

本教程将涵盖:
为什么要抓取 GitHub 存储库?
抓取 GitHub 存储库有几个原因。其中最常见的原因包括:
- 关注技术趋势:通过追踪存储库的星星数和发行版本,您可以了解编程语言、框架和库的当前趋势。抓取 GitHub 帮助您分析哪些技术越来越受欢迎,以监测其增长并发现新兴趋势。这些数据可用于指导技术采用、技能发展和资源分配等方面的决策。
- 访问丰富的编程知识库:GitHub 是开源项目、代码示例和解决方案的宝库。这意味着您可以从该平台收集海量的编程知识和最佳实践。这对于教育、提高编程技能和理解不同技术的实现方式很有用。
- 深入了解协作开发:存储库有助于了解开发者如何通过拉取请求、问题和讨论相互协作。通过收集这些数据,您可以研究协作模式,以便设计团队合作策略,改善项目管理,完善软件开发流程。
GitHub 并非唯一一个用于托管 git 存储库的云平台,还有许多替代方案。但是,出于以下原因,GitHub 目前仍然是数据抓取的首选目标:
- 用户群庞大
- 用户高度活跃
- 已建立良好声誉
特别是,GitHub 数据对于监测技术趋势、寻找库和框架以及改善软件开发流程都非常有价值。这些信息对于在 IT 领域竞争中保持领先地位起到关键作用。
GitHub 抓取库和工具
Python 因语法简单、便于开发者操作、库种类广泛而成为网络抓取方面公认的理想语言。因此它成为 GitHub 抓取的推荐编程语言。参阅我们的如何使用 Python 实施网页抓取的详细指南,了解更多信息。
下一步是从众多可用选项中选择最合适的抓取库。要做出明智的决定,您首先应在浏览器中浏览该平台。打开 DevTools,查看 GitHub 上存储库页面发起的 AJAX 调用。您会注意到其中大多数可以忽略。实际上,大部分页面数据都嵌入在服务器返回的 HTML 文档中。
这意味着将向服务器发出 HTTP 请求的库与 HTML 解析器相结合就足以完成任务。所以,您应该选择:
- Requests:Python 生态系统中最受欢迎的 HTTP 客户端库。此库简化了发送 HTTP 请求和处理相应响应的过程。
- Beautiful Soup:全面的 HTML 和 XML 解析库。它为网页抓取提供了强大的 DOM 导航和数据提取 API。
得益于 Requests 和 Beautiful Soup,您可以使用 Python 有效地执行 GitHub 抓取。让我们详细了解如何实现这一目标!
使用 Beautiful Soup 构建 GitHub 存储库抓取工具
按照本分步教程操作,学习如何在 Python 中抓取 GitHub。想跳过整个编码和抓取过程吗?直接购买 GitHub 数据集即可。
第 1 步:Python 项目设置
开始之前,请确保满足以下先决条件:
- 您的计算机安装了 Python 3+:下载并执行安装程序,然后按照说明操作。
- 您选择的 Python IDE:这里推荐带有 Python 扩展的 Visual Studio Code 和 PyCharm 社区版这两个 IDE。
您现在拥有了在 Python 中设置项目所需的一切!
在终端中启动以下命令以创建 github-scraper 文件夹,并使用 Python 虚拟环境将其初始化:
mkdir github-scraper
cd github-scraper
python -m venv env在 Windows 上,运行以下命令来激活环境:
envScriptsactivate.ps1而在 Linux 或 macOS 上,执行:
./env/bin/activate然后,在项目文件夹中添加一个包含以下代码行的 scraper.py 文件:
print('Hello, World!')现在,您的 GitHub 抓取工具只会打印“你好,世界!”,但它很快就会包含从公共存储库提取数据的逻辑。
您可以通过以下命令启动脚本:
python scraper.py如果一切按计划进行,它应该会在终端中打印以下消息:
Hello, World!现在您知道它能正常使用,就可以在您首选的 Python IDE 中打开项目文件夹。
很好!准备好编写一些 Python 代码吧。
第 2 步:安装抓取库
如前文所述,Beautiful Soup 和 Requests 可以帮助您在 GitHub 上执行网页抓取。在激活的虚拟环境中,执行以下命令将它们添加到项目的依赖项中:
pip install beautifulsoup4 requests清除 scraper.py,然后通过以下几行代码导入这两个包:
import requestsfrom bs4 import BeautifulSoup
# scraping logic...确保您的 Python IDE 没有报告任何错误。您可能会因为未使用的导入内容而收到一些警告。忽略警告,因为您即将使用这些抓取库从 GitHub 提取存储库数据!
第 3 步:下载目标页面
选择要从中检索数据的 GitHub 存储库。在本指南中,您将看到如何抓取 luminati-proxy 存储库。请记住,使用任何其他存储库都可以,因为抓取逻辑都是相同的。
以下是浏览器中目标页面的样子:
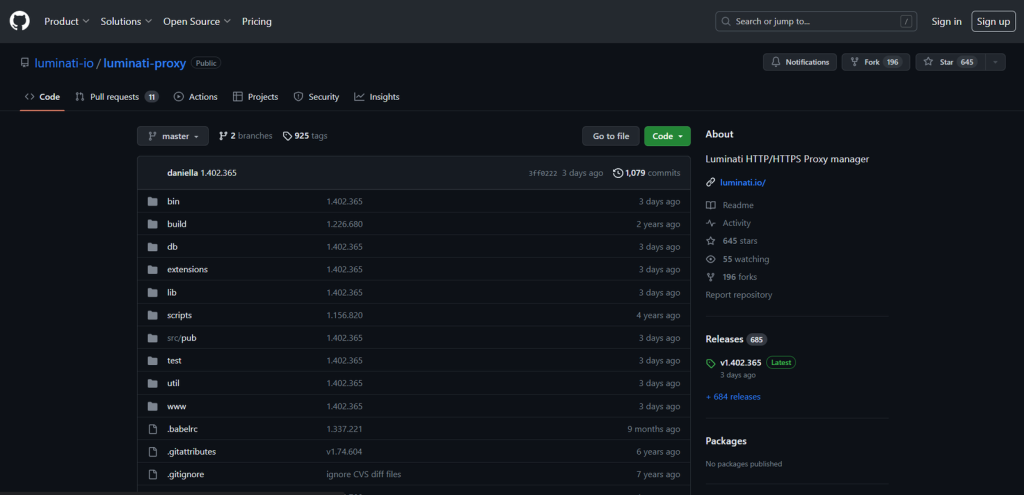
将目标页面的 URL 存储在变量中:
url = 'https://github.com/luminati-io/luminati-proxy'然后,通过 requests.get() 下载此页面:
page = requests.get(url)在后台,requests 向此 URL 发出 HTTP GET 请求,并将服务器生成的响应保存在 page 变量中。您应该重点关注其文本属性。这其中包含与目标网页关联的 HTML 文档。使用简单的 print 指令执行验证:
print(page.text)运行抓取工具,您将在终端中看到:
<!DOCTYPE html>
<html lang="en" data-color-mode="dark" data-light-theme="light" data-dark-theme="dark" data-a11y-animated-images="system" data-a11y-link-underlines="false">
<head>
<meta charset="utf-8">
<link rel="dns-prefetch" href="https://github.githubassets.com">
<link rel="dns-prefetch" href="https://avatars.githubusercontent.com">
<link rel="dns-prefetch" href="https://github-cloud.s3.amazonaws.com">
<link rel="dns-prefetch" href="https://user-images.githubusercontent.com/">
<link rel="preconnect" href="https://github.githubassets.com" crossorigin>
<link rel="preconnect" href="https://avatars.githubusercontent.com">
<!-- Omitted for brevity... -->
Awesome! Let’s now learn how to parse this第 4 步:解析 HTML 文档
要解析前文检索到的 HTML 文档,请将其发送到 Beautiful Soup:
soup = BeautifulSoup(page.text, 'html.parser')BeautifulSoup() 构造函数接受两个参数:
- 包含 HTML 内容的字符串:在此存储在
page.text变量中。 - Beautiful Soup 将使用的解析器:“
html.parser” 是 Python 内置 HTML 解析器的名称。
BeautifulSoup() 将解析 HTML 并返回一个可探索的树结构。详细而言,soup 变量提供了从 DOM 树中选择元素的有效方法,例如:
find():返回与作为参数传递的选择器策略相匹配的首个 HTML 元素。find_all():返回与输入的选择器策略相匹配的 HTML 元素列表。select_one():返回与作为参数传递的 CSS 选择器相匹配的首个 HTML 元素。select():返回与输入的 CSS 选择器相匹配的 HTML 元素列表。
请注意,这些方法也可以在树中的单一节点上调用。除此之外,Beautiful Soup 节点对象还提供了:
find_next_sibling():返回此元素的同级元素中与给定 CSS 选择器相匹配的首个 HTML 节点。find_next_siblings():返回此元素的同级元素中与作为参数传递的 CSS 选择器相匹配的所有 HTML 节点。
得益于这些函数,您已经准备好抓取 GitHub 了。一起看看怎么做吧!
