

旅游相关网站,尤其是 Airbnb,都是丰富的有洞察力的数据来源。无论您是想深入研究价格动态、验证住宿可用性,还是获取各种地点的评论,网络爬虫都可以是一个非常有帮助的工具。
本教程旨在通过手动爬取公共数据,特别是使用 Python 爬取 Airbnb,带您一步一步地完成整个过程。您收集的数据可以打开一个新的可能性世界——从分析市场趋势和制定竞争性定价策略,到对客人评论进行情感分析,甚至构建您自己的推荐系统。
除了手动爬取之外,您还将了解 Bright Data 提供的高级解决方案。他们的最先进工具,包括专业代理和爬虫友好浏览器,旨在使数据提取过程简单高效。
如何爬取 Airbnb
在我们深入探讨之前,建议您具备一些基本的网页爬虫和 HTML 知识。此外,如果您还没有在电脑上安装 Python,请确保安装。官方 Python 指南提供了详细的安装说明。如果您已经安装了 Python,请确保其更新到 Python 3.7.9 或更新版本。
安装 Python 后,启动您的终端或命令行界面,并通过以下命令创建一个新的项目目录:
mkdir airbnb-scraper && cd airbnb-scraper创建新项目目录后,您需要设置一些用于网络爬虫的额外库。特别是,您将使用 Requests,一个在 Python 中启用 HTTP 请求的库;pandas,一个专门用于数据操作和分析的强大库;Beautiful Soup (BS4),用于解析 HTML 内容;以及Playwright,用于自动化基于浏览器的任务。
要安装这些库,请打开终端或 shell 并执行以下命令:
pip3 install beautifulsoup4
pip3 install requests
pip3 install pandas
pip3 install playwright
playwright install确保安装过程没有错误,然后继续本教程的下一步。
注意: 最后一条命令(即
playwright install)是必要的,用于安装浏览器二进制文件。
Airbnb 的结构和数据对象
在您开始爬取 Airbnb 之前,了解其结构至关重要。Airbnb 的主页提供了一个用户友好的搜索栏,允许您查找住宿选项、体验甚至冒险。
输入搜索条件后,结果以列表形式呈现,显示物业的名称、价格、位置、评分和其他相关信息。值得注意的是,这些搜索结果可以根据各种参数进行过滤,例如价格范围、物业类型和可用日期。
如果您想要更多的搜索结果,可以利用页面底部的分页按钮。每页通常包含许多列表,允许您浏览更多的物业。页面顶部的过滤器提供了根据您的需求和偏好优化搜索的机会。
为了帮助您了解 Airbnb 网站的 HTML 结构,请按照以下步骤操作:
- 导航到 Airbnb 网站。
- 在搜索栏中输入所需的地点、日期范围和客人数,并按 Enter。
- 通过右键单击一个物业卡片并选择 Inspect,启动浏览器的开发者工具。
- 探索 HTML 布局,找出包含您感兴趣的数据的标签和属性。
爬取 Airbnb 列表
现在您对 Airbnb 的结构有了更多了解,设置 Playwright 以导航到 Airbnb 列表并爬取数据。在本例中,您将收集列表的名称、位置、价格详情、所有者信息和评论。
创建一个新的 Python 脚本,命名为 airbnb_scraper.py,并添加以下代码:
import asyncio
from playwright.async_api import async_playwright
import pandas as pd
async def scrape_airbnb():
async with async_playwright() as pw:
# Launch new browser
browser = await pw.chromium.launch(headless=False)
page = await browser.new_page()
# Go to Airbnb URL
await page.goto('https://www.airbnb.com/s/homes', timeout=600000)
# Wait for the listings to load
await page.wait_for_selector('div.g1qv1ctd.c1v0rf5q.dir.dir-ltr')
# Extract information
results = []
