

为什么要从 Zalando 抓取产品详细数据?
Zalando 是欧洲最受欢迎的在线服装零售平台之一。拥有超过 5000 万活跃用户,是欧洲领先的时尚电商网站。它提供种类繁多的产品,包括鞋类、服装和配饰,涵盖了知名品牌和新兴设计师的作品。
从 Zalando 抓取产品详细数据的三个主要原因是:
- 市场研究: 获取当前时尚趋势的宝贵见解。这些信息帮助企业做出明智的决策,保持竞争力,并有效地调整其产品以满足客户需求。
- 价格监控: 跟踪价格波动,以利用优惠并研究市场。
- 品牌受欢迎度: 关注 Zalando 上受欢迎的产品,了解哪些品牌在客户中更受欢迎,从而研究其策略。
简而言之,Zalando 爬取数据为公司和用户带来了无限可能。
用于抓取 Zalando 的库和工具
要了解众多可用的抓取工具中哪一个最适合抓取 Zalando,请在浏览器中打开它。检查 DOM 并将其与原始源代码进行比较。您会注意到 DOM 结构与服务器生成的 HTML 文档略有不同。这意味着该网站依赖 JavaScript 进行渲染。要抓取动态内容站点,您需要一个可以运行 JavaScript 的工具,例如 Selenium!
接下来是编程语言。说到网页抓取,最流行的语言是 Python。它的简单语法和丰富的库生态系统使其非常适合我们的目标。所以,让我们使用 Python。
在开始之前,请查看以下两个指南:
Selenium 在一个可控的网络浏览器中渲染站点,您可以指示它执行特定操作。通过在 Python 中使用它,您将能够构建一个有效的 Zalando 爬虫。现在来看看如何实现吧!
使用 Selenium 抓取 Zalando 产品数据
按照这个分步教程,学习如何在 Python 中创建一个 Zalando 爬虫。
步骤 1:设置 Python 项目
在进行网页抓取之前,请确保您满足以下先决条件:
- 在您的机器上安装 Python 3+: 下载安装程序,双击并按照安装向导操作。
- 选择一个 Python IDE: PyCharm Community Edition 或 Visual Studio Code 搭配 Python 扩展。
您现在已具备设置 Python 项目和编写代码所需的一切!
启动终端并运行以下命令:
- 创建一个 zalando-scraper 文件夹。
- 进入文件夹。
- 使用 Python 虚拟环境初始化它。
mkdir zalando-scraper
cd zalando-scraper
python -m venv env在 Linux 或 macOS 上,执行以下命令以激活环境:
./env/bin/activateOn Windows, run:envScriptsactivate.ps1接下来,在项目文件夹中创建一个 scraper.py 文件,并添加以下行:
print("Hello, World!")这是您可以编写的最简单的 Python 脚本。现在,它只会打印“Hello, World!”但很快它将包含 Zalando 抓取逻辑。
运行它以验证其是否正常工作:
python scraper.py它应在终端中打印以下消息:
Hello, World!现在您确定脚本按预期工作,请在您的 Python IDE 中打开项目文件夹。
太好了!准备编写爬虫的第一行代码。
步骤 2:安装抓取库
如前所述,Selenium 是构建 Zalando 爬虫的选择工具。在激活的 Python 虚拟环境中,运行以下命令将其添加到项目依赖项中:
pip install selenium安装过程可能需要一段时间,请耐心等待。
请注意,本教程涉及的 Selenium 版本为 4.13.x,具有自动驱动程序检测功能。如果您的机器上安装了较旧版本的 Selenium,请使用以下命令更新它:
pip install selenium -U从 scraper.py 中删除所有内容,并使用以下代码初始化一个 Selenium 爬虫:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
# set up a controllable Chrome instance
service = Service()
options = webdriver.ChromeOptions()
# your browser options...
driver = webdriver.Chrome(
service=service,
options=options
)
# maxime the window to avoid the responsive rendering
driver.maximize_window()
