
Craigslist有大量的信息可以用于市场研究、价格监控和竞争对手分析。实际上,它每个月发布超过8000万个分类广告。
但由于有地理封锁、IP禁令、速率限制和验证码等防护措施,要编程访问这些信息是一个挑战。
在本文中,您将学习如何使用Playwright和Python手动抓取Craigslist数据,以便利用这些丰富的信息资源。您还将学习如何使用Bright Data代理、Scraping Browser和数据集来避免被封锁。
如何用Python抓取Craigslist数据
在本节中,您将构建Python脚本来抓取Craigslist数据。具体来说,您的爬虫将提取任何输入城市的汽车列表,并将数据存储在CSV文件中。
首先,为项目设置一个新目录:
mkdir craigScraper然后进入新目录:
cd craigScraper使用以下命令为项目设置一个虚拟环境:
python3 -m venv env虚拟环境允许您在特定目录中安装特定的包和版本,避免与全局安装发生冲突。使用以下命令激活虚拟环境:
source env/bin/activate # For Linux/MacOS
envScriptsactivate # For Windows然后安装Playwright库,这是微软的开源跨浏览器自动化和测试平台:
pip3 install pytest-playwright这将用于抓取Craigslist。一旦完成,安装所需的浏览器:
playwright install此命令安装特定版本的测试浏览器,如Chromium和Firefox。
然后创建一个名为scraper.py的文件,并添加以下代码:
from playwright.sync_api import sync_playwright
import csv, sys
def main():
city = input("Enter any city you want to scrape cars from: ").lower() # Get the city that we want to scrape cars from
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
page = browser.new_page() # Launch the browser using Playwright
try: # Go to the cars listing section on Craigslist of the city entered by the user
page.goto(f'https://{city}.craigslist.org/search/cta#search=1~gallery~0~0')
except:
print("Page does not exist on Craigslist")
sys.exit(1)
page.wait_for_timeout(15000)