listings = await page.query_selector_all('div.g1qv1ctd.c1v0rf5q.dir.dir-ltr')
for listing in listings:
result = {}
# Property name
name_element = await listing.query_selector('div[data-testid="listing-card-title"]')
if name_element:
result['property_name'] = await page.evaluate("(el) => el.textContent", name_element)
else:
result['property_name'] = 'N/A'
# Location
location_element = await listing.query_selector('div[data-testid="listing-card-subtitle"]')
result['location'] = await location_element.inner_text() if location_element else 'N/A'
# Price
price_element = await listing.query_selector('div._1jo4hgw')
result['price'] = await price_element.inner_text() if price_element else 'N/A'
results.append(result)
# Close browser
await browser.close()
return results
# Run the scraper and save results to a CSV file
results = asyncio.run(scrape_airbnb())
df = pd.DataFrame(results)
df.to_csv('airbnb_listings.csv', index=False)函数 scrape_airbnb() 异步打开一个浏览器,访问 Airbnb 的房源页面,并从每个房源中收集物业名称、位置和价格等信息。如果未找到元素,则标记为 N/A。处理完成后,收集的数据存储在一个 pandas DataFrame 中,并保存为名为 airbnb_listings.csv的 CSV 文件。
要运行脚本,请在终端或 shell 中运行 python3 airbnb_scraper.py。您的 CSV 文件应如下所示:
property_name,location,price
"Brand bei Bludenz, Austria",343 kilometers away,"€ 2,047
night"
"Saint-Nabord, France",281 kilometers away,"€ 315
night"
"Kappl, Austria",362 kilometers away,"€ 1,090
night"
"Fraisans, France",394 kilometers away,"€ 181
night"
"Lanitz-Hassel-Tal, Germany",239 kilometers away,"€ 185
night"
"Hohentannen, Switzerland",291 kilometers away,"€ 189
Night"
…output omitted…通过 Bright Data 代理增强网络爬虫
爬取网站有时会遇到挑战,例如 IP 禁令和地理封锁。此时 Bright Data 代理 可以派上用场,使您能够绕过这些障碍,增强您的数据爬取效果。
在运行前面的脚本几次后,您可能会注意到不再接收数据。这可能是因为您的 IP 被 Airbnb 检测到并阻止您爬取其网站。
为应对相关挑战,实施代理以进行爬取是一种实用的方法。以下是使用代理进行网络爬虫的一些优势:
- 地理封锁 根据用户的地理位置限制访问内容。代理可以通过提供特定位置的 IP 地址帮助绕过 IP 限制。
- IP 轮 换 涉及 轮换 IP 地址,以防止您的爬虫被网站禁止。这在您需要对单个网站进行大量请求时特别有用。
- 负载均衡 确保网络或应用流量分布在多个资源上,防止任何单一组件成为瓶颈,并在发生故障时提供冗余。
如何将 Bright Data 代理集成到您的 Python 脚本中
