
Node.js已经成为构建网页抓取工具的强大选项,既方便客户端开发,也适合服务器端开发。其丰富的库目录使得使用Node.js进行网页抓取变得轻而易举。在本文中,我们将重点介绍cheerio,并探讨其高效的网页抓取能力。
Cheerio是一个快速且灵活的库,用于解析和操作HTML和XML文档。它实现了一部分jQuery功能,这意味着熟悉jQuery的人会对cheerio的语法感到非常熟悉。在底层,cheerio使用parse5和可选的htmlparser2库来解析HTML和XML文档。
在本文中,您将创建一个使用cheerio的项目,并学习如何从动态网站和静态网页中抓取数据。
使用cheerio进行网页抓取
在开始本教程之前,请确保您的系统已安装Node.js。如果还没有,您可以使用官方文档进行安装。
安装Node.js后,创建一个名为cheerio-demo的目录,并进入该目录:
mkdir cheerio-demo && cd cheerio-demo然后在目录中初始化一个npm项目:
npm init -ynpm install cheerio axios创建一个名为index.js的文件,您将在其中编写本教程的代码。然后用您喜欢的编辑器打开此文件开始编写代码。
首先需要导入所需的模块:
const axios = require("axios");
const cheerio = require("cheerio");在本教程中,您将抓取Books to Scrape页面,这是一个用于测试网页抓取器的公共沙箱。首先,您将使用Axios对网页进行GET请求,代码如下:
axios.get("https://books.toscrape.com/").then((response) => {
});回调中的response对象包含网页的HTML代码在data属性中。需要将此HTML传递给cheerio模块的load函数。此函数返回一个CheerioAPI实例,该实例将在余下的代码中用于访问和操作DOM。请注意,CheerioAPI实例存储在一个名为$的变量中,这是对jQuery语法的致敬:
axios.get("https://books.toscrape.com/").then((response) => {
const $ = cheerio.load(response.data);
});查找元素
cheerio支持使用CSS和XPath选择器从页面中选择元素。如果您使用过jQuery,您会发现语法很熟悉—将CSS选择器传递给$()函数。使用这种语法查找并提取Books to Scrape网站首页上的信息。
访问https://books.toscrape.com/并打开开发者控制台。在检查元素标签中,您将了解页面的HTML结构。在这种情况下,您可以看到所有关于书籍的信息都包含在类为product-pod的article标签中:
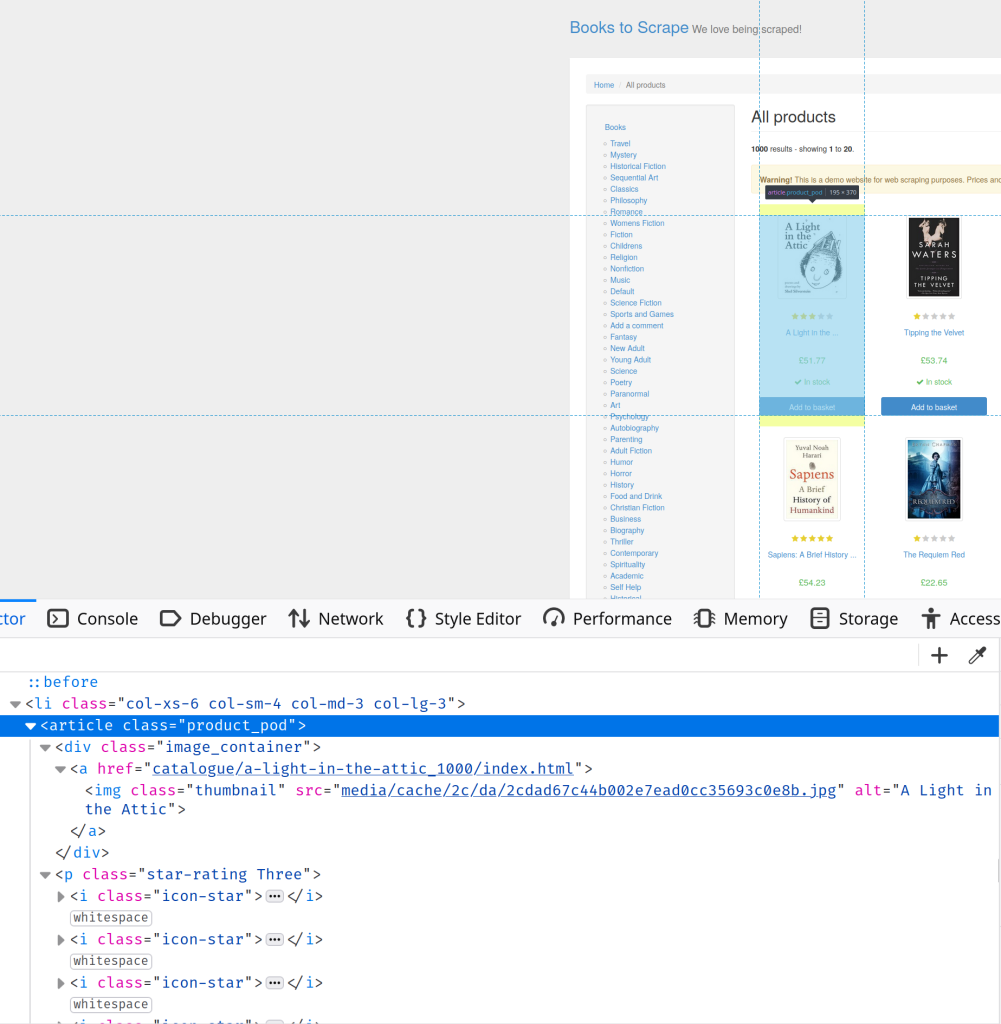
要选择书籍,您需要使用article.product_pod CSS选择器,如下所示:
$("article.product_pod");此函数返回与选择器匹配的所有元素的列表。您可以使用each方法遍历列表:
$("article.product_pod").each( (i, element) => {