# scraping logic...
# close the browser and free up its resources
driver.quit()上述脚本导入了 Selenium 并使用它实例化了一个WebDriver对象。这允许您以编程方式控制 Chrome 浏览器实例。
默认情况下,浏览器窗口将打开,您可以监控页面上执行的操作。这在开发中非常有用。
要在无 GUI 的无头模式下打开 Chrome,请按以下方式配置选项:
options.add_argument('--headless=new')
user_agent = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36'
options.add_argument(f'user-agent={user_agent}')请注意,由于 Zalando 会阻止来自无头浏览器的请求,因此需要额外的 user-agent 选项。这种设置在生产环境中更为常见。
太好了!现在可以构建您的 Zalando Python 爬虫了。
步骤 3:打开目标页面
在本指南中,您将看到如何从Zalando UK 的鞋类产品页面抓取详细数据。当目标不同类型的产品时,您 需要对即将构建的脚本进行一些小的更改。原因是每个产品页面可能有不同的信息结构。
截至本文撰写时,目标页面如下所示:
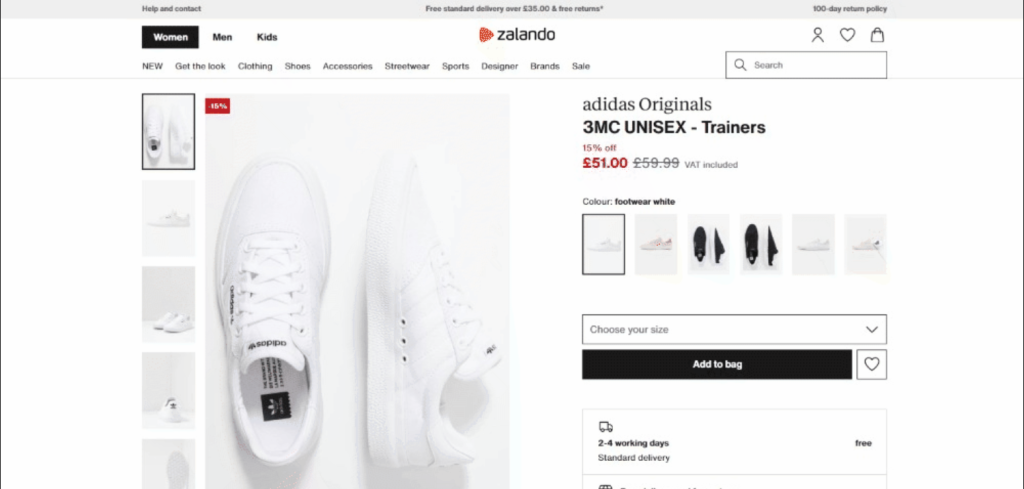
具体来说,这是目标页面的 URL:
使用以下代码在 Selenium 中连接到目标页面:
driver.get('https://www.zalando.co.uk/adidas-originals-3mc-trainers-footwear-whitegold-metallic-ad115o0da-a11.html')get()方法指示浏览器访问传递为参数的 URL 指定的页面。
这是目前的 Zalando 抓取脚本:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
service = Service()
# configure the Chrome instance
options = webdriver.ChromeOptions()
# your browser options...
driver = webdriver.Chrome(
service=service,
options=options
)
# maxime the window to avoid the responsive rendering
driver.maximize_window()