有了上述好处,您可以明白为什么要在 Python 脚本中集成 Bright Data 的代理。好消息是,这很容易做到。只需设置一个 Bright Data 账户,配置您的代理设置,然后在代码中实现这些设置。
首先,您需要创建一个 Bright Data 账户。要创建账户,请访问 Bright Data 网站,并选择 开始免费试用;然后按指示操作。
登录您的 Bright Data 账户,然后单击左侧导航栏中的信用卡图标以访问 Billing。在此,您需要输入首选的支付方式以激活您的账户:
接下来,单击左侧导航栏中的图钉图标以访问 代理和爬取基础设施 页面;然后单击 添加 > 住宅代理:
为您的代理命名(如 residential_proxy1),并在 IP 类型下使用 共享选项。然后单击 添加:
创建住宅代理后,请注意 访问参数,因为您将在代码中使用这些详细信息:
要使用 Bright Data 住宅代理,您需要为浏览器设置证书。可以在Bright Data 教程中找到有关安装证书的说明。
创建一个新的 airbnb_scraping_proxy.py Python 脚本,并添加以下代码:
from playwright.sync_api import sync_playwright
import pandas as pd
def run(playwright):
browser = playwright.chromium.launch()
context = browser.new_context()
# Set up proxy
proxy_username='YOUR_BRIGHTDATA_PROXY_USERNAME'
proxy_password='YOUR_BRIGHTDATA_PROXY_PASSWORD'
proxy_host = 'YOUR_BRIGHTDATA_PROXY_HOST'
proxy_auth=f'{proxy_username}:{proxy_password}'
proxy_server = f'http://{proxy_auth}@{proxy_host}'
context = browser.new_context(proxy={
'server': proxy_server,
'username': proxy_username,
'password': proxy_password
})
page = context.new_page()
page.goto('https://www.airbnb.com/s/homes')
# Wait for the page to load
page.wait_for_load_state("networkidle")
# Extract the data
results = page.eval_on_selector_all('div.g1qv1ctd.c1v0rf5q.dir.dir-ltr', '''(listings) => {
return listings.map(listing => {
return {
property_name: listing.querySelector('div[data-testid="listing-card-title"]')?.innerText || 'N/A',
location: listing.querySelector('div[data-testid="listing-card-subtitle"]')?.innerText || 'N/A',
price: listing.querySelector('div._1jo4hgw')?.innerText || 'N/A'
}
})
}''')
df = pd.DataFrame(results)
df.to_csv('airbnb_listings_scraping_proxy.csv', index=False)
# Close the browser
browser.close()
with sync_playwright() as playwright:
run(playwright)此代码使用 Playwright 库启动带有特定代理服务器的 Chromium 浏览器。它导航到 Airbnb 的主页;从列表中提取物业名称、位置和价格等详细信息;并使用 pandas 将数据保存到 CSV 文件中。数据提取后,浏览器关闭。
注意: 将
proxy_username、proxy_password和proxy_host替换为您的 Bright Data 访问参数。