第 5 步:熟悉目标页面
开始编码之前,还有一个关键步骤需要完成。从网站抓取数据就是选择相关的 HTML 元素并从中提取数据。定义有效的选择策略并不总是那么容易,您必须花一些时间分析目标网页的结构。
因此,在浏览器中打开 GitHub 目标页面并熟悉一下。右键单击选中“检查”以打开 DevTools:
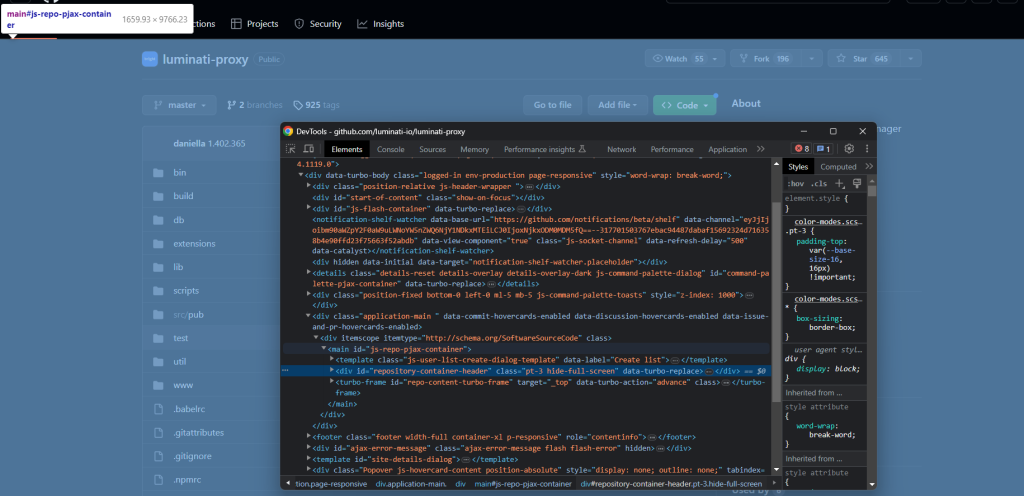
深入研究 HTML 代码,您会发现此网站没有为其中的许多元素指定独特的类或属性。因此,通常难以导航到所需的元素,您可能需要浏览一遍所有同级元素,操作比较棘手。
不过不必担心。虽然为 GitHub 设计有效的选择器策略可能并不容易,但也并非不可能。继续在 DevTools 中检查该页面,直到准备好抓取它!
第 6 步:提取存储库数据
这个步骤的目标是从 GitHub 存储库中提取有用的数据,例如星星数、描述、最近一次提交情况等等。因此,您需要初始化 Python 字典来追踪这些数据。添加到您的代码中:
repo = {}首先,检查名称元素:
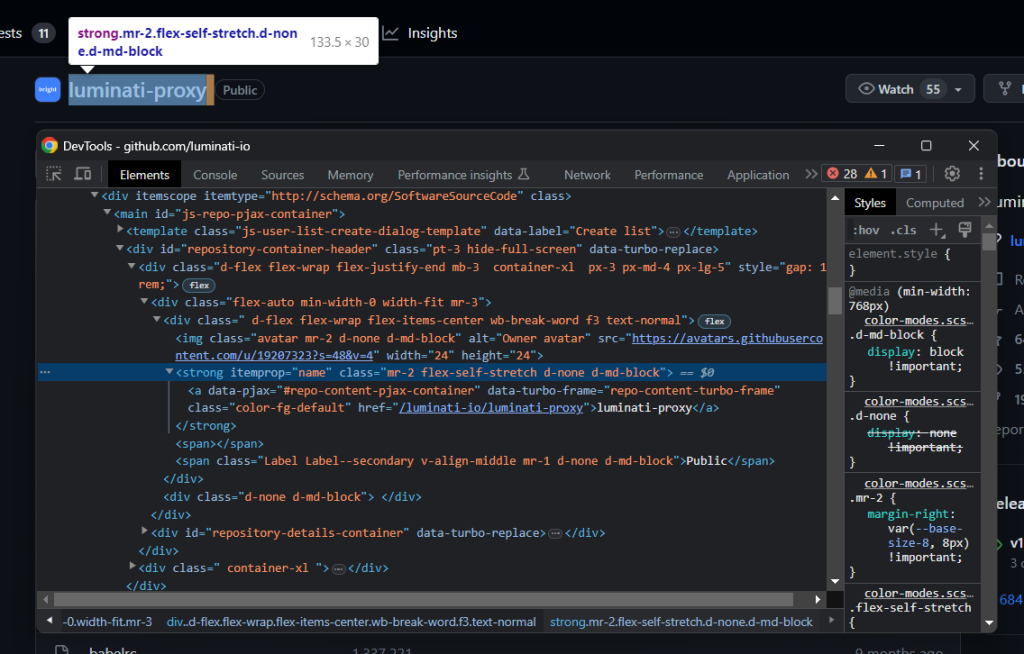
请注意,它有一个独特的 itemprop=“name” 属性。选中它,并使用以下命令提取其文本内容:
name_html_element = soup.select_one('[itemprop="name"]')name = name_html_element.text.strip()在给定一个 Beautiful Soup 节点的情况下,使用 get_text() 方法访问其文本内容。
如果您在调试器中检查 name_html_element.text,您将看到:
nluminati-proxynGitHub 文本字段往往包含空格和换行符。使用 strip() Python 函数删除空格和换行符。
在存储库名称的正下方,有一个分支选择器:
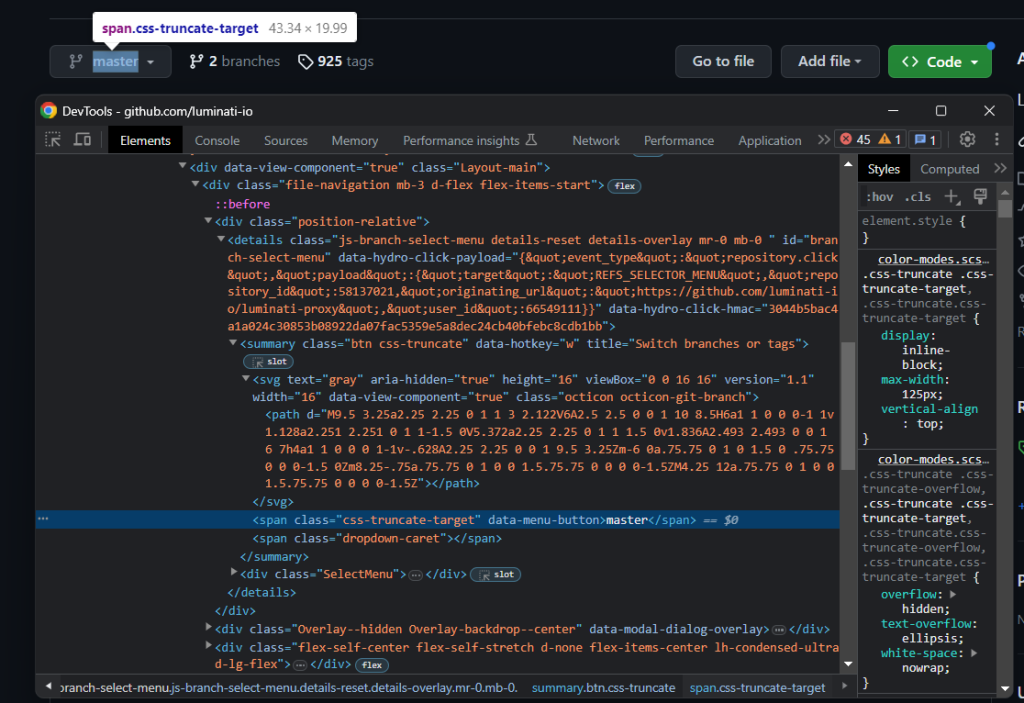
请注意,选择存储主分支名称的 HTML 元素时没有简单的方法。您只能选择 .octicon-git-branch 节点,然后在同级元素中寻找目标 span:
git_branch_icon_html_element = soup.select_one('.octicon-git-branch')
main_branch_html_element = git_branch_icon_html_element.find_next_sibling('span')
main_branch = main_branch_html_element.get_text().strip()
通过图标的同级元素找到相关元素——这一模式在 GitHub 上非常有效。您将在本节中多次看到这个方法。
现在,重点关注分支标题:
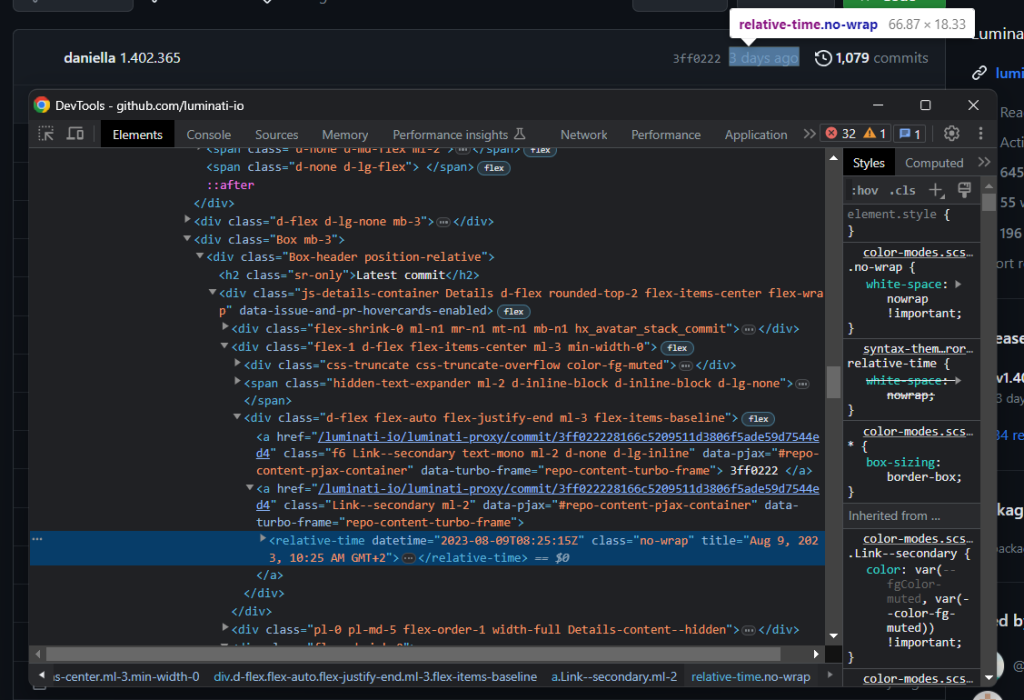
通过以下命令提取最新的提交时间:
relative_time_html_element = boxheader_html_element.select_one('relative-time')
latest_commit = relative_time_html_element['datetime']在给定一个节点的情况下,您可以像在 Python 字典中一样访问其 HTML 属性。
本节中的另一个重要信息是提交次数:
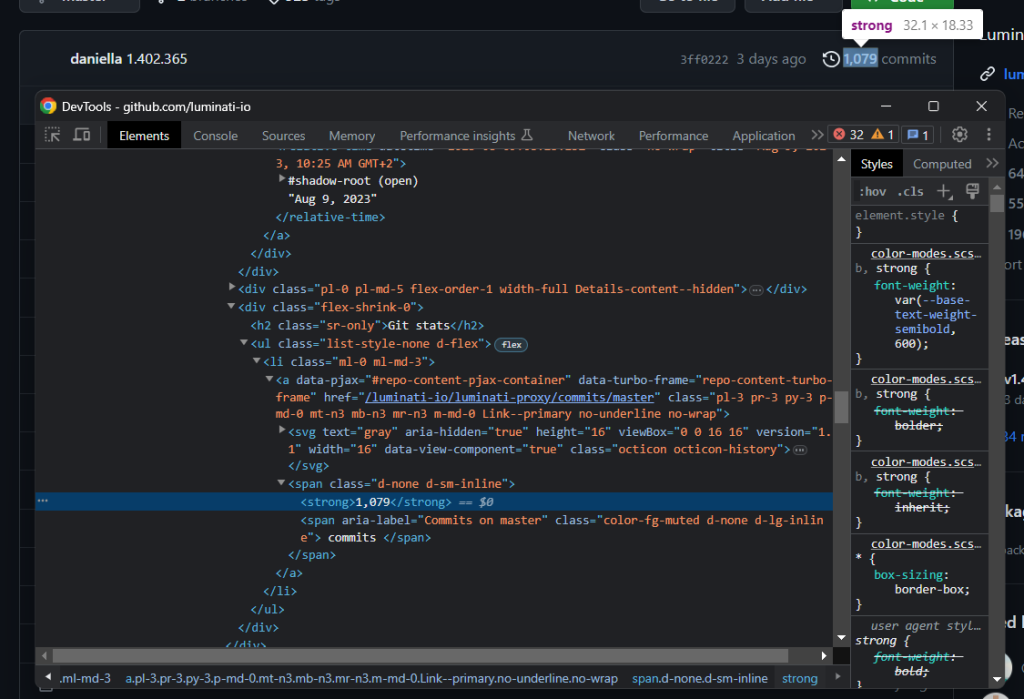
使用前文描述的图标模式收集此信息:
history_icon_html_element = boxheader_html_element.select_one('.octicon-history')
commits_span_html_element = history_icon_html_element.find_next_sibling('span')
commits_html_element = commits_span_html_element.select_one('strong')