cars = page.get_by_role("listitem").all() # Grab all the listings on the page
with open("cars.csv", "w") as csvfile: # Write to a CSV file
writer = csv.writer(csvfile)
writer.writerow(
['Car', 'Price', 'Miles Driven', 'Location', 'Posted', 'Link']) # Columns of the CSV file
for car in cars: # Looping over each of the listings
try:
meta = []
price = car.locator("span.priceinfo").inner_text() # Price of the car
text = car.locator("a > span.label").inner_text() # Title of the listing
link = car.locator("a.posting-title").get_attribute('href') # Link to the listing
info = car.locator("div.meta").inner_text() # Meta info (Posted ago, miles driven, location)
meta = info.split("·")
time, miles, location = meta[0], meta[1], meta[2]
writer.writerow([text, price, miles, location, time, link]) # Writing to CSV file
except:
print(f"Inadequate information about the car n -------------")
page.wait_for_timeout(10000)
browser.close()
if __name__ == "__main__":
main()在这段代码中,您导入了所需的库,即Playwright、CSV和sys。本教程中使用的是同步版本,但对于复杂的场景,您应该使用async_playwright。
接下来,您声明了一个main()函数,存储了整个代码。city变量存储用户选择的要抓取数据的城市。
然后Playwright启动一个浏览器窗口,导航到汽车列表的URL。如果页面不存在,程序会打印错误信息并退出。
之后,程序等待元素完全可见,超时设置为15000毫秒。它获取所有的汽车列表,打开一个CSV文件,写入列标题,并抓取并填写所有剩余数据。如果有任何遗漏,终端会显示错误信息。
Playwright使用page.get_by_role()、page.get_by_text()、page.get_by_label()和page.locator()等定位器来查找页面上的特定元素。