# visit the target page in the controlled browser
driver.get('https://www.zalando.co.uk/adidas-originals-3mc-trainers-footwear-whitegold-metallic-ad115o0da-a11.html')
# scraping logic...
# close the browser and free up its resources
driver.quit()运行应用程序。它将在不到一秒钟的时间内打开以下窗口,然后终止:
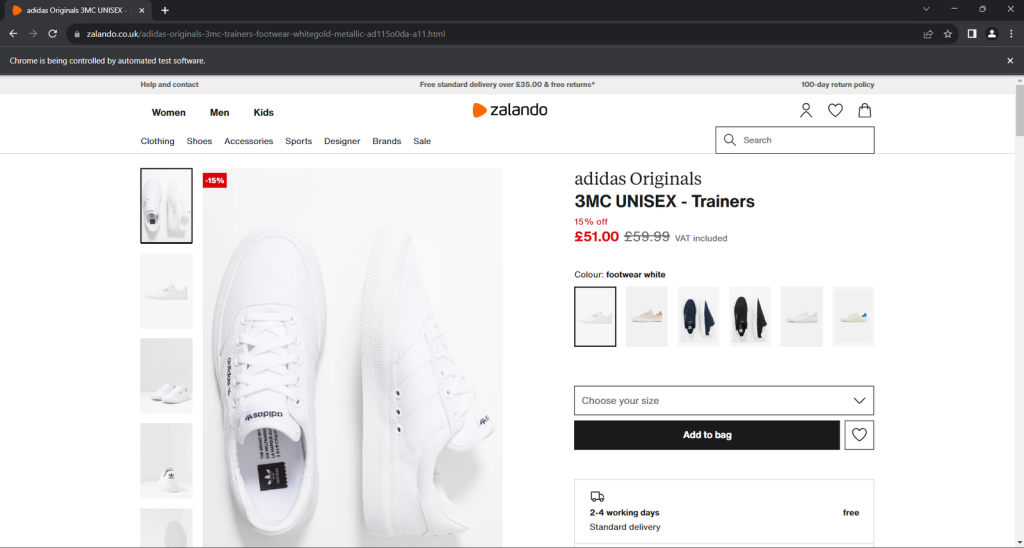
“Chrome 正在被自动化软件控制”的免责声明确保了 Selenium 按预期工作。
步骤 4:熟悉页面结构
要编写有效的抓取逻辑,您需要花些时间研究目标页面的 DOM 结构。这将帮助您了解如何选择 HTML 元素并从中提取数据。
在浏览器中打开隐身模式并访问选择的Zalando 产品页面。右键单击并选择“检查”选项以打开浏览器的开发工具:
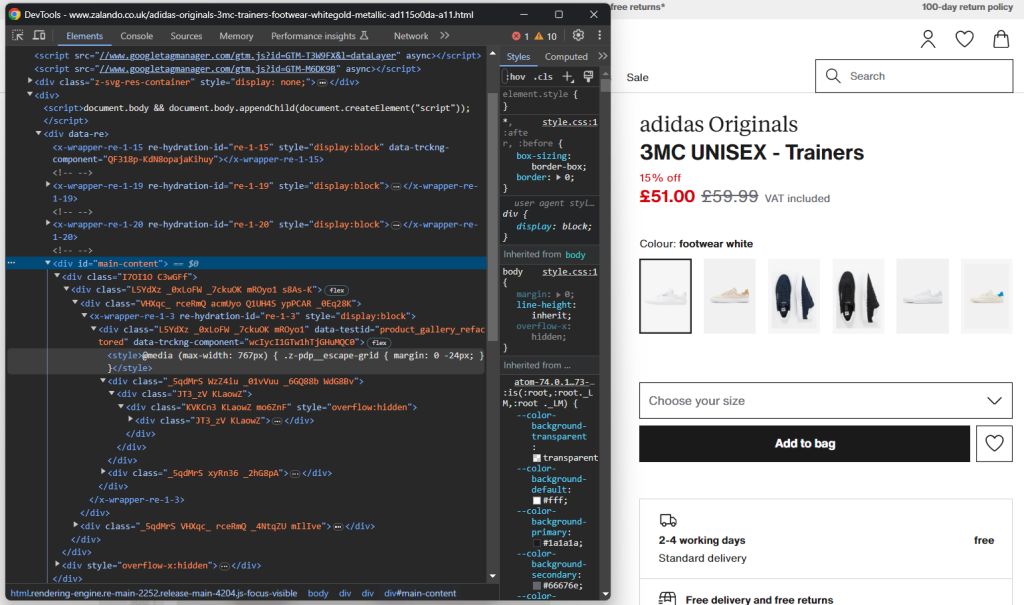
在这里,您一定会注意到大多数 CSS 类似乎是在构建时随机生成的。换句话说,您不应基于它们定义选择策略,因为它们会在每次部署时更改。同时,某些元素具有不常见的 HTML 属性,如 data-testid。这将帮助您定义有效的选择器。
与页面交互,研究点击特定元素(如手风琴)后的 DOM 变化。您会发现某些数据是基于用户操作动态添加到 DOM 中的。
继续检查目标页面,并熟悉其 HTML 结构,直到您觉得准备好继续。
步骤 5:开始提取产品数据
首先,初始化一个数据结构,用于跟踪抓取的数据。Python 字典非常合适:
product = {}开始在页面上选择元素并从中提取数据!
检查包含鞋类品牌的 HTML 元素:
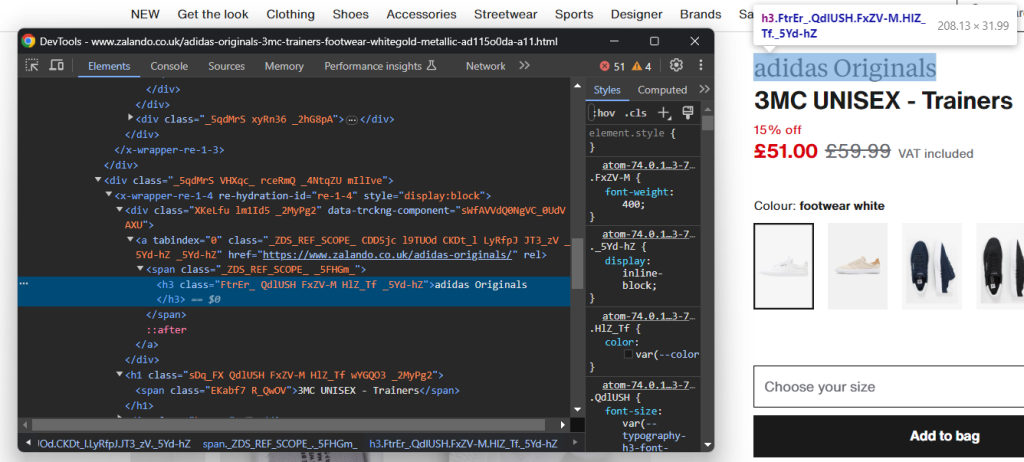
注意,品牌是<h3>,产品名称是<h1>。使用以下代码抓取这些数据:
brand_element = driver.find_element(By.CSS_SELECTOR, 'h3')
brand = brand_element.text
name_element = driver.find_element(By.CSS_SELECTOR, 'h1')
name = name_element.textfind_element()是 Selenium 方法,返回与选择策略匹配的第一个元素。具体来说,By.CSS_SELECTOR 指示驱动程序使用 CSS 选择器策略。Selenium 还支持:
- By.TAG_NAME:根据 HTML 标签搜索元素。
- By.XPATH:通过 XPath 表达式搜索元素。
同样,还有 find_elements(),返回与选择查询匹配的所有节点列表。
记得用以下代码导入 By:
from selenium.webdriver.common.by import By给定一个 HTML 元素,您可以通过 text 属性访问其文本内容。必要时,使用 replace() Python 方法清理文本字符串。
提取价格信息稍微复杂一些。如您从下图中所见,没有简单的方法来选择这些元素:
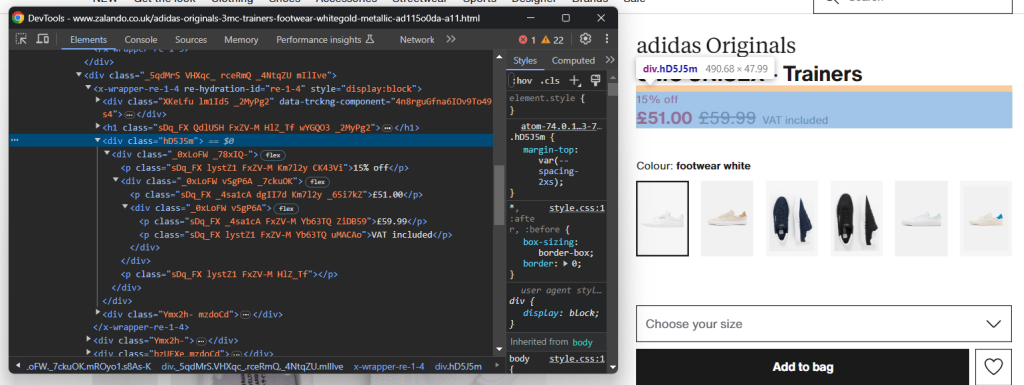
您可以:
- 将价格<div>作为<h1>名称元素的第一个兄弟节点访问。
- 获取其中的所有<p>节点。
使用以下代码实现:
price_elements = name_element
.find_element(By.XPATH, 'following-sibling::*[1]')
.find_elements(By.TAG_NAME, "p")请记住,Selenium 不提供访问节点兄弟节点的实用方法。这就是为什么需要使用 following-sibling::* XPath 表达式。
然后,您可以使用以下代码获取产品价格数据:
discount = None
price = None
original_price = None
if len(price_elements) >= 3:
discount = price_elements[0].text.replace(' off', '')
price = price_elements[1].text
original_price = price_elements[2].text现在关注产品图片库:
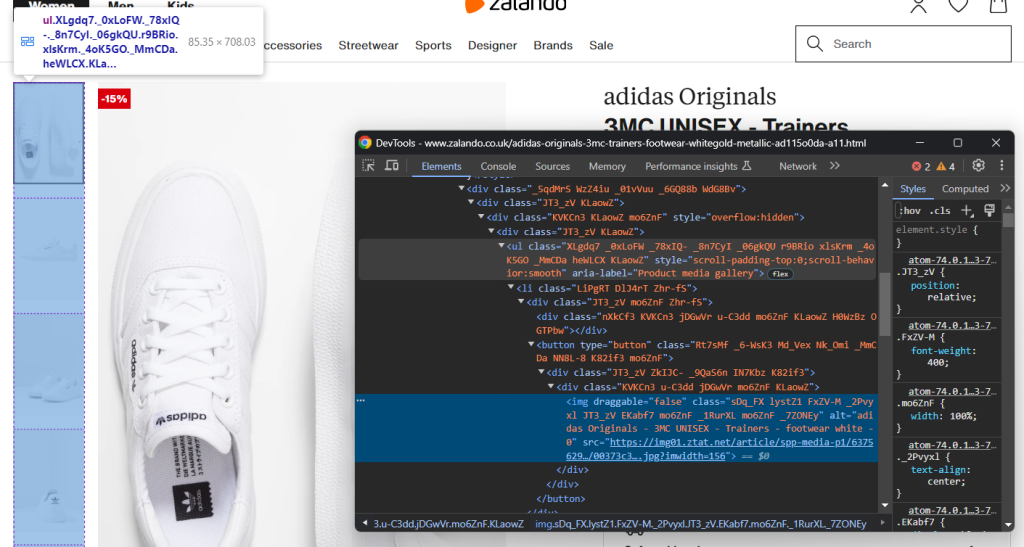
这包含了多张图片,所以初始化一个数组来存储它们:
images = []同样,选择<img>并不容易,但您可以通过定位“Product media gallery”<ul>中的<li>元素实现:
image_elements = driver.find_elements(By.CSS_SELECTOR, '[aria-label="Product media gallery"] li')for image_element in image_elements:
image = image_element.find_element(By.TAG_NAME, 'img').get_attribute('src')