commits = commits_html_element.get_text().strip().replace(',', '')请注意,find_next_sibling() 仅允许访问顶层同级元素。要选择其子元素,您必须先获得同级元素,然后如前文一样调用 select_one()。
由于在 GitHub 中一千以上的数字包含逗号,因此请使用 replace() Python 方法删除逗号。
接着,重点关注右边的信息框:
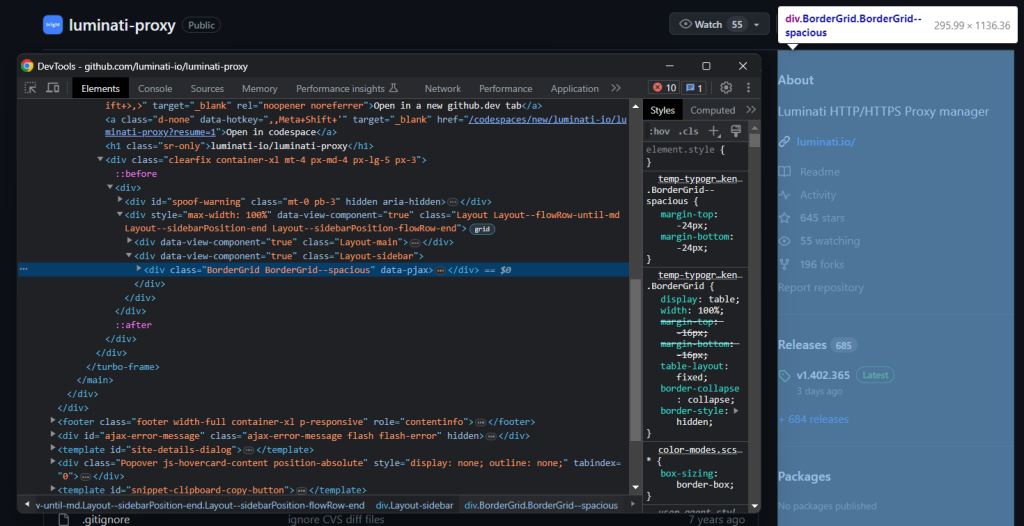
通过以下方式将其选中:
bordergrid_html_element = soup.select_one('.BorderGrid')检查描述元素:
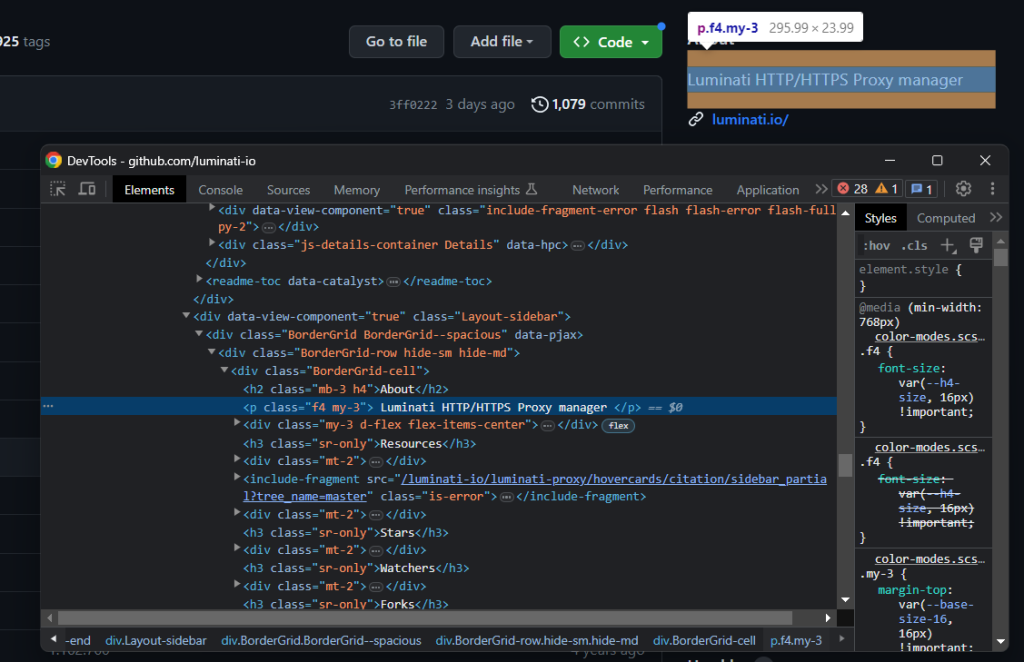
同样,您可以通过同级元素将其选中:
about_html_element = bordergrid_html_element.select_one('h2')
description_html_element = about_html_element.find_next_sibling('p')
description = description_html_element.get_text().strip()然后,应用图标模式以检索存储库的星星数、关注量和复制量等数据。
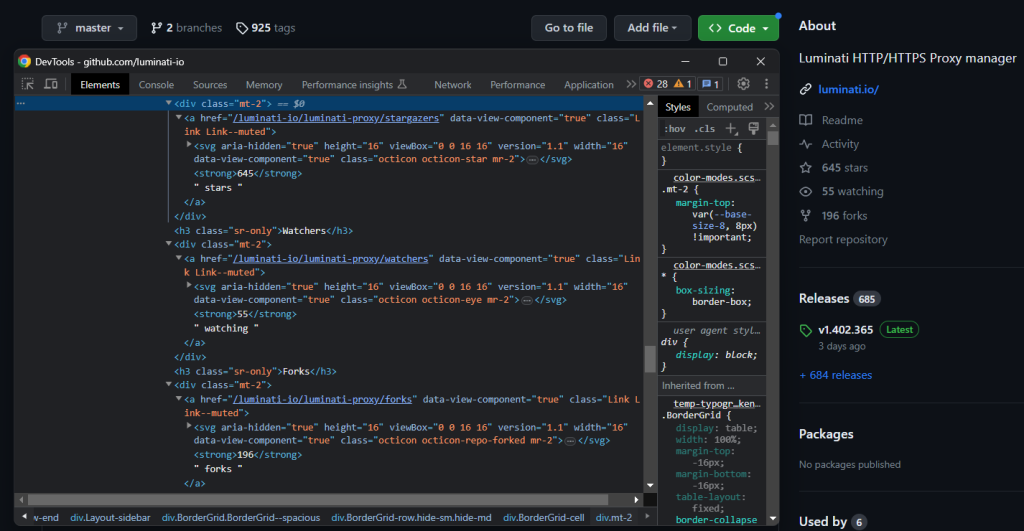
先关注图标,然后再关注其文本同级元素:
star_icon_html_element = bordergrid_html_element.select_one('.octicon-star')
stars_html_element = star_icon_html_element.find_next_sibling('strong')
stars = stars_html_element.get_text().strip().replace(',', '')
eye_icon_html_element = bordergrid_html_element.select_one('.octicon-eye')