在终端或 shell 中运行脚本:
python3 airbnb_scraping_proxy.py爬取的数据将保存到名为 airbnb_listings_scraping_proxy.csv 的 CSV 文件中。文件内容应如下所示:
property_name,location,price
"Sithonia, Greece",Lagomandra,"$3,305
night"
"Apraos, Greece","1,080 kilometers away","$237
night"
"Magnisia, Greece",Milopotamos Paralympic,"$200
night"
"Vourvourou, Greece",861 kilometers away,"$357
night"
"Rovies, Greece","1,019 kilometers away","$1,077
night"
…output omitted…使用 Bright Data 的爬虫浏览器爬取 Airbnb
使用 Bright Data 爬虫浏览器可以使爬取过程更高效。此工具专为网络爬虫设计,提供多种好处,包括自动解除封锁、轻松扩展和躲避反爬虫软件。
前往 Bright Data 仪表板,单击图钉图标以访问 代理和爬取基础设施 页面;然后单击 添加 > 爬虫浏览器:
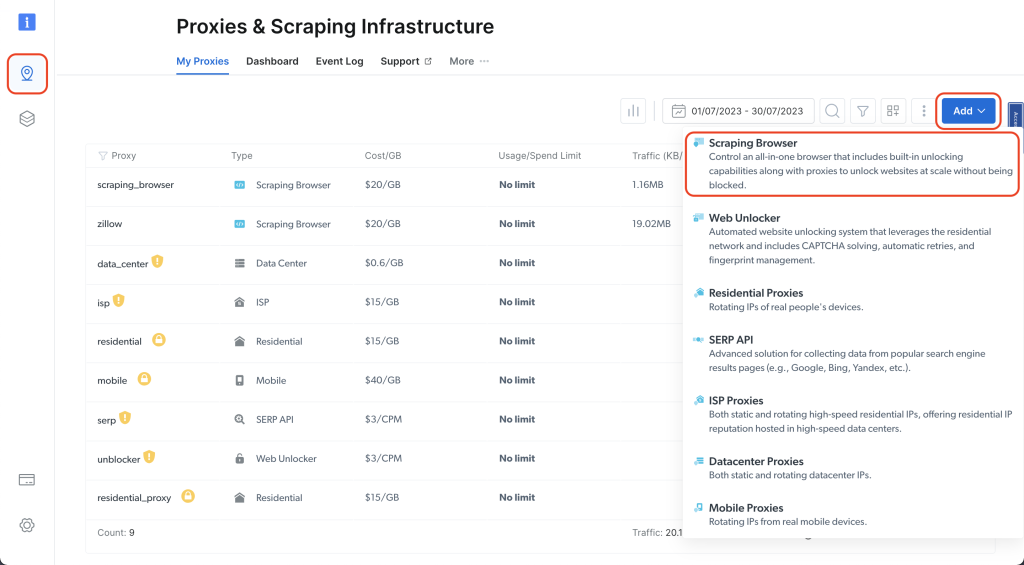
为其命名(如 scraping_browser),然后单击 添加:
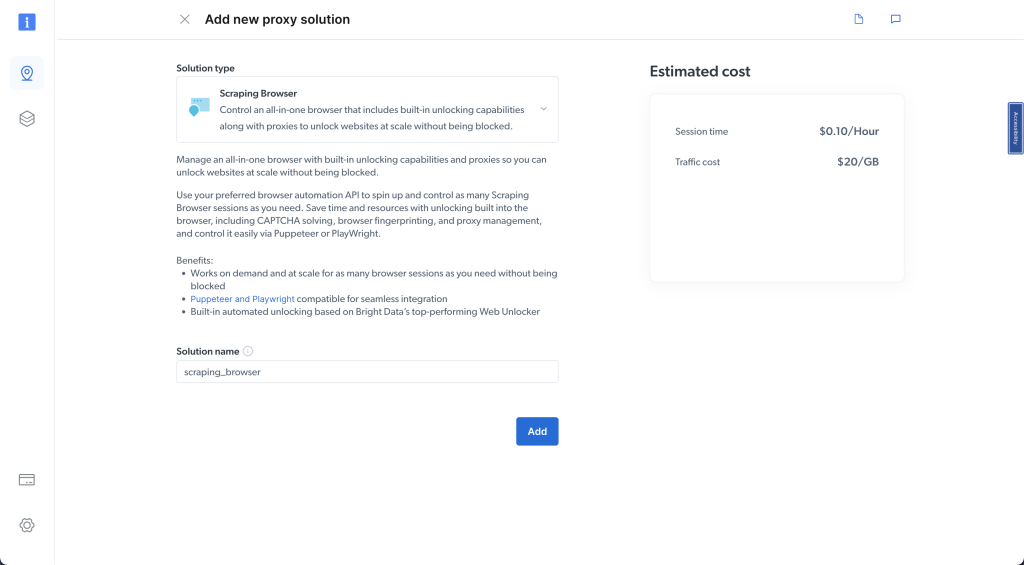
接下来,选择 访问参数 并记录您的用户名、主机和密码——这些详细信息将在本指南的后续部分使用:
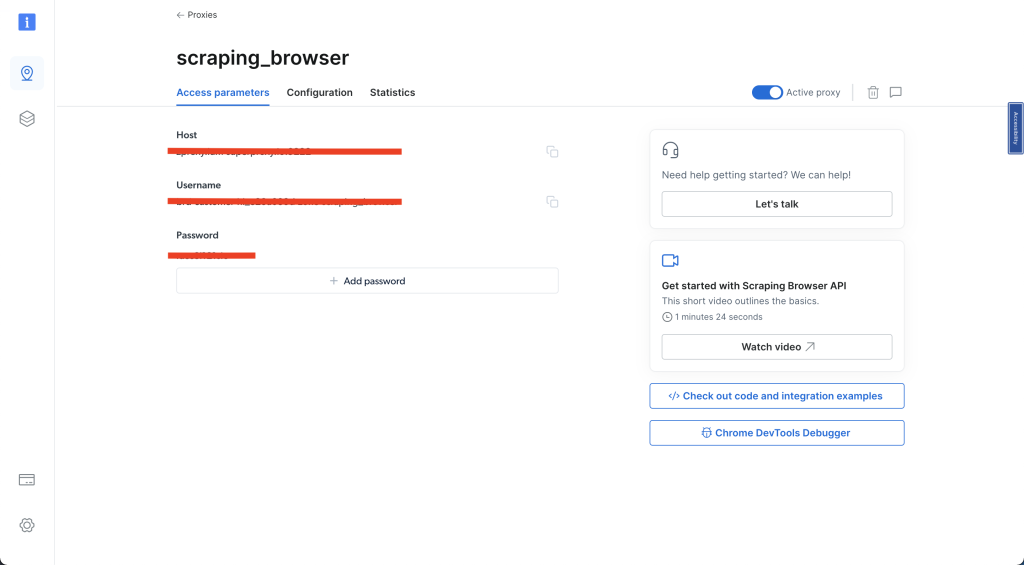
完成这些步骤后,创建一个名为 airbnb_scraping_brower.py的新 Python 脚本,并添加以下代码:
import asyncio
from playwright.async_api import async_playwright
from bs4 import BeautifulSoup
import pandas as pd
username='YOUR_BRIGHTDATA_USERNAME'
password='YOUR_BRIGHTDATA_PASSWORD'
auth=f'{username}:{password}'
host = 'YOUR_BRIGHTDATA_HOST'
browser_url = f'wss://{auth}@{host}'
async def scrape_airbnb():
async with async_playwright() as pw:
# Launch new browser
print('connecting')
browser = await pw.chromium.connect_over_cdp(browser_url)
print('connected')
page = await browser.new_page()
# Go to Airbnb URL
await page.goto('https://www.airbnb.com/s/homes', timeout=120000)
print('done, evaluating')
# Get the entire HTML content
html_content = await page.evaluate('()=>document.documentElement.outerHTML')
# Parse the HTML with Beautiful Soup
soup = BeautifulSoup(html_content, 'html.parser')
# Extract information
results = []
listings = soup.select('div.g1qv1ctd.c1v0rf5q.dir.dir-ltr')
for listing in listings:
result = {}
# Property name
name_element = listing.select_one('div[data-testid="listing-card-title"]')