这段代码搜索所有的列表项(汽车列表),然后使用CSS选择器查找每个元素的标题、价格、链接和其他信息。
如果您查看Craigslist的网站结构,您会看到以下内容:
- 每个汽车列表都有一个
gallery-card类。 - 在这个类中,
a标签包含标题。 - 具有
meta类的div标签包含发布时间、行驶里程和位置。 - 具有
priceinfo类的span标签包含列表价格。
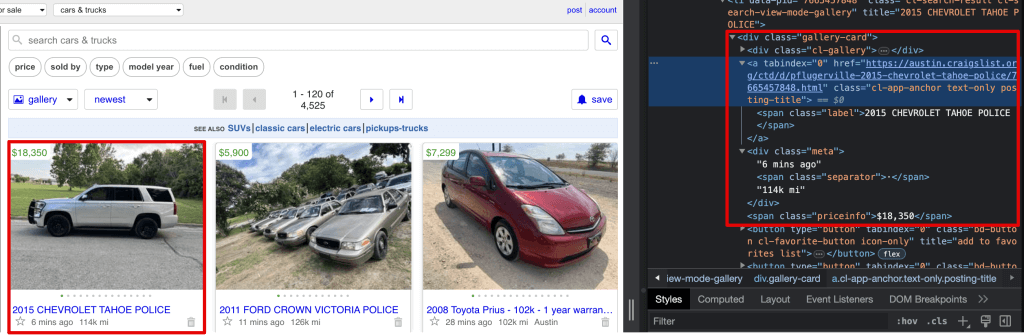
因此,在这段代码中,您使用了span.priceinfo来查找价格。它进入具有priceinfo类名的gallery卡中的span标签。您以类似方式提取了其他详细信息。
一旦提取完成,浏览器窗口就会关闭。
代码的输出如下所示:
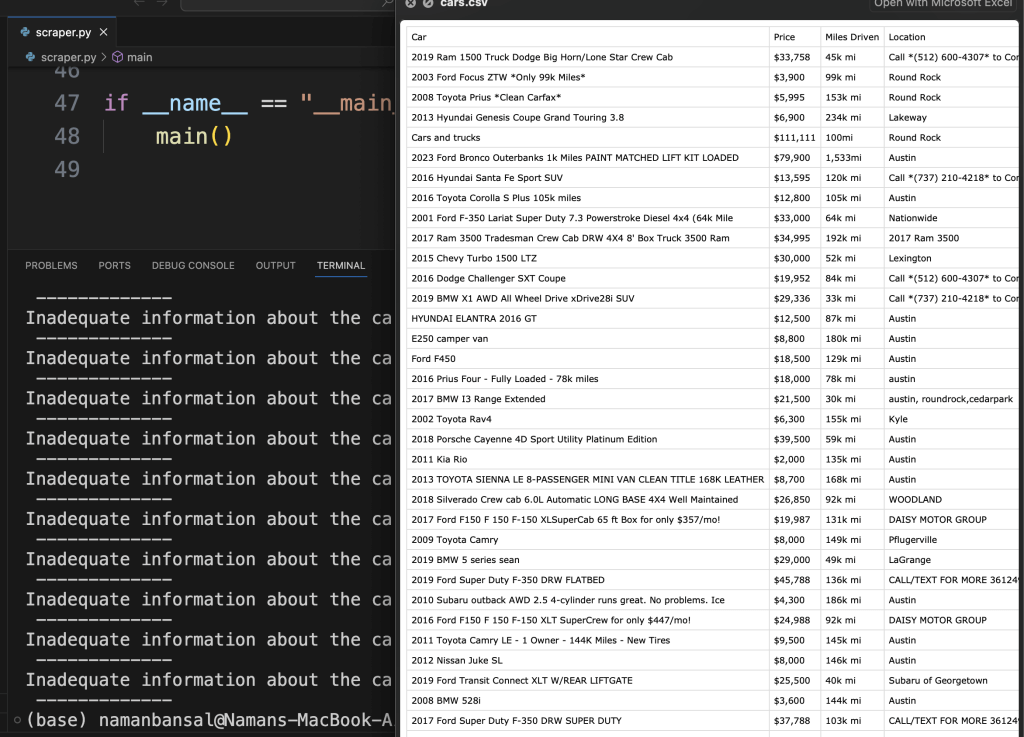
有了列表中的数据,爬虫会创建一个包含所有参数(如标题、价格、链接和位置)的CSV文件,并在终端中打印错误信息。
这看 起来很简单,但实际上并不简单。当您尝试抓取更多数据时,它会变得越来越困难和风险更高。例如,您的爬虫可能因频繁抓取数据而导致您的IP被禁止。更糟糕的是,您可能会因为大规模项目而面临法律风险。
这就是为什么使用代理是明智的选择。
以高频率从同一个IP向网站发送请求可能会导致被禁止。此外,大多数网站都有防止此类攻击的机器人检测措施。这就是为什么代理对于大规模、匿名的网络抓取至关重要。
为什么在抓取网站时应该使用代理
代理通过掩盖您的IP地址,在您和目标网站之间添加了一层匿名性。这就像让朋友帮您取包裹一样,他们去商店而不是您,保护了您的身份。
以下是您在进行网络抓取时应该使用代理的一些原因:
避免地理封锁
地理封锁是基于用户位置限制访问的过程。
当您访问网站时,它会通过IP地址查询数据库中的IP映射位置。这使得网站能够提供个性化内容或执行基于位置的限制。
代理通过掩盖您的IP地址,并使用未被封锁的IP(例如解锁流媒体平台上的区域内容)将您的请求转发给服务器,从而克服这一点。
IP轮换
顾名思义,IP轮换是指不断更改您的代理IP以进一步欺骗网站。从一个IP频繁发送请求可能会导致网站标记它,这可以通过从一组IP中轮换来避免。
像Bright Data这样的代理提供商使用高级轮换算法,确保您不会被封锁。他们还允许您自定义预定义的标准,例如在更改之前的请求次数、IP更改之间的时间以及您的IP池中的IP数量。
负载均衡
负载均衡器是反向代理,它分层服务器并分发客户端请求。这使您能够轻松扩展应用程序,同时确保最佳利用:
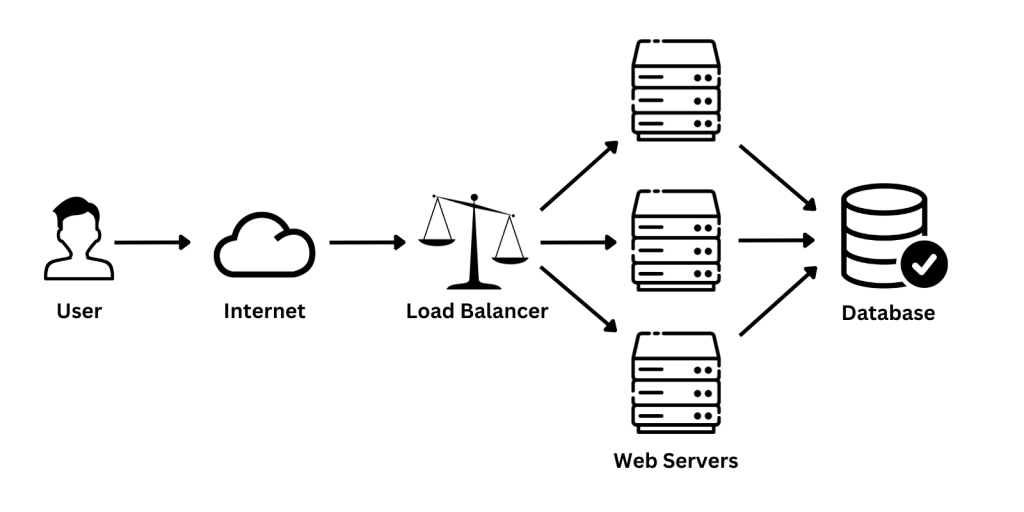
例如,在这个图表中,负载均衡器(或反向代理)将客户端流量分配给三个服务器,然后访问数据库服务器。
除了这些,负载均衡还确保您的网站始终可用,并在最低成本下简化维护过程。内置在负载均衡器中的防火墙可以防止对您的网站的攻击,还可以识别和缓解分布式拒绝服务(DDoS)攻击。