watchers_html_element = eye_icon_html_element.find_next_sibling('strong')
watchers = watchers_html_element.get_text().strip().replace(',', '')
fork_icon_html_element = bordergrid_html_element.select_one('.octicon-repo-forked')
forks_html_element = fork_icon_html_element.find_next_sibling('strong')
forks = forks_html_element.get_text().strip().replace(',', '')
干得好!您刚刚抓取了一个 GitHub 存储库。
第 7 步:抓取 readme
另一个需要检索的重要信息是 README.md 文件。这是一个可选文本文件,用于描述 GitHub 存储库并解释如何使用代码。
如果您点击 README.md 文件,然后点击“原始” (Raw) 按钮,您将被重定向到以下 URL:
https://raw.githubusercontent.com/luminati-io/luminati-proxy/master/README.md
因此可以推断 GitHub 存储库的 readme 文件的 URL 遵循以下格式:
https://raw.githubusercontent.com/<repo_id>/<repo_main_branch>/README.md
由于您将 <repo_main_branch> 信息存储在 main_branch 变量中,您可以通过编程的方式,使用 Python f-string 构建此 URL:
readme_url = f'https://raw.githubusercontent.com/luminati-io/luminati-proxy/{main_branch}/README.md'
然后,使用 requests 检索 readme 的原始 Markdown 内容:
readme_url = f'https://raw.githubusercontent.com/luminati-io/luminati-proxy/{main_branch}/README.md'
readme_page = requests.get(readme_url)
readme = None
# if there is a README.md file
if readme_page.status_code != 404:
readme = readme_page.text
注意 404 检查,以避免在存储库没有 readme 文件时存储了 GitHub 404 页面的内容。
第 8 步:存储抓取的数据
别忘了将抓取的数据变量添加到 repo 字典中:
repo['name'] = name
repo['latest_commit'] = latest_commit
repo['commits'] = commits
repo['main_branch'] = main_branch
repo['description'] = description
repo['stars'] = stars
repo['watchers'] = watchers
repo['forks'] = forks
repo['readme'] = readme
使用 print(repo) 来确保数据提取过程符合预期。运行 Python GitHub 抓取工具,您将看到:
{'name': 'luminati-proxy', 'latest_commit': '2023-08-09T08:25:15Z', 'commits': '1079', 'main_branch': 'master', 'description': 'Luminati HTTP/HTTPS Proxy manager', 'stars': '645', 'watchers': '55', 'forks': '196', 'readme': '# Proxy managernn (omitted for brevity...)'}
很好!您知道怎么抓取 GitHub 了!