images.append(image)同样,您可以收集鞋子的颜色选项:
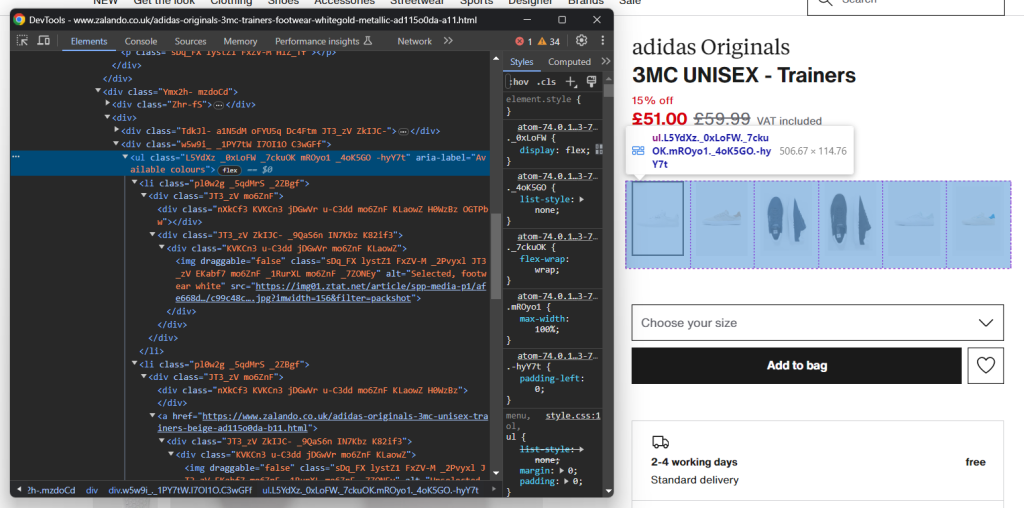
和之前一样,每个颜色元素都是<li>。具体来说,每个颜色部分包含:
- 一个可选的链接。
- 一张图片。
- 一个存储在图片元素 alt 属性中的名称。
使用以下代码提取所有颜色:
colors = []
color_elements = driver.find_elements(By.CSS_SELECTOR, '[aria-label="Available colours"] li')
for color_element in color_elements:
# initialize a new color object
color = {
'color': None,
'image': None,
'link': None
}
# check if the color link is present and scrape its URL
link_elements = color_element.find_elements(By.TAG_NAME, 'a')
if len(link_elements) > 0:
color['link'] = link_elements[0].get_attribute('href')
# check if the color image is present and scrape its data
image_elements = color_element.find_elements(By.TAG_NAME, 'img')
if len(image_elements) > 0:
color['image'] = image_elements[0].get_attribute('src')
color['color'] = image_elements[0].get_attribute('alt')
.replace('Selected, ', '')
.replace('Unselected, ','')
.strip()
colors.append(color)完美!您刚刚实现了一些抓取逻辑,但仍有更多数据需要提取。
步骤 6:抓取产品详细数据
产品详细信息存储在颜色选择元素下方的卡片中:
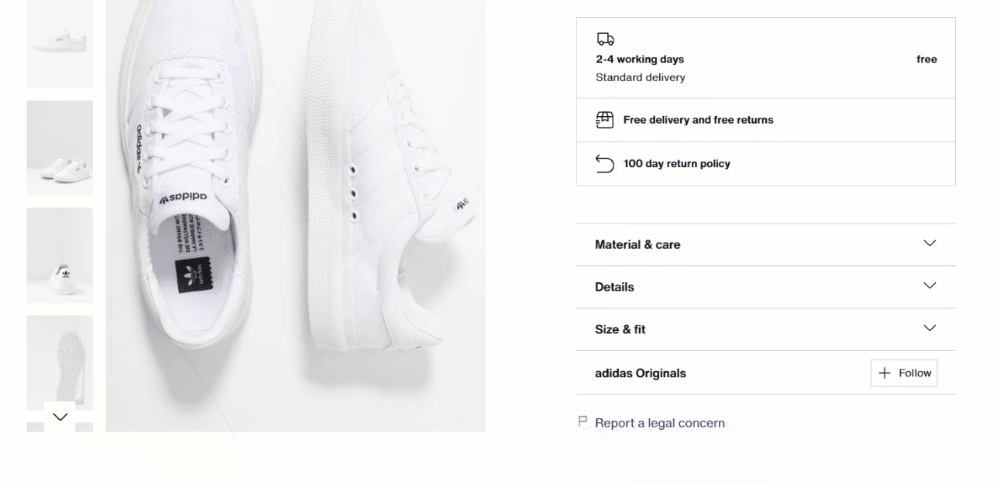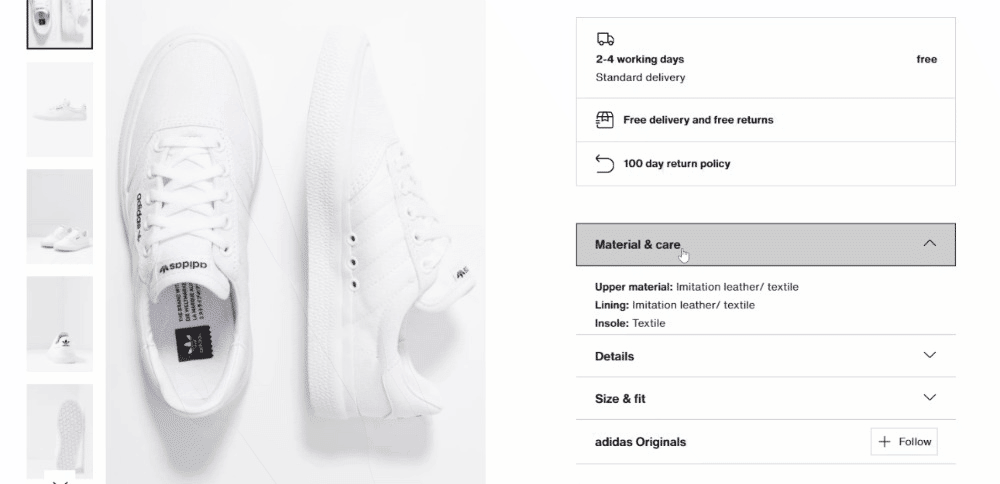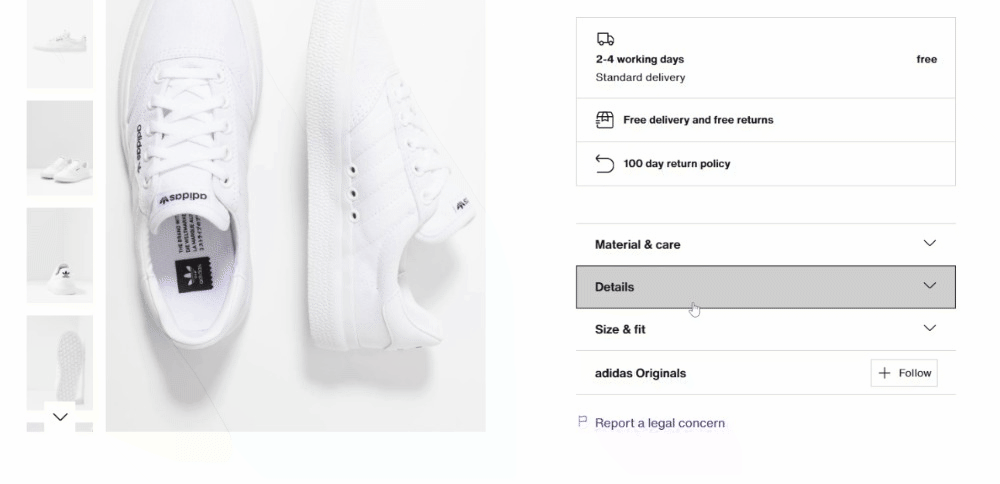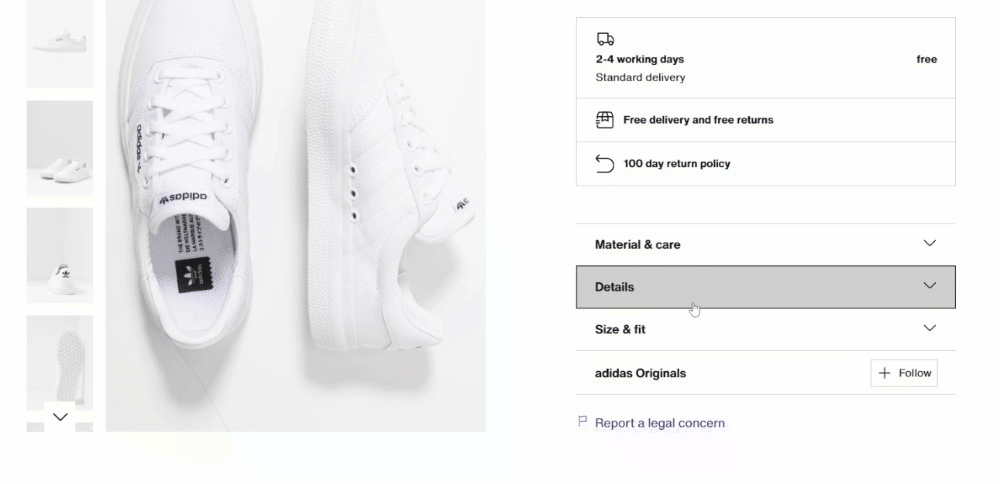