});在循环中,您可以使用element变量提取数据。
尝试提取首页书籍的标题。回到检查元素控制台,您可以看到标题的存储方式:

您会发现需要找到h3,它是element变量的子元素。在h3内,有一个包含书名的a元素。您可以使用find方法和CSS选择器找到一个元素的子元素,但最初需要通过$将element转换为Cheerio实例:
$("article.product_pod").each( (i, element) => {
const titleH3 = $(element).find("h3");
});现在,您可以在titleH3内找到a:
$("article.product_pod").each( (i, element) => {
const titleH3 = $(element).find("h3");
const title = titleH3.find("a");
});注意:
titleH3已经是Cheerio实例,因此不需要再通过$转换。
提取文本
一旦选择了一个元素,您可以使用text方法获取该元素的文本。
修改上一个例子,通过调用find方法的结果上的text方法来提取书名:
$("article.product_pod").each( (i, element) => {
const titleH3 = $(element).find("h3");
const title = titleH3.find("a").text();
console.log(title);
});完整的代码应如下所示:
const axios = require("axios");
const cheerio = require("cheerio");
axios.get("https://books.toscrape.com/").then((response) => {
const $ = cheerio.load(response.data);
$("article.product_pod").each( (i, element) => {
const titleH3 = $(element).find("h3");
const title = titleH3.find("a").text();
console.log(title);
});
});用node index.js运行代码,您应该会看到以下输出:
A Light in the ...
Tipping the Velvet
Soumission
Sharp Objects
Sapiens: A Brief History ...
The Requiem Red
The Dirty Little Secrets ...
The Coming Woman: A ...
The Boys in the ...
The Black Maria
Starving Hearts (Triangular Trade ...
Shakespeare's Sonnets
Set Me Free
Scott Pilgrim's Precious Little ...
Rip it Up and ...
Our Band Could Be ...
Olio
Mesaerion: The Best Science ...