result['property_name'] = name_element.text if name_element else 'N/A'
# Location
location_element = listing.select_one('div[data-testid="listing-card-subtitle"]')
result['location'] = location_element.text if location_element else 'N/A'
# Price
price_element = listing.select_one('div._1jo4hgw')
result['price'] = price_element.text if price_element else 'N/A'
results.append(result)
# Close browser
await browser.close()
return results
# Run the scraper and save results to a CSV file
results = asyncio.run(scrape_airbnb())
df = pd.DataFrame(results)
df.to_csv('airbnb_listings_scraping_browser.csv', index=False)此代码使用 Bright Data 代理连接到 Chromium 浏览器并爬取 Airbnb 网站的物业详情(如名称、位置和价格)。获取的数据存储在一个列表中,然后保存到 DataFrame 中,并导出为名为 airbnb_listings_scraping_browser.csv的 CSV 文件。
注意: 请记得将
username、password和host替换为您的 Bright Data 访问参数。
从终端或 shell 运行代码:
python3 airbnb_scraping_browser.py您应看到项目中创建了一个名为 airbnb_listings_scraping_browser.csv的 CSV 文件。文件内容应如下所示:
property_name,location,price
"Benton Harbor, Michigan",Round Lake,"$514
night"
"Pleasant Prairie, Wisconsin",Lake Michigan,"$366
night"
"New Buffalo, Michigan",Lake Michigan,"$2,486
night"
"Fox Lake, Illinois",Nippersink Lake,"$199
night"
"Salem, Wisconsin",Hooker Lake,"$880
night"
…output omitted…现在,爬取单个列表相关的数据。创建一个新的 Python 脚本,命名为 airbnb_scraping_single_listing.py,并添加以下代码:
import asyncio
from playwright.async_api import async_playwright
from bs4 import BeautifulSoup
import pandas as pd
username='YOUR_BRIGHTDATA_USERNAME'
password='YOUR_BRIGHTDATA_PASSWORD'
auth=f'{username}:{password}'
host = 'YOUR_BRIGHTDATA_HOST'
browser_url = f'wss://{auth}@{host}'
async def scrape_airbnb_listing():
async with async_playwright() as pw:
# Launch new browser
print('connecting')
browser = await pw.chromium.connect_over_cdp(browser_url)
print('connected')
page = await browser.new_page()
# Go to Airbnb URL
await page.goto('https://www.airbnb.com/rooms/26300485', timeout=120000)
print('done, evaluating')