首先,关注配送信息:
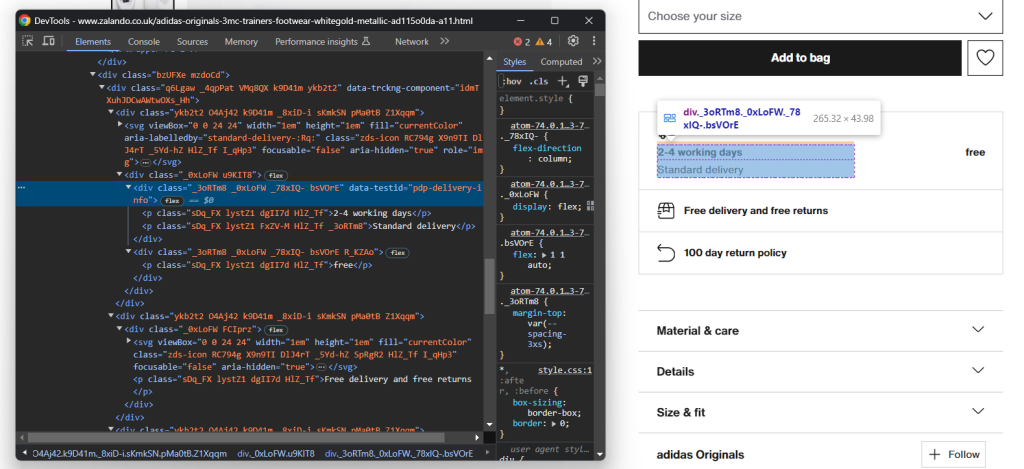
这包括三个数据字段,因此初始化一个如下所示的配送字典:
delivery = {
'time': None,
'type': None,
'cost': None,
}同样,没有简单的选择器可以选择这三个元素。您可以:
- 选择 data-testid 属性为“pdp-delivery-info”的节点。
- 移动到其父节点。
- 获取其所有后代<p>元素。
实现此逻辑并使用以下代码提取配送数据:
delivery_elements = driver
.find_element(By.CSS_SELECTOR, '[data-testid="pdp-delivery-info"]')
.find_element(By.XPATH, 'parent::*[1]')
.find_elements(By.TAG_NAME, 'p')
if len(delivery_elements) == 3:
delivery['time'] = delivery_elements[0].text
delivery['type'] = delivery_elements[1].text
delivery['cost'] = delivery_elements[2].text由于 Selenium 不提供访问节点父节点的方法,因此需要使用 parent::* XPath 表达式。
接下来,关注产品详细信息的手风琴:

这次,您可以通过定位 data-testid 属性以“pdp-accordion-”开头的节点来获取所有手风琴元素。使用以下 CSS 选择器实现:
[data-testid^="pdp-accordion-"]该部分包含多个字段,因此您需要创建一个字典来跟踪:
info = {}然后,应用上述 CSS 选择器选择产品详细信息手风琴:
info_elements = driver.find_elements(By.CSS_SELECTOR, '[data-testid^="pdp-accordion-"]')[:2]“尺寸和合身”元素不包含相关数据,因此您可以忽略它。[:2]将列表减少到前两个元素,如预期。
这些 HTML 元素是动态的,其内容仅在打开时添加到 DOM 中。因此,您需要使用 click() 方法模拟点击交互:
for info_element in info_elements:
info_element.click()
// scraping logic...
