ALL)
writer.writeheader()
# populate the CSV file
for item in items:# transform array fields from "['element1', 'element2', ...]"
# to "element1; element2; ..."
csv_item = {}
for key, value in item.items():
if isinstance(value, list):
csv_item[key] = '; '.join(str(e) for e in value)
else:
csv_item[key] = value
# add a new record
writer.writerow(csv_item)在大约 100 行代码中,您可以构建一个网页蜘蛛来从 Yelp 提取商家数据。
使用以下命令运行抓取器:
python scraper.py等待执行完成,您将在项目的根文件夹中找到 restaurants.csv 文件:

恭喜!您刚刚学会了如何用 Python 抓取 Yelp 数据!
总结
在本分步指南中,您了解了为什么 Yelp 是获取本地商家用户数据的最佳抓取目标之一。详细来说,您学习了如何构建一个可以检索 Yelp 数据的 Python 抓取器。正如这里所示,这只需要几行代码。
同时,网站不断发展并调整其用户界面和结构以适应用户不断变化的期望。这里构建的抓取器今天可以工作,但明天可能不再有效。避免在维护上花费时间和金钱,试试我们的Yelp 抓取器吧!
此外,请记住,大多数网站严重依赖 JavaScript。在这些情况下,基于 HTML 解析器的传统方法将不起作用。相反,您将需要一个可以渲染 JavaScript 并处理指纹、验证码和自动重试的工具。这正是我们的新抓取浏览器解决方案的全部内容!
不想处理 Yelp 网页抓取,只想要数据?购买 Yelp 数据集



技术写作
 5.5 years experience
5.5 years experience
Antonello是一名软件工程师,但他更喜欢称自己为技术传教士。通过写作传播知识是他的使命。




