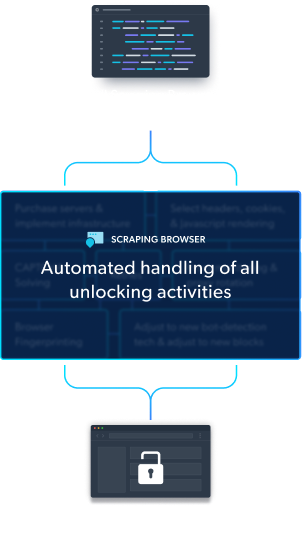
Everything you need for scraping at scale, in one automated browser
Meet the world’s only automated browser with built-in website unblocking automation
![]()
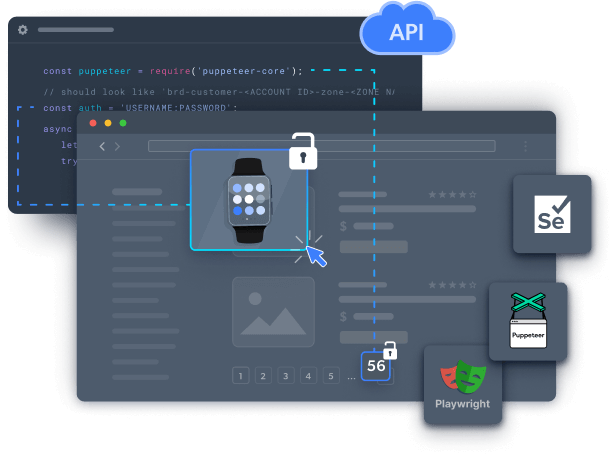
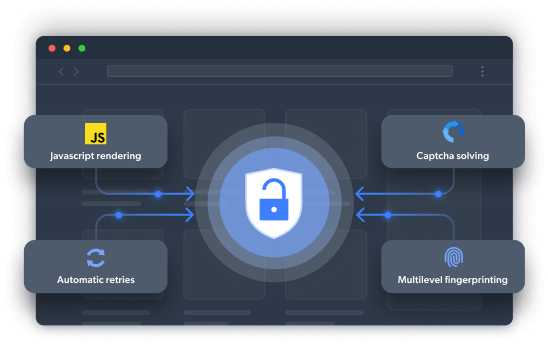


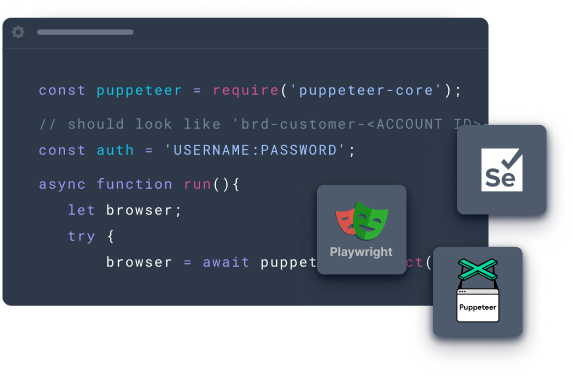
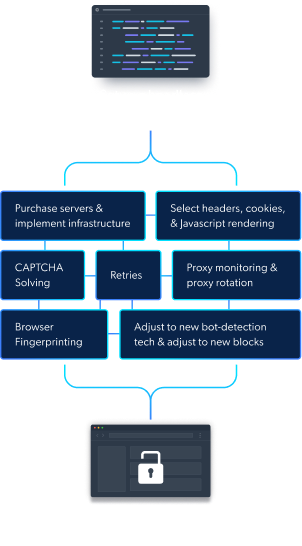

Powered by an award-winning proxy network
Over 72 million IPs, best-in-class technology
and the ability to target any country, city, carrier & ASN make our premium proxy services a top choice for developers.