Next, programmatically populate the info object with:
info_section_name = info_element.find_element(By.CSS_SELECTOR, 'h5').text
info[info_section_name] = {}
for dt_element in info_element.find_elements(By.CSS_SELECTOR, 'dt'):
info_section_detail_name = dt_element.text.replace(':', '')
info[info_section_name][info_section_detail_name] = dt_element.find_element(By.XPATH, 'following-sibling::dd').text上述逻辑动态提取手风琴中的信息并按名称进行组织。
要更好地了解该代码的工作原理,请尝试打印 info。您将看到:
{'Material & care': {'Upper material': 'Imitation leather/ textile', 'Lining': 'Imitation leather/ textile', 'Insole': 'Textile', 'Sole': 'Synthetics', 'Padding type': 'No lining', 'Fabric': 'Canvas'}, 'Details': {'Shoe tip': 'Round', 'Heel type': 'Flat', 'Fastening': 'Laces', 'Shoe fastener': 'Laces', 'Pattern': 'Plain', 'Article number': 'AD115O0DA-A11'}}太棒了!Zalando 产品详细信息抓取完成!
步骤 7:填充产品对象
现在只需用抓取的数据填充 product 字典:
# assign the scraped data to the dictionary
product['brand'] = brand
product['name'] = name
product['price'] = price
product['original_price'] = original_price
product['discount'] = discount
product['images'] = images
product['colors'] = colors
product['delivery'] = delivery
product['info'] = info您还可以添加日志指令,以验证 Zalando 爬虫是否按预期工作:
print(job)
Run the script:
python scraper.py这将生成类似的输出:
{'brand': 'adidas Originals', 'name': '3MC UNISEX - Trainers', 'price': '£51.00', 'original_price': '£59.99', 'discount': '15%', ... }瞧!您刚刚学会了如何从 Zalando 抓取产品数据。
步骤 8:将抓取的数据导出为 JSON
目前,抓取的数据存储在 Python 字典中。将其导出为 JSON,以便于共享和读取:
with open('product.json', 'w', encoding='utf-8') as file:
json.dump(product, file, indent=4, ensure_ascii=False)以上代码段创建了一个 product.json 输出文件,并通过 open() 将其填充为 JSON 数据,通过 json.dump()。查看我们的指南,了解更多关于 如何在 Python 中解析和序列化 JSON 数据的信息。
记得添加 json 导入:
import json该包来自 Python 标准库,因此您甚至不需要手动安装它。
太棒了!您从网页中的原始产品数据开始,现在拥有了半结构化的 JSON 数据。您准备好查看完整的 Zalando 爬虫了。
步骤 9:整合所有代码
以下是 scraper.py 文件的完整代码:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
import json
service = Service()
# configure the Chrome instance
options = webdriver.ChromeOptions()