在进行网络抓取时,代理可以分配负载以提高效率并克服机器人检测。
如何用Bright Data代理抓取Craigslist数据
既然您知道代理的好处,可以通过代理来增强您的Craigslist抓取器。在本教程中,您将使用Bright Data,因为它提供了全面的网络抓取解决方案,包括四种类型的代理:易于使用的代理管理器、浏览器扩展、Scraping Browser API和网络抓取IDE。
首先,访问他们的网站并注册一个免费账户。
创建账户后,导航到侧边栏中的代理和抓取基础设施部分,并使用添加按钮创建一个新代理。然后选择数据中心代理选项:
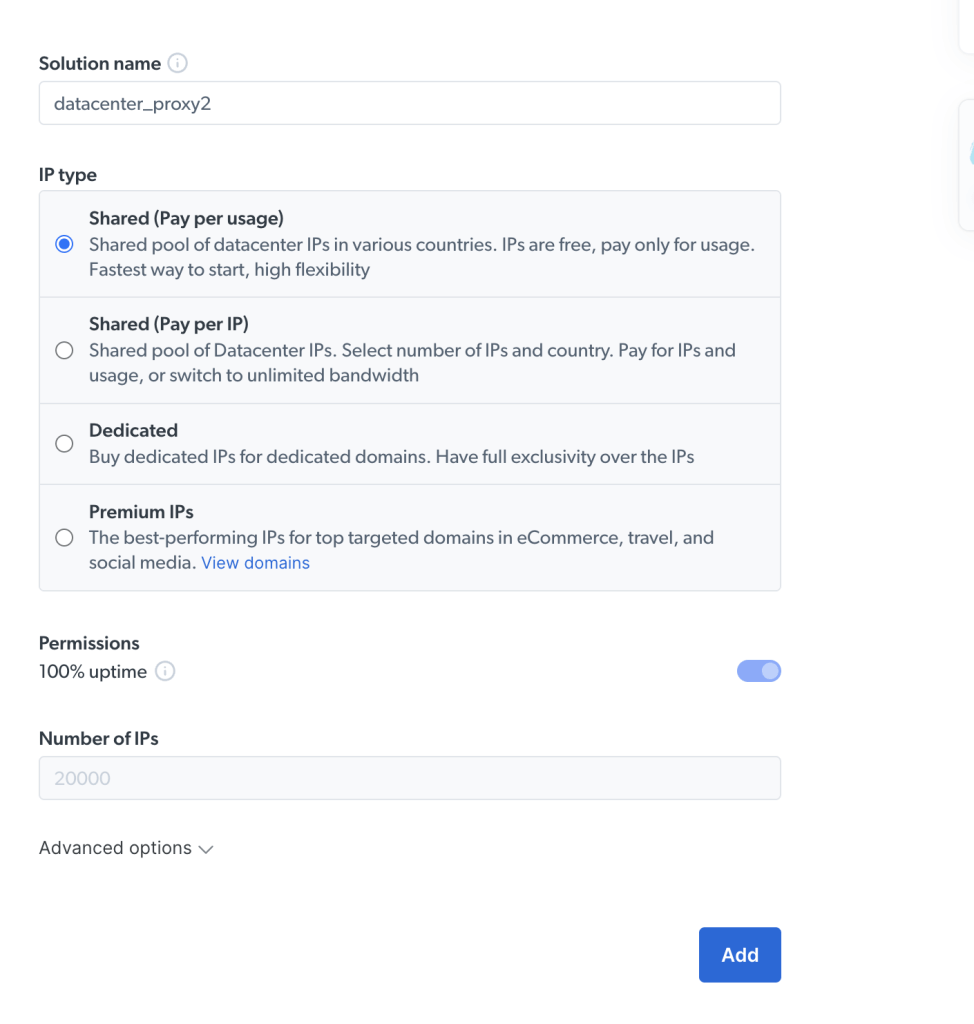
接下来,您将看到一个可以命名解决方案并选择IP类型的屏幕。选项如下:
- 共享(按使用付费):各国共享的数据中心IP池。您只需根据使用情况付费。
- 共享(按IP付费):选择IP数量和国家。您需支付IP数量和使用费或切换到无限带宽。
- 专用:为特定域名购买专用IP。
- 高级IP:最佳表现的IP,用于顶级目标网站,如airbnb.com、amazon.com和reddit.com。
确保激活代理:
接下来,您需要添加三行代码以使其正常工作。
在scraper.py中更新这一行:
browser = p.chromium.launch(headless=False)使用此代码:
browser = p.chromium.launch(headless=False, proxy={
"server": "brd.superproxy.io:22225",
"username": "YOUR_USERNAME",
"password": "YOUR_PASSWORD"
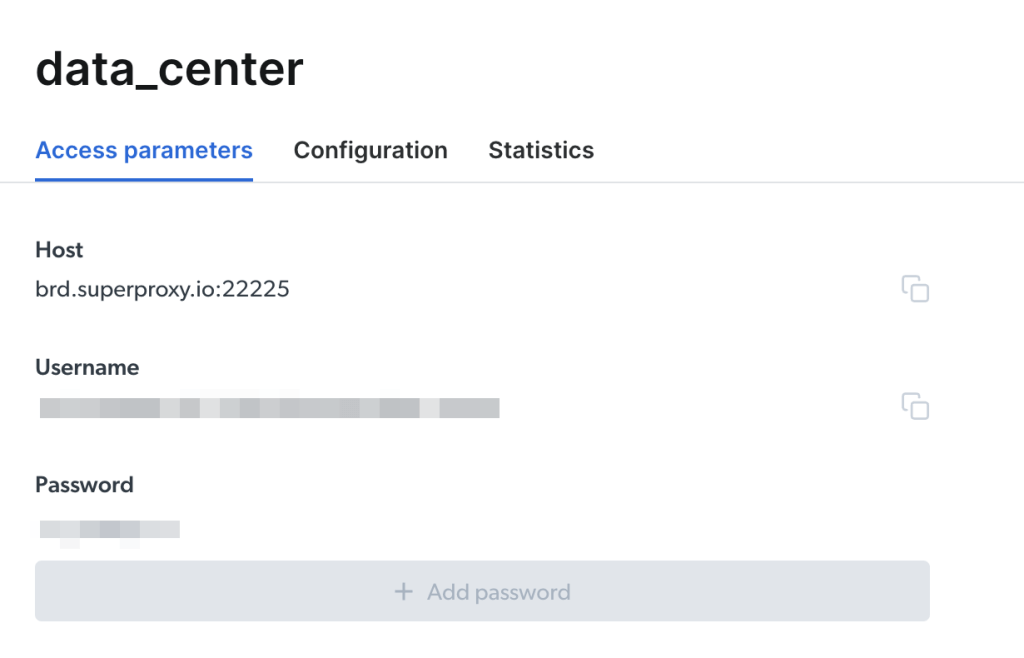
})您可以在Bright Data仪表板中找到这些凭据。转到代理和抓取基础设施并选择要查看的特定代理。在信息页面上可以看到这些信息:
就是这样!如果爬虫加载网站并创建包含数据的CSV文件,则代理集成成功。
Bright Data代理的另一个好处是,您不需要担心IP轮换,因为它内置在代理中。
使用Bright Data抓取浏览器抓取Craigslist数据
Bright Data还提供了一个内置浏览器进行抓取,它兼容Puppeteer、Playwright和Selenium。现在您将使用它实现Craigslist抓取器。
Scraping Browser比本地Chromium实例有很多优势,比如自动内置验证码解决、浏览器指纹、自动重试和JavaScript渲染,能够绕过机器人检测软件。
您可以添加任意数量的抓取项目和浏览器。Bright Data会处理和托管所有内容,节省您的时间、金钱和资源。
在您的仪表板中,通过导航到代理和抓取基础设施,然后点击添加按钮并选择抓取浏览器选项,创建一个新的抓取浏览器实例:

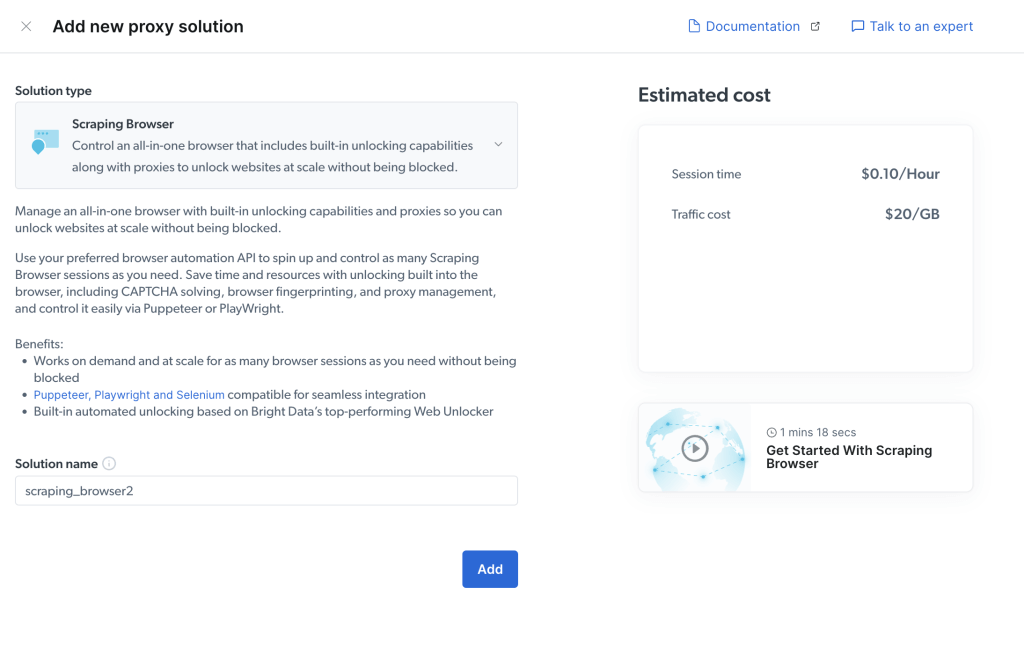
系统会要求您为浏览器命名,并显示预估成本,然后您可以点击添加:
接下来,从抓取浏览器详细信息中复制您的密码,并添加以下代码:
password = 'USER:PASS'
url = f'wss://{pass}@brd.superproxy.io:9222'
browser = browser = p.chromium.connect_over_cdp(url)请注意:您需要将
USER部分替换为用户名,并将PASS替换为抓取浏览器的密码。
您的代码应如下所示:
from playwright.sync_api import sync_playwright
import csv, sys
def main():
city = input("Enter any city you want to scrape cars from: ").lower() # Get the city that we want to scrape cars from
with sync_playwright() as p:
password = 'USER:PASS'
url = f'wss://{password}@brd.superproxy.io:9222'
browser = browser = p.chromium.connect_over_cdp(url)
page = browser.new_page() # Launch the browser using Playwright
try: # Go to the cars listing section on Craigslist of the city entered by the user
page.goto(f'https://{city}.craigslist.org/search/cta#search=1~gallery~0~0')
except:
print("Page does not exist on Craigslist")
sys.exit(1)
page.wait_for_timeout(15000)
cars = page.get_by_role("listitem").all() # Grab all the listings on the page
with open("cars.csv", "w") as csvfile: # Write to a CSV file
writer = csv.writer(csvfile)
writer.writerow(
['Car', 'Price', 'Miles Driven', 'Location', 'Posted', 'Link']) # Columns of the CSV file
for car in cars: # Looping over each of the listings
try:
meta = []
price = car.locator("span.priceinfo").inner_text() # Price of the car