第 9 步:将抓取的数据导出到 JSON
最后一步是让收集的数据更易于共享、读取和分析。实现这一目标的最佳方法是以人类可读的格式导出数据,例如 JSON:
import json
# ...
with open('repo.json', 'w') as file:
json.dump(repo, file, indent=4)
从 Python 标准库导入 json,使用 open()初始化 repo.json 文件,最后使用 json.ump() 填充文件。查看我们的指南,详细了解如何在 Python 中解析 JSON。
完美!这时该查看一下整个 GitHub Python 抓取工具了。
第 10 步:整合所有代码
完整的 scraper.py 文件如下所示:
import requests
from bs4 import BeautifulSoup
import json
# the URL of the target repo to scrape
url = 'https://github.com/luminati-io/luminati-proxy'
# download the target page
page = requests.get(url)
# parse the HTML document returned by the server
soup = BeautifulSoup(page.text, 'html.parser')
# initialize the object that will contain
# the scraped data
repo = {}
# repo scraping logic
name_html_element = soup.select_one('[itemprop="name"]')
name = name_html_element.get_text().strip()
git_branch_icon_html_element = soup.select_one('.octicon-git-branch')
main_branch_html_element = git_branch_icon_html_element.find_next_sibling('span')
main_branch = main_branch_html_element.get_text().strip()
# scrape the repo history data
boxheader_html_element = soup.select_one('.Box .Box-header')
relative_time_html_element = boxheader_html_element.select_one('relative-time')
latest_commit = relative_time_html_element['datetime']
history_icon_html_element = boxheader_html_element.select_one('.octicon-history')
commits_span_html_element = history_icon_html_element.find_next_sibling('span')
commits_html_element = commits_span_html_element.select_one('strong')
commits = commits_html_element.get_text().strip().replace(',', '')
# scrape the repo details in the right box
bordergrid_html_element = soup.select_one('.BorderGrid')
about_html_element = bordergrid_html_element.select_one('h2')
description_html_element = about_html_element.find_next_sibling('p')
description = description_html_element.get_text().strip()
star_icon_html_element = bordergrid_html_element.select_one('.octicon-star')
stars_html_element = star_icon_html_element.find_next_sibling('strong')
stars = stars_html_element.get_text().strip().replace(',', '')
eye_icon_html_element = bordergrid_html_element.select_one('.octicon-eye')
watchers_html_element = eye_icon_html_element.find_next_sibling('strong')
watchers = watchers_html_element.get_text().strip().replace(',', '')
fork_icon_html_element = bordergrid_html_element.select_one('.octicon-repo-forked')
forks_html_element = fork_icon_html_element.find_next_sibling('strong')
forks = forks_html_element.get_text().strip().replace(',', '')
# build the URL for README.md and download it
readme_url = f'https://raw.githubusercontent.com/luminati-io/luminati-proxy/{main_branch}/README.md'
readme_page = requests.get(readme_url)
readme = None
# if there is a README.md file
if readme_page.status_code != 404:
readme = readme_page.text
# store the scraped data
repo['name'] = name
repo['latest_commit'] = latest_commit
repo['commits'] = commits
repo['main_branch'] = main_branch
repo['description'] = description
repo['stars'] = stars
repo['watchers'] = watchers
repo['forks'] = forks
repo['readme'] = readme
# export the scraped data to a repo.json output file
with open('repo.json', 'w') as file:
json.dump(repo, file, indent=4)
您使用不到 100 行代码构建了一个网络爬虫来收集存储库数据。
使用以下命令运行脚本:
python scraper.py
等待抓取完成,然后您将在项目的根文件夹中找到一个 repo.json 文件。打开此文件,您会看到:
{
"name": "luminati-proxy",
"latest_commit": "2023-08-09T08:25:15Z",
"commits": "1079",
"main_branch": "master",
"description": "Luminati HTTP/HTTPS Proxy manager",
"stars": "645",
"watchers": "55",
"forks": "196",
"readme": "# Proxy managernn[](https://david-dm.org/luminati-io/luminati-proxy)n[](https://david-dm..."
}
恭喜!您从网页中包含的原始数据开始,现在已经拥有 JSON 文件中的半结构化数据。您刚刚学会了如何在 Python 中构建 GitHub 存储库抓取工具!
结语
在本分步指南中,您了解了构建 GitHub 存储库抓取工具背后的原因。具体而言,您通过指导教程学习了如何抓取 GitHub。如上文所述,只需几行代码即可!
同时,越来越多的网站正在采用防抓取技术。这些技术通过 IP 封禁和速率限制来识别和阻止请求,从而防止您的抓取工具访问这些网站。绕过这些技术的最佳方法是使用代理。了解一下 Bright Data 提供的各类一流代理服务和专用 GitHub 代理。
Bright Data 掌控着最出色的网页抓取代理,为财富 500 强企业和 20,000 多家客户提供服务。其全球代理网络包括:
总体而言,Bright Data 是市面上最大、最可靠的抓取导向代理
注意:本指南在撰写时已由我们的团队开展了全面测试,但是由于各类网站经常更新代码和结构,某些步骤可能无法如预期使用。



技术写作
 5.5 years experience
5.5 years experience
Antonello是一名软件工程师,但他更喜欢称自己为技术传教士。通过写作传播知识是他的使命。