# your browser options...
driver = webdriver.Chrome(
service=service,
options=options
)
# maxime the window to avoid the responsive rendering
driver.maximize_window()
# visit the target page in the controlled browser
driver.get('https://www.zalando.co.uk/adidas-originals-3mc-trainers-footwear-whitegold-metallic-ad115o0da-a11.html')
# instantiate the object that will contain the scraped data
product = {}
# scraping logic
brand_element = driver.find_element(By.CSS_SELECTOR, 'h3')
brand = brand_element.text
name_element = driver.find_element(By.CSS_SELECTOR, 'h1')
name = name_element.text
price_elements = name_element
.find_element(By.XPATH, 'following-sibling::*[1]')
.find_elements(By.TAG_NAME, "p")
discount = None
price = None
original_price = None
if len(price_elements) >= 3:
discount = price_elements[0].text.replace(' off', '')
price = price_elements[1].text
original_price = price_elements[2].text
images = []
image_elements = driver.find_elements(By.CSS_SELECTOR, '[aria-label="Product media gallery"] li')
for image_element in image_elements:
image = image_element.find_element(By.TAG_NAME, 'img').get_attribute('src')
images.append(image)
colors = []
color_elements = driver.find_elements(By.CSS_SELECTOR, '[aria-label="Available colours"] li')
for color_element in color_elements:
color = {
'color': None,
'image': None,
'link': None
}
link_elements = color_element.find_elements(By.TAG_NAME, 'a')
if len(link_elements) > 0:
color['link'] = link_elements[0].get_attribute('href')
image_elements = color_element.find_elements(By.TAG_NAME, 'img')
if len(image_elements) > 0:
color['image'] = image_elements[0].get_attribute('src')
color['color'] = image_elements[0].get_attribute('alt')
.replace('Selected, ', '')
.replace('Unselected, ','')
.strip()
colors.append(color)
delivery = {
'time': None,
'type': None,
'cost': None,
}
delivery_elements = driver
.find_element(By.CSS_SELECTOR, '[data-testid="pdp-delivery-info"]')
.find_element(By.XPATH, 'parent::*[1]')
.find_elements(By.TAG_NAME, 'p')
if len(delivery_elements) == 3:
delivery['time'] = delivery_elements[0].text
delivery['type'] = delivery_elements[1].text
delivery['cost'] = delivery_elements[2].text
info = {}
info_elements = driver.find_elements(By.CSS_SELECTOR, '[data-testid^="pdp-accordion-"]')[:2]
for info_element in info_elements:
info_element.click()
info_section_name = info_element.find_element(By.CSS_SELECTOR, 'h5').text
info[info_section_name] = {}
for dt_element in info_element.find_elements(By.CSS_SELECTOR, 'dt'):
info_section_detail_name = dt_element.text.replace(':', '')
info[info_section_name][info_section_detail_name] = dt_element.find_element(By.XPATH, 'following-sibling::dd').text
# close the browser and free up its resources
driver.quit()
# assign the scraped data to the dictionary
product['brand'] = brand
product['name'] = name
product['price'] = price
product['original_price'] = original_price
product['discount'] = discount
product['images'] = images
product['colors'] = colors
product['delivery'] = delivery
product['info'] = info
print(product)
# export the scraped data to a JSON file
with open('product.json', 'w', encoding='utf-8') as file:
json.dump(product, file, indent=4, ensure_ascii=False)在不到 100 行代码中,您刚刚构建了一个功能齐全的 Zalando 网络爬虫来检索产品详细数据。
使用以下命令执行它:
python scraper.py等待几秒钟,脚本完成。
在抓取过程结束时,项目根文件夹中将出现一个 product.json 文件。打开它,您将看到:
{
"brand": "adidas Originals",
"name": "3MC UNISEX - Trainers",
"price": "£51.00",
"original_price": "£59.99",
"discount": "15%",
"images": [
"https://img01.ztat.net/article/spp-media-p1/637562911a7e36c28ce77c9db69b4cef/00373c35a7f94b4b84a4e070879289a2.jpg?imwidth=156",
// omitted for brevity...
"https://img01.ztat.net/article/spp-media-p1/7d4856f0e4803b759145755d10e8e6b6/521545d1286c478695901d26fcd9ed3a.jpg?imwidth=156"
],
"colors": [
{
"color": "footwear white",
"image": "https://img01.ztat.net/article/spp-media-p1/afe668d0109a3de0a5175a1b966bf0c9/c99c48c977ff429f8748f961446f79f5.jpg?imwidth=156&filter=packshot",
"link": null
},
// omitted for brevity...
{
"color": "white",
"image": "https://img01.ztat.net/article/spp-media-p1/87e6a1f18ce44e3cbd14da8f10f52dfd/bb1c3a8c409544a085c977d6b4bef937.jpg?imwidth=156&filter=packshot",
"link": "https://www.zalando.co.uk/adidas-originals-3mc-unisex-trainers-white-ad115o0da-a16.html"
}
],
"delivery": {
"time": "2-4 working days",
"type": "Standard delivery",
"cost": "free"
},
"info": {
"Material & care": {
"Upper material": "Imitation leather/ textile",
"Lining": "Imitation leather/ textile",
"Insole": "Textile",
"Sole": "Synthetics",
"Padding type": "No lining",
"Fabric": "Canvas"
},
"Details": {
"Shoe tip": "Round",
"Heel type": "Flat",
"Fastening": "Laces",
"Shoe fastener": "Laces",
"Pattern": "Plain",
"Article number": "AD115O0DA-A11"
}
}
}恭喜!您刚刚学会了如何在 Python 中抓取 Zalando 数据!
结论
在本教程中,您了解了为什么 Zalando 是一个很好的电商网站以及如何从中提取数据。这里,您看到了如何构建一个 Zalando 爬虫,自动从产品页面中检索数据。
如本文所示,抓取 Zalando 并不是最简单的任务,至少有三个原因:
- 该站点实施了一些反抓取措施,可能会阻止您的脚本。
- 网页包含随机的 CSS 类。
- 每个产品页面都有特定的结构,并可能涉及不同的信息。
为了避免第一个问题并忘记被阻止,请尝试我们的新解决方案!Scraping Browser 是一个可控的浏览器,它会自动处理验证码、指纹、自动重试等问题。然而,您仍然需要编写代码并不断维护它。使用开箱即用的解决方案解决其余两个问题,查看我们的 Zalando 爬虫!
不确定哪种工具最适合您?与我们的一位数据专家交谈。



技术写作
 5.5 years experience
5.5 years experience
Antonello是一名软件工程师,但他更喜欢称自己为技术传教士。通过写作传播知识是他的使命。