text = car.locator("a > span.label").inner_text() # Title of the listing
link = car.locator("a.posting-title").get_attribute('href') # Link to the listing
info = car.locator("div.meta").inner_text() # Meta info (Posted ago, miles driven, location)
meta = info.split("·")
time, miles, location = meta[0], meta[1], meta[2]
writer.writerow([text, price, miles, location, time, link]) # Writing to CSV file
except:
print(f"Inadequate information about the car n -------------")
page.wait_for_timeout(10000)
browser.close()
if __name__ == "__main__":
main()现在,Bright Data抓取浏览器将代替本地Chromium实例,为您提供所有相关的好处。
数据集:网络抓取的替代方案
Bright Data提供了针对公共网站的自定义数据集,这些数据集根据您的需求量身定制。这些数据集可以根据请求提供大量最新抓取的数据,同时管理整个过程,从构建爬虫到验证数据。
您可以请求以JSON、ndjson和CSV格式的数据,通过Snowflake、Google Cloud、PubSub、Amazon S3或Microsoft Azure交付,并提供按需访问的API。
Bright Data还遵守数据保护法律,如GDPR和CCPA。
您可以查看他们的自定义Craigslist数据集,其中包含有关工作、住房、服务、汽车等方面的数据。除了按需访问数据,您还可以根据需要调整和调试代码。例如,您可以将其编辑为仅提取住房数据或其中的特定部分,如图像、标题和链接。
结论
抓取Craigslist可以发现很多有用的数据。然而,如果没有适当的措施,如代理,您可能会被封锁或禁止。
本文向您展示了如何抓取Craigslist上的汽车数据,将其保存到CSV文件中,并集成代理。您还探索了Bright Data的抓取解决方案,如完全托管的Scraping Browser以及适用于Facebook、LinkedIn、Crunchbase、Amazon和Zillow等网站的数据集。
Scraping Browser配备内置的验证码解决方案、自动重试和JavaScript渲染,而数据集则提供了无需编码的方法来收集大量可靠的网站数据。
Bright Data工具将帮助您以实惠的价格进行可靠的数据提取。祝您抓取愉快!
立即注册,找到适合您的Craigslist抓取解决方案,包括免费试用。