Libertarianism for Beginners
It's Only the Himalayas导航DOM:查找子元素和兄弟元素
提取标题后,是时候提取每本书的价格和可用性了。检查元素显示,价格和可用性都存储在一个类为product_price的div中。您可以使用.product_price CSS选择器选择这个div,但由于您已经了解了CSS选择器,接下来将讨论另一种方法:

注意:
div是您之前选择的titleH3的兄弟元素。通过调用titleH3的next方法,您可以选择下一个兄弟元素:
const priceDiv = titleH3.next();您已经看到,可以使用find方法基于CSS选择器查找一个元素的子元素。也可以使用children方法选择所有子元素,然后使用eq方法选择特定的子元素。这相当于nth-child CSS选择器。
在这种情况下,价格是priceDiv的第一个子元素,而可用性是priceDiv的第二个子元素。这意味着您可以使用priceDiv.children().eq(0)和priceDiv.children().eq(1)分别选择它们。这样做并打印价格和可用性:
$("article.product_pod").each( (i, element) => {
const titleH3 = $(element).find("h3");
const title = titleH3.find("a").text();
const priceDiv = titleH3.next();
const price = priceDiv.children().eq(0).text().trim();
const availability = priceDiv.children().eq(1).text().trim();
console.log(title, price, availability);
});现在,运行代码将显示以下输出:
A Light in the ... £51.77 In stock
Tipping the Velvet £53.74 In stock
Soumission £50.10 In stock
Sharp Objects £47.82 In stock
Sapiens: A Brief History ... £54.23 In stock
The Requiem Red £22.65 In stock
The Dirty Little Secrets ... £33.34 In stock
The Coming Woman: A ... £17.93 In stock
The Boys in the ... £22.60 In stock
The Black Maria £52.15 In stock
Starving Hearts (Triangular Trade ... £13.99 In stock
Shakespeare's Sonnets £20.66 In stock
Set Me Free £17.46 In stock
Scott Pilgrim's Precious Little ... £52.29 In stock
Rip it Up and ... £35.02 In stock
Our Band Could Be ... £57.25 In stock
Olio £23.88 In stock
Mesaerion: The Best Science ... £37.59 In stock
Libertarianism for Beginners £51.33 In stock
It's Only the Himalayas £45.17 In stock访问属性
到目前为止,您已经导航了DOM并从元素中提取了文本。还可以使用cheerio从元素中提取属性,这是您将在本节中进行的操作。在这里,您将通过读取元素的类列表来提取书籍的评分。
书籍的评分具有有趣的结构。评分包含在一个p标签中。每个p标签都有五颗星,但根据p元素的类名使用CSS着色。例如,在一个类为star-rating.Four的p中,前四颗星被涂成黄色,表示四星级评分:

要提取书籍的评分,您需要提取p元素的类名。第一步是找到包含评分的段落:
const ratingP = $(element).find("p.star-rating");通过将属性名称传递给attr方法,您可以读取元素的属性。在这种情况下,您需要读取类列表,代码如下所示:
const starRating = ratingP.attr('class');类列表的形式为:star-rating X,其中X是One、Two、Three、Four和Five之一。这意味着您需要按空格分割类 列表并取第二个元素。以下代码完成了这一操作,并将文本评分转换为数字评分:
const rating = { One: 1, Two: 2, Three: 3, Four: 4, Five: 5 }[starRating.split(" ")[1]];如果将所有内容放在一起,代码将如下所示:
$("article.product_pod").each( (i, element) => {
const titleH3 = $(element).find("h3");
const title = titleH3.find("a").text();
const priceDiv = titleH3.next();
const price = priceDiv.children().eq(0).text().trim();
const availability = priceDiv.children().eq(1).text().trim();
const ratingP = $(element).find("p.star-rating");
const starRating = ratingP.attr('class');
const rating = { One: 1, Two: 2, Three: 3, Four: 4, Five: 5 }[starRating.split(" ")[1]];
console.log(title, price, availability, rating);
});输出如下所示:
A Light in the ... £51.77 In stock 3
Tipping the Velvet £53.74 In stock 1
Soumission £50.10 In stock 1
Sharp Objects £47.82 In stock 4
Sapiens: A Brief History ... £54.23 In stock 5
The Requiem Red £22.65 In stock 1
The Dirty Little Secrets ... £33.34 In stock 4
The Coming Woman: A ... £17.93 In stock 3
The Boys in the ... £22.60 In stock 4
The Black Maria £52.15 In stock 1
Starving Hearts (Triangular Trade ... £13.99 In stock 2
Shakespeare's Sonnets £20.66 In stock 4
Set Me Free £17.46 In stock 5
Scott Pilgrim's Precious Little ... £52.29 In stock 5
Rip it Up and ... £35.02 In stock 5
Our Band Could Be ... £57.25 In stock 3
Olio £23.88 In stock 1
Mesaerion: The Best Science ... £37.59 In stock 1
Libertarianism for Beginners £51.33 In stock 2
It's Only the Himalayas £45.17 In stock 2保存数据
从网页抓取数据后,通常需要保存这些数据。保存的方法有很多种,例如保存到文件、保存到数据库或将其传输到数据处理管道。在本节中,您将学习最简单的方法—将数据保存为CSV文件。
为此,请安装node-csv包:
npm install csv在index.js中,导入fs和csv-stringify模块:
const fs = require("fs");
const { stringify } = require("csv-stringify");要写入本地文件,需要创建一个WriteStream:
const filename = "scraped_data.csv";
const writableStream = fs.createWriteStream(filename);声明列名,这些列名将作为CSV文件的标题添加:
const columns = [
"title",
"rating",
"price",
"availability"
];用列名创建一个字符串化器:
const stringifier = stringify({ header: true, columns: columns });在each函数内,使用stringifier写入数据:
$("article.product_pod").each( (i, element) => {
...