# Wait for content to load
await page.wait_for_selector('div.tq51prx.dir.dir-ltr h2')
# Get the entire HTML content
html_content = await page.evaluate('()=>document.documentElement.outerHTML')
# Parse the HTML with Beautiful Soup
soup = BeautifulSoup(html_content, 'html.parser')
# Extract host name
host_div = soup.select_one('div.tq51prx.dir.dir-ltr h2')
host_name = host_div.text.split("hosted by ")[-1] if host_div else 'N/A'
print(f'Host name: {host_name}')
# Extract reviews
reviews_span = soup.select_one('span._s65ijh7 button')
reviews = reviews_span.text.split(" ")[0] if reviews_span else 'N/A'
print(f'Reviews: {reviews}')
# Close browser
await browser.close()
return {
'host_name': host_name,
'reviews': reviews,
}
# Run the scraper and save results to a CSV file
results = asyncio.run(scrape_airbnb_listing())
df = pd.DataFrame([results]) # results is now a dictionary
df.to_csv('scrape_airbnb_listing.csv', index=False)在此代码中,您导航到所需的列表 URL,提取 HTML 内容,并使用Beautiful Soup解析以检索主机名和评论数量,最后使用 pandas 将提取的详细信息保存到 CSV 文件。
从终端或 shell 运行代码:
python3 airbnb_scraping_single_listing.py您应在项目中看到一个名为 scrape_airbnb_listing.csv的新 CSV 文件。文件内容应如下所示:
host_name,reviews
Amelia,88本教程的所有代码都可以在 此 GitHub 仓库中找到。
使用 Bright Data 爬虫浏览器的好处
选择 Bright Data 的爬虫浏览器而不是本地 Chromium 实例有几个原因。以下是其中一些原因:
- 自动解除封锁: Bright Data 爬虫浏览器自动处理验证码、被阻止的页面和其他网站用来阻止爬虫的挑战。这大大减少了爬虫被封锁的可能性。
- 轻松扩展: Bright Data 的解决方案设计为易于扩展,允许您同时从大量网页收集数据。
- 躲避反爬虫软件: 现代网站使用复杂的反爬虫系统。Bright Data 爬虫浏览器可以成功模仿人类行为,以躲避这些检测算法。
此外,如果手动爬取数据或设置脚本听起来过于耗时或复杂,Bright Data 的定制数据集是一个很好的替代方案。他们提供一个Airbnb 数据集,其中包含 Airbnb 物业的信息,您可以在不进行任何爬取的情况下访问和分析这些信息。
要查看数据集,请单击左侧导航菜单中的 Web 数据,然后选择 数据集市场,并搜索 Airbnb。单击 查看数据集。在此页面上,您可以应用过滤器并购买所需的任何数据。根据您想要的记录数量付款:
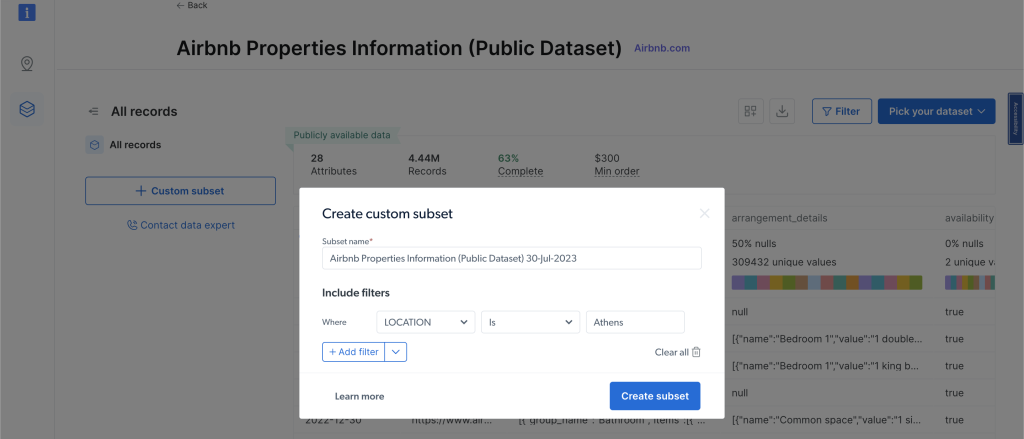
结论
在本教程中,您学习了如何使用 Python 从 Airbnb 列表中提取数据,并看到了 Bright Data 的工具(如代理和爬虫浏览器)如何使这项工作更加轻松。
Bright Data 提供了一套工具,可以帮助您快速轻松地从任何网站(不仅仅是 Airbnb)收集数据。这些工具将复杂的网络爬虫任务变得简单,节省了您的时间和精力。不确定需要哪种产品?与 Bright Data 的网络数据专家交谈,以找到适合您的数据需求的解决方案。