const data = { title, rating, price, availability };
stringifier.write(data);
});最后,在each函数外,需要将stringifier的内容写入writableStream变量:
stringifier.pipe(writableStream);此时,您的代码应如下所示:
const axios = require("axios");
const cheerio = require("cheerio");
const fs = require("fs");
const { stringify } = require("csv-stringify");
const filename = "scraped_data.csv";
const writableStream = fs.createWriteStream(filename);
const columns = [
"title",
"rating",
"price",
"availability"
];
const stringifier = stringify({ header: true, columns: columns });
axios.get("https://books.toscrape.com/").then((response) => {
const $ = cheerio.load(response.data);
$("article.product_pod").each( (i, element) => {
const titleH3 = $(element).find("h3");
const title = titleH3.find("a").text();
const priceDiv = titleH3.next();
const price = priceDiv.children().eq(0).text().trim();
const availability = priceDiv.children().eq(1).text().trim();
const ratingP = $(element).find("p.star-rating");
const starRating = ratingP.attr('class');
const rating = { One: 1, Two: 2, Three: 3, Four: 4, Five: 5 }[starRating.split(" ")[1]];
console.log(title, price, availability, rating);
const data = { title, rating, price, availability };
stringifier.write(data);
});
stringifier.pipe(writableStream);
});运行代码,应该会创建一个包含抓取数据的scraped_data.csv文件:
title,rating,price,availability
A Light in the ...,3,£51.77,In stock
Tipping the Velvet,1,£53.74,In stock
Soumission,1,£50.10,In stock
Sharp Objects,4,£47.82,In stock
Sapiens: A Brief History ...,5,£54.23,In stock
The Requiem Red,1,£22.65,In stock
The Dirty Little Secrets ...,4,£33.34,In stock
The Coming Woman: A ...,3,£17.93,In stock
The Boys in the ...,4,£22.60,In stock
The Black Maria,1,£52.15,In stock
Starving Hearts (Triangular Trade ...,2,£13.99,In stock
Shakespeare's Sonnets,4,£20.66,In stock
Set Me Free,5,£17.46,In stock
Scott Pilgrim's Precious Little ...,5,£52.29,In stock
Rip it Up and ...,5,£35.02,In stock
Our Band Could Be ...,3,£57.25,In stock
Olio,1,£23.88,In stock
Mesaerion: The Best Science ...,1,£37.59,In stock
Libertarianism for Beginners,2,£51.33,In stock
It's Only the Himalayas,2,£45.17,In stock结论
正如您在这里看到的,cheerio库通过其类似jQuery的语法和极快的操作使得网页抓取变得容易。在本文中,您学习了如何:
- 使用cheerio加载和解析HTML网页
- 使用CSS选择器查找元素
- 从元素中提取数据
- 导航DOM
- 将抓取的数据保存到本地文件存储中
您可以在GitHub上找到完整代码。
然而,cheerio只是一个HTML解析器,因此无法执行JavaScript代码。这意味着您不能使用它抓取动态网页和单页应用程序。要抓取这些网页,您需要超 越cheerio,寻找像Selenium或Playwright这样复杂的工具。这就是Bright Data的用武之地。Bright Data广泛的网页抓取解决方案包括Selenium抓取浏览器和Playwright抓取浏览器。要了解更多关于这些产品的信息,您可以访问我们的抓取浏览器文档。







